Optimización del uso de memoria para Apache Spark
En este artículo se describe cómo optimizar la administración de memoria del clúster de Apache Spark para obtener el mejor rendimiento en Azure HDInsight.
Información general
Spark funciona mediante la colocación de datos en memoria, por lo que administrar los recursos de memoria es un aspecto importante de la optimización de la ejecución de trabajos de Spark. Hay varias técnicas que puede aplicar para usar la memoria del clúster de manera eficaz.
- Elija particiones de datos más pequeñas y tenga en cuenta el tamaño de los datos, los tipos y la distribución en su estrategia de creación de particiones.
- Considere la
Kryo data serializationmás reciente y más eficiente, en lugar de la serialización Java predeterminada. - Elija el uso de YARN, dado que separa
spark-submitpor lote. - Supervise y ajuste los valores de configuración de Spark.
Para que le sirva de referencia, en la imagen siguiente se muestran la estructura de memoria de Spark y algunos parámetros de memoria de ejecutores principales.
Consideraciones de memoria de Spark
Si usa Apache Hadoop YARN, YARN controla la memoria que usan todos los contenedores en cada nodo de Spark. En el diagrama siguiente se muestran los objetos principales y sus relaciones.
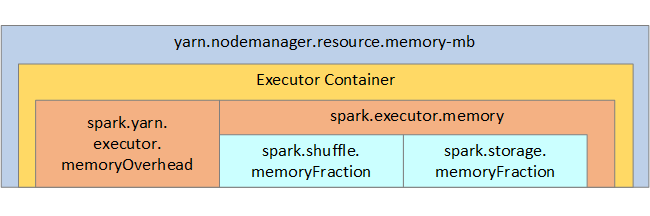
Para resolver los mensajes de falta de memoria, intente lo siguiente:
- Revise los órdenes aleatorios de administración de DAG. Reduzca en el lado de asignación, cree particiones previas (o depósitos) de los datos de origen, maximice los órdenes aleatorios únicos y reduzca la cantidad de datos enviados.
- Elija
ReduceByKey, con su límite fijo de memoria, antes queGroupByKey, que proporciona agregaciones, ventanas y otras funciones, pero que tiene un límite de memoria no enlazado. - Elija
TreeReduce, que realiza más trabajo en los ejecutores o particiones, antes queReduce, que hace todo el trabajo en el controlador. - Use DataFrames en lugar de los objetos RDD de nivel inferior.
- Cree ComplexTypes que encapsulan acciones, como "N principales", diversas agregaciones u operaciones de ventanas.
Si necesita pasos de solución de problemas adicionales, consulte Excepciones OutOfMemoryError para Apache Spark en Azure HDInsight.