Introducción a Apache Spark Streaming
Apache Spark Streaming proporciona procesamiento de flujo de datos en clústeres de HDInsight Spark. Garantiza que todos los eventos de entrada se procesan exactamente una vez, incluso si se produce un error del nodo. Un flujo de Spark es un trabajo de ejecución prolongada que recibe datos de entrada de una amplia variedad de orígenes, incluido Azure Event Hubs. También: Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ, sockets TCP sin formato, o bien desde la supervisión de los sistemas de archivo YARN de Apache Hadoop. A diferencia de un proceso exclusivamente orientado a eventos, un flujo de Spark procesa por lotes los datos de entrada en ventanas de tiempo. Por ejemplo, como un segmento de 2 segundos, y luego transforma cada lote de datos utilizando operaciones de asignación, reducción, unión y extracción. Spark Streaming después escribe los datos transformados en sistemas de archivos, bases de datos, paneles y la consola.
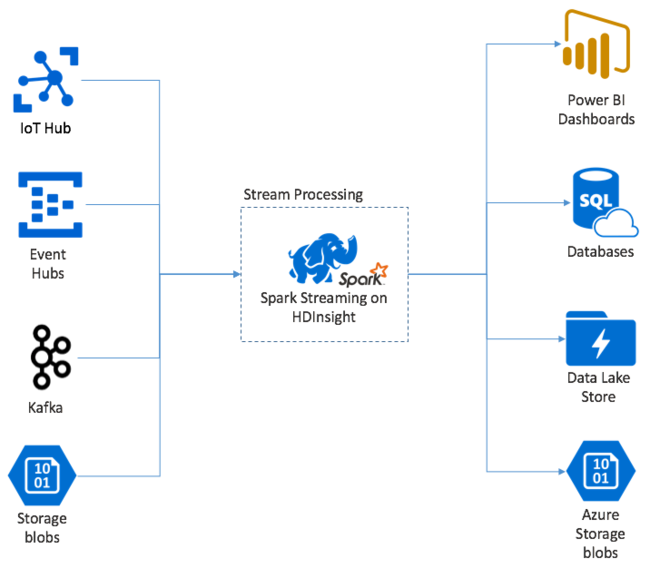
Las aplicaciones de Spark Streaming deben esperar una fracción de segundo para recopilar cada micro-batch de eventos antes de enviar ese lote para procesarlo. En cambio, una aplicación controlada por eventos procesa cada evento inmediatamente. La latencia de Spark Streaming suele ser de unos segundos. Las ventajas del enfoque de los microlotes son una mayor eficacia del procesamiento de datos y cálculos agregados más sencillos.
Introducción a los flujos DStream
Spark Streaming representa un flujo continuo de datos entrantes que utilizan un flujo discretizado llamado "DStream". Se puede crear un flujo DStream a partir de orígenes de entrada como Event Hubs o Kafka. O aplicando transformaciones en otro DStream.
Un flujo DStream proporciona una capa de abstracción basada en los datos del evento sin procesar.
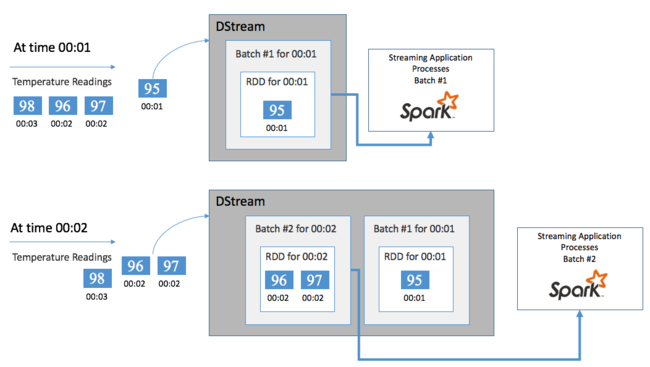
Comience con un solo evento, por ejemplo, una lectura de temperatura en un termostato conectado. Cuando este evento llega a la aplicación de Spark Streaming, se almacena de forma confiable, donde se replica en varios nodos. Esta tolerancia a errores garantiza que un error de un solo nodo no provocará la pérdida del evento. Spark Core usa una estructura de datos que distribuye los datos entre varios nodos del clúster. En este caso, en general, cada nodo mantiene sus propios datos en memoria para obtener el mejor rendimiento. Esta estructura de datos se denomina conjunto de datos distribuido resistente (RDD).
Cada RDD representa eventos recopilados a través de un período definido por el usuario llamado intervalo entre lotes. Cuando transcurre cada intervalo entre lotes, se genera un nuevo diseño que contiene todos los datos de ese intervalo. El conjunto continuo de datos distribuidos resistentes se recopila en un flujo DStream. Por ejemplo, si el intervalo entre lotes es de un segundo, el flujo DStream emite un lote cada segundo con un RDD que contiene todos los datos ingeridos durante ese segundo. Al procesar el flujo DStream, el evento de temperatura se muestra en uno de estos lotes. Una aplicación de Spark Streaming procesa los lotes que contienen los eventos y, en última instancia, actúa en los datos almacenados en cada RDD.
Estructura de una aplicación de Spark Streaming
Una aplicación de Spark Streaming es una aplicación de ejecución prolongada que recibe datos de orígenes de ingesta. Aplica las transformaciones para procesar los datos y, a continuación, envía los datos a uno o varios destinos. La estructura de una aplicación de Spark Streaming tiene una parte estática y otra dinámica. La parte estática define el origen de los datos y qué procesamiento hay que realizar en ellos. Además, dónde deben ir los resultados. La parte dinámica ejecuta la aplicación de forma indefinida y espera una señal de detención.
Por ejemplo, la siguiente aplicación sencilla recibe una línea de texto a través de un socket TCP y cuenta el número de veces que aparece cada palabra.
Definición de la aplicación
La definición de la lógica de la aplicación consta de cuatro pasos:
- Crear un objeto StreamingContext
- Crear un flujo DStream a partir del objeto StreamingContext
- Aplicar transformaciones al flujo DStream
- Generar los resultados
Esta definición es estática y no se procesa ningún dato hasta que se ejecuta la aplicación.
Creación de un objeto StreamingContext
Cree un objeto StreamingContext desde el objeto SparkContext que apunta al clúster. Al crear un objeto StreamingContext, especifique el tamaño del lote en segundos, por ejemplo:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Creación de un flujo DStream
Con la instancia del objeto StreamingContext, cree un flujo DStream de entrada para el origen de entrada. En este caso, la aplicación se fija en la apariencia de los archivos nuevos en el almacenamiento asociado predeterminado.
val lines = ssc.textFileStream("/uploads/Test/")
Aplicación de transformaciones
Implemente el procesamiento aplicando transformaciones en el flujo DStream. Esta aplicación recibe una línea de texto a la vez desde el archivo y divide cada línea en palabras. Y, a continuación, usa un patrón map-reduce para contar el número de veces que aparece cada palabra.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Generación de los resultados
Envíe los resultados de transformación a los sistemas de destino aplicando operaciones de salida. En este caso, el resultado de cada ejecución durante el cálculo se imprime en la salida de consola.
wordCounts.print()
Ejecución de la aplicación
Inicie la aplicación de streaming y ejecútela hasta que se reciba una señal de finalización.
ssc.start()
ssc.awaitTermination()
Para obtener más información sobre la API de Spark Streaming, consulte la guía de programación de Apache Spark Streaming.
La siguiente aplicación de ejemplo es independiente, así que puede ejecutarla en un cuaderno de Jupyter Notebook. En este ejemplo, se crea un origen de datos ficticio en la clase DummySource que genera el valor de un contador y la hora actual en milisegundos cada cinco segundos. Un nuevo objeto StreamingContext tiene un intervalo entre lotes de 30 segundos. Cada vez que se crea un lote, la aplicación de streaming examina el RDD generado. A continuación, convierte el RDD en un DataFrame de Spark y crea una tabla temporal sobre el DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Espere aproximadamente 30 segundos después de iniciar la aplicación anterior. Después, puede consultar periódicamente el objeto DataFrame para ver el conjunto actual de valores presentes en el lote, por ejemplo, con el uso de esta consulta SQL:
%%sql
SELECT * FROM demo_numbers
El resultado tendrá un aspecto similar al siguiente:
| value | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Hay seis valores, ya que el objeto DummySource crea un valor cada cinco segundos y la aplicación emite un lote cada treinta segundos.
Ventanas deslizantes
Para realizar cálculos agregados en el flujo DStream durante un período concreto, por ejemplo, para obtener una temperatura media durante los últimos dos segundos, use las operaciones de sliding window incluidas con Spark Streaming. Una ventana deslizante tiene una duración (la longitud de la ventana) y un intervalo durante el cual se evalúa su contenido (el intervalo de deslizamiento).
Las ventanas deslizantes se pueden superponer; por ejemplo, puede definir una ventana con una longitud de dos segundos, que se desliza cada segundo. Esta acción implica que cada vez que realice un cálculo de agregación, la ventana incluirá los datos del último segundo de la ventana anterior. Además de cualquier dato nuevo del siguiente segundo.
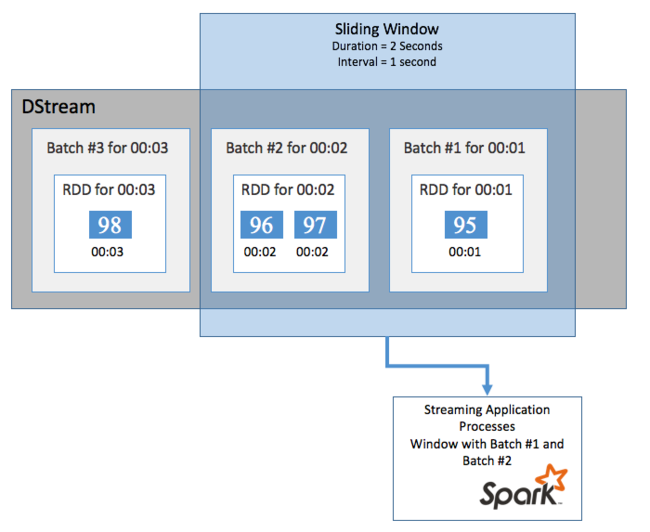
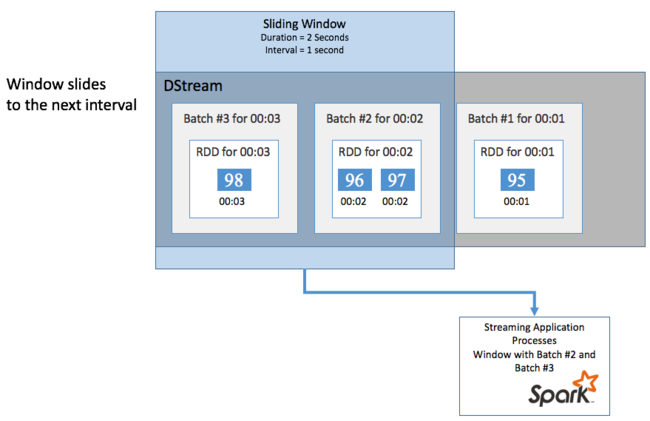
En el ejemplo siguiente, se actualiza el código que utiliza el objeto DummySource para recopilar los lotes en una ventana con una duración de un minuto y un deslizamiento de un minuto.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Después del primer minuto, hay doce entradas: seis entradas de cada uno de los dos lotes recopilados en la ventana.
| value | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Las funciones de ventana deslizante disponibles en la API de Spark Streaming incluyen las funciones window, countByWindow, reduceByWindow y countByValueAndWindow. Para obtener más información sobre estas funciones, consulte Transformations on DStreams (Transformaciones en flujos DStream).
Puntos de control
Para proporcionar resistencia y tolerancia a errores, Spark Streaming se basa en los puntos de control para garantizar que el procesamiento de flujos puede continuar sin interrupciones, aunque se produzcan errores de nodo. Spark crea puntos de control en un almacenamiento duradero (Azure Storage o Data Lake Storage). Estos puntos de control almacenan metadatos de la aplicación de streaming, como la configuración y las operaciones definidas por la aplicación. Además, todos los lotes que se pusieron en cola pero que todavía no se han procesado. En algunos casos, los puntos de control también guardarán los datos en los RDD para recompilar con más rapidez el estado de los datos a partir de lo que haya presente en los RDD que administra Spark.
Implementación de aplicaciones de Spark Streaming
Normalmente se crea una aplicación de Spark Streaming localmente en un archivo JAR. A continuación, se implementa en Spark en HDInsight copiando el archivo JAR en el almacenamiento conectado predeterminado. Después, puede iniciar la aplicación mediante las API REST de LIVY disponibles en el clúster mediante una operación POST. El cuerpo de POST incluye un documento JSON que proporciona la ruta de acceso al archivo JAR. Y el nombre de la clase cuyo método principal define y ejecuta la aplicación de streaming y, opcionalmente, los requisitos de recursos del trabajo (por ejemplo, el número de ejecutores, la memoria y los núcleos). Además, todos los valores de configuración que requiere el código de la aplicación.
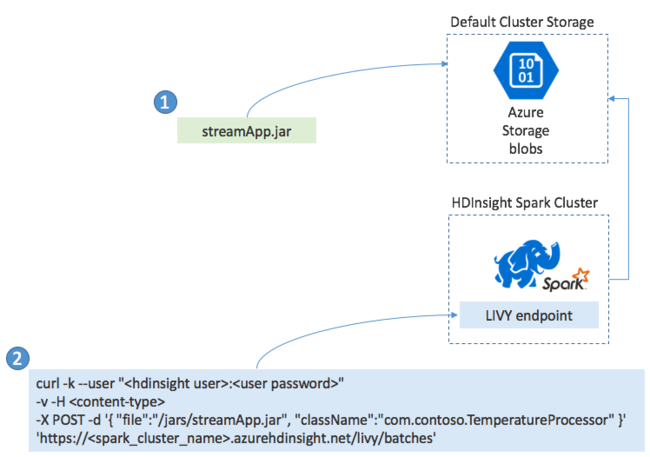
También se puede comprobar el estado de todas las aplicaciones con una solicitud GET en un punto de conexión de LIVY. Por último, puede finalizar una aplicación en ejecución emitiendo una solicitud DELETE en el punto de conexión de LIVY. Para más información sobre la API de LIVY, consulte Trabajos remotos con Apache LIVY.