Guía de ajuste de tamaño del clúster de Azure HDInsight Interactive Query (Hive LLAP)
En este documento se describe el ajuste de tamaño del clúster de HDInsight Interactive Query (clúster Hive LLAP) de una carga de trabajo típica para lograr un rendimiento razonable. Tenga en cuenta que las recomendaciones proporcionadas en este documento son directrices genéricas y las cargas de trabajo específicas pueden necesitar un ajuste específico.
Tipos de VM predeterminadas de Azure para el clúster de HDInsight Interactive Query (LLAP)
| Tipo de nodo | Instancia | Size |
|---|---|---|
| Head | D13 v2 | 8 vcpus, RAM de 56 GB, SSD de 400 GB |
| Trabajo | D14 v2 | 16 vcpus, RAM de 112 GB, SSD de 800 GB |
| ZooKeeper | A4 v2 | 4 vcpus, RAM de 8 GB, SSD de 40 GB |
Nota: Todos los valores de las configuraciones recomendadas se basan en el nodo de trabajo de tipo D14 v2
Configuración:
| Clave de configuración | Valor recomendado | Descripción |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 102400 (MB) | Memoria total proporcionada, en MB, para todos los contenedores de YARN de un nodo. |
| yarn.scheduler.maximum-allocation-mb | 102400 (MB) | La asignación máxima para cada solicitud de contenedor en RM, en MB. Las solicitudes de memoria que superen este valor no surtirán efecto. |
| yarn.scheduler.maximum-allocation-vcores | 12 | Número máximo de núcleos de CPU para cada solicitud de contenedor en Resource Manager. Las solicitudes que superen este valor no surtirán efecto. |
| yarn.nodemanager.resource.cpu-vcores | 12 | Número de núcleos de CPU por NodeManager que se pueden asignar para contenedores. |
| yarn.scheduler.capacity.root.llap.capacity | 85 (%) | Asignación de la capacidad de YARN para la cola de LLAP |
| tez.am.resource.memory.mb | 4096 (MB) | Cantidad de memoria en MB que va a usar AppMaster de Tez. |
| hive.server2.tez.sessions.per.default.queue | <number_of_worker_nodes> | Número de sesiones de cada cola mencionada en hive.server2.tez.default.queues. Este número corresponde al número de coordinadores de consultas (AM de Tez). |
| hive.tez.container.size | 4096 (MB) | Tamaño de contenedor de Tez especificado en MB. |
| hive.llap.daemon.num.executors | 19 | Número de ejecutores por demonio de LLAP. |
| hive.llap.io.threadpool.size | 19 | Tamaño del grupo de subprocesos para los ejecutores. |
| hive.llap.daemon.yarn.container.mb | 81920 (MB) | Memoria total en MB usada por demonios de LLAP individuales (memoria por demonio). |
| hive.llap.io.memory.size | 242688 (MB) | Tamaño de caché en MB por demonio de LLAP si la caché del disco SSD está habilitada. |
| hive.auto.convert.join.noconditionaltask.size | 2048 (MB) | Tamaño de memoria en MB para realizar la combinación de asignación. |
Componentes o arquitectura de LLAP:
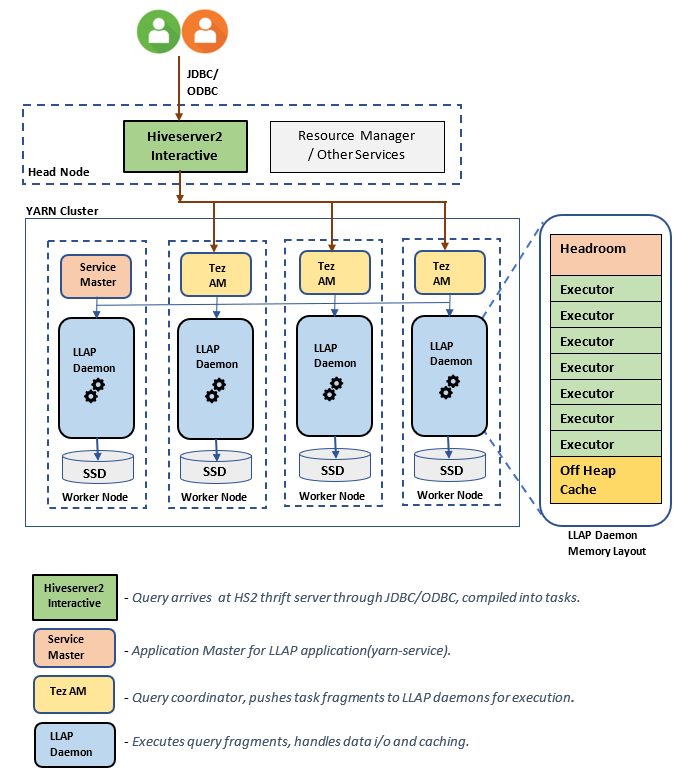
Estimaciones de tamaño de demonio de LLAP:
1. Determinación de la asignación de memoria total de YARN para todos los contenedores de un nodo
Configuración: yarn.nodemanager.resource.memory-mb
Este valor indica una suma máxima de memoria en MB que pueden usar los contenedores de YARN en cada nodo. El valor especificado debe ser inferior a la cantidad total de memoria física en ese nodo.
Memoria total de todos los contenedores de YARN de un nodo = (memoria física total – memoria de SO + otros servicios)
Establezca este valor en aproximadamente un 90 % del tamaño de RAM disponible.
Para D14 v2, se recomienda un valor de 102400 MB.
2. Determinación de la cantidad máxima de memoria por solicitud de contenedor de YARN
Configuración: yarn.scheduler.maximum-allocation-mb
Este valor indica la asignación máxima para cada solicitud de contenedor en Resource Manager, en MB. Las solicitudes de memoria que superen el valor especificado no surtirán efecto. Resource Manager puede proporcionar memoria a los contenedores en incrementos de yarn.scheduler.minimum-allocation-mb y no puede superar el tamaño especificado por yarn.scheduler.maximum-allocation-mb. El valor especificado no debe ser mayor que la memoria total proporcionada para todos los contenedores en el nodo especificado por yarn.nodemanager.resource.memory-mb.
Para los nodos de trabajo D14 v2, se recomienda un valor de 102400 MB.
3. Determinación de la cantidad máxima de vcores por solicitud de contenedor de YARN
Configuración: yarn.scheduler.maximum-allocation-vcores
Este valor indica el número máximo de núcleos de CPU virtuales para cada solicitud de contenedor en Resource Manager. La solicitud de un número mayor de vcores que este valor no surtirá efecto. Esta es una propiedad global del programador de YARN. Para el contenedor del demonio de LLAP, este valor se puede establecer en el 75 % del total de vcores disponibles. El 25 % restante se debe reservar para NodeManager, DataNode y otros servicios que se ejecutan en los nodos de trabajo.
Hay 16 vcores en las máquinas virtuales de D14 v2 y el contenedor de demonio de LLAP puede usar un 75 % de los 16 vcores totales.
Para D14 v2, se recomienda un valor de 12.
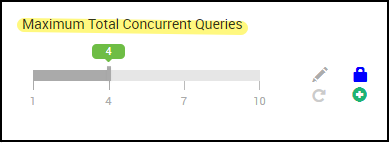
4. Número de consultas simultáneas
Configuración: hive.server2.tez.sessions.per.default.queue
Este valor de configuración determina el número de sesiones de Tez que deben iniciarse en paralelo. Estas sesiones de Tez se inician para cada una de las colas especificadas por "hive.server2.tez.default.queues". Corresponde al número de AM de Tez (coordinadores de consultas). Se recomienda que sea el mismo que el número de nodos de trabajo. El número de AM de Tez puede ser mayor que el número de nodos de demonio de LLAP. La responsabilidad principal de los AM de Tez es coordinar la ejecución de la consulta y asignar los fragmentos del plan de consulta a los demonios de LLAP correspondientes para su ejecución. Mantenga este valor como múltiplo de muchos nodos de demonio de LLAP para lograr un mayor rendimiento.
El clúster de HDInsight predeterminado tiene cuatro demonios de LLAP que se ejecutan en cuatro nodos de trabajo, por lo que el valor recomendado es 4.
Control deslizante de la interfaz de usuario de Ambari de la variable de configuración de Hive hive.server2.tez.sessions.per.default.queue:
5. Tamaño del maestro de la aplicación Tez y el contenedor de Tez
Configuración: tez.am.resource.memory.mb, hive.tez.container.size
tez.am.resource.memory.mb - define el tamaño del maestro de la aplicación Tez.
Se recomienda un valor de 4096 MB.
hive.tez.container.size: define la cantidad de memoria proporcionada para el contenedor de Tez. Este valor se debe establecer entre el tamaño mínimo de contenedor de YARN (yarn.scheduler.minimum-allocation-mb) y el tamaño máximo del contenedor de YARN (yarn.scheduler.maximum-allocation-mb). Los ejecutores del demonio de LLAP usan este valor para limitar el uso de memoria por ejecutor.
Se recomienda un valor de 4096 MB.
6. Asignación de la capacidad de la cola de LLAP
Configuración: yarn.scheduler.capacity.root.llap.capacity
Este valor indica un porcentaje de la capacidad proporcionada a la cola de LLAP. Las asignaciones de capacidad pueden tener valores diferentes para las distintas cargas de trabajo en función de cómo estén configuradas las colas de YARN. Si la carga de trabajo es de operaciones de solo lectura, configurar esta opción en un máximo del 90 % de la capacidad debería funcionar. Pero si la carga de trabajo es una mezcla de operaciones de actualización, eliminación y combinación con tablas administradas, se recomienda proporcionar un 85 % de la capacidad a la cola de LLAP. Otras tareas, como la compactación, etc., pueden usar el 15 % de capacidad restante para asignar contenedores desde la cola predeterminada. De este modo, las tareas de la cola predeterminada no desautorizarán los recursos de YARN.
En los nodos de trabajo D14 v2, el valor recomendado de la cola de LLAP es 85.
(Para cargas de trabajo de solo lectura, se puede aumentar hasta 90 según sea necesario).
7. Tamaño del contenedor del demonio de LLAP
Configuración: hive.llap.daemon.yarn.container.mb
El demonio de LLAP se ejecuta como un contenedor de YARN en cada nodo de trabajo. El tamaño total de la memoria para el demonio de LLAP depende de los siguientes factores:
- Configuraciones de tamaño de contenedor de YARN (yarn.scheduler.minimum-allocation-mb, yarn.scheduler.maximum-allocation-mb, yarn.nodemanager.resource.memory-mb)
- Número de AM de Tez en un nodo
- Memoria total configurada para todos los contenedores en un nodo y capacidad de la cola de LLAP
La memoria que necesitan los maestros de la aplicación Tez (AM de Tez) se puede calcular de la manera siguiente.
Un AM de Tez actúa como coordinador de consultas, así que el número de AM de Tez debe configurarse basándose en muchas consultas simultáneas que se van a atender. Teóricamente, se puede considerar un AM de Tez por nodo de trabajo. Pero es posible que se vea más de un AM de Tez en un nodo de trabajo. Para fines de cálculo, se da por hecha una distribución uniforme de AM de Tez entre todos los nodos de trabajo o demonio de LLAP.
Se recomienda tener 4 GB de memoria por AM de Tez.
Número de AM de Tez = valor especificado por la configuración de Hive hive.server2.tez.sessions.per.default.queue.
Número de nodos de demonio de LLAP = especificado por la variable env num_llap_nodes_for_llap_daemons en la interfaz de usuario de Ambari.
Tamaño de contenedor de AM de Tez = valor especificado por la configuración de Tez tez.am.resource.memory.mb.
Memoria de AM de Tez por nodo = (ceil(Número de AM de Tez / Número de nodos de demonio de LLAP) x Tamaño de contenedor de AM de Tez**)**
En D14 V2, la configuración predeterminada tiene cuatro AM de Tez y cuatro nodos de demonio de LLAP.
Memoria de AM de Tez por nodo = (ceil(4/4) x 4 GB) = 4 GB
La memoria total disponible para la cola de LLAP por nodo de trabajo se puede calcular de la manera siguiente:
Este valor depende de la cantidad total de memoria disponible para todos los contenedores de YARN de un nodo (yarn.nodemanager.resource.memory-mb) y el porcentaje de capacidad configurada para la cola de LLAP (yarn.scheduler.capacity.root.llap.capacity).
Memoria total para la cola de LLAP en el nodo de trabajo = memoria total disponible para todos los contenedores de YARN de un nodo x porcentaje de capacidad para la cola de LLAP.
En D14 v2, este valor es [100 GB x 0,85] = 85 GB.
El tamaño del contenedor del demonio de LLAP se calcula como se indica a continuación:
Tamaño de contenedor de demonio de LLAP = (Memoria total de la cola de LLAP en un nodo de trabajo) – (Memoria de AM de Tez por nodo) - (Tamaño del contenedor maestro del servicio)
Solo hay un maestro de servicio (maestro de aplicación de servicio LLAP) en el clúster generado en uno de los nodos de trabajo. Para fines de cálculo, se considera un maestro de servicio por nodo de trabajo.
En el nodo de trabajo D14 v2, HDI 4.0: el valor recomendado es (85 GB - 4 GB - 1 GB)) = 80 GB
8. Determinación del número de ejecutores por demonio de LLAP
Configuración: hive.llap.daemon.num.executors, hive.llap.io.threadpool.size
hive.llap.daemon.num.executors:
Esta configuración controla el número de ejecutores que pueden ejecutar tareas en paralelo por demonio de LLAP. Este valor depende del número de núcleos virtuales, la cantidad de memoria usada por ejecutor y la cantidad de memoria total disponible por contenedor de demonio de LLAP. El número de ejecutores se puede saturar al 120 % de núcleos virtuales disponibles por nodo de trabajo. Pero debe ajustarse si no cumple los requisitos de memoria según la memoria necesaria por ejecutor y el tamaño de contenedor de demonio de LLAP.
Cada ejecutor es equivalente a un contenedor de Tez y puede consumir 4 GB (tamaño de contenedor de Tez) de memoria. Todos los ejecutores del demonio de LLAP comparten la misma memoria en montón. Si se da por hecho que no todos los ejecutores ejecutan operaciones intensivas de memoria al mismo tiempo, puede considerar el 75 % del tamaño de contenedor de Tez (4 GB) por ejecutor. De este modo, puede aumentar el número de ejecutores si asigna a cada ejecutor menos memoria (por ejemplo, 3 GB) para un mayor paralelismo. Pero se recomienda ajustar este valor a la carga de trabajo de destino.
Hay 16 núcleos virtuales en las VM de D14 v2. En D14 v2, el valor recomendado para el número de ejecutores es (16 núcleos virtuales x 120 %) ~= 19 en cada nodo de trabajo que considere 3 GB por ejecutor.
hive.llap.io.threadpool.size:
Este valor especifica el tamaño del grupo de subprocesos para los ejecutores. Como los ejecutores son fijos tal y como se han especificado, coincide con el número de ejecutores por demonio de LLAP.
En D14 v2, el valor recomendado es 19.
9. Determinación del tamaño de la caché del demonio de LLAP
Configuración: hive.llap.io.memory.size
La memoria del contenedor del demonio de LLAP consta de los siguientes componentes:
- Capacidad de aumento
- Memoria de montón usada por los ejecutores (Xmx)
- Caché en memoria por demonio (su tamaño de memoria fuera del montón, no aplicable cuando la memoria caché de SSD está habilitada)
- Tamaño de los metadatos de caché en memoria (solo se aplica cuando la memoria caché de SSD está habilitada)
Tamaño de la capacidad de aumento: este tamaño indica una parte de la memoria fuera del montón usada para la sobrecarga de la máquina virtual de Java (metaespacio, pila de subprocesos, estructuras de datos de gc, etc.). Por lo general, esta sobrecarga es aproximadamente el 6 % del tamaño del montón (Xmx). Para ir a lo seguro, este valor se puede calcular como el 6 % del tamaño total de la memoria del demonio de LLAP.
En D14 v2, el valor recomendado es ceil(80 GB x 0,06) ~= 4 GB.
Tamaño del montón (Xmx) : cantidad de memoria en el montón disponible para todos los ejecutores.
Tamaño total del montón = Número de ejecutores x 3 GB
En D14 v2, este valor es 19 x 3 GB = 57 GB
Ambari environment variable for LLAP heap size:

Si la memoria caché de SSD está deshabilitada, la caché en memoria es la cantidad de memoria que queda después de tomar el tamaño de la capacidad de aumento y el tamaño del montón del tamaño de contenedor del demonio de LLAP.
El cálculo del tamaño de la caché es diferente cuando la memoria caché de SSD está habilitada.
Si establece hive.llap.io.allocator.mmap = true, se habilita el almacenamiento en caché de SSD.
Si se habilita la memoria caché de SSD, se usará parte de la memoria para almacenar los metadatos de la memoria caché de SSD. Los metadatos se almacenan en memoria y se espera que ocupen aproximadamente el 8 % del tamaño de la caché de SSD.
Tamaño de metadatos en memoria de la caché de SSD = Tamaño de contenedor del demonio de LLAP - (Capacidad de aumento + Tamaño del montón)
En D14 v2, con HDI 4.0, el tamaño de los metadatos en memoria de la caché de SSD = 80 GB - (4 GB + 57 GB) = 19 GB
Dado el tamaño de la memoria disponible para almacenar los metadatos de la memoria caché de SSD, podemos calcular el tamaño de la memoria caché de SSD que se puede admitir.
Tamaño de metadatos en memoria de la caché de SSD = Tamaño de contenedor del demonio de LLAP - (Capacidad de aumento + Tamaño del montón) = 19 GB
Tamaño de la caché de SSD = Tamaño de los metadatos en memoria de la caché de SSD(19 GB) / 0,08 (8 %)
En D14 v2 y HDI 4.0, el tamaño de la caché de SSD recomendado es de 19 GB / 0,08 ~= 237 GB
10. Ajuste de la memoria de combinación de asignación
Configuración: hive.auto.convert.join.noconditionaltask.size
Asegúrese de que tiene hive.auto.convert.join.noconditionaltask habilitado para que este parámetro surta efecto.
Esta configuración determina el umbral para la selección de combinación de asignación por parte del optimizador de Hive que considera la saturación de memoria de otros ejecutores para tener más espacio para las tablas hash en memoria con el fin de permitir más conversiones de combinación de asignación. Si se consideran 3 GB por ejecutor, este tamaño se puede saturar a 3 GB, aunque otras operaciones también pueden usar alguna memoria del montón para los búferes de ordenación, los búferes aleatorios, etc.
Así, en D14 v2, con 3 GB de memoria por ejecutor, se recomienda establecer este valor en 2048 MB.
(Nota: Este valor puede necesitar ajustes adecuados para la carga de trabajo. Si se establece este valor demasiado bajo, no se podrá usar la característica de conversión automática; establecerlo demasiado alto puede dar lugar a excepciones de falta de memoria o pausas de GC que causen errores de funcionamiento).
11. Número de demonios de LLAP
Variables de entorno de Ambari: num_llap_nodes, num_llap_nodes_for_llap_daemons
_num_llap_nodes: especifica el número de nodos usados por el servicio LLAP de Hive, y se incluyen los nodos que ejecutan el demonio de LLAP, el maestro de servicio de LLAP y el maestro de aplicación de Tez (AM de Tez).
num_llap_nodes_for_llap_daemons - número especificado de nodos usados solo para demonios de LLAP. Los tamaños de contenedor de demonio de LLAP se establecen en el nodo de ajuste máximo, lo que da lugar a un demonio de llap en cada nodo.

Se recomienda que ambos valores sean iguales al número de nodos de trabajo en el clúster de Interactive Query.
Consideraciones para la administración de cargas de trabajo
Si quiere habilitar la administración de cargas de trabajo de LLAP, asegúrese de reservar capacidad suficiente para que esta funcione según lo previsto. La administración de cargas de trabajo requiere la configuración de una cola de YARN personalizada, además de la cola de llap. Asegúrese de dividir la capacidad total de los recursos de clúster entre la cola de llap y la cola de administración de cargas de trabajo según los requisitos de carga de trabajo.
La administración de cargas de trabajo genera los maestros de aplicación de Tez (AM de Tez) cuando se activa un plan de recursos.
Nota:
- Los AM de Tez generados mediante la activación de un plan de recursos consumen recursos de la cola de administración de cargas de trabajo como se especifica en
hive.server2.tez.interactive.queue. - El número de AM de Tez depende del valor de
QUERY_PARALLELISMespecificado en el plan de recursos. - Una vez que la administración de cargas de trabajo está activa, no se usan los AM de Tez de la cola de LLAP. Solo se usan los de la cola de administración de cargas de trabajo para la coordinación de consultas. Los AM de Tez de la cola de
llapse usan cuando la administración de cargas de trabajo está deshabilitada.
Por ejemplo: Capacidad total del clúster = 100 GB de memoria divididos entre las colas de LLAP, administración de cargas de trabajo y predeterminadas como se indica a continuación:
- Capacidad de la cola de LLAP = 70 GB
- Capacidad de la cola de administración de cargas de trabajo = 20 GB
- Capacidad de la cola predeterminada = 10 GB
Con 20 GB de capacidad de la cola de administración de cargas de trabajo, un plan de recursos puede especificar el valor QUERY_PARALLELISM como cinco, lo que significa que la administración de cargas de trabajo puede iniciar cinco AM de Tez con un tamaño de contenedor de 4 GB cada uno. Si QUERY_PARALLELISM es mayor que la capacidad, puede ver algunos AM de Tez dejen de responder en el estado ACCEPTED. El servidor de Hive 2 interactivo no puede enviar fragmentos de consulta a los AM de Tez que no están en estado RUNNING.
Pasos siguientes
Si con el establecimiento de este valor no se resuelve el problema, elija una de las opciones siguientes:
Obtenga respuestas de expertos de Azure mediante el soporte técnico de la comunidad de Azure.
Póngase en contacto con @AzureSupport, la cuenta oficial de Microsoft Azure para mejorar la experiencia del cliente, al dirigir a la comunidad de Azure a los recursos adecuados: respuestas, soporte técnico y expertos.
Si necesita más ayuda, puede enviar una solicitud de soporte técnico desde Azure Portal. Seleccione Soporte técnico en la barra de menús o abra la central Ayuda + soporte técnico. Para obtener información más detallada, revise Creación de una solicitud de soporte técnico de Azure. La suscripción a Microsoft Azure incluye acceso al soporte técnico para facturación y administración de suscripciones. El soporte técnico se proporciona a través de uno de los planes de soporte técnico de Azure.
Otras referencias: