Uso de la replicación de Apache Hive en clústeres de Azure HDInsight
En el contexto de las bases de datos y los almacenes, la replicación es el proceso por el cual se duplican las entidades de un almacén a otro. La duplicación puede aplicarse a una base de datos completa o a un nivel más pequeño, como una tabla o una partición. El objetivo es tener una réplica que cambie cada vez que lo hace la entidad base. La replicación en Apache Hive se centra en la recuperación ante desastres y ofrece replicación unidireccional de copia principal. En los clústeres de HDInsight, la replicación de Hive se puede usar para replicar unidireccionalmente el metastore de Hive y el lago de datos subyacente asociado en Azure Data Lake Storage Gen2.
La replicación de Hive ha evolucionado a lo largo de los años con nuevas versiones que proporcionan una mejor funcionalidad y son más rápidas y que consumen menos recursos. En este artículo, se describe la replicación de Hive (Replv2), que se admite en los tipos de clúster de HDInsight 3.6 y HDInsight 4.0.
Ventajas de replv2
Hive ReplicationV2 (también conocido como Replv2) tiene las ventajas siguientes con respecto a la primera versión de la replicación de Hive que usaba Hive IMPORT-EXPORT:
- Replicación incremental basada en eventos
- Replicación de un momento dado
- Requisitos de ancho de banda reducidos
- Reducción del número de copias intermedias
- Se mantiene el estado de replicación
- Replicación restringida
- Compatibilidad con un modelo radial
- Compatibilidad con tablas ACID (en HDInsight 4.0)
Fases de replicación
La replicación basada en eventos de Hive se configura entre los clústeres principal y secundario. Esta replicación se compone de dos fases distintas: arranque y ejecuciones incrementales.
Arranque
El arranque está diseñado para ejecutarse una vez para replicar el estado base de las bases de datos del servidor principal al secundario. Puede configurar el arranque, si es necesario, para incluir un subconjunto de las tablas en la base de datos de destino donde se debe habilitar la replicación.
Ejecuciones incrementales
Después del arranque, las ejecuciones incrementales se automatizan en el clúster principal y los eventos generados durante estas ejecuciones incrementales se reproducen en el clúster secundario. Cuando el clúster secundario se pone al día con el clúster principal, el secundario se vuelve coherente con los eventos del principal.
Comandos de replicación
Hive ofrece un conjunto de comandos de REPL: DUMP, LOAD y STATUS para organizar el flujo de eventos. El comando DUMP genera un registro local de todos los eventos DDL/DML en el clúster principal. El comando LOAD es un enfoque para copiar los metadatos y los datos registrados de forma diferida en la salida del volcado de replicación extraído que se ejecuta en el clúster de destino. El comando STATUS se ejecuta desde el clúster de destino para proporcionar el último identificador de evento en el que se ha replicado correctamente la carga de replicación más reciente.
Establecimiento del origen de la replicación
Antes de comenzar con la replicación, asegúrese de que la base de datos que se va a replicar esté establecida como el origen de la replicación. Puede usar el comando DESC DATABASE EXTENDED <db_name> para determinar si el parámetro repl.source.for se establece con el nombre de la directiva.
Si la directiva está programada y no se ha establecido el parámetro repl.source.for, primero debe establecer este parámetro mediante ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Volcado de metadatos en el lago de datos
El comando REPL DUMP [database name]. => location / event_id se usa en la fase de arranque para volcar los metadatos relevantes en Azure Data Lake Storage Gen2. El elemento event_id especifica el evento mínimo en el que se han colocado los metadatos pertinentes en Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Salida de ejemplo:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Carga de datos en el clúster de destino
El comando REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } se usa para cargar datos en el clúster de destino para el arranque y las fases incrementales de la replicación. El elemento [database name] puede ser el mismo que el origen o un nombre diferente en el clúster de destino. El elemento [location] representa la ubicación de la salida del comando REPL DUMP anterior. Esto significa que el clúster de destino debe ser capaz de comunicarse con el clúster de origen. La cláusula WITH se agregó principalmente para impedir que se reinicie el clúster de destino, lo que permite la replicación.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Generación del último identificador de evento replicado
El comando REPL STATUS [database name] se ejecuta en los clústeres de destino y genera el último event_id replicado. El comando también permite que los usuarios sepan a qué estado se ha replicado su clúster de destino. Puede usar la salida de este comando para construir el siguiente comando REPL DUMP para la replicación incremental.
repl status tpcds_orc;
Salida de ejemplo:
| last_repl_id |
|---|
| 2925 |
Volcado de datos y metadatos relevantes en el lago de datos
El comando REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } se usa para volcar los metadatos y los datos relevantes en Azure Data Lake Storage. Este comando se usa en la fase incremental y se ejecuta en el almacén de origen. El elemento FROM [event-id] es necesario para la fase incremental, y el valor de event-id se puede derivar mediante la ejecución del comando REPL STATUS [database name] en el almacén de destino.
repl dump tpcds_orc from 2925;
Salida de ejemplo:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
Proceso de replicación de Hive
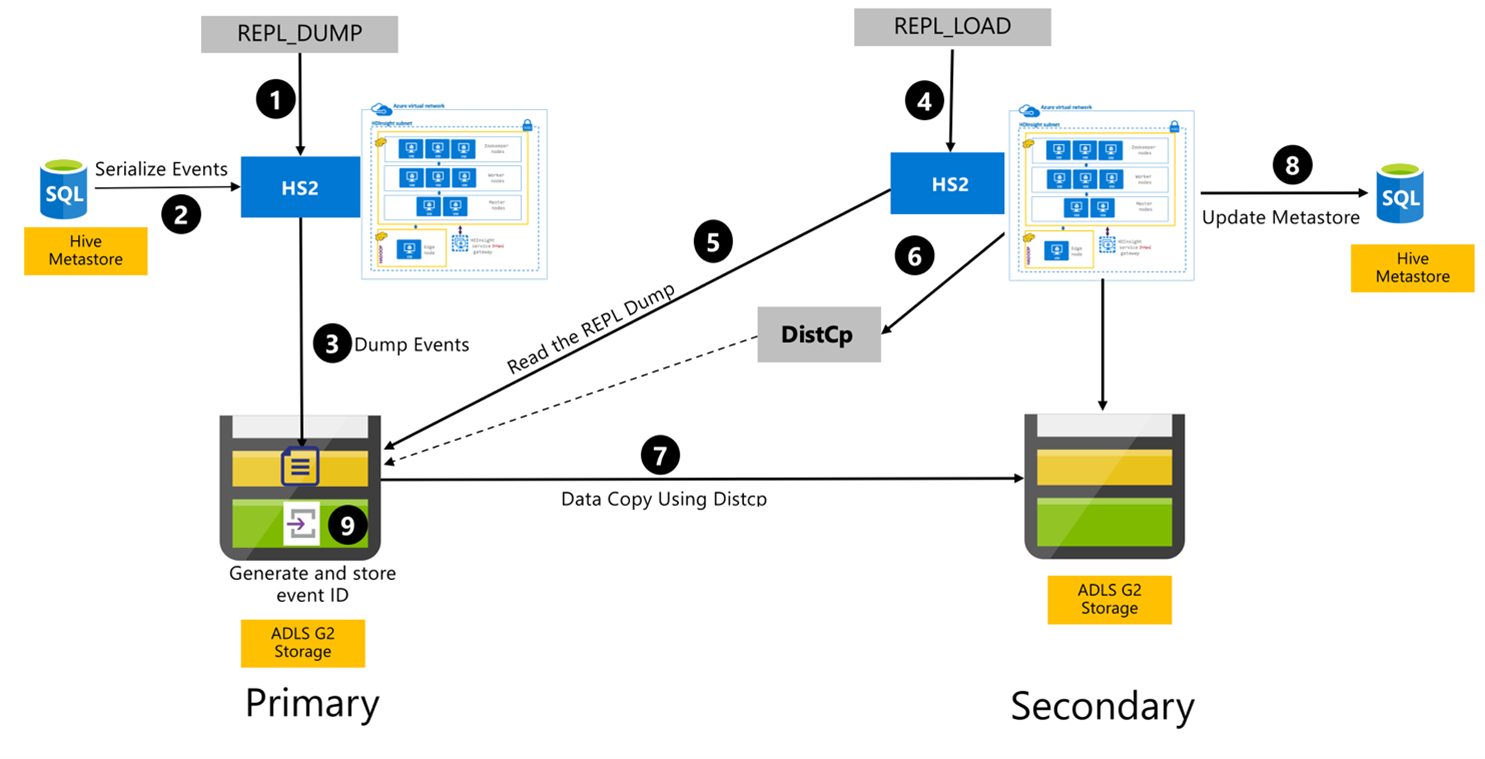
Los pasos siguientes son los eventos secuenciales que tienen lugar durante el proceso de replicación de Hive.
Asegúrese de que las tablas que se van a replicar se establecen como el origen de replicación para una directiva determinada.
El comando
REPL_DUMPse emite para el clúster principal con restricciones asociadas como el nombre de la base de datos, el intervalo del identificador de evento y la dirección URL de almacenamiento de Azure Data Lake Storage Gen2.El sistema serializa un volcado de todos los eventos de los que se ha realizado un seguimiento desde el metastore hasta el más reciente. Este volcado se almacena en la cuenta de almacenamiento de Azure Data Lake Storage Gen2 en el clúster principal, en la dirección URL especificada por el comando
REPL_DUMP.El clúster principal conserva los metadatos de replicación en el almacenamiento de Azure Data Lake Storage Gen2 del clúster principal. La ruta de acceso se puede configurar en la interfaz de usuario de configuración de Hive en Ambari. El proceso proporciona la ruta de acceso donde se almacenan los metadatos y el identificador del evento DML/DDL sometido a seguimiento más reciente.
El comando
REPL_LOADse emite desde el clúster secundario. El comando apunta a la ruta de acceso configurada en el paso 3.El clúster secundario lee el archivo de metadatos con los eventos sometidos a seguimiento creados en el paso 3. Asegúrese de que el clúster secundario tiene conectividad de red con el almacenamiento de Azure Data Lake Storage Gen2 del clúster principal en el que se almacenan los eventos
REPL_DUMPsometidos a seguimiento.El clúster secundario genera un proceso de copia distribuida (
DistCP).El clúster secundario copia los datos del almacenamiento del clúster principal.
El metastore del clúster secundario está actualizado.
El último identificador de evento sometido a seguimiento está almacenado en el metastore principal.
La replicación incremental sigue el mismo proceso y requiere el último identificador de evento replicado como entrada. Esto genera una copia incremental desde el último evento de replicación. Las replicaciones incrementales normalmente se automatizan con una frecuencia predeterminada para lograr los objetivos de punto de recuperación (RPO) necesarios.
Patrones de replicación
Normalmente, la replicación se configura de forma unidireccional entre el clúster principal y el secundario, donde el principal se encarga de las solicitudes de lectura y escritura, mientras que el secundario solo se ocupa de las solicitudes de lectura. Se permiten las escrituras en el clúster secundario si se produce un desastre, pero es necesario volver a configurar en el principal la replicación inversa.
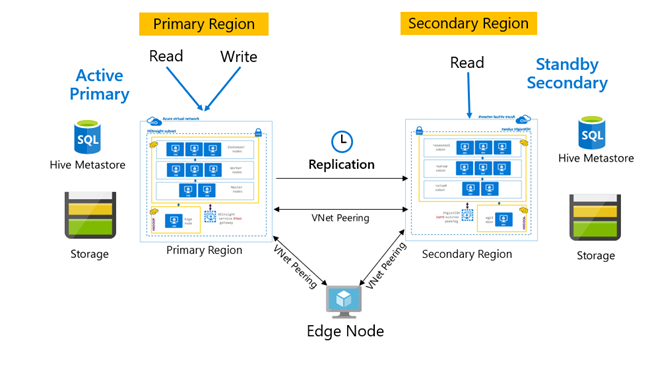
Hay muchos patrones adecuados para la replicación de Hive, como principal-secundario, radial y retransmisión.
En HDInsight, el patrón clúster principal activo y secundario en espera es un patrón común de continuidad empresarial y recuperación ante desastres (BCDR), y HiveReplicationV2 puede usar este patrón con clústeres de HDInsight Hadoop separados por regiones con emparejamiento de VNet. Se puede usar una máquina virtual común emparejada con ambos clústeres para hospedar los scripts de automatización de la replicación. Para obtener más información sobre los posibles patrones de BCDR de HDInsight, consulte Documentación de continuidad empresarial de HDInsight.
Replicación de Hive con Enterprise Security Package
En los casos en los que la replicación de Hive está planeada en clústeres de Hadoop de HDInsight con Enterprise Security Package, debe tener en cuenta los mecanismos de replicación para el metastore de Ranger y Microsoft Entra Domain Services.
Use la característica conjuntos de réplicas de Microsoft Entra Domain Services para crear más de un conjunto de réplicas de Microsoft Entra Domain Services por inquilino de Microsoft Entra en varias regiones. Cada conjunto de réplicas individual debe estar emparejado con las redes virtuales de HDInsight en sus respectivas regiones. En esta configuración, los cambios en Microsoft Entra Domain Services, incluida la configuración, la identidad de usuario y las credenciales, los grupos, los objetos de directiva de grupo, los objetos de equipo y otros cambios se aplican a todos los conjuntos de réplicas del dominio administrado mediante la replicación de Microsoft Entra Domain Services.
Se pueden realizar copias de seguridad periódicas de las directivas de Ranger y replicarlas desde el clúster principal al secundario mediante la funcionalidad de importación y exportación de Ranger. Puede optar por replicar todas o un subconjunto de directivas de Ranger según el nivel de autorización que busque implementar en el clúster secundario.
Código de ejemplo
La siguiente secuencia de código proporciona un ejemplo de cómo se puede implementar el arranque y la replicación incremental en una tabla de ejemplo denominada tpcds_orc.
Establezca la tabla como el origen de una directiva de replicación.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Volcado de arranque en el clúster principal.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Salida de ejemplo:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Carga de arranque en el clúster secundario.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Compruebe el estado de
REPLen el clúster secundario.repl status tpcds_orc;last_repl_id 2925 Volcado incremental en el clúster principal.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Salida de ejemplo:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Carga incremental en el clúster secundario.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Compruebe el estado
REPLen el clúster secundario.repl status tpcds_orc;last_repl_id 2960
Pasos siguientes
Para más información sobre los elementos que se describen en este artículo, consulte: