Instalación y uso de Hue en clústeres de Hadoop para HDInsight
Aprenda a instalar Hue en clústeres de HDInsight Linux y a usar tunelización para enrutar las solicitudes a Hue.
Nota
Hue no se admite en HDInsight 4.0 ni en versiones posteriores.
¿Qué es Hue?
Hue es un conjunto de aplicaciones web que se usan para interactuar con un clúster de Apache Hadoop. Puede usar Hue para examinar el almacenamiento asociado a un clúster de Hadoop (WASB, en el caso de clústeres de HDInsight), ejecutar trabajos de Hive y scripts de Pig, etc. Los siguientes componentes son compatibles con la instalación de Hue en un clúster de Hadoop para HDInsight.
- Editor Beeswax de Hive
- Apache Pig
- Administrador de la tienda de metadatos
- Apache Oozie
- FileBrowser (que se comunica con el contenedor predeterminado WASB)
- Explorador web
Advertencia
Los componentes ofrecidos con HDInsight son totalmente compatibles. Además, el soporte técnico de Microsoft le ayudará a aislar y resolver problemas relacionados con estos componentes.
Los componentes personalizados reciben soporte técnico comercialmente razonable para ayudarle a solucionar el problema. Esto podría resolver el problema o pedirle que forme parte de los canales disponibles para las tecnologías de código abierto donde se encuentra la más amplia experiencia para esa tecnología. Por ejemplo, hay diversos sitios de la comunidad que se pueden usar, como la página de preguntas de Microsoft Q&A sobre HDInsight, https://stackoverflow.com. Los proyectos de Apache también tienen sitios de proyecto en https://apache.org, por ejemplo: Hadoop.
Instalación de Hue mediante acciones de script
Utilice la información de la tabla siguiente para la acción de script. Para obtener instrucciones específicas sobre el uso de las acciones de script, consulte Personalización de clústeres de HDInsight mediante acciones de script.
Nota
Para instalar Hue en clústeres de HDInsight, el tamaño recomendado de nodo principal es como mínimo A4 (8 núcleos, 14 gigabytes de memoria).
| Propiedad | Value |
|---|---|
| Tipo de script: | - Personalizado |
| Nombre | Instalación de Hue |
| URI de script de Bash | https://hdiconfigactions.blob.core.windows.net/linuxhueconfigactionv02/install-hue-uber-v02.sh |
| Tipos de nodo: | Head |
Ejecución de una consulta de Hive
En el portal de Hue, seleccione Query Editors (Editores de consultas), y, a continuación, seleccione Hive para abrir el editor de Hive.
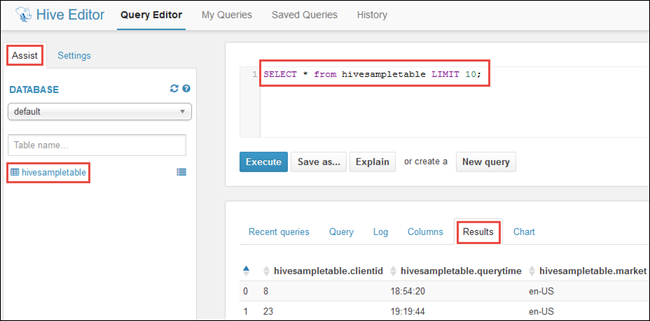
En la pestaña Assist (Asistencia), en Database (Base de datos), debería de ver hivesampletable. Se trata de una tabla de ejemplo que se incluye con todos los clústeres de Hadoop en HDInsight. Escriba una consulta de ejemplo en el panel derecho y vea el resultado en la pestaña Results (resultados) en el panel debajo, como se muestra en la captura de pantalla.
También puede usar la pestaña Chart para ver una representación visual del resultado.
Examinar el almacenamiento del clúster
En el portal de Hue, seleccione File Browser (explorador de archivos) en la esquina superior derecha de la barra de menús.
De forma predeterminada se abre el explorador de archivos en el directorio /user/myuser . Seleccione la barra oblicua que se encuentra antes del directorio del usuario en la ruta de acceso para ir a la raíz del contenedor de Azure Storage asociado con el clúster.
Haga clic con el botón derecho en un archivo o carpeta para ver las operaciones disponibles. Use el botón Cargar situado en la esquina derecha para cargar archivos en el directorio actual. Use el botón Nuevo para crear nuevos archivos o directorios.
Nota
El explorador de archivos de Hue solo puede mostrar el contenido del contenedor predeterminado asociado con el clúster de HDInsight. Cualquier cuenta o contenedor de almacenamiento adicional asociados con el clúster no serán accesibles mediante el explorador de archivos. Sin embargo, los contenedores adicionales asociados con el clúster siempre serán accesibles para los trabajos de Hive. Por ejemplo, si escribe el comando dfs -ls wasbs://newcontainer@mystore.blob.core.windows.net en el editor de Hive, también podrá ver el contenido de los contenedores adicionales. En este comando, newcontainer no es el contenedor predeterminado asociado a un clúster.
Consideraciones importantes
El script que se usó para instalar Hue lo instala solo en el nodo principal primario del clúster.
Durante la instalación, se reinician varios servicios de Hadoop (HDFS, YARN, MR2, Oozie) para actualizar la configuración. Cuando el script finaliza la instalación de Hue, puede tardar algún tiempo hasta que otros servicios de Hadoop se inicien. Esto podría afectar inicialmente al rendimiento de Hue. Una vez que todos los servicios se inician, la funcionalidad de Hue será total.
La matiz no entiende los trabajos de Apache Tez, que es el valor predeterminado actual de Hive. Si desea usar MapReduce como el motor de ejecución de Hive, actualice el script para usar el comando siguiente en el script:
set hive.execution.engine=mr;Con los clústeres de Linux, se puede dar el caso de que los servicios se ejecutan en el nodo principal primario mientras Resource Manager se ejecuta en el secundario. Este escenario podría producir errores (que se muestra a continuación) cuando se usa Hue para ver detalles de trabajos de ejecución en el clúster. De todas formas, puede ver los detalles del trabajo una vez que el trabajo se complete.
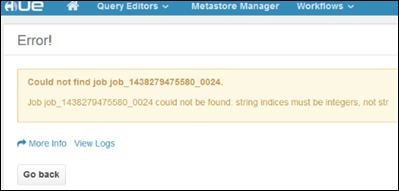
Este es un problema conocido. Como alternativa, modifique Ambari para que la instancia de Resource Manager que está activa también se ejecute en el nodo principal primario.
Hue entiende WebHDFS, mientras que los clústeres de HDInsight usan Azure Storage mediante
wasbs://. Por lo tanto, el script personalizado que se usa con la acción de script instala WebWasb, que es un servicio compatible con WebHDFS para hablar con WASB. Así que aunque el portal de Hue dice HDFS en lugares (como cuando se mueve el mouse sobre el Explorador de archivos), se debe interpretar como WASB.
Pasos siguientes
Personalización de clústeres de HDInsight con acciones de script