Usar las herramientas Spark y Hive para Visual Studio Code
Obtenga información sobre cómo usar las herramientas Apache Spark y Apache Hive para Visual Studio Code. Use las herramientas para crear y enviar trabajos por lotes de Apache Hive, consultas de Hive interactivas y scripts de PySpark para Apache Spark. Primero, describiremos cómo instalar las herramientas Spark y Hive en Visual Studio Code. A continuación, veremos cómo enviar trabajos a las herramientas Spark y Hive.
Las herramientas Spark y Hive se pueden instalar en todas las plataformas compatibles con Visual Studio Code. Observe los siguientes requisitos previos para las distintas plataformas.
Requisitos previos
Los elementos siguientes son necesarios para completar los pasos indicados en este artículo:
- Un clúster de HDInsight de Azure. Para crear un clúster, vea la introducción a HDInsight. O bien, use un clúster de Hive y Spark que admita un punto de conexión de Apache Livy.
- Visual Studio Code.
- Mono. Mono solo es obligatorio para Linux y macOS.
- Un entorno interactivo de PySpark para Visual Studio Code.
- Un directorio local. En este artículo se usa
C:\HD\HDexample.
Instalar Spark & Hive Tools
Después de completar los requisitos previos, puede instalar Spark & Hive Tools para Visual Studio Code siguiendo estos pasos:
Abra Visual Studio Code.
En la barra de menús, vaya a Ver>Extensiones.
En el cuadro de búsqueda, escriba Spark & Hive.
Seleccione Spark & Hive Tools en los resultados de búsqueda y seleccione Instalar:
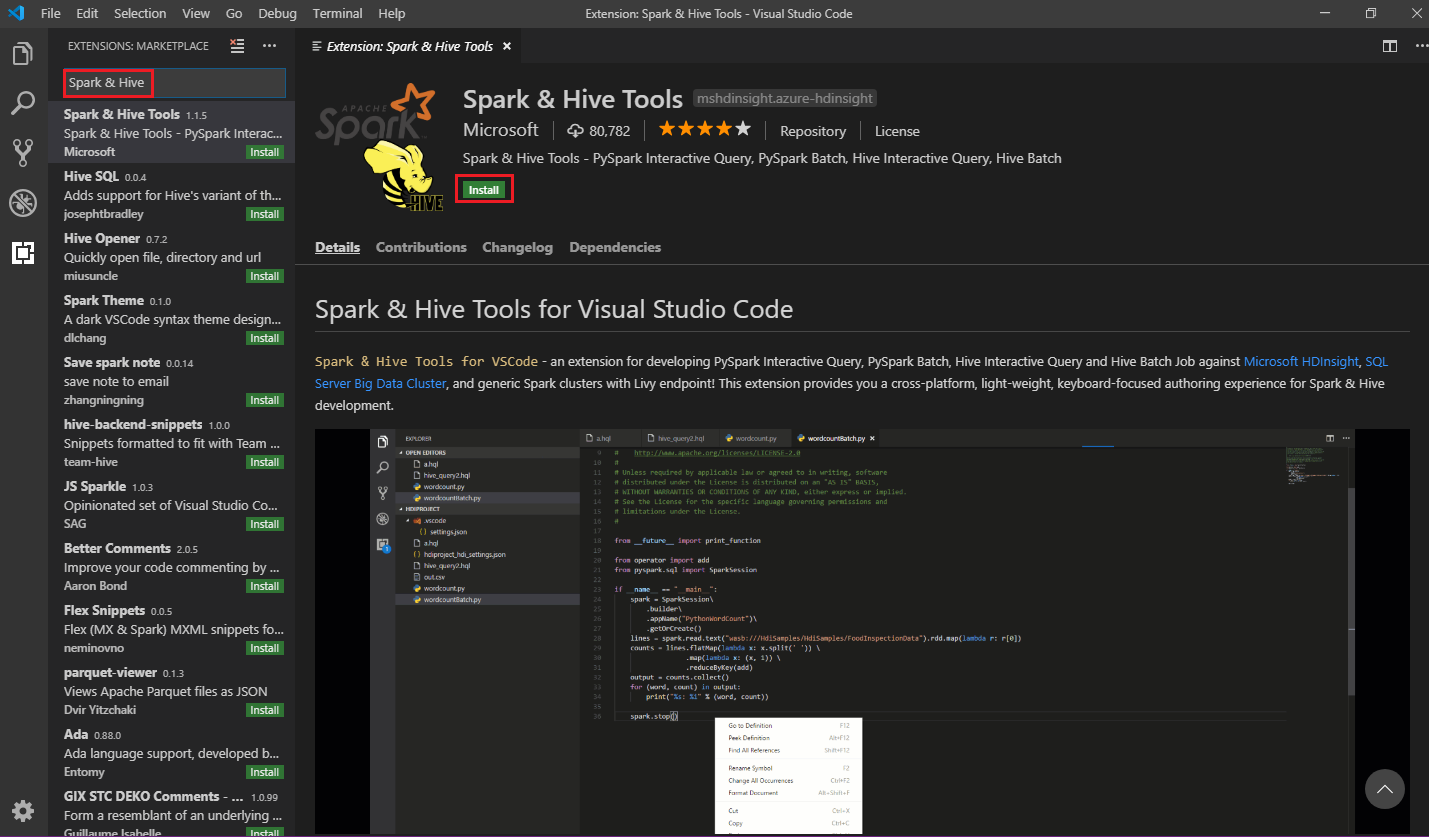
Seleccione Recargar cuando sea necesario.
Apertura de una carpeta de trabajo
Para abrir una carpeta de trabajo y crear un archivo en Visual Studio Code, siga estos pasos:
En la barra de menús, vaya a Archivo>Abrir carpeta...>
C:\HD\HDexampley seleccione el botón Seleccionar carpeta. La carpeta se mostrará en la vista Explorador de la parte izquierda.En la vista Explorador, seleccione la carpeta,
HDexampley luego seleccione el icono Nuevo archivo situado junto a la carpeta de trabajo: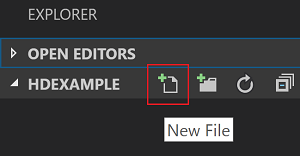
Asigne al nuevo archivo la extensión de archivo
.hql(consultas de Hive) o.py(script de Spark). En este ejemplo se utiliza HelloWorld.hql.
Establecimiento del entorno de Azure
Para usuarios de la nube nacional, siga los pasos para configurar el entorno de Azure en primer lugar y, a continuación, use el comando Azure: Sign In para iniciar sesión en Azure:
Vaya a Archivo>Preferencias>Configuración.
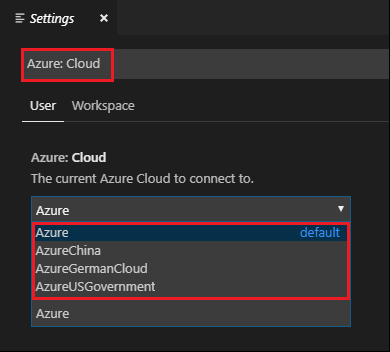
Busque la siguiente cadena: Azure: Cloud (Azure: nube).
Seleccione la nube nacional de la lista:
Conexión a la cuenta de Azure
Para poder enviar scripts a los clústeres desde Visual Studio Code, el usuario puede iniciar sesión en la suscripción de Azure o vincular un clúster de HDInsight. Use el nombre de usuario y la contraseña de Ambari o las credenciales del clúster ESP para conectarse al clúster de HDInsight. Siga estos pasos para conectarse a Azure:
En la barra de menús, vaya a Ver>Paleta de comandos... y escriba Azure: Sign In:
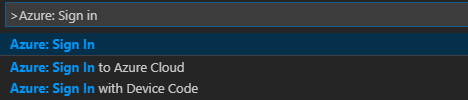
Siga las instrucciones para iniciar sesión en Azure. Una vez establecida la conexión, el nombre de la cuenta de Azure se muestra en la barra de estado en la parte inferior de la ventana de Visual Studio Code.
Vinculación de un clúster
Vínculo: HDInsight de Azure
Puede vincular un clúster normal mediante un nombre de usuario administrado de Apache Ambari o vincular un clúster de Hadoop de seguridad de Enterprise Security Pack mediante un nombre de usuario de dominio (como user1@contoso.com).
En la barra de menús, vaya a Ver>Paleta de comandos... y escriba Spark / Hive: Link a Cluster (vincular un clúster).

Seleccione el tipo de clúster vinculado Azure HDInsight.
Escriba la dirección URL del clúster de HDInsight.
Escriba el nombre de usuario de Ambari; el valor predeterminado es admin.
Escriba la contraseña de Ambari.
Seleccione el tipo de clúster.
Establezca el nombre para mostrar del clúster (opcional).
Revise la vista SALIDA.
Nota
Si el clúster se registró en la suscripción de Azure y se vinculó, se usan el nombre de usuario y la contraseña vinculados.
Vínculo: punto de conexión de Livy genérico
En la barra de menús, vaya a Ver>Paleta de comandos... y escriba Spark / Hive: Link a Cluster (vincular un clúster).
Seleccione el tipo de clúster vinculado Generic Livy Endpoint (Punto de conexión de Livy genérico).
Escriba el punto de conexión de Livy genérico. Por ejemplo: http://10.172.41.42:18080.
Seleccione el tipo de autorización Básica o Ninguna. Si selecciona Básico:
Escriba el nombre de usuario de Ambari; el valor predeterminado es admin.
Escriba la contraseña de Ambari.
Revise la vista SALIDA.
Lista de clústeres
En la barra de menús, vaya a Ver>Paleta de comandos... y escriba Spark / Hive: List Cluster (lista de clústeres).
Seleccione la suscripción que desea.
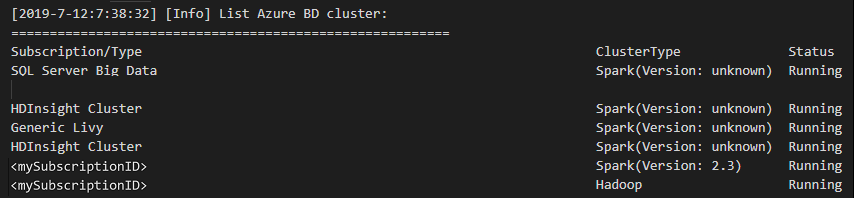
Revise la ventana de SALIDA. Esta vista muestra el clúster vinculado (o los clústeres vinculados) y todos los clústeres de su suscripción de Azure:
Establecimiento de clúster predeterminado
Vuelva a abrir la carpeta
HDexampleque se trató anteriormente, en caso de que esté cerrada.Seleccione el archivo HelloWorld.hql que se creó anteriormente. Se abre en el editor de scripts.
Haga clic con el botón derecho en el editor de scripts y, después, seleccione Spark / Hive: Set Default Cluster (establecer clúster predeterminado).
Conéctese a su cuenta de Azure o vincule un clúster si no lo ha hecho aún.
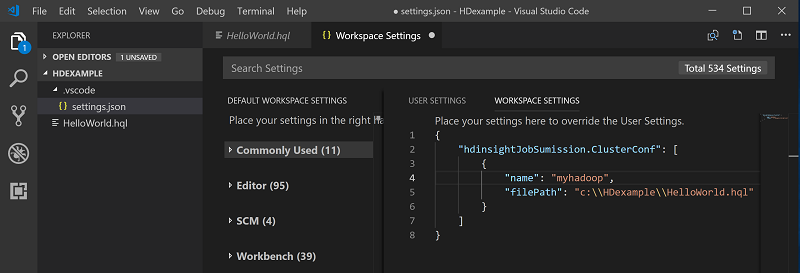
Seleccione un clúster como el clúster predeterminado para el archivo de script actual. Las herramientas actualizan automáticamente el archivo de configuración .VSCode\settings.json:
Envío de consultas de Hive interactivas y scripts por lotes de Hive
Con Spark & Hive Tools para Visual Studio Code, puede enviar consultas de Hive interactivas y scripts por lotes de Hive a sus clústeres.
Vuelva a abrir la carpeta
HDexampleque se trató anteriormente, en caso de que esté cerrada.Seleccione el archivo HelloWorld.hql que se creó anteriormente. Se abre en el editor de scripts.
Copie y pegue el código siguiente en el archivo de Hive y guárdelo:
SELECT * FROM hivesampletable;Conéctese a su cuenta de Azure o vincule un clúster si no lo ha hecho aún.
Haga clic con el botón derecho en el editor de scripts y seleccione Hive: Interactive (Hive: Interactivo) para enviar la consulta, o bien use el acceso directo Ctrl+Alt +I. Seleccione Hive: Batch (Hive: Lote) para enviar la consulta, o bien use el acceso directo Ctrl+Alt+H.
Seleccione el clúster si no ha especificado un clúster predeterminado. Las herramientas también permiten enviar un bloque de código en lugar del archivo de script completo mediante el menú contextual. Transcurridos unos instantes, los resultados de la consulta aparecen en una pestaña nueva:
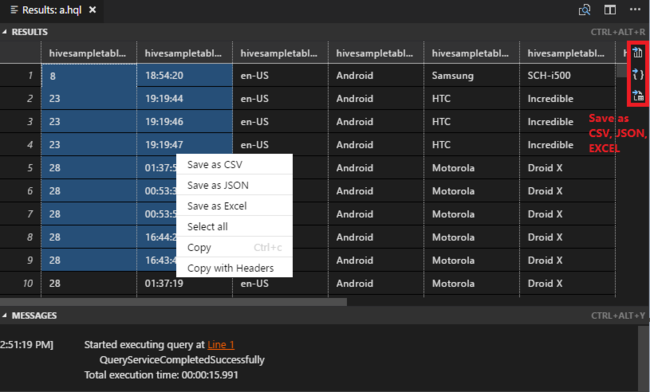
Panel RESULTADOS: Puede guardar todo el resultado en forma de archivo CSV, JSON o de Excel en una ruta de acceso local, o bien seleccionar únicamente varias líneas.
Panel MENSAJES: Al seleccionar el número de Línea, se salta a la primera línea del script en ejecución.
Enviar consultas de PySpark interactivas
Requisito previo para PySpark interactivo
Observe que la versión de la extensión de Jupyter (ms-jupyter): v2022.1.1001614873, y la versión de la extensión de Python (ms-python): v2021.12.1559732655, python 3.6.x y 3.7.x son necesarias para las consultas de PySpark interactivas de HDInsight.
Los usuarios pueden ejecutar PySpark Interactive de las siguientes maneras.
Con el comando de PySpark Interactive en el archivo PY
Para usar el comando de PySpark Interactive con el fin de enviar las consultas, siga estos pasos:
Vuelva a abrir la carpeta
HDexampleque se trató anteriormente, en caso de que esté cerrada.Cree un nuevo archivo HelloWorld.py siguiendo los pasos anteriores.
Copie y pegue el código siguiente en el archivo de script:
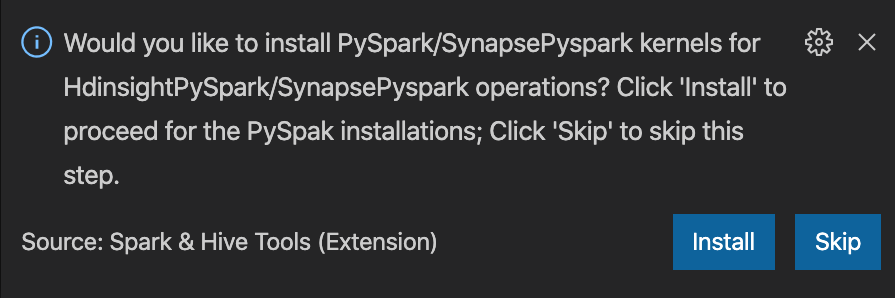
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])El mensaje para instalar el kernel de PySpark/Synapse Pyspark se muestra en la esquina inferior derecha de la ventana. Puede hacer clic en el botón Instalar para continuar con las instalaciones de Pyspark o Synaps PySpark, o bien hacer clic en el botón Omitir para omitir este paso.
Si tiene que instalarlo más adelante, puede ir a Archivo>Preferencia>Configuración y desactivar HDInsight: Enable Skip Pyspark Installation (Habilitar Omitir la instalación de Pyspark) en las opciones.
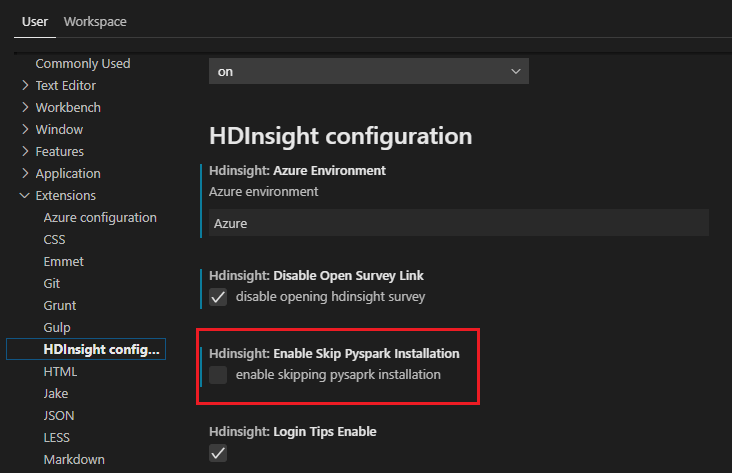
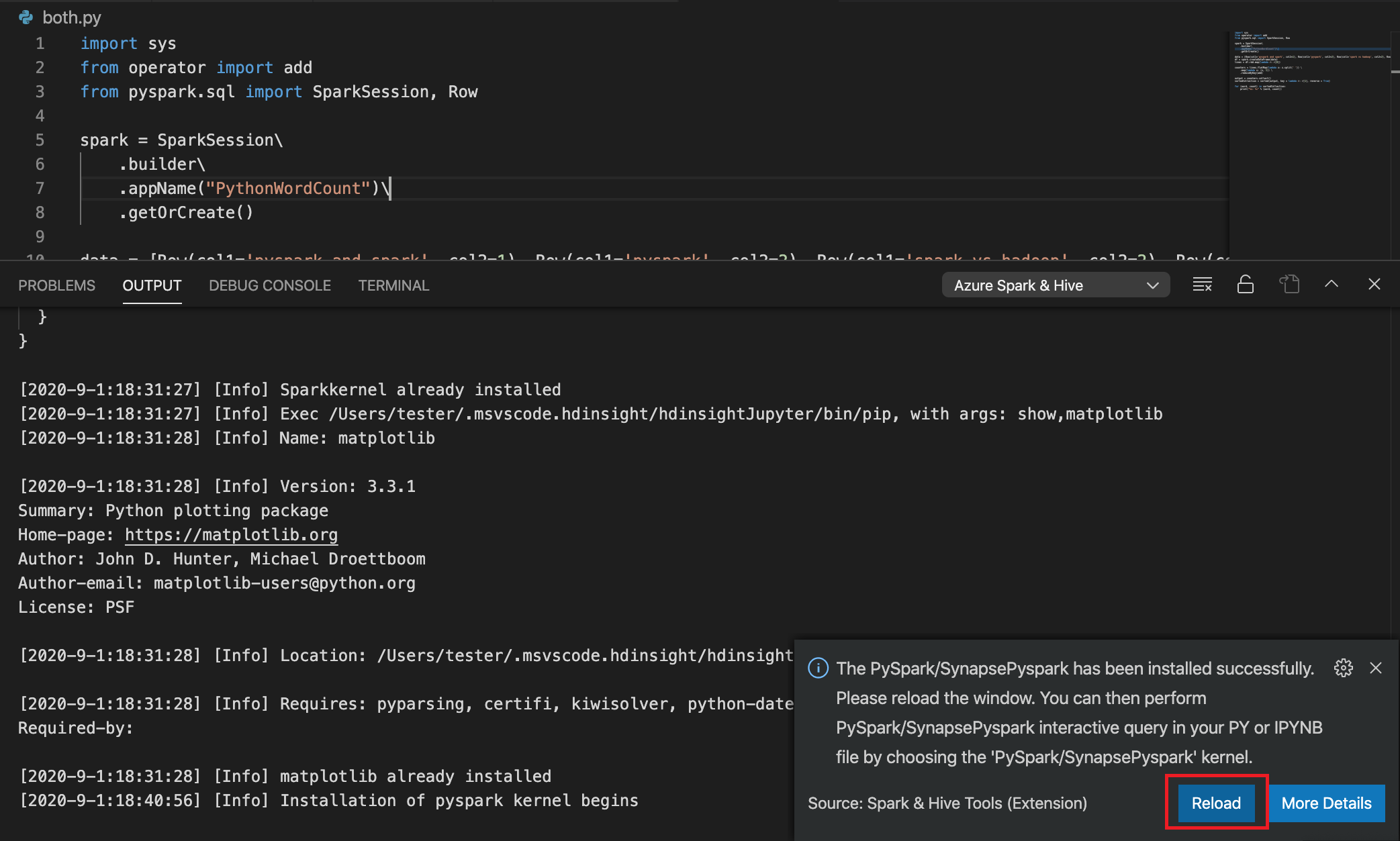
Si la instalación se realiza correctamente en el paso 4, el cuadro de mensaje "PySpark installed succesfully" (PySpark se instaló correctamente) se muestra en la esquina inferior derecha de la ventana. Haga clic en botón Reload (Recargar) para volver a cargar la ventana.
En la barra de menús, vaya a View (Ver) >Command Palette (Paleta de comandos) o use el método abreviado de teclado Mayús + Ctrl + P y escriba Python: Seleccione Interpreter (Intérprete) para iniciar el servidor de Jupyter.

Seleccione la opción de Python que aparece a continuación.

En la barra de menús, vaya a View(Ver)>Command Palette (Paleta de comandos) o use el método abreviado de teclado Mayús + Ctrl + P y escriba Desarrollador: Recargar ventana.

Conéctese a su cuenta de Azure o vincule un clúster si no lo ha hecho aún.
Seleccione todo el código, haga clic con el botón derecho en el editor de scripts y seleccione Spark: PySpark Interactive/Synapse: Pyspark Interactive para enviar la consulta.
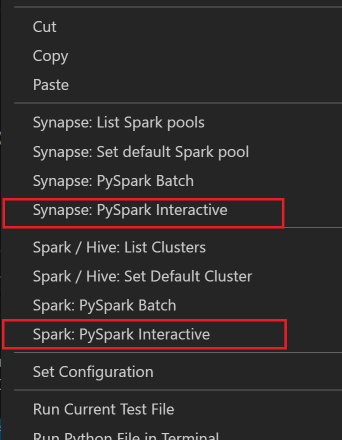
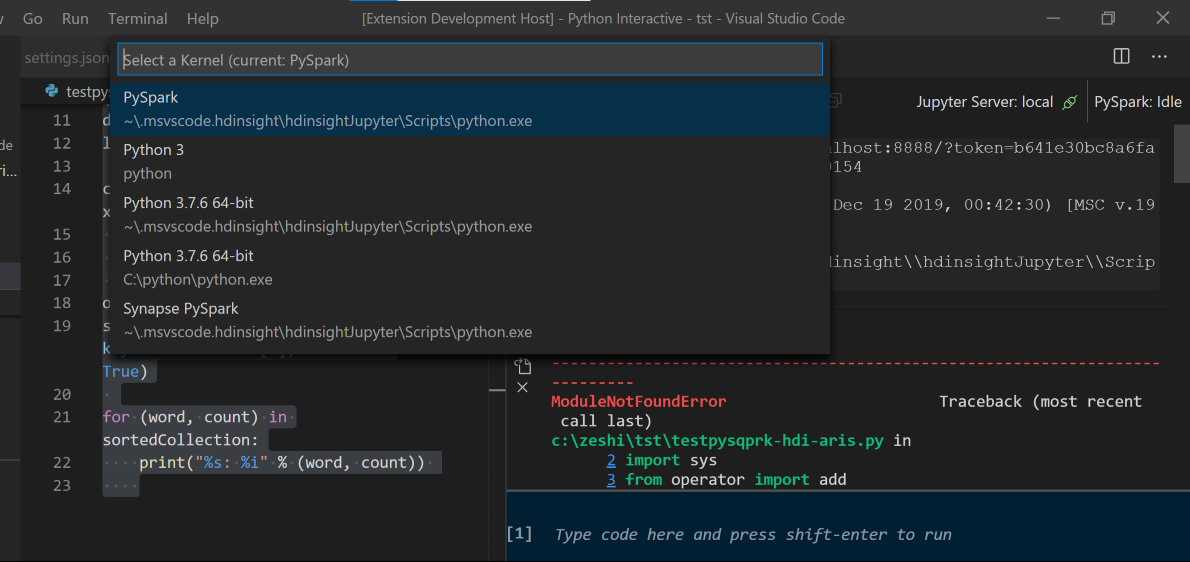
Seleccione el clúster si no ha especificado un clúster predeterminado. En un momento, los resultados de Python Interactive se mostrarán en una pestaña nueva. Haga clic en PySpark para cambiar el kernel a PySpark/Synapse Pyspark y así el código se ejecuta correctamente. Si se quiere cambiar al kernel de Synapse Pyspark, se recomienda deshabilitar la configuración automática en Azure Portal. En caso contrario, es posible que se tarde mucho tiempo en reactivar el clúster y establecer el kernel de Synapse para el primer uso. Si las herramientas también permiten enviar un bloque de código en lugar del archivo de script completo mediante el menú contextual:
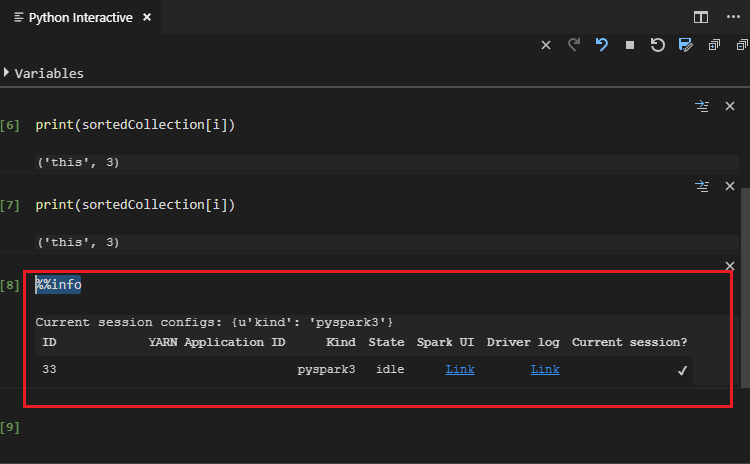
Escriba %%info y presione Mayús+Entrar para ver información sobre el trabajo (opcional):
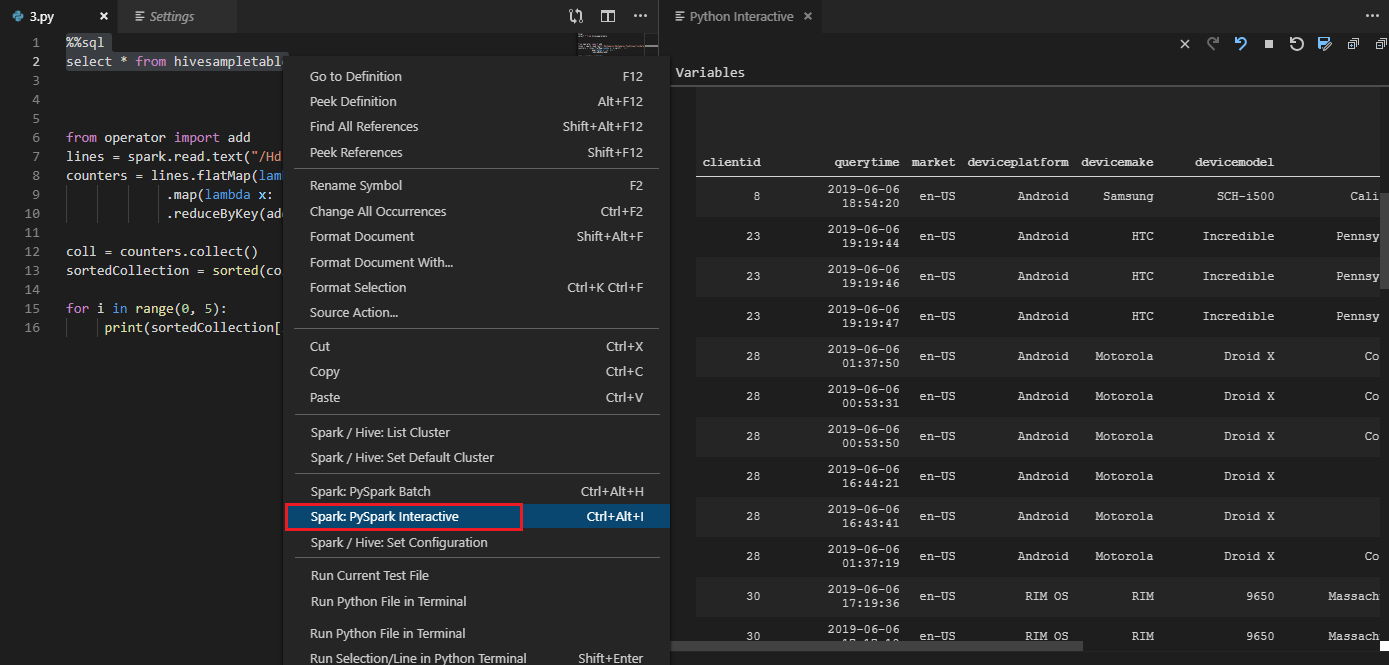
La herramienta también admite la consulta Spark SQL:
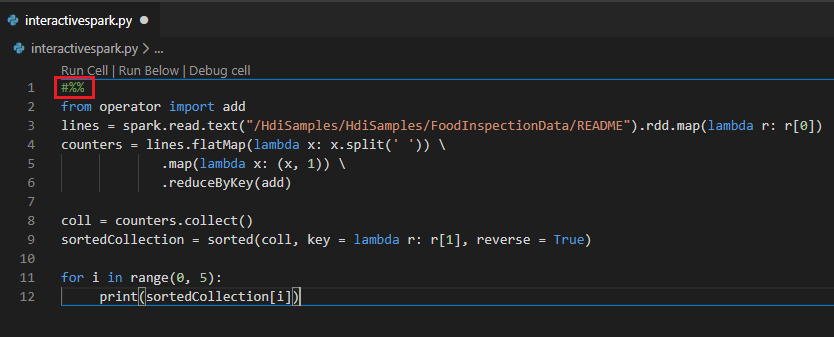
Consulta interactiva en el archivo PY con un comentario #%%
Agregue #%% antes del código de Py para obtener la experiencia del cuaderno.
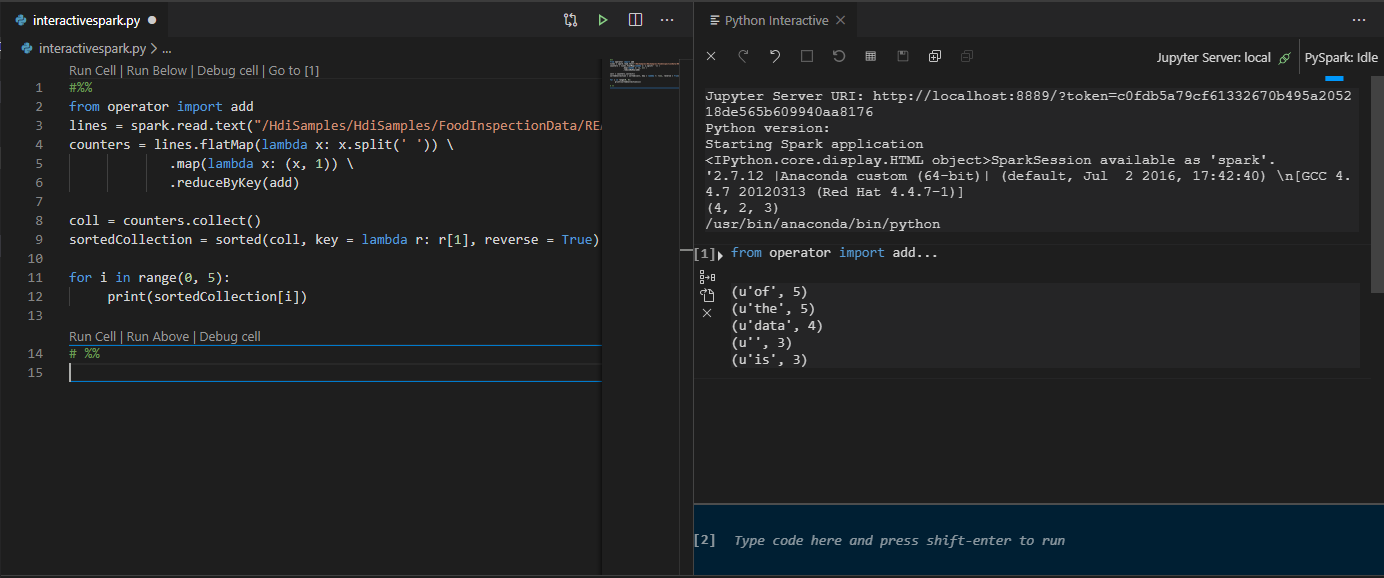
Haga clic en Run Cell (Ejecutar celda). En un momento, los resultados de Python Interactive se mostrarán en una pestaña nueva. Haga clic en PySpark para cambiar el kernel a PySpark/Synapse PySpark y luego vuelva a hacer clic en Ejecutar celda para que el código se ejecute correctamente.
Aprovechar la compatibilidad con IPYNB de la extensión de Python
Puede crear un comando de Jupyter Notebook en la paleta de comandos o mediante la creación de un nuevo archivo
.ipynben el área de trabajo. Para más información, consulte Trabajo con cuadernos de Jupyter Notebook en Visual Studio Code.Haga clic en el botón Run cell (Ejecutar celda), siga las indicaciones para Set the default spark pool (Establecer el grupo de Spark predeterminado) (se recomienda establecer el grupo o clúster predeterminado cada vez antes de abrir un cuaderno) y, luego, haga clic en Reload para volver a cargar la ventana.
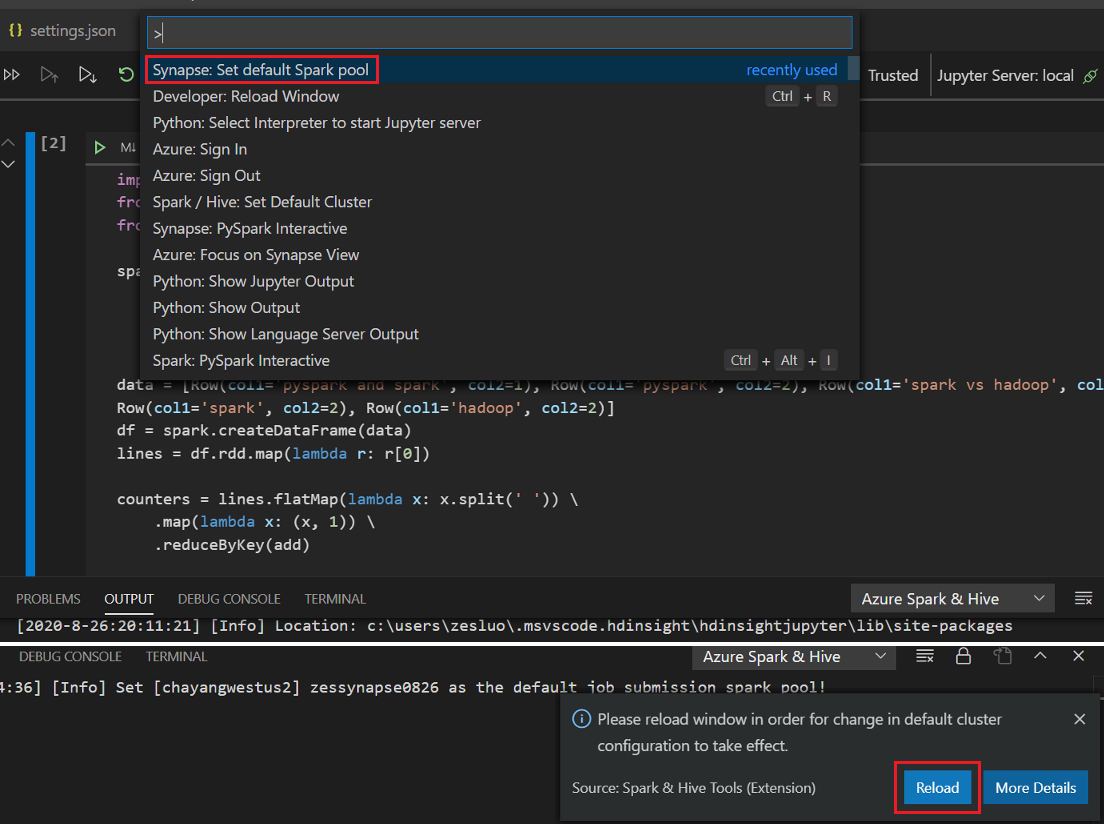
Haga clic en PySpark para cambiar el kernel a PySpark/Synapse Pyspark y luego haga clic en Ejecutar celda; al cabo de un momento se muestra el resultado.
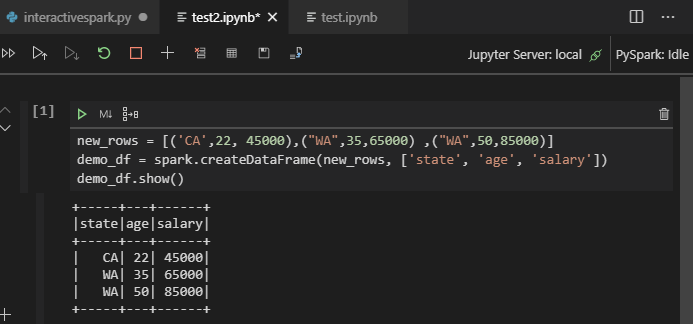
Nota:
En caso de error de instalación de Synapse PySpark, dado que otro equipo ya no conservará su dependencia, esto ya no se mantendrá. Si intenta usar Synapse Pyspark interactivo, utilice Azure Synapse Analytics en su lugar. Se trata de un cambio a largo plazo.
Enviar trabajo por lotes de PySpark
Vuelva a abrir la carpeta
HDexampleque se trató anteriormente, en caso de que esté cerrada.Cree un nuevo archivo BatchFile.py siguiendo los pasos anteriores.
Copie y pegue el código siguiente en el archivo de script:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Conéctese a su cuenta de Azure o vincule un clúster si no lo ha hecho aún.
Haga clic con el botón derecho en el editor de scripts y seleccione Spark: PySpark Batch(Spark: lote de PySpark) o Synapse: PySpark Batch (Synapse: lote de PySpark)*.
Seleccione un clúster o grupo de Spark para enviar el trabajo de PySpark a:
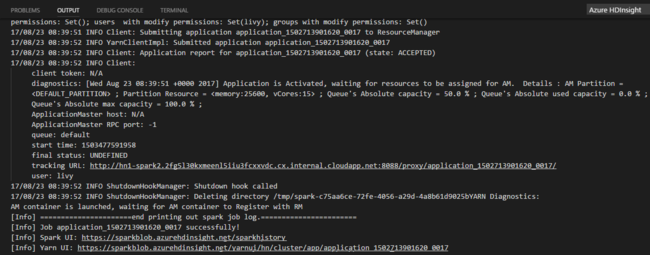
Después de enviar trabajo de Python, los registros de envío se muestran en la ventana de SALIDA en Visual Studio Code. También se muestran la dirección URL de interfaz de usuario de Spark y la dirección URL de interfaz de usuario de Yarn. Si envía el trabajo por lotes a un grupo de Apache Spark, también se muestran la dirección URL de la interfaz de usuario del historial de Spark y la dirección URL de la interfaz de usuario de la aplicación de trabajo de Spark. Para realizar un seguimiento del estado del trabajo, puede abrir la URL en un explorador web.
Integración con HDInsight Identity Broker (HIB)
Conexión al clúster de HDInsight ESP con el agente de HDInsight Identity Broker (HIB)
Puede seguir los pasos normales para iniciar sesión en la suscripción de Azure para conectarse a su clúster de HDInsight ESP con el agente de HDInsight Identity Broker (HIB). Después de iniciar sesión, verá la lista de clústeres en Azure Explorer. Para conocer más instrucciones, consulte Conexión al clúster de HDInsight.
Ejecución de un trabajo de Hive/PySpark en un clúster de HDInsight ESP con el agente de identidad (HIB)
Para ejecutar un trabajo de Hive, puede seguir los pasos normales para enviar el trabajo a un clúster de HDInsight ESP con el agente de identidad (HIB). Consulte Envío de consultas de Hive interactivas y scripts por lotes de Hive para más instrucciones.
Para ejecutar un trabajo de PySpark interactivo, puede seguir los pasos normales para enviar el trabajo a un clúster de HDInsight ESP con el agente de identidad (HIB). Consulte Envío de consultas interactivas de PySpark.
Para ejecutar un trabajo por lotes de PySpark, puede seguir los pasos normales para enviar el trabajo a un clúster de HDInsight ESP con el agente de identidad (HIB). Consulte Enviar trabajo por lotes de PySpark para obtener más instrucciones.
Configuración de Apache Livy
La configuración de Apache Livy es compatible. Puede configurarla en el archivo .VSCode\settings.json en la carpeta del área de trabajo. En la actualidad, la configuración de Livy solo admite el script de Python. Para más información, vea el LÉAME de Livy.
Cómo activar la configuración de Livy
Método 1
- En la barra de menús, vaya a Archivo>Preferencias>Configuración.
- En el cuadro de texto Configuración de la búsqueda escriba HDInsight Job Submission: configuración de Livy.
- Seleccione Editar en settings.json para el resultado de la búsqueda relevante.
Método 2
Envíe un archivo y observe que la carpeta .vscode se agrega automáticamente a la carpeta de trabajo. Puede encontrar la configuración de Livy si selecciona .vscode\settings.json.
Configuración del proyecto:
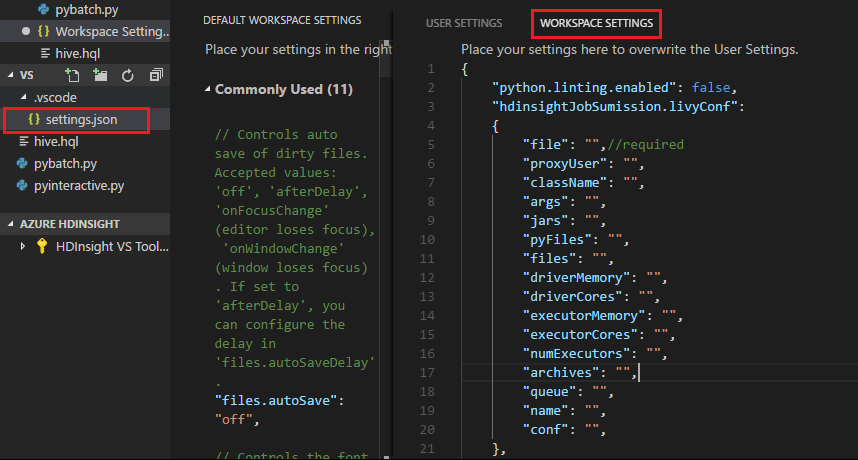
Nota:
Para la configuración de driverMemory y executorMemory, establezca el valor y la unidad. Por ejemplo: 1g o 1024m.
Configuraciones de Livy admitidas:
POST /batches
Cuerpo de la solicitud
name description type archivo Archivo que contiene la aplicación que se ejecutará Ruta (obligatorio) proxyUser Usuario que se suplantará al ejecutar el trabajo String className Clase principal de Java/Spark de la aplicación String args Argumentos de la línea de comandos para la aplicación Lista de cadenas jars Archivos JAR que se usarán en esta sesión Lista de cadenas pyFiles Archivos de Python que se usarán en esta sesión Lista de cadenas files Archivos que se usarán en esta sesión Lista de cadenas driverMemory Cantidad de memoria que se usará para el proceso del controlador String driverCores Número de núcleos que se usarán para el proceso del controlador Int executorMemory Cantidad de memoria que se usará por proceso de ejecutor String executorCores Número de núcleos que se usará para cada ejecutor Int numExecutors Número de ejecutores que se iniciarán para esta sesión Int archives Archivos que se usarán en esta sesión Lista de cadenas cola El nombre de la cola YARN a la que se enviará String name Nombre de esta sesión String conf Propiedades de configuración de Spark Mapa de clave=valor Cuerpo de respuesta El objeto Batch creado.
name description type ID Identificador de sesión Int appId Id. de aplicación de esta sesión String appInfo Información detallada de la aplicación Mapa de clave=valor log Líneas de registro Lista de cadenas state Estado del lote String Nota:
La configuración de Livy asignada se muestra en el panel de salida al enviar el script.
Integración con Azure HDInsight desde el explorador
Puede obtener una vista previa de la tabla de Hive directamente en los clústeres a través del explorador de Azure HDInsight:
Conéctese a su cuenta de Azure si no lo ha hecho aún.
Seleccione el icono Azure de la columna situada en el extremo izquierdo.
En el panel izquierdo, expanda AZURE: HDINSIGHT. Aparecen las suscripciones y clústeres disponibles.
Expanda el clúster para ver el esquema de base de datos y tablas de metadatos de Hive.
Haga clic con el botón derecho en la tabla de Hive. Por ejemplo: hivesampletable. Seleccione Vista previa.
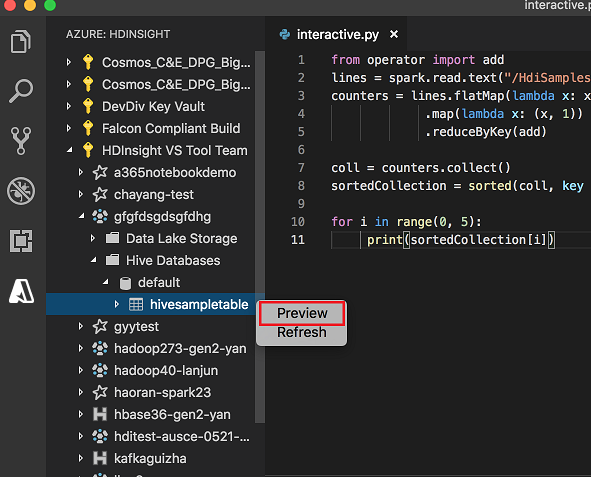
Se abre la ventana Vista previa de resultados:
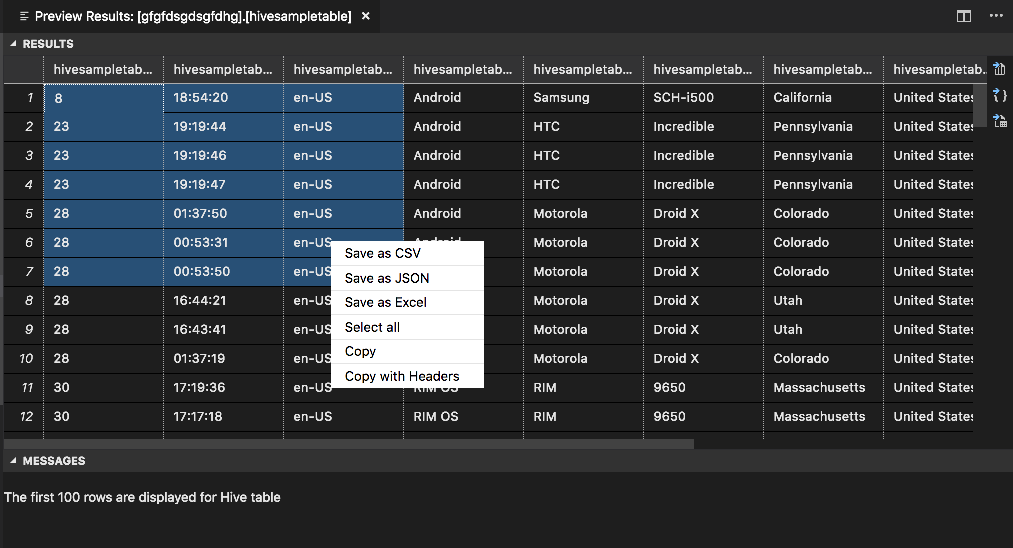
Panel RESULTADOS
Puede guardar todo el resultado en forma de archivo CSV, JSON o Excel en una ruta de acceso local, o bien seleccionar únicamente varias líneas.
Panel MENSAJES
Cuando el número de filas de la tabla es superior a 100, aparece un mensaje que informa de que se muestran las 100 primeras filas de la tabla de Hive.
Cuando el número de filas de la tabla es menor o igual a 100, aparece el siguiente mensaje: se muestran 60 filas de la tabla de Hive.
Cuando no haya contenido en la tabla, verá el siguiente mensaje: "
0 rows are displayed for Hive table."Nota
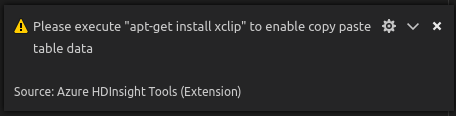
En Linux, instale xclip para permitir la copia de datos de tabla.
Funciones adicionales
Hive y Spark para Visual Studio Code admite también las siguientes características:
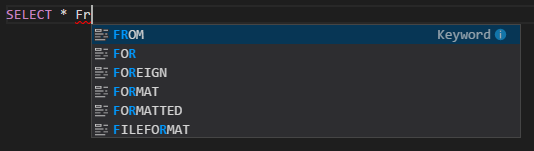
Autocompletar de IntelliSense. Aparecen sugerencias para palabras clave, métodos, variables y otros elementos de programación. Los distintos iconos representan diferentes tipos de objetos:
Marcador de error de IntelliSense. El servicio de lenguaje subraya los errores de edición del script de Hive.
Sintaxis resaltada. El servicio de lenguaje usa colores diferentes para diferenciar variables, palabras clave, tipos de datos, funciones y otros elementos de programación:
Rol de solo lectura
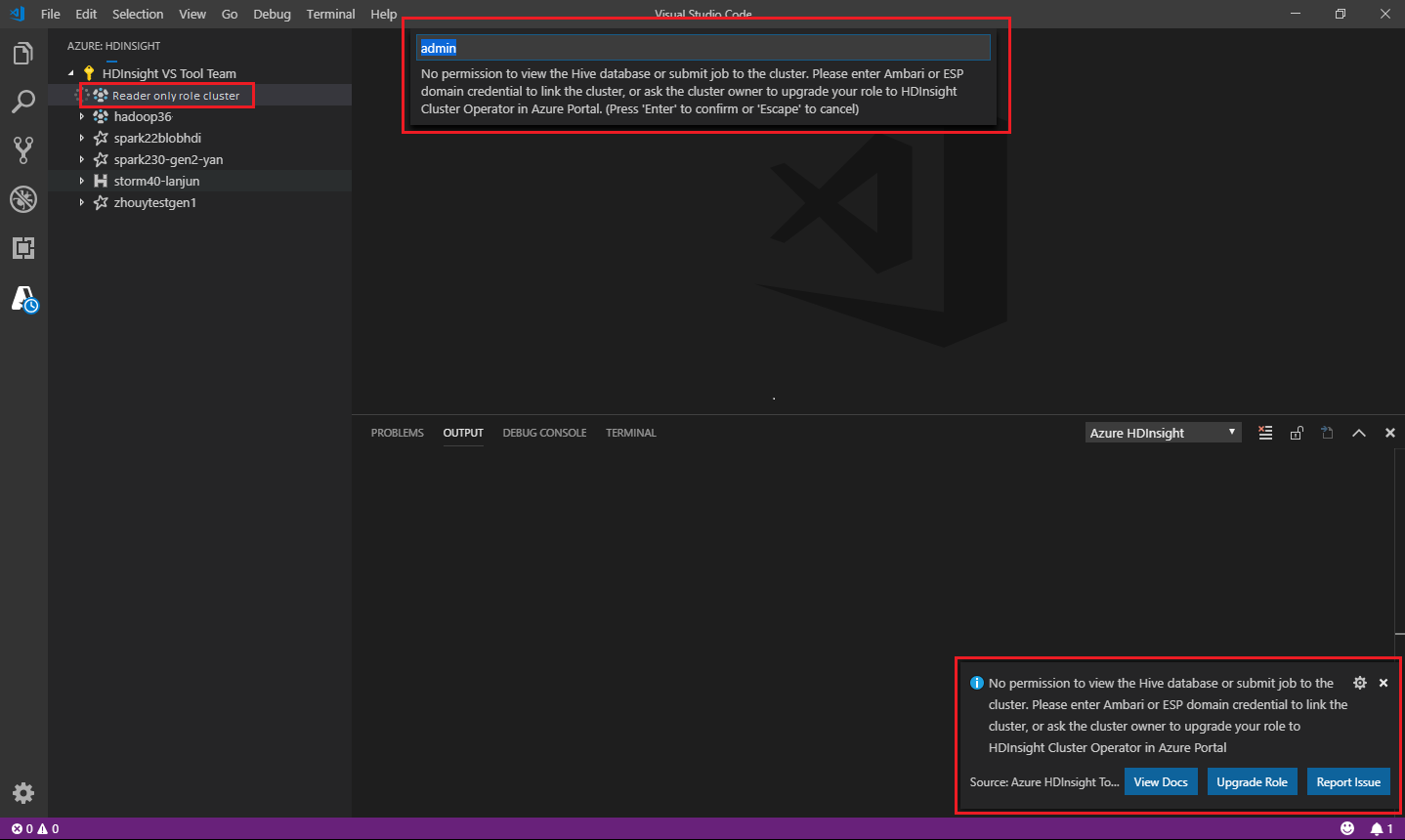
Los usuarios a los que se haya asignado el rol de solo lector para el clúster ya no pueden enviar trabajos al clúster de HDInsight ni pueden ver la base de datos de Hive. Póngase en contacto con el administrador de clústeres para actualizar el rol a operador de clústeres de HDInsight en Azure Portal. Si tiene credenciales de Ambari válidas, puede vincular manualmente el clúster siguiendo estas instrucciones.
Examen del clúster de HDInsight
Al seleccionar el explorador de Azure HDInsight para expandir un clúster de HDInsight, se le pedirá que vincule el clúster si tiene el rol de solo lector en el clúster. Use el método siguiente para vincular al clúster con sus credenciales de Ambari.
Envío del trabajo al clúster de HDInsight
Al enviar un trabajo al clúster de HDInsight, se le pide que vincule el clúster si tiene el rol de solo lector en el clúster. Siga estos pasos para vincular al clúster con sus credenciales de Ambari.
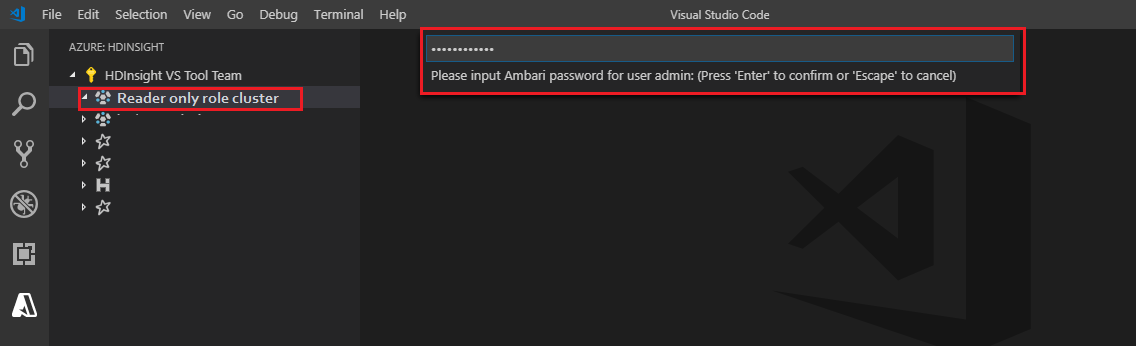
Vínculo al clúster
Escriba un nombre de usuario de Ambari válido.
Escriba una contraseña válida.
Nota:
Puede usar
Spark / Hive: List Clusterpara comprobar el clúster vinculado:
Azure Data Lake Storage Gen2
Examen de una cuenta de Data Lake Storage Gen2
Seleccione el explorador de Azure HDInsight para expandir una cuenta de Data Lake Storage Gen2. Se le pedirá que especifique la clave de acceso de almacenamiento si su cuenta de Azure no tiene acceso al almacenamiento de Gen2. Una vez validada la clave de acceso, la cuenta de Data Lake Storage Gen2 se expande automáticamente.
Envío de trabajos a un clúster de HDInsight con Data Lake Storage Gen2
Envíe un trabajo a un clúster de HDInsight con Data Lake Storage Gen2. Se le pedirá que especifique la clave de acceso de almacenamiento si su cuenta de Azure no tiene acceso de escritura al almacenamiento de Gen2. El trabajo se enviará sin problemas una vez validada correctamente la clave de acceso.

Nota:
Puede obtener la clave de acceso de la cuenta de almacenamiento desde Azure Portal. Para más información, consulte Administración de las claves de acceso de la cuenta de almacenamiento.
Desvincular clúster
En la barra de menús, vaya a Vista>Paleta de comandos y escriba Spark / Hive: desvincular un clúster.
Seleccione el clúster que desea desvincular.
Revise la vista SALIDA para comprobarlo todo.
Cerrar sesión
En la barra de menús, vaya a Vista>Paleta de comandos y escriba Azure: Sign Out (Cerrar sesión).
Problemas conocidos
Error de instalación de Synapse PySpark.
En caso de error de instalación de Synapse PySpark, dado que otro equipo ya no conservará su dependencia, esto ya no se mantendrá. Si intenta usar Synapse Pyspark interactivo, utilice Azure Synapse Analytics en su lugar. Se trata de un cambio a largo plazo.
Pasos siguientes
Para ver un vídeo de demostración del uso de Spark y Hive para Visual Studio Code, consulte Spark y Hive para Visual Studio Code.