Conectarse a Azure HDInsight y ejecutar consultas de Apache Hive con Herramientas de Data Lake para Visual Studio
Obtenga información sobre cómo usar Herramientas de Microsoft Azure Data Lake y Stream Analytics para Visual Studio (Herramientas de Data Lake). Use la herramienta para conectarse a los clústeres de Apache Hadoop en Azure HDInsight y envíe las consultas de Hive.
Para obtener más información sobre cómo usar HDInsight, consulte Introducción a HDInsight.
Data Lake Tools para Visual Studio se puede utilizar para acceder a Azure Data Lake Analytics y a HDInsight. Para más información acerca de Data Lake Tools, consulte Desarrollo de scripts U-SQL mediante Data Lake Tools para Visual Studio.
Prerrequisitos
Para completar este artículo y usar Herramientas de Data Lake para Visual Studio, se necesitan los siguientes elementos:
Un clúster de HDInsight de Azure. Para crear un clúster de HDInsight, consulte Introducción a Apache Hadoop en Azure HDInsight. Para ejecutar consultas interactivas de Apache Hive, necesita un clúster de HDInsight Interactive Query.
Visual Studio. La edición Visual Studio Community es gratuita. Las instrucciones que se muestran aquí se aplican a Visual Studio 2019.
Instalación de Data Lake Tools para Visual Studio
Siga las instrucciones adecuadas para instalar la versión que necesita de Herramientas de Data Lake para Visual Studio:
Para Visual Studio 2017 o Visual Studio 2019:
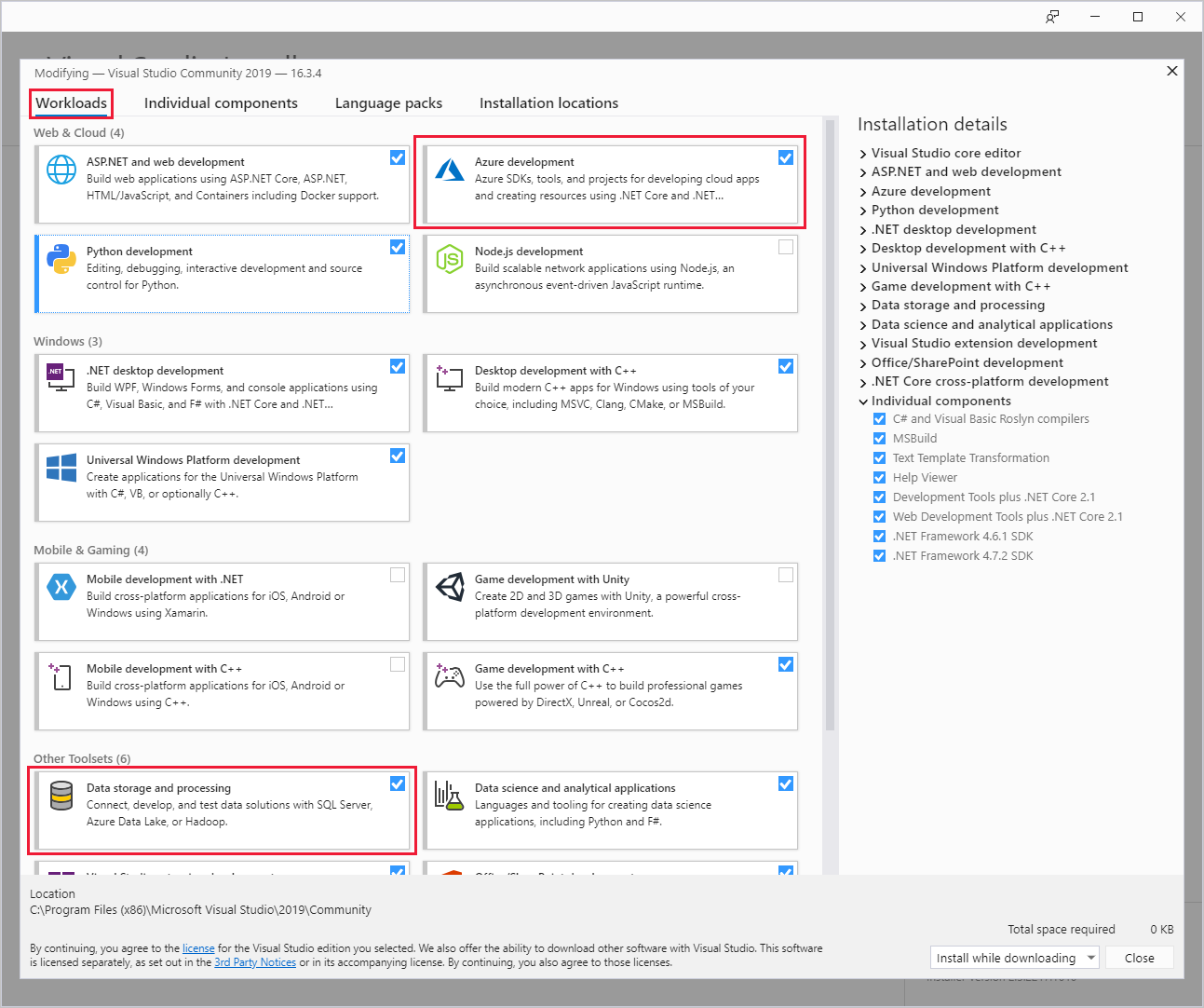
Durante la instalación de Visual Studio, asegúrese de incluir la carga de trabajo Desarrollo de Azure o la carga de trabajo de Almacenamiento y procesamiento de datos.
Para las instalaciones existentes de Visual Studio, vaya a la barra de menús del IDE y seleccione Herramientas>Obtener herramientas y características para abrir el Instalador de Visual Studio. En la pestaña Cargas de trabajo, seleccione al menos la carga de trabajo Desarrollo de Azure (en Web y nube). O bien, seleccione la carga de trabajo Almacenamiento y procesamiento de datos (en Otros conjuntos de herramientas).
Para Visual Studio 2015:
Descargue Herramientas de Data Lake. Elija la versión de Data Lake Tools que coincida con su versión de Visual Studio.
Actualización de Herramientas de Data Lake para Visual Studio
Después, asegúrese de actualizar Herramientas de Data Lake a la versión más reciente.
Abra Visual Studio.
En la ventana de inicio, seleccione Continuar sin código.
En la barra de menús del IDE de Visual Studio, elija Extensiones>Administrar extensiones.
En el cuadro de diálogo Administrar extensiones, expanda el nodo Actualizaciones.
Si la lista de actualizaciones disponibles incluye Herramientas de Azure Data Lake y Stream Analytics, selecciónela. A continuación, haga clic en el botón Actualizar. Después de que aparezca y desaparezca el cuadro de diálogo Descargar e instalar, Visual Studio agregará la extensión Herramientas de Azure Data Lake y Stream Analytics a la programación de actualizaciones.
Cierre todas las ventanas de Visual Studio. Aparecerá el cuadro de diálogo Instalador de VSIX.
Seleccione Licencia para leer los términos de la licencia y, a continuación, seleccione Cerrar para volver al cuadro de diálogo Instalador de VSIX.
Seleccione Modificar. Comienza la instalación de la actualización de la extensión. Pasado un tiempo, el cuadro de diálogo cambia para mostrar que ha terminado de realizar modificaciones. Seleccione Cerrar y, luego, reinicie Visual Studio para completar la instalación.
Nota
Puede utilizar solo Data Lake Tools, versión 2.3.0.0 o posterior, para conectarse a clústeres de Interactive Query y ejecutar consultas de Hive interactivas.
Conexión a suscripciones de Azure
Herramientas de Data Lake para Visual Studio se puede usar para conectarse a clústeres de HDInsight, realizar algunas operaciones básicas de administración y ejecutar consultas de Hive.
Nota
Para más información acerca de cómo conectarse a un clúster de Hadoop genérico, consulte Cómo escribir y enviar consultas de Hive mediante Visual Studio.
Conexión a una suscripción de Azure
Para conectarse a su suscripción de Azure:
Abra Visual Studio.
En la ventana de inicio, seleccione Continuar sin código.
En la barra de menús del IDE, vaya a Ver>Explorador de servidores.
En el Explorador de servidores, haga clic con el botón derecho en Azure, seleccione Conectar a la suscripción de Microsoft Azure y complete el proceso de autenticación. En el Explorador de servidores, expanda Azure>HDInsight para ver una lista de los clústeres de HDInsight existentes.
Si no tiene ningún clúster, cree uno mediante Azure Portal, Azure PowerShell o el SDK de HDInsight. Para obtener más información, consulte Configuración de clústeres en HDInsight.
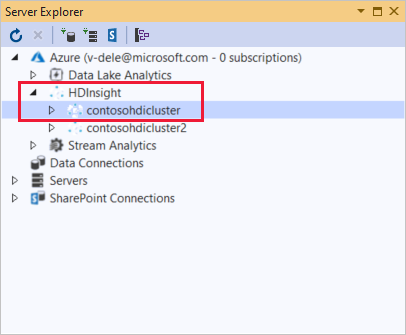
Expanda un clúster de HDInsight. El clúster contiene nodos para Bases de datos de Hive. También una cuenta de almacenamiento predeterminada, cuentas de almacenamiento vinculadas adicionales y un registro del servicio Hadoop. Puede expandir las entidades.
Una vez conectado a su suscripción de Azure, puede realizar las siguientes tareas.
Conexión a Azure desde Visual Studio
Para conectarse a Azure Portal desde Visual Studio:
En el Explorador de servidores, expanda Azure>HDInsight y seleccione el clúster.
Haga clic con el botón derecho en un clúster de HDInsight y seleccione Administrar clústeres en Azure Portal.
Preguntas y comentarios desde Visual Studio
Para hacer preguntas y realizar comentarios desde Visual Studio:
En el Explorador de servidores, seleccione Azure>HDInsight.
Haga clic con el botón derecho en HDInsight y seleccione Foro de MSDN para formular preguntas, o bien Enviar comentarios para aportar sus comentarios.
Vinculación o edición de clústeres
Nota
Actualmente, el único tipo de clúster de HDInsight al que se puede vincular es un tipo Hive.
Para vincular un clúster de HDInsight:
Haga clic con el botón derecho en HDInsight y, después, seleccione Vincular un clúster de HDInsight para mostrar el cuadro de diálogo Vincular un clúster de HDInsight.
Escriba una dirección URL de conexión con el formato
https://CLUSTERNAME.azurehdinsight.net. El nombre del clúster se rellena automáticamente con la parte del nombre del clúster de su dirección URL cuando se desplaza a otro campo. Escriba un nombre de usuario y una contraseña y seleccione Siguiente.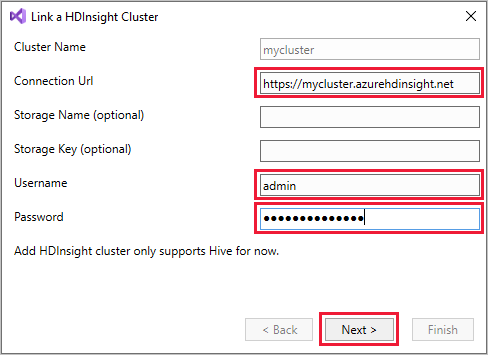
Seleccione Finalizar. Si la vinculación del clúster se realiza correctamente, el clúster se muestra en el nodo HDInsight.
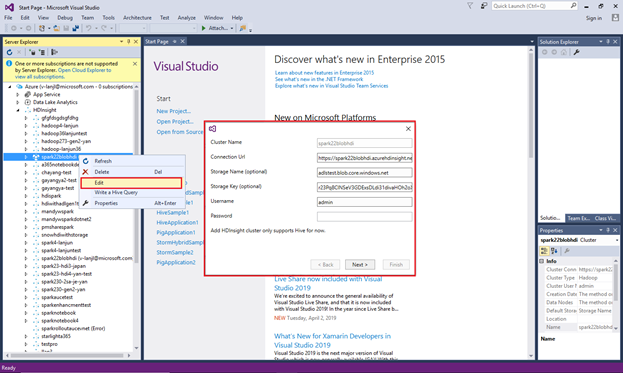
Para actualizar un clúster vinculado, haga clic con el botón derecho en el clúster y seleccione Editar. Después, puede actualizar la información del clúster.
Exploración de recursos vinculados
Desde el Explorador de servidores, podrá ver la cuenta de almacenamiento predeterminada y las cuentas de almacenamiento vinculadas. Expanda la cuenta de almacenamiento predeterminada para ver los contenedores en la cuenta de almacenamiento. Se marcarán la cuenta de almacenamiento predeterminada y el contenedor predeterminado.
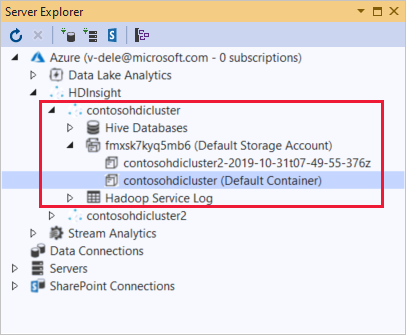
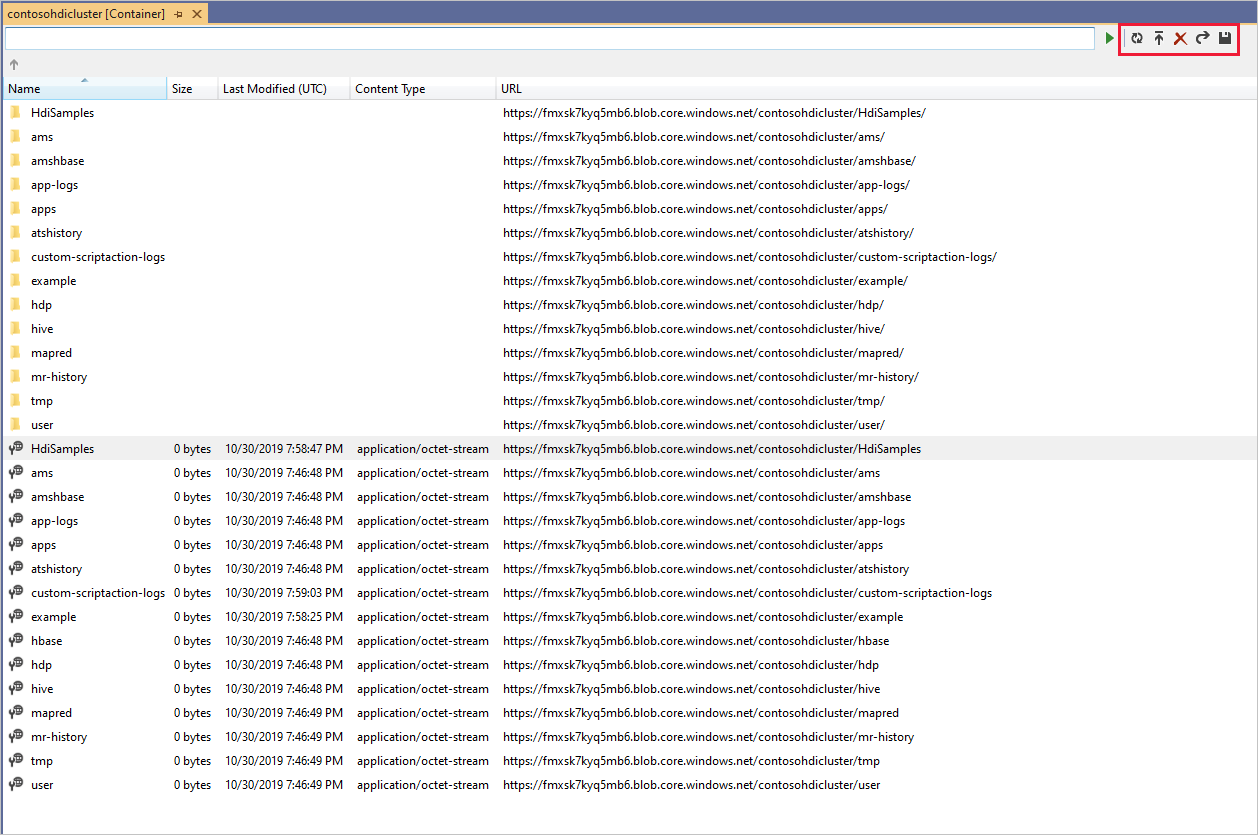
Haga clic con el botón derecho en un contenedor y seleccione Ver contenedor para ver su contenido. Después de abrir un contenedor, puede usar los botones de la barra de herramientas Actualizar (para actualizar la lista de contenido), Cargar blobs, Eliminar blobs seleccionados, Abrir un blob y Guardar como (para descargar los blobs seleccionados).
Ejecución de consultas interactivas de Apache Hive
Apache Hive es una infraestructura de almacenamiento de datos que se basa en Hadoop. Hive se utiliza para el análisis, las consultas y resumen de los datos. Data Lake Tools para Visual Studio se puede usar para ejecutar consultas de Hive desde Visual Studio. Para obtener más información sobre Hive, consulte ¿Qué son Apache Hive y HiveQL en Azure HDInsight?.
Interactive Query en Azure HDInsight usa Hive en LLAP en Apache Hive 2.1. Interactive Query aporta interactividad a las complejas consultas de estilo de almacenamiento de datos en grandes conjuntos de datos almacenados. La ejecución de consultas de Hive en Interactive Query es mucho más rápida que los trabajos por lotes tradicionales de Hive.
Nota
Solo se pueden ejecutar consultas de Hive interactivas al conectarse a un clúster de HDInsight Interactive Query.
También se puede utilizar Data Lake Tools para Visual Studio para ver el contenido de un trabajo de Hive. Data Lake Tools para Visual Studio recopila y muestra los registros Yarn de determinados trabajos de Hive.
En el Explorador de servidores, vaya a Azure>HDInsight y seleccione el clúster. Este nodo es el punto de partida en el Explorador de servidores para las secciones que siguen.
Ver hivesampletable
Todos los clústeres de HDInsight tienen una tabla de Hive de ejemplo denominada hivesampletable.
En el clúster, seleccione Bases de datos de Hive>predeterminado>hivesampletable.
Para ver el esquema de
hivesampletable:Expanda hivesampletable. Se muestran los nombres y los tipos de datos de las columnas de
hivesampletable.Para ver los datos de
hivesampletable:Haga clic con el botón derecho en hivesampletable y seleccione Ver las 100 primeras filas. La lista con 100 resultados aparece en la ventana Tabla de Hive: hivesampletable. Esta acción equivale a ejecutar la siguiente consulta de Hive mediante el uso del controlador ODBC de Hive:
SELECT * FROM hivesampletable LIMIT 100Puede personalizar el recuento de filas si cambia Número de filas; puede elegir 50, 100, 200 o 1000 filas en la lista desplegable.
Crear tablas de Hive
Para crear una tabla de Hive, puede usar la GUI o las consultas de Hive. Para obtener información acerca del uso de consultas de Hive, consulte Creación y ejecución de consultas de Hive.
En el clúster, seleccione Bases de datos de Hive>predeterminado.
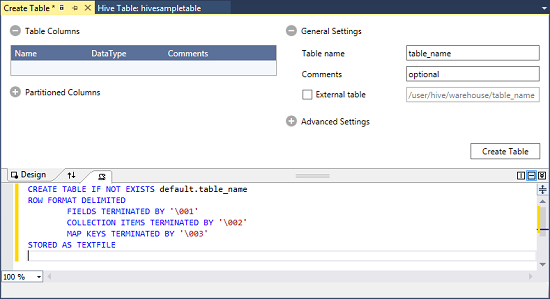
Haga clic con el botón derecho en predeterminado y seleccione Crear tabla.
Configure la tabla.
Seleccione el botón Crear tabla para enviar el trabajo, de este modo se crea la nueva tabla de Hive.
Creación y ejecución de consultas de Hive
Para crear y ejecutar consultas de Hive tiene dos opciones:
- Crear consultas ad hoc
- Crear una aplicación de Hive
Creación de una consulta ad hoc
Para crear y ejecutar una consulta ad hoc:
Haga clic con el botón derecho en el clúster en que desee ejecutar la consulta y seleccione Escribir una consulta de Hive.
Especifique una consulta de Hive.
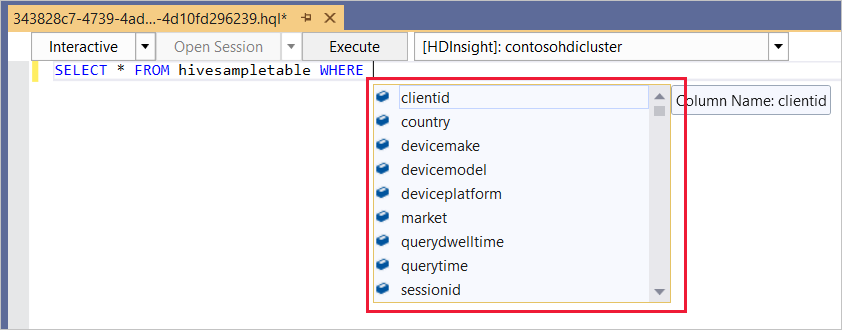
El editor de Hive es compatible con IntelliSense. Data Lake Tools para Visual Studio es compatible con la carga de metadatos remotos cuando se edita un script de Hive. Por ejemplo, si escribe
SELECT * FROM, IntelliSense enumera todos los nombres de tabla sugeridos. Cuando se especifica un nombre de tabla, IntelliSense enumera los nombres de columna. Las herramientas admiten casi todas las instrucciones DML de Hive, subconsultas y UDF integradas.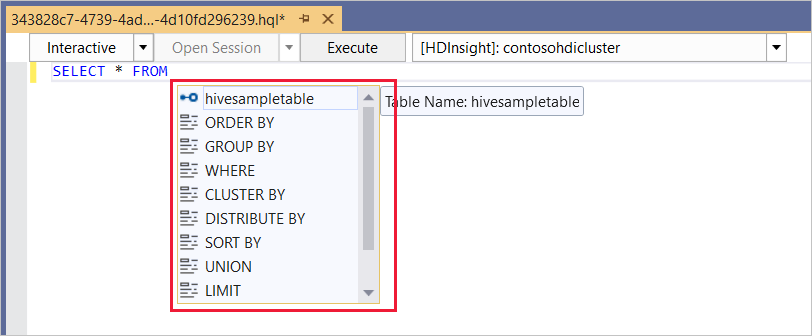
Nota:
IntelliSense solo sugiere los metadatos del clúster que se seleccionan en la barra de herramientas de HDInsight.
Esta es una consulta de ejemplo que puede usar:
SELECT devicemodel, COUNT(devicemodel) AS deviceCount FROM hivesampletable GROUP BY devicemodel ORDER BY devicemodelElija el modo de ejecución:
Interactivo
En la primera lista desplegable, elija Interactivo y, a continuación, seleccione Ejecutar.

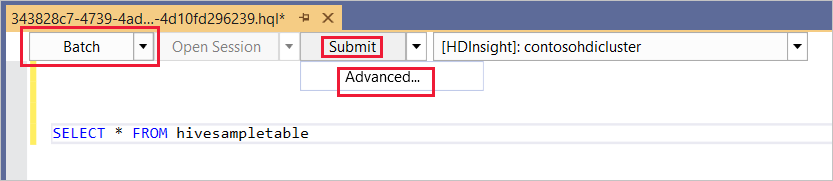
Batch
En la primera lista desplegable, elija Lote y, a continuación, seleccione Enviar. O bien, seleccione el icono desplegable situado junto a Enviar y elija Avanzado.
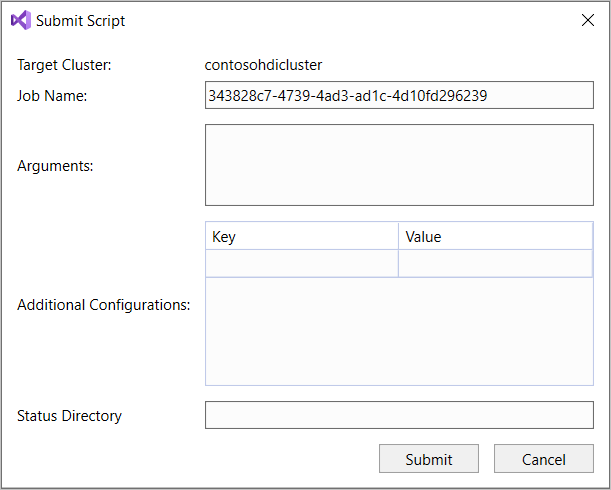
Si selecciona la opción de envío avanzado, aparecerá el cuadro de diálogo Enviar script. Configure el nombre del trabajo, los argumentos, las configuraciones adicionales y el estado de directorio del script.
Nota:
No se pueden enviar lotes a clústeres de Interactive Query. Hay que usar el modo interactivo.
Crear una aplicación de Hive
Para crear y ejecutar una solución de Hive:
En la barra de menús, elija Archivo>Nuevo>Proyecto.
En la ventana Crear un nuevo proyecto, seleccione el cuadro de búsqueda y escriba Hive. A continuación, elija Aplicación de Hive y seleccione Siguiente.
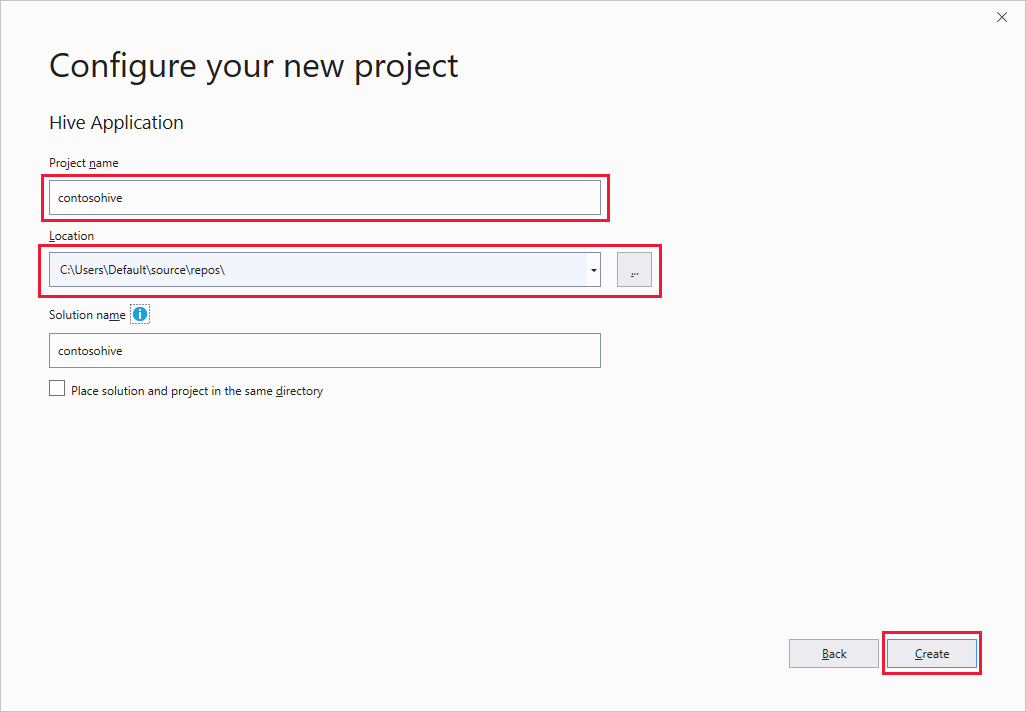
En la ventana Configure su nuevo proyecto, escriba un nombre de proyecto, elija o cree la ubicación del proyecto y, después, seleccione Crear.
En el Explorador de soluciones, haga doble clic en Script.hql para abrir el script.
Visualización de salida y resumen del trabajo
El resumen del trabajo varía ligeramente entre los modos por lotes e interactivo.
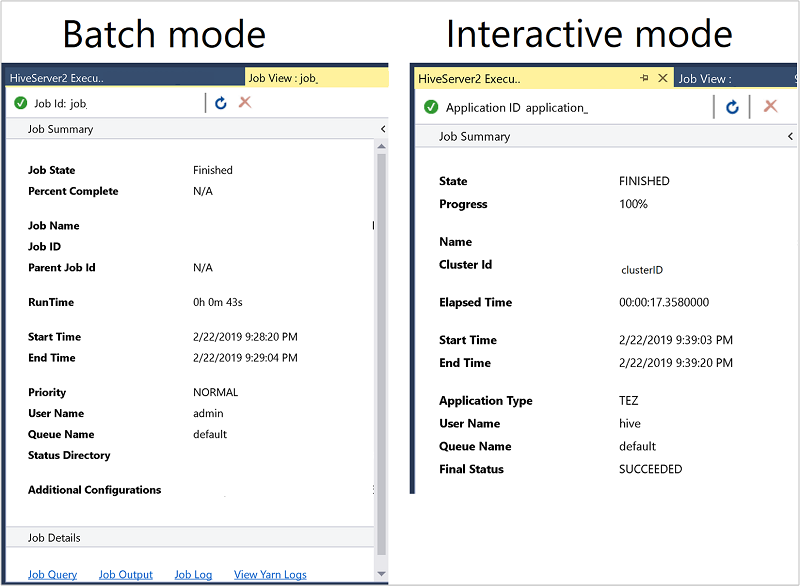
Use el icono Actualizar para actualizar el estado hasta que el estado del trabajo cambie a Finalizado.
Para obtener detalles del trabajo del modo por lotes, seleccione los vínculos de la parte inferior para ver Consulta de trabajo, Salida del trabajo, Registro de trabajo o Ver registros de Yarn.
Para obtener detalles del trabajo del modo interactivo, vea los paneles Salida y Salida de HiveServer2.
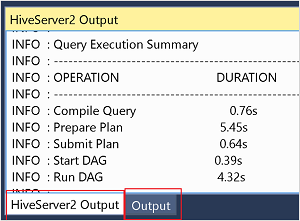
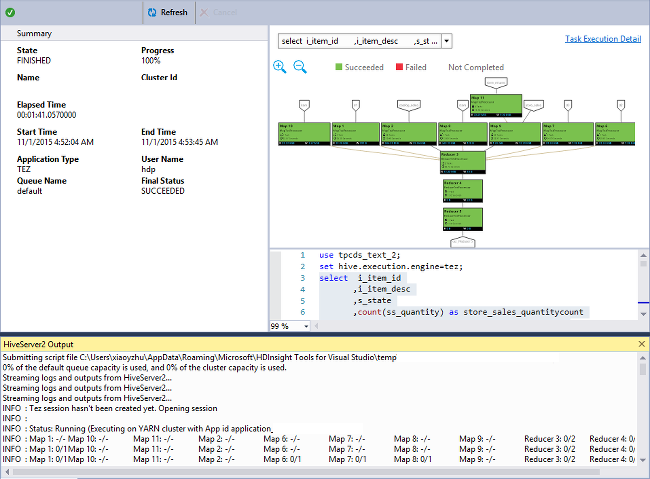
Visualización del gráfico del trabajo
Actualmente, solo se muestran gráficos de trabajo de los trabajos de Hive que usan Tez como motor de ejecución. Para obtener más información sobre la habilitación de Tez, consulte ¿Qué son Apache Hive y HiveQL en Azure HDInsight?. Vea también Uso de Apache Tez en lugar de MapReduce.
Para ver todos los operadores que hay en el vértice, haga doble clic en los vértices del gráfico del trabajo. También puede señalar a un operador concreto para ver más detalles de él.
Aun habiendo especificado Tez como motor de ejecución, es posible que no se muestre el gráfico del trabajo si no hay iniciada ninguna aplicación Tez. Esta situación puede producirse porque el trabajo no contiene instrucciones DML o porque las instrucciones DML pueden volver sin iniciar una aplicación Tez. Por ejemplo, SELECT * FROM table1 no iniciará la aplicación Tez.
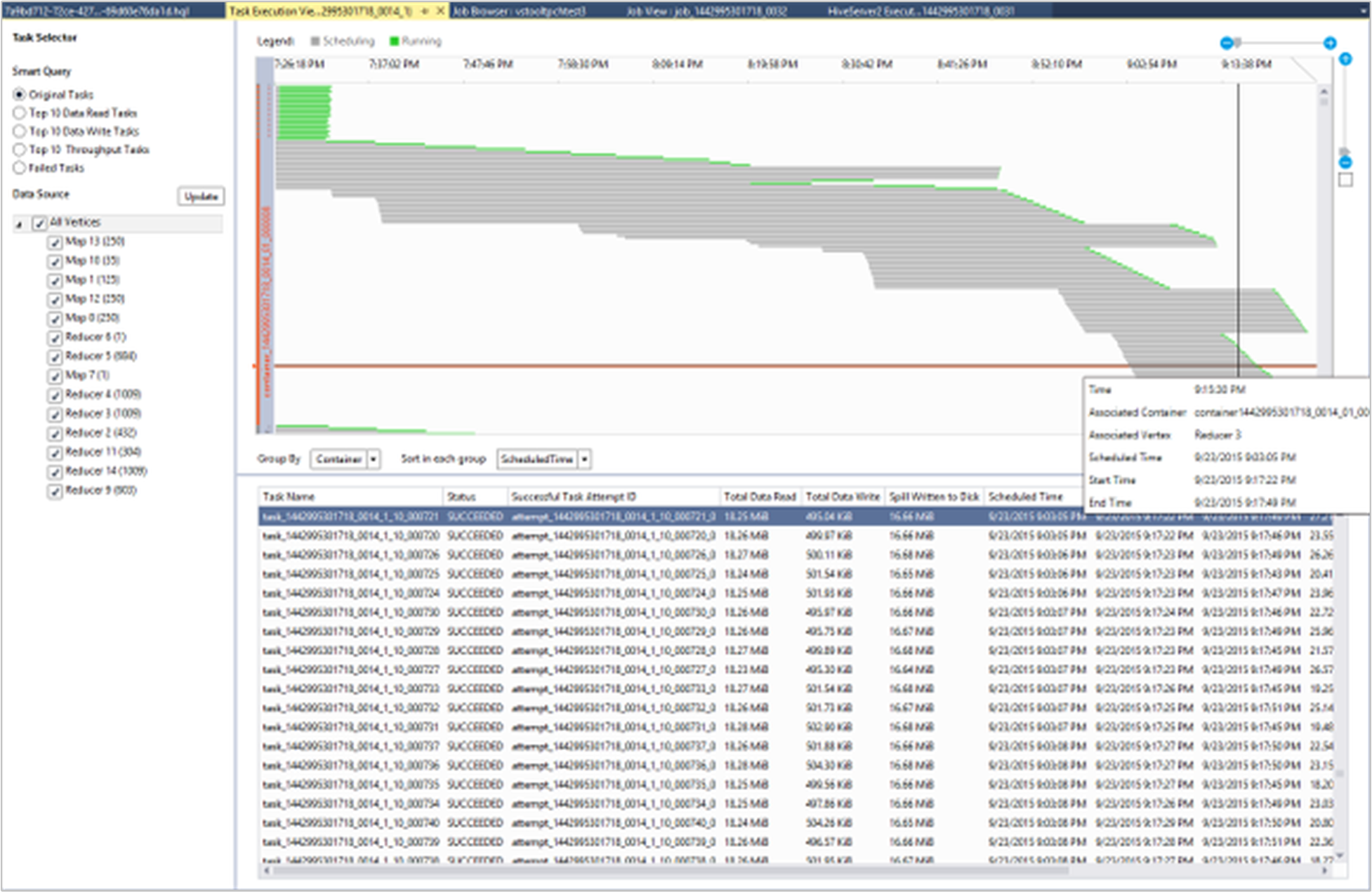
Visualización de los detalles de ejecución de la tarea
En el gráfico del trabajo, se puede seleccionar Detalles de ejecución de la tarea para obtener información estructurada y visualizada de los trabajos de Hive. También puede obtener más información del trabajo. Si se produce algún problema de rendimiento, puede usar la vista para obtener más información sobre el mismo. Por ejemplo, puede recuperar información acerca de cómo funciona cada tarea e información detallada acerca de cada tarea (lectura y escritura de datos, hora de programación, de inicio o de fin, etc.). Esta información se puede usar para ajustar las configuraciones de trabajo o la arquitectura del sistema en función de la información visualizada.
Ver trabajos de Hive
Puede ver consultas de trabajo, salidas de trabajo, registros de trabajo y registros Yarn para trabajos de Hive.
En la versión más reciente de las herramientas puede ver el contenido de los trabajos de Hive al recopilar y exponer los registros Yarn. Un registro Yarn puede ayudarle a investigar problemas de rendimiento. Para más información acerca de la forma en que HDInsight recopila registros Yarn, consulte Acceso a registros de aplicación de YARN de Apache Hadoop.
Para ver trabajos de Hive:
Haga clic con el botón derecho en un clúster de HDInsight y seleccione Ver trabajos.
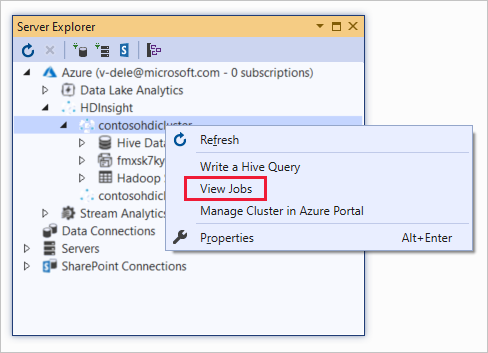
Aparece una lista de los trabajos de Hive que se ejecutaron en el clúster.
Seleccione un trabajo. En la ventana Resumen de trabajos de Hive, seleccione uno de los siguientes vínculos:
- Consulta de trabajo
- Salida de trabajo
- Registro de trabajo
- Registro de Yarn
Ejecución de scripts de Apache Pig
En la barra de menús, elija Archivo>Nuevo>Proyecto.
En la ventana de inicio, seleccione el cuadro de búsqueda y escriba Pig. Seleccione Aplicación Pig y, después, Siguiente.
En la ventana Configure su nuevo proyecto, escriba un nombre de proyecto y elija o cree la ubicación del proyecto. Seleccione Crear.
En el Explorador de soluciones del IDE, haga doble clic en Script.pig para abrir el script.
Comentarios y problemas conocidos
Se ha corregido un problema en el que no se muestran los resultados que comienzan por valores null. Si está bloqueado debido a este problema, póngase en contacto con el equipo de soporte técnico.
La codificación del script HQL que crea Visual Studio depende de la configuración regional del usuario. El script no se ejecuta correctamente si se carga en un clúster como un archivo binario.
Pasos siguientes
En este artículo, ha aprendido a usar el paquete Data Lake Tools para Visual Studio para establecer conexión a los clústeres de HDInsight desde Visual Studio. También ha aprendido a ejecutar una consulta de Hive.
- Ejecución de las consultas de Apache Hive mediante Herramientas de Data Lake para Visual Studio
- ¿Qué son Apache Hive y HiveQL en Azure HDInsight?
- Creación de un clúster de Apache Hadoop: plantilla
- Envío de trabajos de Apache Hadoop en HDInsight
- Análisis de datos de X con Apache Hive y Apache Hadoop en HDInsight