Requisito previo: recopilación de requisitos
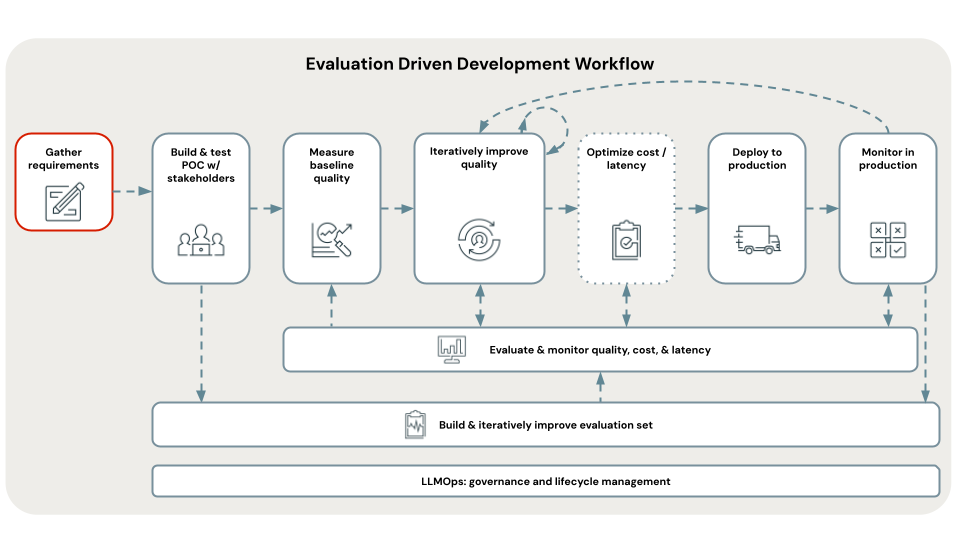
Definir requisitos de casos de uso claros y completos es un primer paso fundamental para desarrollar una aplicación RAG de manera correcta. Estos requisitos sirven para dos propósitos principales. En primer lugar, ayudan a determinar si RAG es el enfoque más adecuado para el caso de uso dado. Si RAG es realmente una buena opción, estos requisitos guían el diseño, la implementación y las decisiones de evaluación de soluciones. La inversión de tiempo en el inicio de un proyecto relacionada con la recopilación de requisitos detallados puede evitar desafíos y retrocesos cruciales más adelante en el proceso de desarrollo, y garantiza que la solución resultante satisfaga las necesidades de los usuarios finales y las partes interesadas. Los requisitos bien definidos proporcionan la base para las fases posteriores del ciclo de vida de desarrollo que recorreremos.
Consulte el repositorio de GitHub para ver el código de ejemplo de esta sección. También puede usar el código del repositorio como plantilla con la que crear sus propias aplicaciones de inteligencia artificial.
¿El caso de uso es adecuado para RAG?
Lo primero que debe establecer es si RAG es incluso el enfoque adecuado para su caso de uso. Dada la expectación alrededor de RAG, es tentador verla como una posible solución para cualquier problema. Sin embargo, no siempre RAG es la alternativa más conveniente.
RAG es una buena opción al:
- Razonar sobre información recuperada (tanto no estructurada como estructurada) que no encaja del todo en la ventana contextual del LLM
- Sintetizar información de múltiples orígenes (por ejemplo, generar un resumen de los puntos clave de diferentes artículos sobre un tema)
- La recuperación dinámica basada en una consulta de usuario es necesaria (por ejemplo, dada una consulta de usuario, se necesita determinar de qué origen de datos se va a recuperar)
- El caso de uso requiere generar contenido nuevo basado en información recuperada (por ejemplo, responder preguntas, proporcionar explicaciones, ofrecer recomendaciones)
RAG puede no ser la mejor opción cuando:
- La tarea no requiere una recuperación específica de la consulta. Por ejemplo, generar resúmenes de transcripción de llamadas; incluso si se proporcionan transcripciones individuales como contexto en la indicación al LLM, la información recuperada sigue siendo la misma para cada resumen.
- Todo el conjunto de información que se va a recuperar puede caber en la ventana de contexto del LLM
- Se requieren respuestas de latencia extremadamente baja (por ejemplo, cuando se requieren respuestas en milisegundos)
- Las respuestas simples basadas en reglas o con plantillas son suficientes (por ejemplo, un bot de chat de soporte al cliente que proporciona respuestas predefinidas basadas en palabras clave)
Requisitos
Después de haber establecido que RAG es una buena opción para su caso de uso, tenga en cuenta las siguientes preguntas para capturar los requisitos concretos. Los requisitos se priorizan de la siguiente manera:
🟢 P0: debe definir este requisito antes de iniciar la prueba de concepto.
🟡 P1: debe definirse antes de ir a producción, pero puede refinarse iterativamente durante la prueba de concepto.
⚪ P2: requisito que es bueno tener.
Esta no es una lista exhaustiva de preguntas. Sin embargo, debe proporcionar una base sólida para capturar los requisitos clave de la solución RAG.
Experiencia del usuario
Defina cómo interactuarán los usuarios con el sistema RAG y qué tipo de respuestas se esperan
🟢 [P0] ¿Qué aspecto tendrá una solicitud típica a la cadena RAG? Pida a las partes interesadas ejemplos de posibles consultas de usuario.
🟢 [P0] ¿Qué tipo de respuestas esperarán los usuarios (respuestas cortas, explicaciones de formato largo, una combinación o algo más)?
🟡 [P1] ¿Cómo interactuarán los usuarios con el sistema? ¿A través de una interfaz de chat, una barra de búsqueda o alguna otra modalidad?
🟡 [P1] ¿Qué tono o estilo deben adoptar las respuestas generadas? (formal, conversacional, técnico?)
🟡 [P1] ¿Cómo debe controlar la aplicación consultas ambiguas, incompletas o irrelevantes? ¿Debe proporcionarse alguna forma de comentarios o instrucciones en estos casos?
⚪ [P2] ¿Hay requisitos específicos de formato o presentación para la salida generada? ¿La salida debe incluir metadatos además de la respuesta de la cadena?
Data
Determine la naturaleza, los orígenes y la calidad de los datos que se usarán en la solución RAG.
🟢 [P0] ¿Cuáles son los orígenes disponibles que se van a usar?
Para cada origen de datos:
- 🟢 [P0] ¿Los datos están estructurados o no?
- 🟢 [P0] ¿Cuál es el formato de origen de los datos de recuperación (por ejemplo, archivos PDF, documentación con imágenes o tablas, respuestas de API estructuradas)?
- 🟢 [P0] ¿Dónde residen esos datos?
- 🟢 [P0] ¿Cuántos datos están disponibles?
- 🟡 [P1] ¿Con qué frecuencia se actualizan los datos? ¿Cómo se deben controlar esas actualizaciones?
- 🟡 [P1] ¿Hay algún problema conocido de calidad de datos o incoherencias para cada origen de datos?
Considere la posibilidad de crear una tabla de inventario para consolidar esta información, por ejemplo:
| Origen de datos | Source | Tipos de archivo | Size | Frecuencia de actualización |
|---|---|---|---|---|
| Origen de datos 1 | Volumen de Unity Catalog | JSON | 10 GB | Diariamente |
| Origen de datos 2 | API pública | XML | NA (API) | Tiempo real |
| Origen de datos 3 | SharePoint | PDF, .docx | 500MB | Mensualmente |
Restricciones de rendimiento
Capture los requisitos de rendimiento y recursos para la aplicación RAG.
🟡 [P1] ¿Cuál es la latencia máxima aceptable para generar las respuestas?
🟡 [P1] ¿Cuál es el tiempo máximo aceptable para el primer token?
🟡 [P1] Si se transmite la salida, ¿se acepta una mayor latencia total?
🟡 [P1] ¿Existen limitaciones de costos en los recursos de proceso disponibles para la inferencia?
🟡 [P1] ¿Cuáles son los patrones de uso esperados y las cargas máximas?
🟡 [P1] ¿Cuántos usuarios o solicitudes simultáneos deben controlar el sistema? Databricks controla de forma nativa estos requisitos de escalabilidad, a través de la capacidad de escalar automáticamente con Servicio de modelos.
Evaluación
Establezca cómo se evaluará y mejorará la solución RAG con el tiempo.
🟢 [P0] ¿Cuál es el objetivo empresarial o KPI sobre el que desea influir? ¿Cuál es el valor de línea base y cuál es el objetivo?
🟢 [P0] ¿Qué usuarios o partes interesadas proporcionarán comentarios iniciales y continuos?
🟢 [P0] ¿Qué métricas se deben usar para evaluar la calidad de las respuestas generadas? La evaluación del agente de Mosaic AI proporciona un conjunto recomendado de métricas que se van a usar.
🟡 [P1] ¿Cuál es el conjunto de preguntas para las cuales la aplicación RAG debe ser buena antes de ir a producción?
🟡 [P1] ¿Existe un [conjunto de evaluación]? ¿Es posible obtener un conjunto de evaluación de consultas de usuario, junto con respuestas de verdad fundamental y (opcionalmente) los documentos auxiliares correctos que se deben recuperar?
🟡 [P1] ¿Cómo se recopilarán e incorporarán los comentarios del usuario en el sistema?
Seguridad
Identifique las consideraciones de seguridad y privacidad.
🟢 [P0] ¿Hay datos confidenciales que se deben manejar con cuidado?
🟡 [P1] ¿Es necesario implementar controles de acceso en la solución (por ejemplo, un usuario determinado solo puede recuperar información de un conjunto restringido de documentos)?
Implementación
Comprender cómo se integrará, implementará y mantendrá la solución RAG.
🟡 ¿Cómo se debe integrar la solución RAG con los sistemas y flujos de trabajo existentes?
🟡 ¿Cómo se debe implementar, escalar y versionar el modelo? En este tutorial, se explica cómo se puede controlar el ciclo de vida de un extremo a otro en Databricks mediante MLflow, Unity Catalog, SDK del agente y Servicio de modelos.
Ejemplo
Por ejemplo, considere cómo se aplican estas preguntas a esta aplicación RAG de ejemplo usada por un equipo de soporte al cliente de Databricks:
| Área | Consideraciones | Requisitos |
|---|---|---|
| Experiencia del usuario | - Modalidad de interacción. - Ejemplos típicos de consultas de usuario. - Formato y estilo de respuesta esperados. - Control de consultas ambiguas o irrelevantes. |
- Interfaz de chat integrada con Slack. - Consultas de ejemplo: "¿Cómo se reduce el tiempo de inicio del clúster?" "¿Qué tipo de plan de soporte técnico tengo?" - Respuestas claras y técnicas con fragmentos de código y vínculos a la documentación pertinente cuando corresponda. - Proporcionar sugerencias contextuales y escalar a los ingenieros de soporte técnico cuando sea necesario. |
| Data | - Número y tipo de orígenes de datos. - Formato de datos y ubicación. - Tamaño de datos y frecuencia de actualización. - Calidad y coherencia de los datos. |
- Tres orígenes de datos. - Documentación de la empresa (HTML, PDF). - Incidencias de soporte técnico resueltas (JSON). - Entradas de foro de la comunidad (tabla Delta). - Datos almacenados en Unity Catalog y actualizados semanalmente. - Tamaño total de datos: 5 GB. - Estructura de datos coherente y calidad mantenida por documentos dedicados y equipos de soporte técnico. |
| Rendimiento | - Latencia máxima aceptable. - Restricciones de costos. - Uso y simultaneidad esperados. |
- Requisito de latencia máxima. - Restricciones de costos. - Carga máxima esperada. |
| Evaluación | - Disponibilidad del conjunto de datos de evaluación. - Métricas de calidad. - Recopilación de comentarios del usuario. |
- Expertos en la materia de cada área del producto ayudan a revisar las salidas y ajustan las respuestas incorrectas para crear el conjunto de datos de evaluación. - KPI de negocio. - Aumento de la tasa de resolución de incidencias de soporte técnico. - Disminución del tiempo de usuario invertido por incidencia de soporte técnico. - Métricas de calidad. - Corrección y pertinencia de las respuestas evaluadas por el LLM. - El LLM juzga la precisión de la recuperación. - Votación a favor o en contra por parte del usuario. - Recopilación de comentarios. - Slack contará con instrumentos para proporcionar un pulgar arriba/abajo. |
| Seguridad | - Control de datos confidenciales. - Requisitos de control de acceso. |
- No debe haber datos confidenciales del cliente en el origen de recuperación. - Autenticación de usuarios a través del inicio de sesión único de Databricks Community. |
| Implementación | - Integración con sistemas existentes. - Implementación y control de versiones. |
- Integración con el sistema de vales de soporte técnico. - Cadena implementada como punto de conexión de servicio del modelo de Databricks. |
Paso siguiente
Comenzar con el Paso 1. Clone el repositorio de código y cree el proceso.