Tutorial: Ejecución de un archivo de Python en un clúster y como trabajo mediante la extensión de Databricks para Visual Studio Code
Este tutorial le guía a través de la configuración de la extensión de Databricks para Visual Studio Code y, a continuación, la ejecución de un archivo de Python en un clúster de Azure Databricks y como un trabajo de Azur Databricks en su área de trabajo remota. Consulte ¿Qué es la extensión de Databricks para Visual Studio Code?.
Requisitos
Este tutorial requiere lo siguiente:
- Instalación de la extensión de Databricks para Visual Studio Code. Consulte Instalación de la extensión de Databricks para Visual Studio Code.
- Un clúster remoto de Azure Databricks que se va a usar. Anote el nombre del clúster. Para ver los clústeres disponibles, en la barra lateral del área de trabajo de Azure Databricks, haga clic en Proceso. Consulte Proceso.
Paso 1: Crear un nuevo proyecto de Databricks
En este paso, creará un nuevo proyecto de Databricks y configurará la conexión con el área de trabajo remota de Azure Databricks.
- Inicie Visual Studio Code y, a continuación, haga clic en Abrir > Abrir carpeta y abra una carpeta vacía en la máquina de desarrollo local.
- En la barra lateral, haga clic en el icono del logotipo de Databricks. Se abrirá la extensión de Databricks.
- En la vista de configuración , haga clic en Crear configuración.
- Se abre la paleta de comandos para configurar el área de trabajo de Databricks. En Host de Databricks, escriba o seleccione la dirección URL por área de trabajo, por ejemplo,
https://adb-1234567890123456.7.azuredatabricks.net. - Seleccione un perfil de autenticación para el proyecto. Consulte Configurar la autorización para la extensión de Databricks para Visual Studio Code.
Paso 2: Agregar información de clúster a la extensión de Databricks e iniciar el clúster
Con la vista Configuración ya abierta, haga clic en Seleccionar un clúster o haga clic en el icono de engranaje (Configurar clúster).
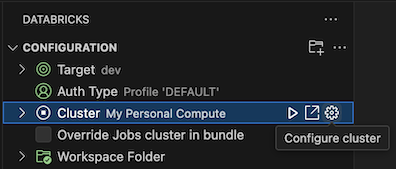
En la paleta de comandos, seleccione el nombre del clúster que creó anteriormente.
Si aún no se ha iniciado, haga clic en el icono de reproducción (Iniciar clúster).
Paso 3: Crear y ejecutar código de Python
Cree un archivo de código de Python local: en la barra lateral, haga clic en el icono de carpeta (Explorador).
En el menú principal, haga clic en Archivo > Nuevo archivo y elija un archivo de Python. Nombre el archivo como demo.py y guárdelo en la raíz del proyecto.
Agregue el siguiente código al archivo y guárdelo. Este código crea y muestra los contenidos de un DataFrame de PySpark básico:
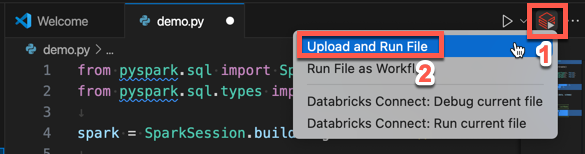
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Haga clic en el icono Ejecutar en Databricks junto a la lista de pestañas del editor y, a continuación, haga clic en Cargar y ejecutar archivo. La salida aparece en la vista Consola de depuración.
En la vista Explorer, también puede hacer clic con el botón derecho en el archivo
demo.pyy después en Ejecutar en Databricks>Cargar y ejecutar archivo.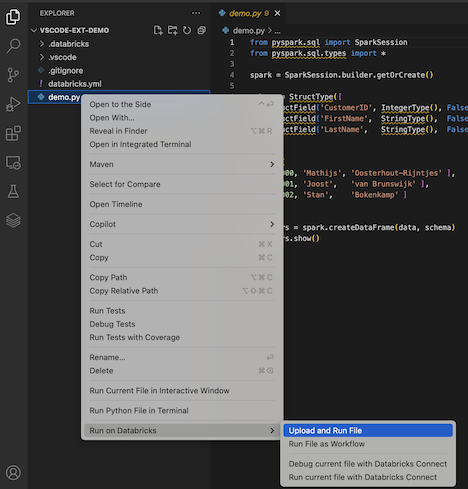
Paso 4: Ejecutar el código como un trabajo
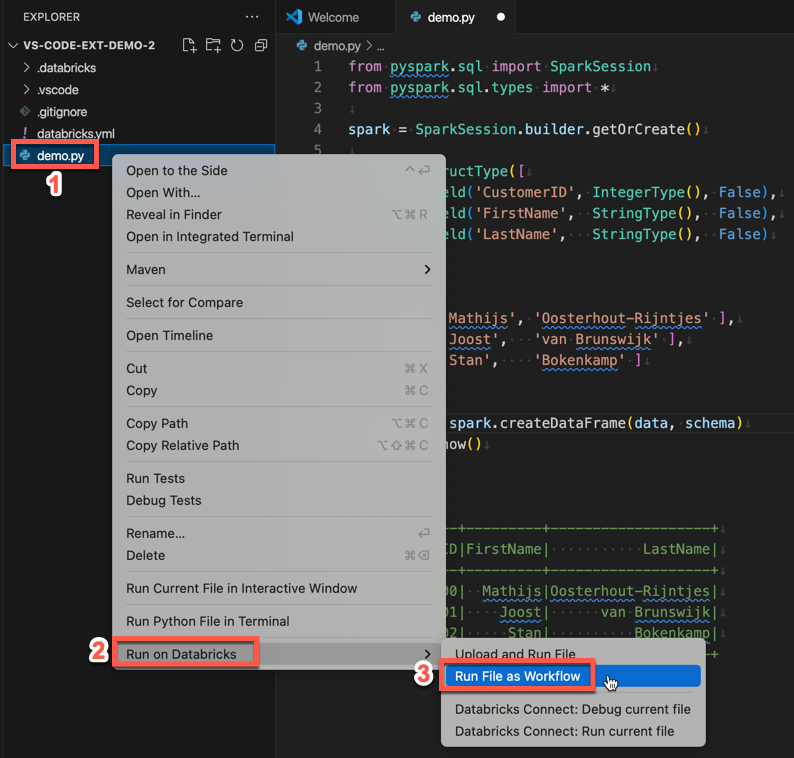
Para ejecutar demo.py como un trabajo, haga clic en el icono Ejecutar en Databricks junto a la lista de pestañas del editor y, a continuación, haga clic en Ejecutar archivo como flujo de trabajo. La salida aparece en una pestaña del editor independiente junto al editor de archivos demo.py.
![]()
También puede hacer clic con el botón derecho en el archivo demo.py en el panel Explorador y, a continuación, seleccionar Ejecutar en Databricks>Ejecutar archivo como flujo de trabajo.
Pasos siguientes
Ahora que ha usado satisfactoriamente la extensión de Databricks para Visual Studio Code para cargar un archivo de Python local y ejecutarlo de forma remota, también puede hacer lo siguiente:
- Explorar los recursos y variables de agrupaciones de recursos de Databricks mediante la interfaz de usuario de la extensión. Vea Características de extensión de conjuntos de recursos de Databricks.
- Ejecutar o depurar código de Python con Databricks Connect. Vea Depuración de código mediante Databricks Connect para la extensión de Databricks para Visual Studio Code.
- Ejecutar un archivo o un cuaderno como un trabajo de Azure Databricks. Vea Ejecución de un archivo en un clúster, archivo o cuaderno como trabajo en Azure Databricks mediante la extensión de Databricks para Visual Studio Code.
- Ejecutar pruebas con
pytest. Vea Ejecución de pruebas con pytest mediante la extensión de Databricks para Visual Studio Code.