Uso de atributos mediante etiquetas
En este artículo se explica cómo usar etiquetas personalizadas y predeterminadas para atribuir cargas de trabajo a áreas de trabajo específicas, equipos, proyectos y usuarios.
Para supervisar el costo y atribuir con precisión el uso de Azure Databricks a las unidades de negocio y los equipos de la organización (por ejemplo, para contracargos), puede etiquetar áreas de trabajo (grupos de recursos), y recursos de proceso. Estas etiquetas se propagan a informes de análisis de costos detallados a los que puede acceder en Azure Portal. Nota: Los datos de etiqueta se pueden replicar globalmente. No use nombres de etiqueta ni valores que puedan poner en peligro la seguridad de los recursos. Por ejemplo, no use nombres de etiqueta que contengan información personal o confidencial.
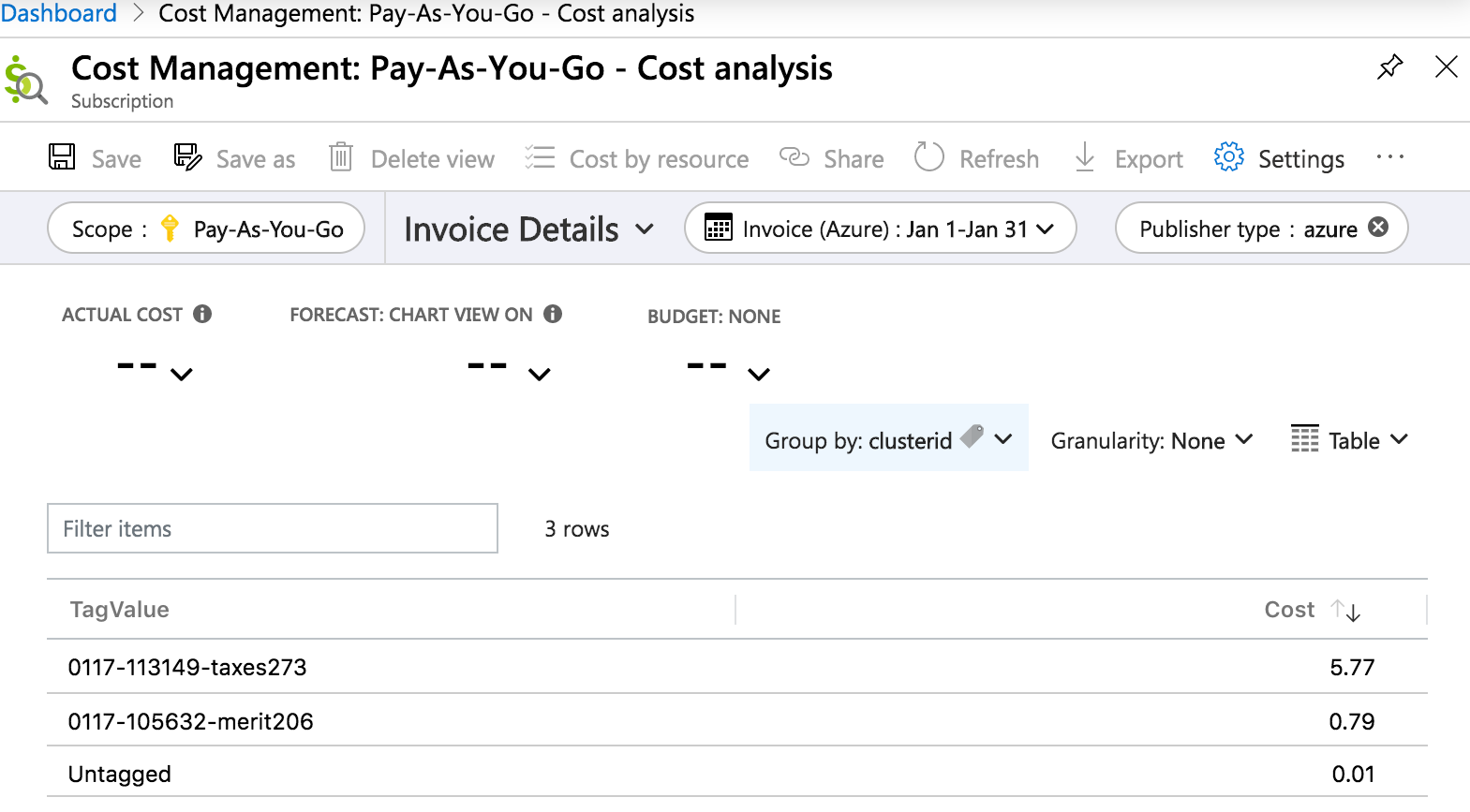
A continuación, encontrará un informe de detalles de la factura de análisis de costes en Azure Portal que detalla el coste por la etiqueta clusterid durante un período de un mes:
Objetos y recursos etiquetados
| Object | Interfaz de etiquetado (UI) | Interfaz de etiquetado (API) |
|---|---|---|
| Área de trabajo | Azure Portal | API de recursos de Azure |
| grupo | UI de grupos en el área de trabajo de Azure Databricks | API de grupo de instancia |
| Proceso de trabajo y de uso completo | UI de proceso en el área de trabajo de Azure Databricks | API de clústeres |
| Almacén de SQL | UI de almacén de SQL en el área de trabajo de Azure Databricks | API de almacenes |
Advertencia
No asigne una etiqueta personalizada con la clave Name a un clúster. Cada clúster tiene una etiqueta Name con el valor establecido por Azure Databricks. Si cambia el valor asociado a la clave Name, Azure Databricks ya no puede realizar el seguimiento del clúster. Como consecuencia, es posible que el clúster no finalice después de quedarse inactivo y que siga incurriendo en costos de uso.
Etiquetas predeterminadas
Azure Databricks agrega las siguientes etiquetas predeterminadas al proceso de uso completo:
| Clave de etiqueta | Valor |
|---|---|
Vendor |
Valor constante: Databricks |
ClusterId |
Identificador interno de Azure Databricks del clúster |
ClusterName |
Nombre del clúster |
Creator |
Nombre de usuario (dirección de correo electrónico) del usuario que creó el clúster |
En los clústeres de trabajo, Azure Databricks también aplica las siguientes etiquetas predeterminadas:
| Clave de etiqueta | Valor |
|---|---|
RunName |
Nombre del trabajo |
JobId |
Id. del trabajo |
Azure Databricks agrega las siguientes etiquetas predeterminadas a todos los grupos:
| Clave de etiqueta | Valor |
|---|---|
Vendor |
Valor constante: Databricks |
DatabricksInstancePoolCreatorId |
Identificador interno de Azure Databricks del usuario que creó el grupo |
DatabricksInstancePoolId |
Identificador interno de Azure Databricks del grupo |
En el proceso que usa Lakehouse Monitoring, Azure Databricks también aplica las siguientes etiquetas:
| Clave de etiqueta | Valor |
|---|---|
LakehouseMonitoring |
true |
LakehouseMonitoringTableId |
Identificador de la tabla supervisada |
LakehouseMonitoringWorkspaceId |
Identificador del área de trabajo donde se creó el monitor |
LakehouseMonitoringMetastoreId |
Identificador de la tienda de metadatos donde existe la tabla supervisada |
Etiquetado de cargas de trabajo de proceso sin servidor
Importante
Esta característica está en versión preliminar pública.
Para atribuir el uso de proceso sin servidor a usuarios, grupos o proyectos, puede usar directivas de presupuesto. Cuando se asigna a un usuario una directiva de presupuesto, su uso sin servidor se etiqueta automáticamente con las etiquetas de su directiva. Consulte Attribute serverless usage with budget policies (Uso sin servidor de atributos con directivas de presupuesto).
Propagación de etiquetas
Azure Databricks agrega las etiquetas de área de trabajo, grupo y clúster y se propagan a las VM de Azure para los informes de análisis de costos. Pero las etiquetas de grupo y clúster se propagan de forma diferente entre sí.
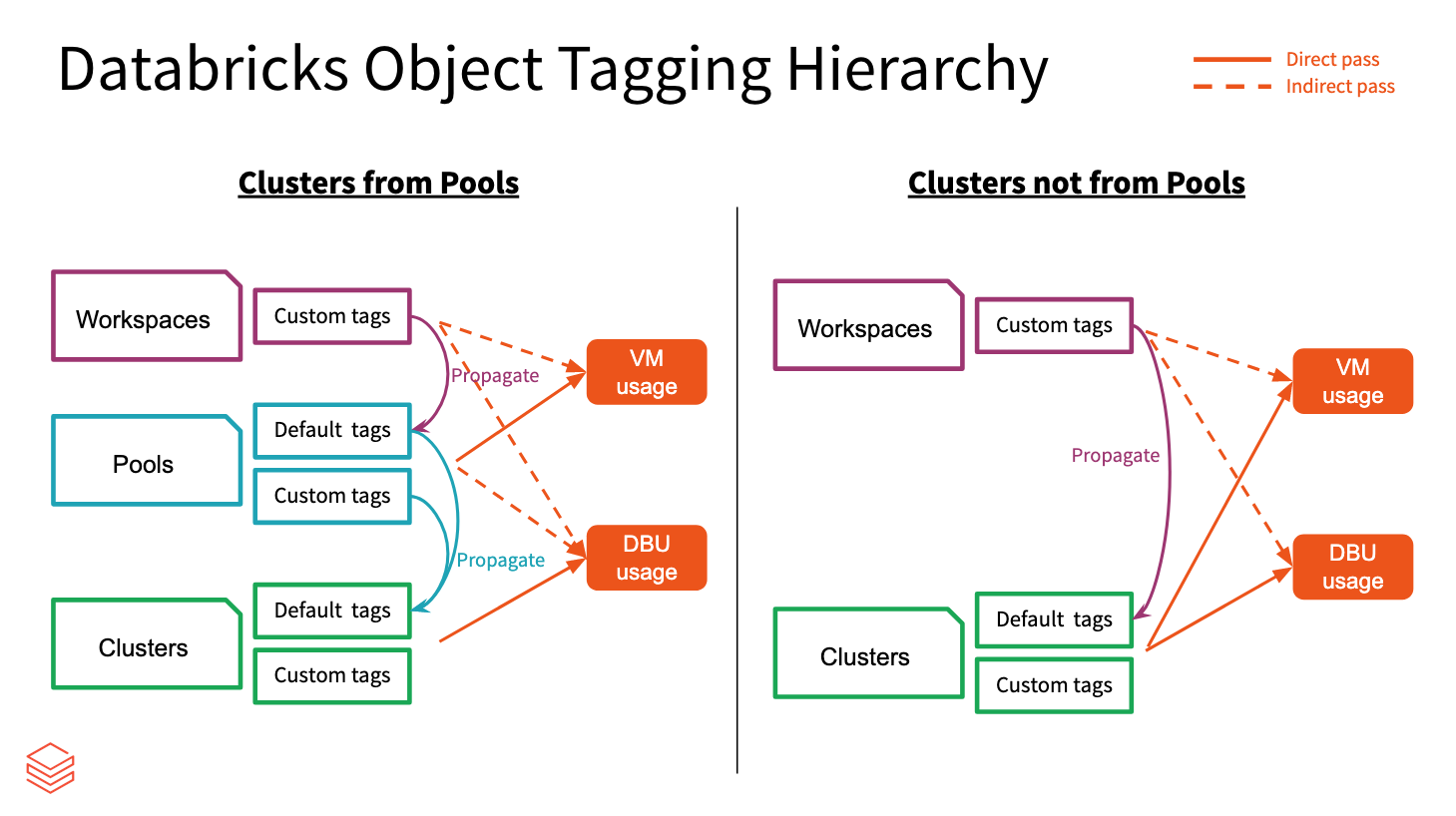
Las etiquetas de área de trabajo y grupo se agregan y asignan como etiquetas de recursos de las VM de Azure que hospedan los grupos.
Las etiquetas de área de trabajo y clúster se agregan y asignan como etiquetas de recursos de las VM de Azure que hospedan los clústeres.
Cuando se crean clústeres a partir de grupos, solo las etiquetas de área de trabajo y las etiquetas de grupo se propagan a las VM. Con el fin de conservar el rendimiento de inicio del clúster del grupo, las etiquetas de clúster no se propagan.
Resolución de conflictos de etiquetas
Si una etiqueta de clúster, etiqueta de grupo o etiqueta de área de trabajo personalizada tiene el mismo nombre que una etiqueta de grupo o clúster predeterminada de Azure Databricks, a la etiqueta personalizada se la agrega el prefijo x_ cuando se propaga.
Por ejemplo, si un área de trabajo está etiquetada con vendor = Azure Databricks, esa etiqueta entra en conflicto con la etiqueta de clúster predeterminada vendor = Databricks. Por lo tanto, las etiquetas se propagarán como x_vendor = Azure Databricks y vendor = Databricks.
Limitaciones
- Las etiquetas de área de trabajo personalizadas pueden tardar hasta una hora en propagarse a Azure Databricks después de cualquier cambio.
- No se pueden asignar más de cincuenta etiquetas a un recurso de Azure. Si el recuento total de etiquetas agregadas supera este límite, las etiquetas con prefijo
x_se evalúan en orden alfabético y las que superan el límite se omiten. Si se omiten todas las etiquetas con prefijox_y el recuento es superior al límite, las etiquetas restantes se evalúan en orden alfabético y las que superan el límite se omiten. - Las claves y los valores de etiqueta solo pueden contener letras, espacios, números o los caracteres
+, ,-=._:, , ./@Las etiquetas que contienen otros caracteres no son válidas. - Si cambia los nombres o valores de clave de etiqueta, estos cambios solo se aplican después del reinicio del clúster o la expansión del grupo.
- Si las etiquetas personalizadas del clúster entran en conflicto con las etiquetas personalizadas de un grupo, el clúster no se puede crear.
- Las etiquetas de área de trabajo recién agregadas no se asignan automáticamente a los recursos de proceso existentes. Para conseguir que las nuevas etiquetas se propaguen, abra la página de detalles del recurso de computación, haga clic en Editary luego en Confirmar y reiniciar.
Procedimientos recomendados de etiquetado
- Dado que las etiquetas se pueden escribir manualmente, la organización debe estandarizar sus pares clave-valor. Databricks recomienda desarrollar una directiva empresarial para la nomenclatura de clave y valor que puede compartir con todos los usuarios.
- Todos los recursos deben etiquetarse con claves generales que atribuyen el uso a una unidad de negocio o proyecto. Por ejemplo, un recurso de cálculo de trabajo creado por el equipo financiero para su presupuesto anual podría incluir las etiquetas
business-unit:financeyproject:annual-budget. - Para obtener información más detallada, asigne etiquetas mediante claves de alta especificidad. Por ejemplo, puede crear claves basadas en roles, productos, servicios o clientes.
- Cuando corresponda, los administradores del área de trabajo deben aplicar etiquetas mediante directivas de proceso y directivas de presupuesto. Consulte aplicación de etiquetas personalizadas.