Transformación de datos en Azure Virtual Network mediante la actividad de Hive en Azure Data Factory
SE APLICA A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, se usa Azure PowerShell para crear una canalización de Data Factory que transforma los datos mediante la actividad de Hive en un clúster de HDInsight que se encuentra en una instancia de Azure Virtual Network (VNet). En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Creación y configuración de Integration Runtime autohospedado
- Creación e implementación de servicios vinculados
- Creación e implementar de una canalización que contiene una actividad de Hive
- Inicio de la ejecución de una canalización.
- Supervisión de la ejecución de la canalización
- Comprobación del resultado
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Nota:
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Para comenzar, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Cuenta de Azure Storage. Cree un script de Hive y cárguelo en Azure Storage. La salida desde el script de Hive se almacena en esta cuenta de almacenamiento. En este ejemplo, el clúster de HDInsight usa esta cuenta de Azure Storage como el almacenamiento principal.
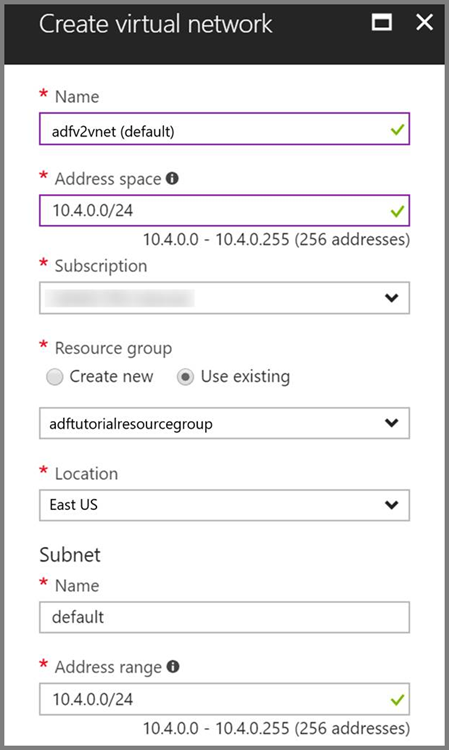
Azure Virtual Network. Si no tiene ninguna instancia de Azure Virtual Network, cree una siguiendo estas instrucciones. En este ejemplo, HDInsight se encuentra en una instancia de Azure Virtual Network. A continuación, puede ver una configuración de ejemplo de Azure Virtual Network.
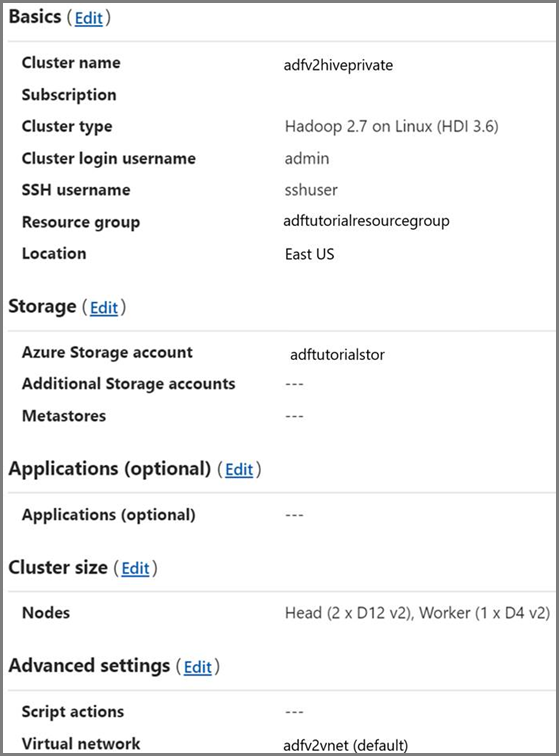
Clúster de HDInsight. Consulte el artículo siguiente para crear un clúster de HDInsight y unirlo a la red virtual que creó en el paso anterior: Extender Azure HDInsight mediante una instancia de Azure Virtual Network. A continuación, puede ver una configuración de ejemplo de HDInsight en una red virtual.
Azure PowerShell. Siga las instrucciones de Instalación y configuración de Azure PowerShell.
Carga del script de Hive en la cuenta de Blob Storage
Cree un archivo SQL de Hive denominado hivescript.hql con el siguiente contenido:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableEn Azure Blob Storage, cree un contenedor denominado adftutorial si no existe.
Cree una carpeta llamada hivescripts.
Cargue el archivo hivescript.hql en la subcarpeta hivescripts.
Crear una factoría de datos
Establezca el nombre del grupo de recursos. Se crea un grupo de recursos como parte de este tutorial. Sin embargo, puede usar un grupo de recursos existente, si lo desea.
$resourceGroupName = "ADFTutorialResourceGroup"Especifique el nombre de la factoría de datos. Debe ser único globalmente.
$dataFactoryName = "MyDataFactory09142017"Escriba un nombre para la canalización.
$pipelineName = "MyHivePipeline" #Especifique un nombre para el Integration Runtime autohospedado. Cuando Data Factory necesita tener acceso a los recursos ubicados dentro de una red virtual, como Azure SQL Database, se necesita un entorno de ejecución de integración autohospedado.
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"Inicie PowerShell. Mantenga Azure PowerShell abierto hasta el final de esta guía de inicio rápido. Si lo cierra y vuelve a abrirlo, deberá ejecutar los comandos de nuevo. Para una lista de las regiones de Azure en las que Data Factory está disponible actualmente, seleccione las regiones que le interesen en la página siguiente y expanda Análisis para poder encontrar Data Factory: Productos disponibles por región. Los almacenes de datos (Azure Storage, Azure SQL Database, etc.) y los procesos (HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
Ejecute el siguiente comando y escriba el nombre de usuario y la contraseña que utiliza para iniciar sesión en Azure Portal:
Connect-AzAccountEjecute el siguiente comando para ver todas las suscripciones de esta cuenta:
Get-AzSubscriptionEjecute el comando siguiente para seleccionar la suscripción con la que desea trabajar. Reemplace SubscriptionId con el identificador de la suscripción de Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"Creación del grupo de recursos: ADFTutorialResourceGroup si aún no existe en la suscripción.
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"Cree la factoría de datos.
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupNameEjecute el comando siguiente para ver la salida:
$df
Creación de una instancia de IR autohospedada
En esta sección, creará una instancia de Integration Runtime autohospedada y la asociará a una VM de Azure de la misma instancia que Azure Virtual Network en la que se encuentra el clúster de HDInsight.
Cree Integration Runtime autohospedado. Use un nombre único en caso de que exista otra instancia de Integration Runtime con el mismo nombre.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHostedEste comando crea un registro lógico de la instancia de Integration Runtime autohospedada.
Use PowerShell para recuperar las claves de autenticación y registrar la instancia de Integration Runtime autohospedada. Copie una de las claves para registrar la instancia de Integration Runtime autohospedada.
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-JsonEste es la salida de ejemplo:
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }Anote el valor de AuthKey1 sin comillas.
Cree una máquina virtual de Azure y únala a la misma red virtual que contiene el clúster de HDInsight. Para obtener más información, consulte Creación de máquinas virtuales. Únalas a una instancia de Azure Virtual Network.
En la máquina virtual de Azure, descargue la instancia de Integration Runtime autohospedada. Use la clave de autenticación que obtuvo en el paso anterior para registrar manualmente la instancia de Integration Runtime autohospedada.
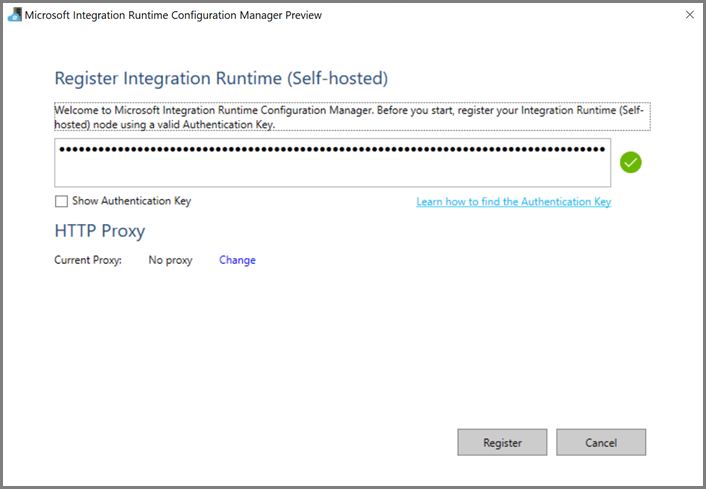
Verá el siguiente mensaje cuando el entorno de ejecución de integración autohospedado se haya registrado correctamente:
Verá la siguiente página cuando el nodo esté conectado al servicio en la nube:
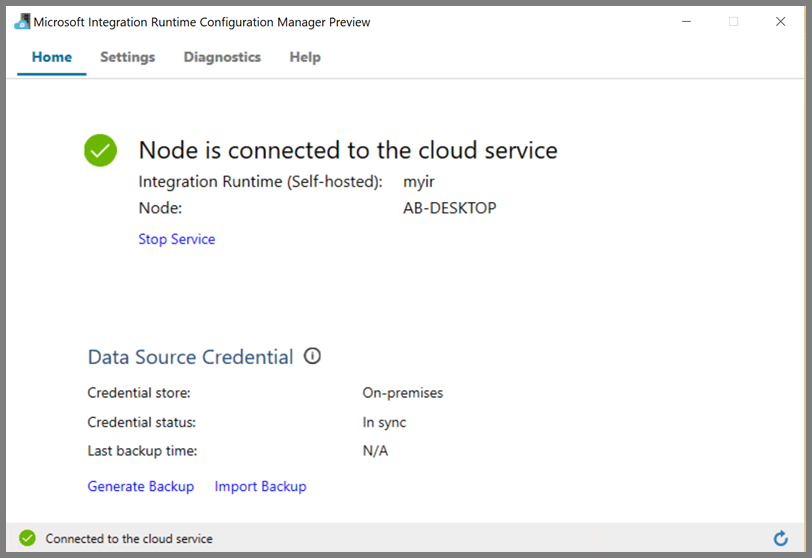
Creación de servicios vinculados
En esta sección, deberá crear e implementar dos servicios vinculados:
- Un servicio vinculado a Azure Storage que vincule una cuenta de Azure Storage con la factoría de datos. Este es el almacenamiento principal que usa el clúster de HDInsight. En este caso, también usamos esta cuenta de Azure Storage para conservar el script de Hive y la salida del script.
- Un servicio vinculado a HDInsight. Azure Data Factory envía el script de Hive a este clúster de HDInsight para su ejecución.
Servicio vinculado de Azure Storage
Cree un archivo JSON con su editor preferido, copie la siguiente definición de JSON de un servicio vinculado de Azure Storage y, a continuación, guarde el archivo como MyStorageLinkedService.json.
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Reemplace <accountname> y <accountkey> por el nombre y la clave de su cuenta de Azure Storage.
Servicio vinculado de HDInsight
Cree un archivo JSON con su editor preferido, copie la siguiente definición de JSON de un servicio vinculado de Azure HDInsight y, a continuación, guarde el archivo como MyHDInsightLinkedService.json.
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Actualice los valores de las siguientes propiedades en la definición de servicio vinculado:
username. Nombre del usuario de inicio de sesión del clúster que especificó al crear el clúster.
password. Contraseña del usuario.
clusterUri. Especifique la dirección URL de su clúster de HDInsight con el formato siguiente:
https://<clustername>.azurehdinsight.net. En este artículo, se supone que tiene acceso al clúster a través de Internet. Por ejemplo, se puede conectar al clúster enhttps://clustername.azurehdinsight.net. Esta dirección usa la puerta de enlace pública, que no está disponible si ha usado grupos de seguridad de red (NSG) o rutas definidas por el usuario (UDR) para restringir el acceso desde Internet. Para que Data Factory pueda enviar trabajos al clúster de HDInsight en Azure Virtual Network, debe configurar su instancia de Azure Virtual Network de modo que la URL pueda resolverse en la dirección IP privada de la puerta de enlace que usa HDInsight.Desde Azure Portal, abra la instancia de Virtual Network en que se encuentra HDInsight. Abra la interfaz de red con nombres que empiecen por
nic-gateway-0. Anote su dirección IP privada. Por ejemplo: 10.6.0.15.Si su instancia de Azure Virtual Network tiene un servidor DNS, actualice el registro DNS para que la dirección URL del clúster de HDInsight
https://<clustername>.azurehdinsight.netpuede resolverse en10.6.0.15. Éste es el método recomendado. Si no tiene ningún servidor DNS en su instancia de Azure Virtual Network, puede evitar este problema de forma temporal. Para ello, edite el archivo de hosts (C:\Windows\System32\drivers\etc) de todas las máquinas virtuales que se registran como nodos de la instancia de Integration Runtime autohospedado mediante la adición de una entrada similar a la siguiente:10.6.0.15 myHDIClusterName.azurehdinsight.net
Crear servicios vinculados
En PowerShell, cambie a la carpeta donde creó los archivos JSON y ejecute el siguiente comando para implementar los servicios vinculados:
En PowerShell, cambie a la carpeta donde creó los archivos JSON.
Ejecute el siguiente comando para crear un servicio vinculado de Azure Storage:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"Ejecute el siguiente comando para crear un servicio vinculado de Azure HDInsight:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
Creación de una canalización
En este paso, se crea una canalización con una actividad de Hive. La actividad ejecuta el script de Hive para devolver datos de una tabla de ejemplo y guardarlos en una ruta de acceso que haya definido. Cree un archivo JSON en el editor que prefiera, copie la siguiente definición de JSON de una definición de canalización y guárdela como MyHiveOnDemandPipeline.json.
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
Tenga en cuenta los siguientes puntos:
- scriptPath apunta a la ruta de acceso al script de Hive de la cuenta de Azure Storage que usó para MyStorageLinkedService. La ruta de acceso distingue mayúsculas de minúsculas.
- Output es un argumento que se usa en el script de Hive. Use el formato de
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/para que apunte a una carpeta existente de su instancia de Azure Storage. La ruta de acceso distingue mayúsculas de minúsculas.
Cambie a la carpeta donde creó los archivos JSON y ejecute el siguiente comando para implementar la canalización:
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
Inicio de la canalización
Inicio de la ejecución de una canalización. También se captura el id. de ejecución de la canalización para poder realizar una supervisión en un futuro.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineNameEjecute el script siguiente para comprobar continuamente el estado de ejecución de la canalización hasta que termine.
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"Este es el resultado de la ejecución de ejemplo:
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"Compruebe la carpeta
outputfolderpara ver el archivo recién creado como resultado de la consulta de Hive. Debería ser similar a la siguiente salida de ejemplo:8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
Contenido relacionado
En este tutorial, realizó los pasos siguientes:
- Creación de una factoría de datos.
- Creación y configuración de Integration Runtime autohospedado
- Creación e implementación de servicios vinculados
- Creación e implementar de una canalización que contiene una actividad de Hive
- Inicio de la ejecución de una canalización.
- Supervisión de la ejecución de la canalización
- Comprobación del resultado
Pase al tutorial siguiente para obtener información acerca de la transformación de datos mediante el uso de un clúster de Spark en Azure: