Temas avanzados de SAP CDC
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Obtenga información sobre temas avanzados para el conector CDC de SAP, como la integración de datos basada en metadatos, la depuración y mucho más.
Parametrización de un flujo de datos de asignación CDC de SAP
Uno de los puntos fuertes de las canalizaciones y los flujos de datos de asignación en Azure Data Factory y Azure Synapse Analytics es la compatibilidad con la integración de datos basada en metadatos. Con esta función, es posible diseñar una única (o varias) canalización parametrizada que pueda utilizarse para administrar la integración de cientos o incluso miles de origen. El conector SAP CDC se ha diseñado teniendo en cuenta este principio: todas las propiedades relevantes, ya sea el objeto de origen, el modo de ejecución, las columnas clave, etc., se pueden proporcionar mediante parámetros para maximizar la flexibilidad y el potencial de reutilización de los flujos de datos de asignación de SAP CDC.
Para comprender los conceptos básicos de parametrizar los flujos de datos de asignación, lea Parametrización de flujos de datos de asignación.
En la galería de plantillas de Azure Data Factory y Azure Synapse Analytics, encontrará una plantilla de canalización y flujo de datos que muestra cómo parametrizar la ingesta de datos de SAP CDC.
Parametrizar el origen y el modo de ejecución
El flujo de datos de asignación no requiere necesariamente un artefacto Dataset: tanto las transformaciones de origen como las de destino ofrecen un Tipo de origen (o tipo de Sink) Inline. En este caso, todas las propiedades de origen definidas de otro modo en un conjunto de datos ADF pueden configurarse en las Opciones de origen de la transformación de origen (o en la pestaña Configuración de la transformación de destino). El uso de un conjunto de datos insertado proporciona una mejor introducción y simplifica la parametrización de un flujo de datos de asignación, ya que la configuración completa del origen (o receptor) se mantiene en un solo lugar.
En el caso de SAP CDC, las propiedades que se suelen configurar mediante parámetros se encuentran en las pestañas Opciones de origen y Optimizar. Cuando el Tipo de origen es Inline, se pueden parametrizar las siguientes propiedades en las Opciones de origen.
-
Contexto ODP: los valores válidos de los parámetros son
- ABAP_CDS para las Vistas de los servicios de datos básicos de ABAP
- BW para SAP BW o SAP BW/4HANA InfoProviders
- HANA para las vistas de información de SAP HANA
- SAPI para fuentes de datos/extractores SAP
- cuando se utiliza SAP Landscape Transformation Replication Server (SLT) como origen, el nombre de contexto ODP es SLT~<Alias de la cola>. El valor de Alias de cola se encuentra en Datos de administración en la configuración SLT en el cockpit SLT (transacción SAP LTRC).
- ODP_SELF y RANDOM son contextos ODP utilizados para validación técnica y pruebas, y normalmente no son relevantes.
- Nombre ODP: proporcione el nombre del ODP del que desea extraer datos.
-
Modo de funcionamiento: los valores válidos de los parámetros son
- fullAndIncrementalLoad para Completo en la primera ejecución y, a continuación, incremental, que inicia un proceso de captura de datos de cambios y extrae una instantánea de datos completa actual.
- fullLoad para Full en cada ejecución, que extrae una instantánea de los datos completos actuales sin iniciar un proceso de captura de datos de cambios.
- incrementalLoad solo para cambios incrementales, que inicia un proceso de captura de datos de cambios sin extraer una instantánea completa actual.
- Columnas clave: las columnas clave se proporcionan como una matriz de cadenas (entre comillas dobles). Por ejemplo, al trabajar con la tabla SAP VBAP (posiciones de pedido de cliente), la definición de la clave tendría que ser ["VBELN", "POSNR"] (o ["MANDT", "VBELN", "POSNR"] en caso de que también se tenga en cuenta el campo del cliente).
Parametrización de las condiciones de filtro para la creación de particiones de origen
En la pestaña Optimizar, se puede definir mediante parámetros un esquema de partición de origen (consulte optimización del rendimiento para cargas completas o iniciales). Por lo general, se requieren dos pasos:
- Defina el esquema de partición de origen.
- Introducir el parámetro de partición en el flujo de datos de asignación.
Definir un esquema de partición de origen
El formato del paso 1 sigue el estándar JSON y consiste en una matriz de definiciones de particiones, cada una de las cuales es a su vez una matriz de condiciones de filtro individuales. Estas condiciones en sí son objetos JSON con una estructura alineada con las llamadas opciones de selección en SAP. De hecho, el formato requerido por el marco SAP ODP es básicamente el mismo que los filtros de autoedición dinámicos en SAP BW:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
Por ejemplo,
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
corresponde a una cláusula SQL WHERE ... WHERE "VBELN" = "0000001000", o bien
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
corresponde a una cláusula SQL WHERE ... WHERE "VBELN" BETWEEN "0000000000" y "0000001000”
Una definición JSON de un esquema de partición que contenga dos particiones tiene el siguiente aspecto
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
donde la primera partición contiene los ejercicios fiscales (GJAHR) 2011 a 2015, y la segunda partición contiene los ejercicios fiscales 2016 a 2020.
Nota
Azure Data Factory no realiza ninguna comprobación de estas condiciones. Por ejemplo, es responsabilidad del usuario asegurarse de que las condiciones de partición no se solapan.
Las condiciones de partición pueden ser más complejas y constar de varias condiciones de filtro elementales. No existen conjunciones lógicas que definan explícitamente cómo combinar múltiples condiciones elementales dentro de una partición. La definición implícita en SAP es la siguiente:
- incluyendo las condiciones ("sign": "I") para el mismo nombre de campo se combinan con OR (mentalmente, ponga entre paréntesis la condición resultante)
- excluyendo las condiciones ("sign": "E") para el mismo nombre de campo se combinan con OR (de nuevo, mentalmente, ponga entre paréntesis la condición resultante)
- las condiciones resultantes de los pasos 1 y 2 son
- combinado con AND para incluir condiciones,
- combinado con AND NOT para excluir condiciones.
Como por ejemplo, la condición de partición
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
corresponde a una cláusula SQL WHERE ... WHERE ("BUKRS" = '1000' OR "BUKRS" = '1010') AND ("GJAHR" BETWEEN '2010' AND '2025') AND NOT ("GJAHR" = '2021' or "GJARH" = '2023')
Nota:
Asegúrese de utilizar el formato interno de SAP para los valores bajos y altos, incluya ceros a la izquierda y exprese las fechas del calendario como una cadena de ocho caracteres con el formato "AAAAMMDD".
Introducción del parámetro de partición en el flujo de datos de asignación
Para introducir el esquema de partición en un flujo de datos de asignación, cree un parámetro de flujo de datos (por ejemplo, "sapPartitions"). Para pasar el formato JSON a este parámetro, hay que convertirlo a cadena mediante la función @string():
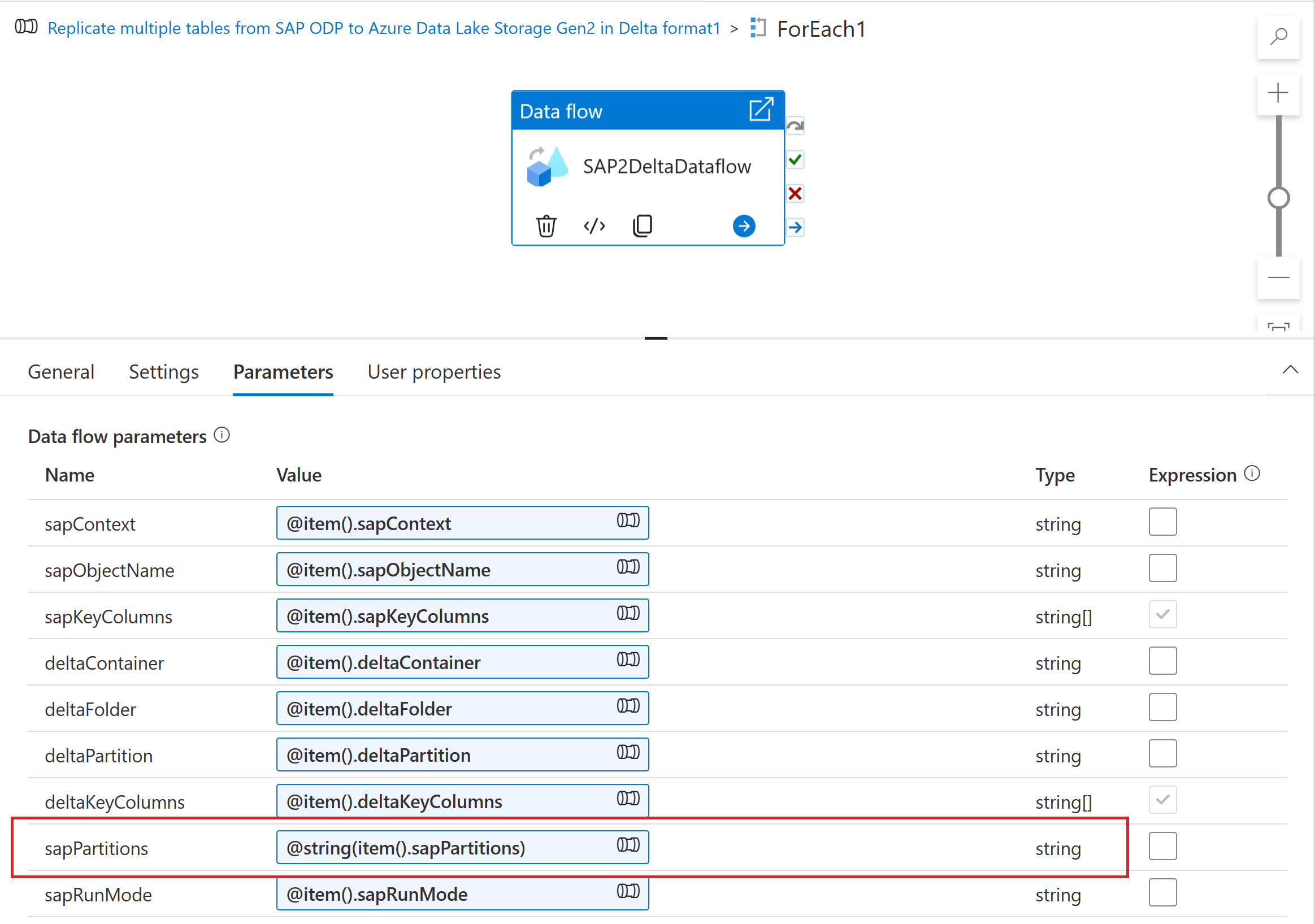
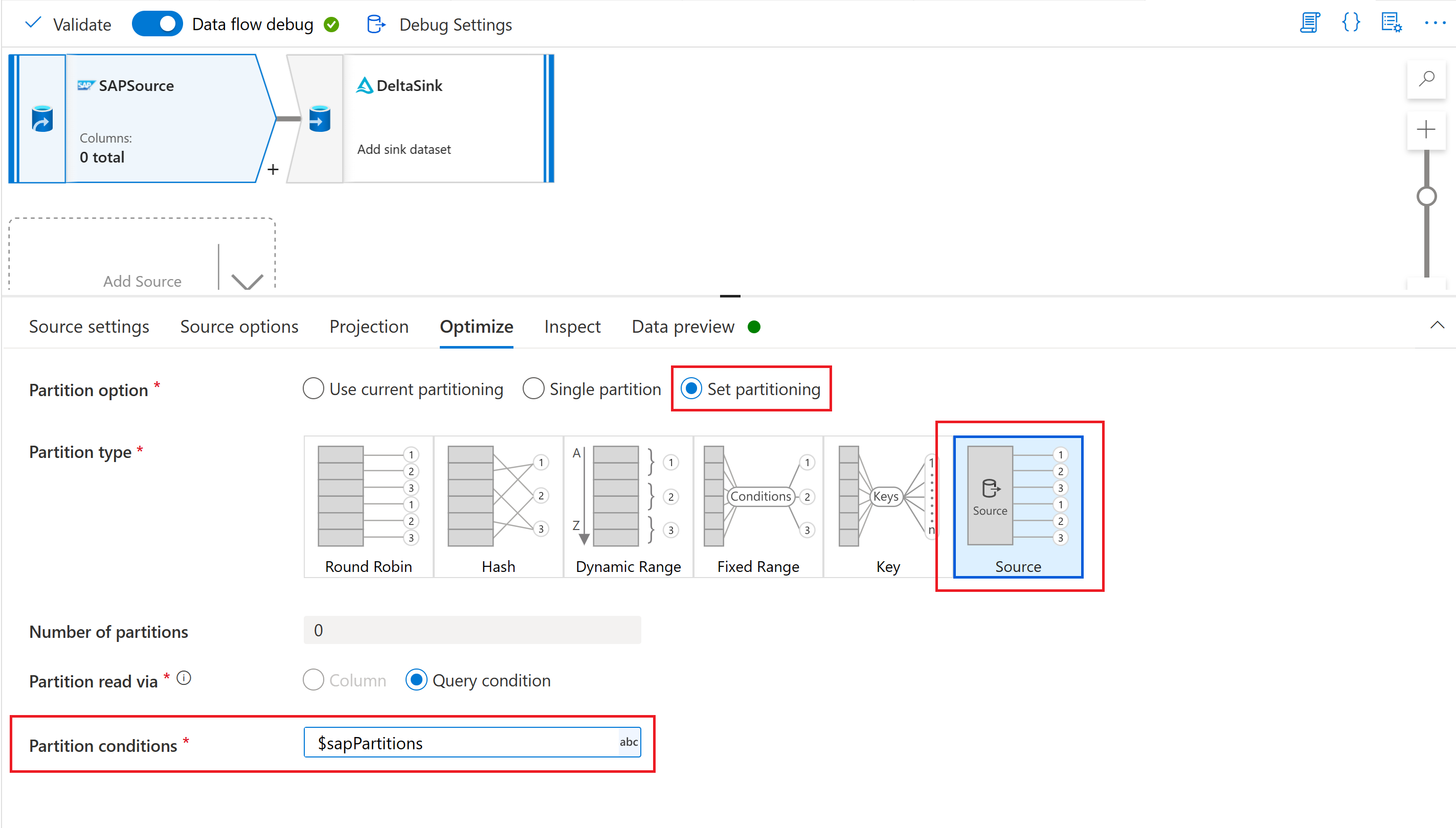
Por último, en la pestaña optimizar de la transformación de origen de su flujo de datos de asignación, seleccione Tipo de partición "Origen" e introduzca el parámetro de flujo de datos en la propiedad Condiciones de partición.
Parametrización de la clave de punto de control
Cuando se utiliza un flujo de datos parametrizado para extraer datos de múltiples fuentes SAP CDC, es importante parametrizar la Clave de punto de control en la actividad de flujo de datos de la canalización. Azure Data Factory utiliza la clave de punto de control para administrar el estado de un proceso de captura de datos de cambios. Para evitar que el estado de un proceso CDC sobrescriba el estado de otro, asegúrese de que los valores de la clave de control son únicos para cada conjunto de parámetros utilizado en un flujo de datos.
Nota
Una mejor práctica para asegurar la singularidad de la Clave de punto de control es agregar el valor de la clave de punto de control al conjunto de parámetros para su flujo de datos.
Para más información sobre la clave de punto de control, consulte Transformar datos con el conector SAP CDC.
Depuración
Las canalizaciones de Azure Data Factory pueden ejecutarse mediante ejecuciones activadas o de depuración. Una diferencia fundamental entre estas dos opciones es que las ejecuciones de depuración ejecutan el flujo de datos y la canalización basándose en la versión actual modelada en la interfaz de usuario, mientras que las ejecuciones activadas ejecutan la última versión publicada de un flujo de datos y una canalización.
Para SAP CDC, hay un aspecto más que debe entenderse: para evitar un impacto de las ejecuciones de depuración en un proceso de captura de datos de cambios existente, las ejecuciones de depuración utilizan un valor de "proceso de suscriptor" diferente (consulte Supervisión de los flujos de datos de SAP CDC) que las ejecuciones activadas. Así, crean suscripciones separadas (es decir, procesos de captura de datos de modificación) dentro del sistema SAP. Además, el valor "proceso de abonado" para las ejecuciones de depuración tiene un tiempo de vida limitado a la sesión de la interfaz de usuario del navegador.
Nota
Para probar la estabilidad de un proceso de captura de datos de cambios con SAP CDC durante un período de tiempo más largo (digamos, varios días), es necesario publicar el flujo de datos y la canalización, y ejecutar ejecuciones activadas.