Desarrollo iterativo y depuración con canalizaciones de Azure Data Factory y Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Azure Data Factory y Synapse Analytics admiten el desarrollo iterativo y la depuración de canalizaciones. Estas características le permiten probar los cambios antes de crear una solicitud de incorporación de cambios o publicarlos en el servicio.
Si desea una introducción y demostración de ocho minutos de esta característica, vea el siguiente vídeo:
Depuración de una canalización
A medida que realiza sus creaciones utilizando el lienzo de la canalización, puede probar sus actividades con la funcionalidad Depurar. Cuando realiza las series de pruebas, no es necesario que publique los cambios que se realizaron en el servicio antes de seleccionar Depurar. Esta característica resulta útil en escenarios en los que se quiere garantizar que los cambios funcionen según lo esperado antes de actualizar el flujo de trabajo.
Mientras se ejecuta la canalización, puede ver los resultados de cada actividad en la pestaña Salida del lienzo de la canalización.
Consulte los resultados de las series de pruebas en la ventana Salida del lienzo de la canalización.
Después de realizar correctamente una serie de pruebas, agregue más actividades a la canalización y continúe con la depuración de manera iterativa. También puede cancelar una serie de pruebas mientras está en curso.
Importante
Al seleccionar Depurar, se ejecuta la canalización. Por ejemplo, si la canalización contiene actividad de copia, la serie de pruebas copia datos del origen al destino. Como resultado, se recomienda usar las carpetas de prueba en las actividades de copia y otras actividades cuando se realice la depuración. Una vez que se depure la canalización, cambie a las carpetas reales que desea usar en las operaciones normales.
Establecimiento de puntos de interrupción
El servicio también permite realizar la depuración hasta alcanzar una actividad concreta en el lienzo de la canalización. Ubique un punto de interrupción en la actividad que indique hasta donde desea probar y seleccione Depurar. El servicio garantiza que las pruebas se ejecutan solo hasta la actividad de punto de interrupción en el lienzo de la canalización. Esta característica Debug Until (Depurar hasta) resulta útil cuando no desea probar toda la canalización, sino solo un subconjunto de actividades dentro de la canalización.
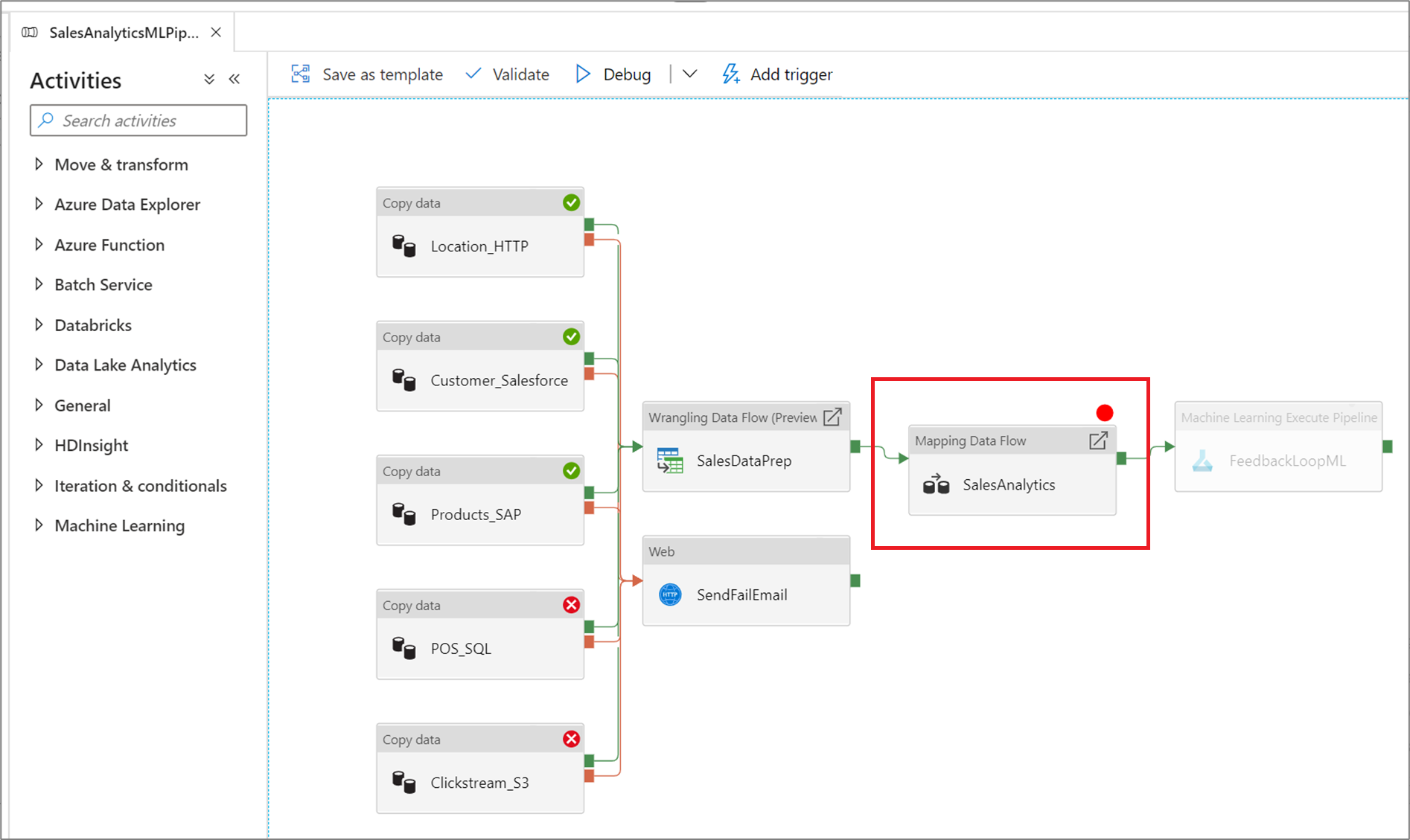
Para establecer un punto de interrupción, seleccione un elemento en el lienzo de la canalización. La opción Depurar hasta aparece como un círculo rojo vacío en la esquina superior derecha del elemento.
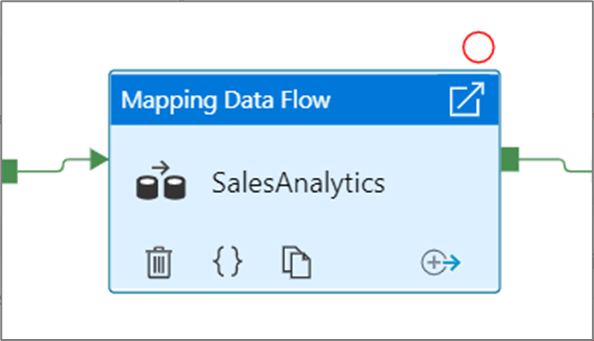
Tras seleccionar la opción Depurar hasta, cambia a un círculo de color rojo con relleno para indicar que el punto de interrupción está habilitado.
Supervisión de ejecuciones de depuración
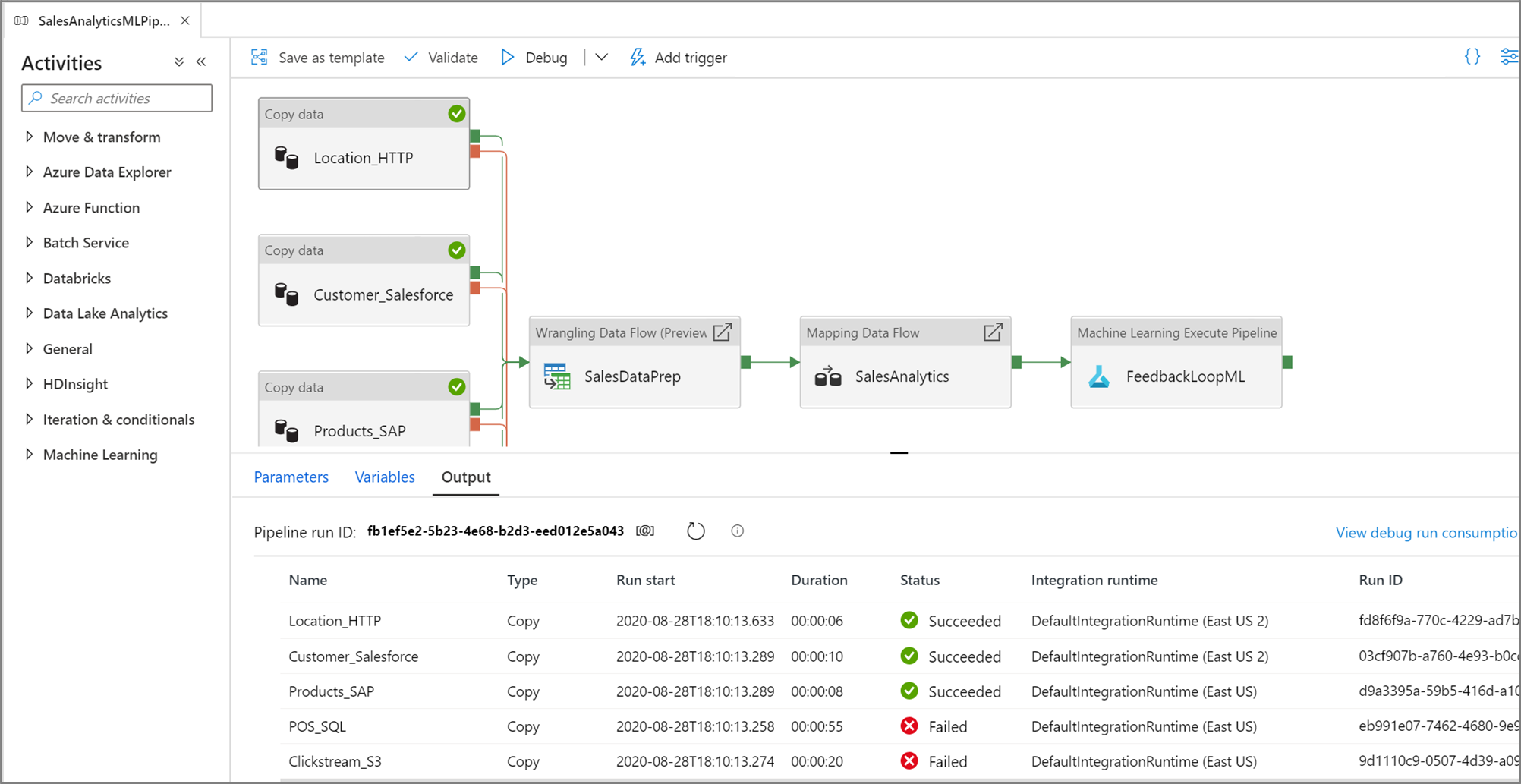
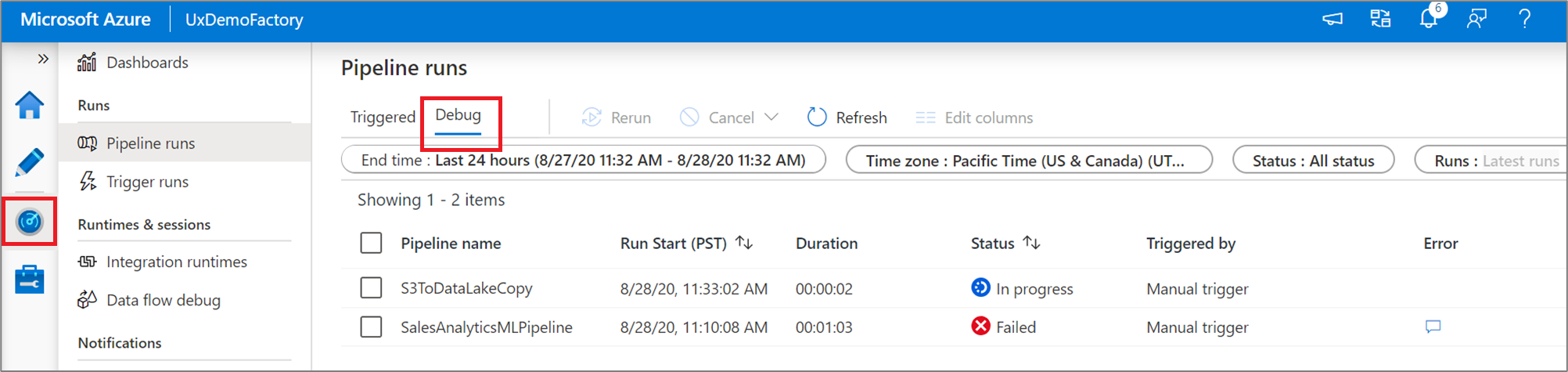
Al realizar una ejecución de depuración de canalización, los resultados aparecerán en la ventana Salida del lienzo de la canalización. La pestaña Salida solo contendrá la ejecución más reciente que se haya producido durante la sesión actual del explorador.
Para ver una vista histórica de las ejecuciones de depuración o ver una lista de todas las ejecuciones de depuración activas, puede entrar en el experiencia Supervisar.
Nota
El servicio solo conserva el historial de ejecución de depuraciones durante 15 días.
Depuración de flujos de datos de asignación
Los flujos de datos de asignación le permiten crear lógica de transformación de datos sin código que se ejecuta a escala. Al crear la lógica, puede activar una sesión de depuración para trabajar de forma interactiva con los datos mediante un clúster de Spark en vivo. Para obtener más información, lea acerca del modo de depuración del flujo de datos de asignación.
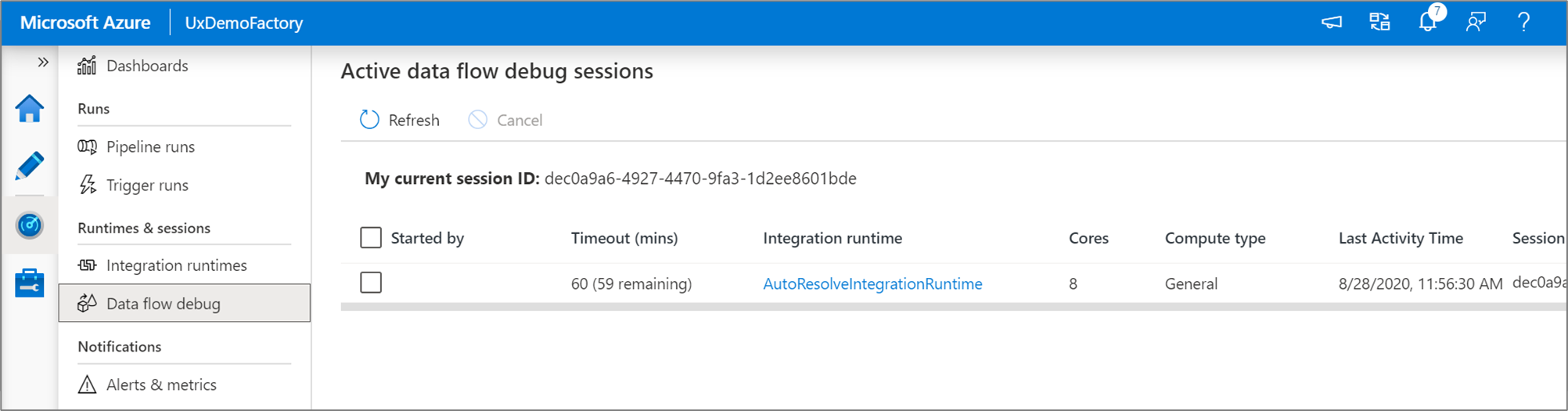
Puede supervisar las sesiones de depuración del flujo de datos activas en la experiencia Supervisar.
La vista previa de los datos en el diseñador de flujo de datos y la depuración de la canalización de flujos de datos están diseñadas para ofrecer el máximo rendimiento con muestras de datos pequeñas. Sin embargo, si necesita probar la lógica de una canalización o de un flujo de datos con grandes cantidades de datos, aumente el tamaño de la instancia de Azure Integration Runtime utilizada en la sesión de depuración con más núcleos y un proceso mínimo de uso general.
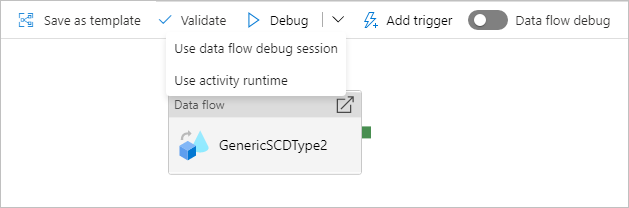
Depuración de una canalización con una actividad de flujo de datos
Al ejecutar una canalización de depuración con un flujo de datos, tiene dos opciones sobre qué proceso utilizar. Puede usar un clúster de depuración existente o poner en marcha un nuevo clúster Just-in-Time para los flujos de datos.
El uso de una sesión de depuración existente reducirá considerablemente el tiempo de inicio del flujo de datos puesto que el clúster ya se está ejecutando, pero no se recomienda para cargas de trabajo complejas o paralelas, ya que puede producir un error cuando se ejecutan varios trabajos a la vez.
El uso del entorno de ejecución de actividad creará un nuevo clúster con la configuración especificada en el entorno de ejecución de integración de cada actividad de flujo de datos. Esto permite aislar cada trabajo y debe usarse para cargas de trabajo complejas o pruebas de rendimiento. También puede controlar el TTL en Azure IR para que los recursos de clúster usados para la depuración sigan estando disponibles durante ese período de tiempo para atender solicitudes de trabajo adicionales.
Nota
Si tiene una canalización con flujos de datos que se ejecutan en paralelo o flujos de datos que deben probarse con grandes conjuntos de datos, elija "Use Activity Runtime" (Usar tiempo de ejecución de la actividad) para que el servicio pueda usar el entorno de Integration Runtime que ha seleccionado en la actividad del flujo de datos. Esto permitirá que los flujos de datos se ejecuten en varios clústeres y puedan adaptarse a las ejecuciones de flujo de datos paralelas.
Contenido relacionado
Después de probar los cambios, promuévalos a entornos más altos mediante integración e implementación continuas.