Copia de datos desde y en Oracle mediante Azure Data Factory o Azure Synapse Analytics
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se resume el uso de la actividad de copia de Azure Data Factory para copiar datos con una base de datos Oracle como origen o destino. Se basa en la introducción a la actividad de copia.
Funcionalidades admitidas
El conector de Oracle es compatible con las siguientes funcionalidades:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/receptor) | ① ② |
| Actividad de búsqueda | ① ② |
| Actividad de script | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Consulte la tabla de almacenes de datos compatibles para ver una lista de almacenes de datos que la actividad de copia admite como orígenes o receptores.
En concreto, este conector de Oracle admite lo siguiente:
- Las siguientes versiones de una base de datos de Oracle:
- Oracle 19c R1 (19.1) y superior
- Oracle 18c R1 (18.1) y superior
- Oracle 12c R1 (12.1) y superior
- Oracle 11g R1 (11.1) y superior
- Oracle 10g R1 (10.1) y superior
- Oracle 9i R2 (9.2) y superior
- Oracle 8i R3 (8.1.7) y superior
- Oracle Database Cloud Exadata Service
- Copia en paralelo desde un origen de Oracle. Consulte la sección Copia en paralelo desde Oracle para obtener más detalles.
Nota
El servidor proxy de Oracle no se admite.
Prerrequisitos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
El entorno de ejecución de integración proporciona un controlador de Oracle integrado. Por tanto, no es necesario instalar manualmente un controlador para copiar datos con Oracle como origen y destino.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado en Oracle mediante la interfaz de usuario
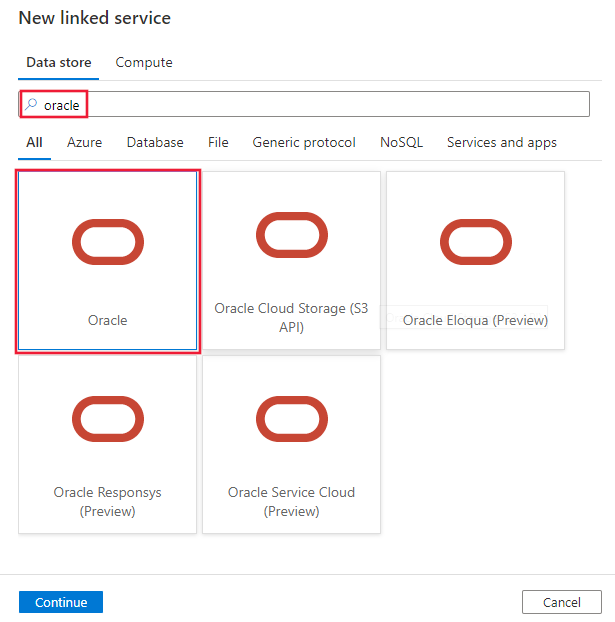
Siga estos pasos para crear un servicio vinculado en Oracle en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Oracle y seleccione el conector de Oracle.
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
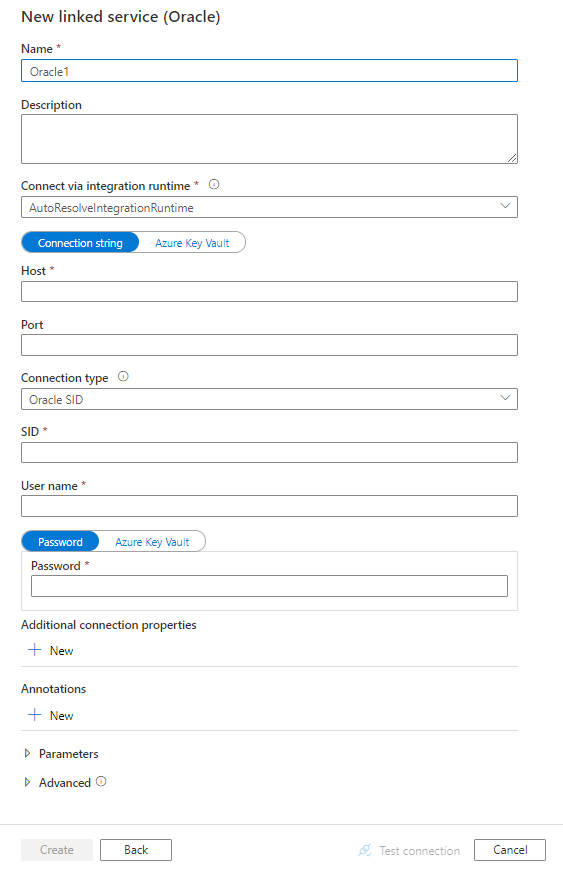
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades específicas para el conector de Oracle.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado Oracle:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type se debe establecer en: Oracle. | Sí |
| connectionString | Especifica la información necesaria para conectarse a la instancia de Oracle Database. También puede poner una contraseña en Azure Key Vault y extraer la configuración de password de la cadena de conexión. Consulte los siguientes ejemplos y el artículo Almacenamiento de credenciales en Azure Key Vault con información detallada. Tipo de conexión admitido: para identificar su base de datos, puede usar el SID de Oracle o el nombre de servicio de Oracle: - Si usa el SID: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;- Si usa el nombre del servicio: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;Para las opciones avanzadas de conexión nativa de Oracle, puede optar por agregar una entrada en el archivo TNSNAMES.ORA de la máquina en la que está instalado el entorno de ejecución de integración autohospedado y, en el servicio vinculado de Oracle, elegir usar el tipo de conexión Nombre de servicio de Oracle y configurar el nombre de servicio correspondiente. |
Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Sugerencia
Si recibe un error, "ORA-01025: parámetro UPI fuera del intervalo" y tiene la versión 8i de Oracle, agregue WireProtocolMode=1 a la cadena de conexión. A continuación, inténtelo de nuevo.
Si tiene varias instancias de Oracle para el escenario de conmutación por error, puede crear un servicio vinculado de Oracle y rellenar el host principal, el puerto, el nombre de usuario, la contraseña, entre otros, y agregar una nueva sección "Propiedades de conexión adicionales" con el nombre de propiedad AlternateServers y el valor (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>); no olvide los corchetes y ponga atención al uso de dos puntos (:) como separadores. Por ejemplo, el siguiente valor de servidores alternativos define dos servidores de bases de datos alternativos para la conmutación por error de conexiones: (HostName=AccountingOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Puede establecer más propiedades de conexión en la cadena de conexión, según su caso:
| Propiedad | Descripción | Valores permitidos |
|---|---|---|
| ArraySize | El número de bytes que el conector puede capturar en un solo recorrido de ida y vuelta de red. Por ejemplo, ArraySize=10485760.Los valores mayores aumentan la capacidad de proceso al reducir el número de veces que se capturan los datos en la red. Los valores más pequeños aumentan el tiempo de respuesta, ya que hay menos retraso en la espera para que el servidor transmita datos. |
Entero de 1 a 4294967296 (4 GB). El valor predeterminado es 60000. El valor 1 no define el número de bytes, sino que indica que se asigna espacio para exactamente una fila de datos. |
Para habilitar el cifrado en la conexión de Oracle, tiene dos opciones:
Para usar el cifrado Triple-DES (3DES) y el Estándar de cifrado avanzado (AES) , en el lado servidor de Oracle, vaya a Oracle Advanced Security (OAS) y configure las opciones de cifrado. Para más información, consulte esta documentación de Oracle. El conector de Oracle Application Development Framework (ADF) negocia automáticamente el método de cifrado para usar el que configura en OAS al establecer la conexión con Oracle.
Para usar TLS, configure
truststorepara la autenticación de servidor SSL aplicando uno de los tres métodos siguientes:Método 1 (recomendado)::
Instale el certificado TLS/SSL importándolo en el almacén de certificados local. El controlador de Oracle integrado puede cargar el certificado necesario desde el almacén de certificados.
En el servicio, configure la cadena de conexión de Oracle con
EncryptionMethod=1.
Método 2:
Obtenga la información del certificado TLS/SSL. Obtenga la información de certificado con codificación distintivo (DER) o correo mejorado de privacidad (PEM) de su certificado TLS/SSL.
openssl x509 -inform (DER|PEM) -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -textEn el servicio, configure la cadena de conexión de Oracle con
EncryptionMethod=1y el valor correspondienteTrustStore. Por ejemplo:Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore= data:// -----BEGIN CERTIFICATE-----<certificate content>-----END CERTIFICATE-----Nota:
- El valor del campo
TrustStoredebe tener el prefijodata://. - Al especificar contenido para varios certificados, especifique el contenido de cada certificado entre
-----BEGIN CERTIFICATE-----y-----END CERTIFICATE-----. El número de guiones (-----) debe ser el mismo antes y después deBEGIN CERTIFICATEyEND CERTIFICATE. Por ejemplo:
-----BEGIN CERTIFICATE-----<certificate content 1>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 2>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 3>-----END CERTIFICATE----- - El campo
TrustStoreadmite contenido de hasta 8192 caracteres de longitud.
- El valor del campo
Método 3:
Cree el
truststorearchivo con cifrados seguros como AES256.openssl pkcs12 -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -keypbe AES-256-CBC -certpbe AES-256-CBC -nokeys -exportColoque el archivo
truststoreen la máquina de ejecución de integración autoalojada. Por ejemplo, coloque el archivo enC:\MyTrustStoreFile.En el servicio, configure la cadena de conexión de Oracle con
EncryptionMethod=1y el valor correspondienteTrustStore/TrustStorePassword. Por ejemplo,Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Ejemplo:
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: Almacenamiento de la contraseña en Azure Key Vault
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de Oracle. Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte Conjuntos de datos.
Para copiar datos con Oracle como origen o destino, establezca la propiedad type del conjunto de datos en OracleTable. Se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en OracleTable. |
Sí |
| esquema | Nombre del esquema. | No para el origen, sí para el receptor |
| table | Nombre de la tabla o vista. | No para el origen, sí para el receptor |
| tableName | Nombre de la tabla o vista con el esquema. Esta propiedad permite la compatibilidad con versiones anteriores. Para la nueva carga de trabajo use schema y table. |
No para el origen, sí para el receptor |
Ejemplo:
{
"name": "OracleDataset",
"properties":
{
"type": "OracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propiedades de la actividad de copia
En esta sección se proporciona una lista de las propiedades que admiten el receptor y el origen Oracle. Para ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte Canalizaciones.
Oracle como origen
Sugerencia
Consulte más información en Copia en paralelo desde Oracle para cargar datos desde Oracle de manera eficaz con la creación de particiones de datos.
Para copiar datos desde Oracle, establezca el tipo de origen de la actividad de copia en OracleSource. En la sección source de la actividad de copia se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en OracleSource. |
Sí |
| oracleReaderQuery | Use la consulta SQL personalizada para leer los datos. Un ejemplo es "SELECT * FROM MyTable".Si habilita la carga con particiones, deberá enlazar todos los parámetros de partición integrados correspondientes en la consulta. Consulte la sección Copia en paralelo desde Oracle para obtener algunos ejemplos. |
No |
| convertDecimalToInteger | El tipo NUMBER de Oracle con escala cero o sin especificar se convertirá en el entero correspondiente. Los valores permitidos son true y false (predeterminado). | No |
| partitionOptions | Especifica los opciones de creación de particiones de datos que se usan para cargar datos desde Oracle. Los valores permitidos son: None (valor predeterminado), PhysicalPartitionsOfTable y DynamicRange. Cuando se habilita una opción de partición (es decir, no None), el grado de paralelismo para cargar simultáneamente datos de una base de datos Oracle se controla mediante la configuración parallelCopies en la actividad de copia. |
No |
| partitionSettings | Especifique el grupo de configuración para la creación de particiones de datos. Se aplica si la opción de partición no es None. |
No |
| partitionNames | Lista de particiones físicas que deben copiarse. Se aplica si la opción de partición es PhysicalPartitionsOfTable. Si usa una consulta para recuperar datos de origen, enlace ?AdfTabularPartitionName en la cláusula WHERE. Consulte la sección Copia en paralelo desde Oracle para ver un ejemplo. |
No |
| partitionColumnName | Especifique el nombre de la columna de origen in integer type que usará la creación de particiones por rangos para la copia en paralelo. Si no se especifica, se detectará automáticamente la clave principal de la tabla y se usará como columna de partición. Se aplica si la opción de partición es DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?AdfRangePartitionColumnName en la cláusula WHERE. Consulte la sección Copia en paralelo desde Oracle para ver un ejemplo. |
No |
| partitionUpperBound | El valor máximo de la columna de partición para copiar datos. Se aplica si la opción de partición es DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?AdfRangePartitionUpbound en la cláusula WHERE. Consulte la sección Copia en paralelo desde Oracle para ver un ejemplo. |
No |
| partitionLowerBound | El valor mínimo de la columna de partición para copiar datos. Se aplica si la opción de partición es DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?AdfRangePartitionLowbound en la cláusula WHERE. Consulte la sección Copia en paralelo desde Oracle para ver un ejemplo. |
No |
Ejemplo: copia de datos mediante una consulta básica sin partición
"activities":[
{
"name": "CopyFromOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "OracleSource",
"convertDecimalToInteger": false,
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Oracle como receptor
Si va a copiar datos en Oracle, establezca el tipo de receptor de la actividad de copia en OracleSink. En la sección sink de la actividad de copia se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en OracleSink. |
Sí |
| writeBatchSize | Inserta datos en la tabla SQL cuando el tamaño del búfer alcanza el valor de writeBatchSize.Los valores permitidos son: enteros (número de filas). |
No (el valor predeterminado es 10 000) |
| writeBatchTimeout | Tiempo de espera para que la operación de inserción por lotes se complete antes de que se agote el tiempo de espera. Los valores permitidos son intervalos de tiempo. Un ejemplo es 00:30:00 (30 minutos). |
No |
| preCopyScript | Especifique una consulta SQL para que la actividad de copia se ejecute antes de escribir datos en Oracle en cada ejecución. Puede usar esta propiedad para limpiar los datos cargados previamente. | No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyToOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Oracle output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "OracleSink"
}
}
}
]
Copia en paralelo desde Oracle
El conector de Oracle proporciona creación de particiones de datos integrada para copiar datos de Oracle en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.

Al habilitar la copia con particiones, el servicio ejecuta consultas en paralelo en el origen de Oracle para cargar los datos mediante particiones. El grado en paralelo se controla mediante el valor parallelCopies de la actividad de copia. Por ejemplo, si establece parallelCopies en cuatro, el servicio genera y ejecuta al mismo tiempo cuatro consultas de acuerdo con la configuración y la opción de partición que ha especificado, y cada consulta recupera una porción de datos de la base de datos de Oracle.
Se le sugiere que habilite la copia en paralelo con la creación de particiones de datos, especialmente si carga grandes cantidades de datos de su base de datos de Oracle. Estas son algunas configuraciones sugeridas para diferentes escenarios. Cuando se copian datos en un almacén de datos basado en archivos, se recomienda escribirlos en una carpeta como varios archivos (solo especifique el nombre de la carpeta), en cuyo caso el rendimiento es mejor que escribirlos en un único archivo.
| Escenario | Configuración sugerida |
|---|---|
| Carga completa de una tabla grande con particiones físicas. |
Opción de partición: particiones físicas de la tabla. Durante la ejecución, el servicio detecta automáticamente las particiones físicas y copia los datos por particiones. |
| Carga completa de una tabla grande, sin particiones físicas, aunque con una columna de enteros para la creación de particiones de datos. |
Opciones de partición: partición por rangos dinámica. Columna de partición: especifique la columna usada para crear la partición de datos. Si no se especifica, se usa la columna de clave principal. |
| Cargue una gran cantidad de datos mediante una consulta personalizada con particiones físicas. |
Opción de partición: particiones físicas de la tabla. Consulta: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>.Nombre de la partición: especifique los nombres de las particiones desde las que se copiarán los datos. Si no se especifican, el servicio detecta automáticamente las particiones físicas en la tabla que ha especificado en el conjunto de datos de Oracle. Durante la ejecución, el servicio reemplaza ?AdfTabularPartitionName por el nombre real de la partición y se lo envía a Oracle. |
| Carga de grandes cantidades de datos mediante una consulta personalizada, sin particiones físicas, aunque cuenta con una columna de enteros para la creación de particiones de datos. |
Opciones de partición: partición por rangos dinámica. Consulta: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para crear la partición de datos. Puede crear particiones en la columna con un tipo de datos entero. Límite de partición superior y límite de partición inferior: especifique si quiere filtrar en la columna de partición para recuperar solo los datos entre el intervalo inferior y el superior. Durante la ejecución, el servicio reemplaza ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound y ?AdfRangePartitionLowbound por el nombre real de la columna y los rangos de valores de cada partición y se los envía a Oracle. Por ejemplo, si establece la columna de partición "ID" con un límite inferior de 1 y un límite superior de 80, con la copia en paralelo establecida en 4, el servicio recupera los datos de 4 particiones. Los identificadores están comprendidos entre [1, 20], [21, 40], [41, 60] y [61, 80] respectivamente. |
Sugerencia
Al copiar datos de una tabla sin particiones, puede usar la opción de partición "Dynamic range" (Intervalo dinámico) para crear particiones en una columna de enteros. Si los datos de origen no tienen este tipo de columna, puede aprovechar la función ORA_HASH de la consulta de origen para generar una columna y usarla como columna de partición.
Ejemplo: consulta con partición física
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Ejemplo: consulta con partición por rangos dinámica
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Asignación de tipos de datos para Oracle
Al copiar datos desde y en Oracle, se usan las siguientes asignaciones de tipos de datos provisionales dentro del servicio. Para más información acerca de la forma en que la actividad de copia asigna el tipo de datos y el esquema de origen al receptor, consulte el artículo sobre asignaciones de tipos de datos y esquema.
| Tipo de datos de Oracle | Tipo de datos provisional |
|---|---|
| BFILE | Byte[] |
| BLOB | Byte[] (solo se admite en Oracle 10g y versiones posteriores) |
| CHAR | String |
| CLOB | String |
| DATE | DateTime |
| FLOAT | Decimal, String (si la precisión > 28) |
| INTEGER | Decimal, String (si la precisión > 28) |
| LONG | String |
| LONG RAW | Byte[] |
| NCHAR | String |
| NCLOB | String |
| NUMBER (p,s) | Decimal, String (si p > 28) |
| NUMBER sin precisión ni escala | Double |
| NVARCHAR2 | String |
| RAW | Byte[] |
| ROWID | String |
| TIMESTAMP | DateTime |
| TIMESTAMP WITH LOCAL TIME ZONE | String |
| TIMESTAMP WITH TIME ZONE | String |
| UNSIGNED INTEGER | Number |
| VARCHAR2 | String |
| XML | String |
Nota:
Los tipos de datos INTERVAL YEAR TO MONTH e INTERVAL DAY TO SECOND no son compatibles.
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Contenido relacionado
Para obtener una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos que se admiten.