Copia de datos de Amazon Redshift mediante Azure Data Factory o Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se resume el uso de la actividad de copia en canalizaciones de Azure Data Factory y Synapse Analytics para copiar datos de Amazon Redshift. El documento se basa en el artículo de introducción a la actividad de copia que describe información general de la actividad de copia.
Funcionalidades admitidas
Este conector de Amazon Redshift se admite para las siguientes características:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/-) | ① ② |
| Actividad de búsqueda | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Consulte la tabla de almacenes de datos compatibles para ver una lista de almacenes de datos que la actividad de copia admite como orígenes o receptores.
En concreto, este conector de Amazon Redshift admite la recuperación de datos de Redshift mediante una consulta o la compatibilidad integrada con Redshift UNLOAD.
El conector admite las versiones de Windows de este artículo.
Sugerencia
Para obtener el mejor rendimiento al copiar grandes cantidades de datos desde Redshift, considere usar Redshift UNLOAD integrado a través de Amazon S3. Vea la sección Uso de UNLOAD para copiar datos de Amazon Redshift para más detalles.
Prerrequisitos
- Si va a copiar datos a un local almacén de datos local mediante Integration Runtime autohospedado, conceda a Integration Runtime (use la dirección IP de la máquina) el acceso al clúster de Amazon Redshift. Consulte Authorize access to the cluster (Autorización para acceder al clúster) para obtener instrucciones.
- Si va a copiar datos a un almacén de datos de Azure, consulte Azure Data Center IP Ranges (Intervalos de direcciones IP de Azure Data Center) para ver los intervalos de direcciones IP de Compute y los intervalos SQL que se utilizan en los centros de datos de Azure.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado a Amazon Redshift mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado a Amazon Redshift en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Amazon y seleccione el conector Amazon Redshift.
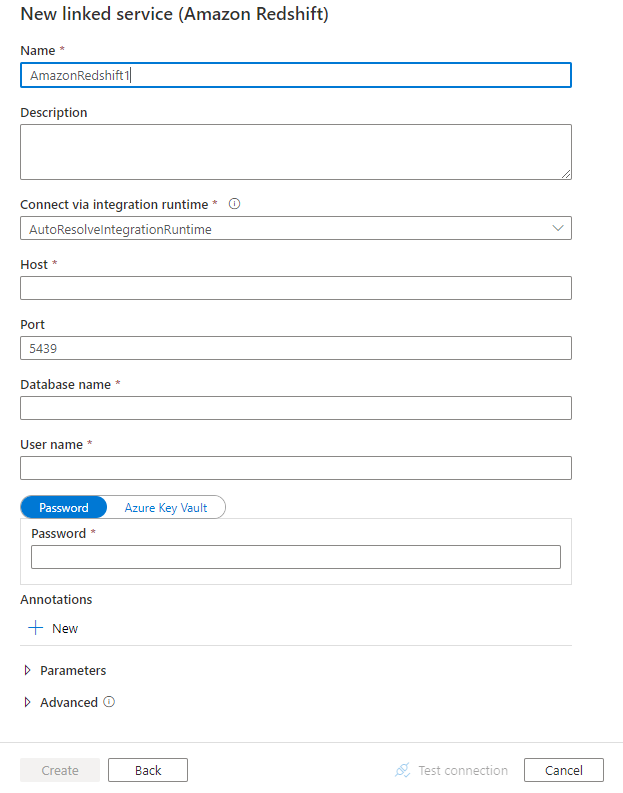
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de Data Factory específicas del conector de Amazon Redshift.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado Amazon Redshift:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en: AmazonRedshift | Sí |
| server | Dirección IP o nombre de host del servidor de Amazon Redshift. | Sí |
| port | El número del puerto TCP que el servidor de Amazon Redshift utiliza para escuchar las conexiones del cliente. | No, el valor predeterminado es 5439 |
| database | Nombre de la base de datos de Amazon Redshift. | Sí |
| username | Nombre del usuario que tiene acceso a la base de datos. | Sí |
| password | Contraseña para la cuenta de usuario. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | Sí |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Puede usar los entornos Integration Runtime (autohospedado) (si el almacén de datos se encuentra en una red privada) o Azure Integration Runtime. Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplo:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades que el conjunto de datos de Amazon Redshift admite.
Para copiar datos de Amazon Redshift, se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en: AmazonRedshiftTable | Sí |
| esquema | Nombre del esquema. | No (si se especifica "query" en el origen de la actividad) |
| table | Nombre de la tabla. | No (si se especifica "query" en el origen de la actividad) |
| tableName | Nombre de la tabla con el esquema. Esta propiedad permite la compatibilidad con versiones anteriores. Use schema y table para la carga de trabajo nueva. |
No (si se especifica "query" en el origen de la actividad) |
Ejemplo
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Si estaba usando un conjunto de datos de tipo RelationalTable, todavía se admite tal cual, aunque se aconseja usar el nuevo en el futuro.
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que el origen Amazon Redshift admite.
Amazon Redshift como origen
Para copiar datos desde Amazon Redshift, establezca el tipo de origen de la actividad de copia en AmazonRedshiftSource. Se admiten las siguientes propiedades en la sección source de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en: AmazonRedshiftSource | Sí |
| Query | Utilice la consulta personalizada para leer los datos. Por ejemplo: select * from MyTable. | No (si se especifica "tableName" en el conjunto de datos) |
| redshiftUnloadSettings | Grupo de propiedades al usar Amazon Redshift UNLOAD. | No |
| s3LinkedServiceName | Hace referencia a Amazon S3 que se usa como almacenamiento provisional especificando para ello un nombre de servicio vinculado de tipo "AmazonS3". | Sí, se utiliza UNLOAD |
| bucketName | Indique el depósito S3 para almacenar los datos provisionales. Si no se proporciona, el servicio lo genera automáticamente. | Sí, se utiliza UNLOAD |
Ejemplo: Origen Amazon Redshift de la actividad de copia mediante UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Obtenga más información en la sección siguiente sobre cómo usar UNLOAD para copiar datos desde Amazon Redshift de forma eficaz.
Uso de UNLOAD para copiar datos de Amazon Redshift
UNLOAD es un mecanismo proporcionado por Amazon Redshift, que puede descargar los resultados de una consulta a uno o varios archivos en Amazon Simple Storage Service (Amazon S3). Es la manera que Amazon recomienda para copiar el conjunto de datos grande de Redshift.
Ejemplo: copiar datos de Amazon Redshift en Azure Synapse Analytics con UNLOAD, copia almacenada provisionalmente y PolyBase
En este caso de uso de ejemplo, la actividad de copia descarga los datos de Amazon Redshift en Amazon S3 según se configura en "redshiftUnloadSettings", luego copia los datos de Amazon S3 en Azure Blob, según se especifica en "stagingSettings", y al final se usa PolyBase para cargar los datos en Azure Synapse Analytics. Todo el formato provisional es controlado como corresponde por la actividad de copia.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Asignación de tipos de datos para Amazon Redshift
Al copiar datos desde Amazon Redshift, se utilizan las siguientes asignaciones de los tipos de datos de Amazon Redshift en los tipos de datos provisionales usados internamente en el servicio. Consulte el artículo sobre asignaciones de tipos de datos y esquema para información sobre cómo la actividad de copia asigna el tipo de datos y el esquema de origen al receptor.
| Tipo de datos de Amazon Redshift | Tipo de datos de servicio provisional |
|---|---|
| bigint | Int64 |
| BOOLEAN | String |
| CHAR | String |
| DATE | DateTime |
| DECIMAL | Decimal |
| DOUBLE PRECISION | Double |
| INTEGER | Int32 |
| real | Single |
| SMALLINT | Int16 |
| TEXT | String |
| TIMESTAMP | DateTime |
| VARCHAR | String |
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Contenido relacionado
Para obtener una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos que se admiten.