Administración de datos históricos con directivas de retención
Importante
Azure SQL Edge se retirará el 30 de septiembre de 2025. Para obtener más información y opciones de migración, consulte el aviso de retirada.
Nota:
Azure SQL Edge ya no admite la plataforma ARM64.
Después de definir la directiva de retención de datos para una base de datos y la tabla subyacente, se ejecuta una tarea de temporizador en segundo plano para quitar los registros obsoletos de la tabla habilitada para la retención de datos. La identificación de las filas coincidentes y su eliminación de la tabla se producen de forma transparente, en la tarea en segundo plano programada y ejecutada por el sistema. La condición de vencimiento de las filas de la tabla se comprueba en función de la columna filter_column especificada en la definición de tabla. Si el período de retención se establece en una semana, por ejemplo, las filas de la tabla aptas para la limpieza cumplen una de las siguientes condiciones:
- Si la columna de filtro usa el tipo de datos DATETIMEOFFSET, la condición es
filter_column < DATEADD(WEEK, -1, SYSUTCDATETIME()) - De lo contrario, la condición es
filter_column < DATEADD(WEEK, -1, SYSDATETIME())
Fases de la limpieza de la retención de datos
La operación de limpieza de retención de datos consta de dos fases:
- Detección: en esta fase, la operación de limpieza identifica todas las tablas de las bases de datos del usuario para crear una lista para la limpieza. La detección se ejecuta una vez al día.
- Limpieza: en esta fase, se ejecuta la limpieza en todas las tablas con retención de datos finita, identificadas en la fase de detección. Si no se puede realizar la operación de limpieza en una tabla, esa tabla se omite en la ejecución actual y se reintentará su limpieza en la siguiente iteración. Durante la limpieza se aplican los siguientes principios:
- Si una fila obsoleta está bloqueada por otra transacción, se omite.
- La limpieza se ejecuta con un tiempo de espera de bloqueo predeterminado de 5 segundos. Si los bloqueos no se pueden adquirir en una tabla durante el tiempo de espera, la tabla se omite en la ejecución actual y se incluirá en la siguiente iteración.
- Si se produce un error durante la limpieza de una tabla, esa tabla se omite y se vuelve a incluir en la siguiente iteración.
Limpieza manual
En función de la configuración de retención de datos de una tabla y según la naturaleza de la carga de trabajo en la base de datos, es posible que el subproceso de limpieza automática no quite completamente todas las filas obsoletas durante su ejecución. Para permitir que los usuarios quiten manualmente las filas obsoletas, se ha introducido el procedimiento almacenado sys.sp_cleanup_data_retention en Azure SQL Edge.
Este procedimiento almacenado toma tres parámetros:
@schema_name: nombre del esquema propietario de la tabla. Necesario.@table_name: nombre de la tabla para la que se ejecuta la limpieza manual. Necesario.@rowcount: variable de salida. Devuelve el número de filas limpiadas por el procedimiento almacenado de limpieza manual. Opcional.
Para obtener más información, consulte sys.sp_cleanup_data_retention (Transact-SQL).
En el ejemplo siguiente se muestra la ejecución del procedimiento almacenado de limpieza manual para la tabla dbo.data_retention_table.
DECLARE @rowcnt BIGINT;
EXEC sys.sp_cleanup_data_retention 'dbo', 'data_retention_table', @rowcnt OUTPUT;
SELECT @rowcnt;
Eliminación de las filas obsoletas
El proceso de limpieza depende del diseño del índice de la tabla. Se crea una tarea en segundo plano para realizar la limpieza de datos obsoletos en todas las tablas con un período de retención finito. La lógica de limpieza del índice de almacén de filas (montículo o árbol B) elimina la fila obsoleta en fragmentos más pequeños (hasta 10 000), lo que reduce la presión en el registro de base de datos y el subsistema de E/S. A pesar de que la lógica de limpieza usa el índice de árbol B necesario, no se puede garantizar el orden de las eliminaciones de las filas más antiguas en relación con el período de retención. En otras palabras, no tome una dependencia del orden de limpieza en las aplicaciones.
Advertencia
En el caso de montones e índices de árbol B, la retención de datos ejecuta una consulta de eliminación en las tablas subyacentes, lo que puede entrar en conflicto con desencadenadores de eliminación en las tablas. Debe quitar los desencadenadores de eliminación de las tablas o evitar el uso de la retención de datos en tablas que tienen desencadenadores DML de eliminación.
La tarea de limpieza de los índices de almacén de columnas agrupadas quita grupos de filas completos de una sola vez (normalmente, cada uno contiene 1 millón de filas), lo que es eficaz, especialmente cuando los datos se generan y quedan obsoletos a un ritmo alto.
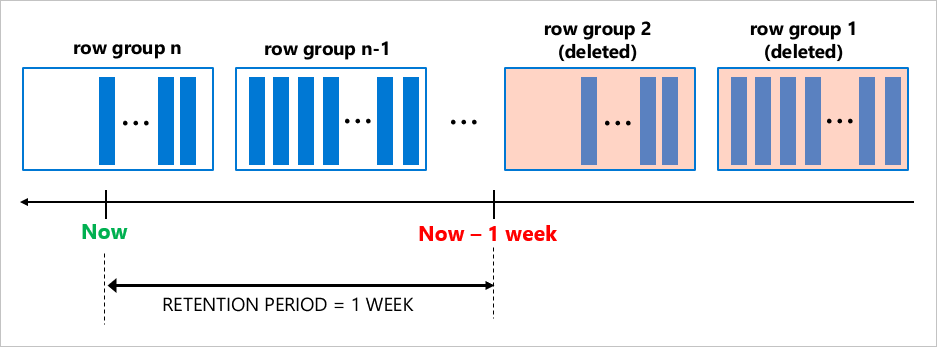
La excelente compresión de datos y la limpieza eficaz de la retención hacen que los índices de almacén de columnas agrupadas sea una elección perfecta en escenarios en los que la carga de trabajo genera rápidamente una gran cantidad de datos.
Supervisión de la limpieza de retención de datos
Las operaciones de limpieza de directivas de retención de datos se pueden supervisar mediante eventos extendidos en Azure SQL Edge. Para obtener más información sobre los eventos extendidos, consulte Información general sobre eventos extendidos.
Los siguientes eventos extendidos ayudan a realizar un seguimiento del estado de las operaciones de limpieza.
| Nombre | Descripción |
|---|---|
| data_retention_task_started | Se produce cuando se inicia la tarea en segundo plano para la limpieza de las tablas con una directiva de retención. |
| data_retention_task_completed | Se produce cuando finaliza la tarea en segundo plano para la limpieza de las tablas con una directiva de retención. |
| data_retention_task_exception | Se produce cuando se produce un error en la tarea en segundo plano para la limpieza de tablas con una directiva de retención, fuera del proceso de limpieza de retención específico de esas tablas. |
| data_retention_cleanup_started | Se produce cuando se inicia el proceso de limpieza de una tabla con la directiva de retención de datos. |
| data_retention_cleanup_exception | Se produce cuando se produce un error en el proceso de limpieza de una tabla con directiva de retención. |
| data_retention_cleanup_completed | Se produce cuando finaliza el proceso de limpieza de una tabla con la directiva de retención de datos. |
Además, se ha agregado un nuevo tipo de búfer de anillo denominado RING_BUFFER_DATA_RETENTION_CLEANUP a la vista de administración dinámica sys.dm_os_ring_buffers. Esta vista se puede usar para supervisar las operaciones de limpieza de la retención de datos.