Uso de la escalabilidad automática predictiva para escalar horizontalmente antes de las demandas de carga en conjuntos de escalado de máquinas virtuales
El escalado automático predictivo usa el aprendizaje automático para ayudar a administrar y escalar Azure Virtual Machine Scale Sets con patrones de carga de trabajo cíclicos. Prevee la carga total de CPU en el conjunto de escalado de máquinas virtuales, en función de los patrones de uso de CPU históricos. Predice la carga general de CPU observando y aprendiendo del uso histórico. Este proceso garantiza que el escalado horizontal se produzca a tiempo para satisfacer la demanda.
La escalabilidad automática predictiva necesita un mínimo de siete días de historial para proporcionar predicciones. El período máximo de muestreo es una ventana gradual de 15 días, que proporciona los mejores resultados predictivos. Para patrones de cargas de trabajo mensuales o anuales, use configuraciones de escalado automático basado en programación o escalado automático basado en métricas.
La escalabilidad automática predictiva se ajusta a los límites de escalado que ha establecido para el conjunto de escalado de máquinas virtuales. Si el sistema predice que el porcentaje de carga de CPU del conjunto de escalado de máquinas virtuales superará el límite del escalado horizontal, se agregarán nuevas instancias según las especificaciones. También puede configurar hasta qué punto quiere que se aprovisionan nuevas instancias, hasta 1 hora antes de que se produzca el pico de carga de trabajo previsto.
La previsión solo permite ver la previsión de CPU, sin desencadenar la acción de escalado según la predicción. Después, puede comparar la previsión con los patrones de carga de trabajo reales para generar confianza en los modelos de predicción antes de habilitar la característica de escalabilidad automática predictiva.
Ofertas de escalabilidad automática predictiva
- La escalabilidad automática predictiva es para las cargas de trabajo que muestran patrones de uso de CPU cíclicos.
- La compatibilidad solo está disponible para conjuntos de escalado de máquinas virtuales.
- La métrica Porcentaje de CPU con el tipo de agregación Media es la única métrica admitida actualmente.
- La escalabilidad automática predictiva solo admite la escalabilidad horizontal. Configure el escalado automático estándar para administrar para escalar en acciones.
- La escalabilidad automática predictiva solo está disponible para la nube comercial de Azure. Actualmente no se admiten nubes de Azure Government.
Habilitación de la escalabilidad automática predictiva o la previsión solo con Azure Portal
Vaya a la pantalla del conjunto de escalado de máquinas virtuales y seleccione Escalado.
En la sección Escalado automático personalizado aparece la escalabilidad automática predictiva.
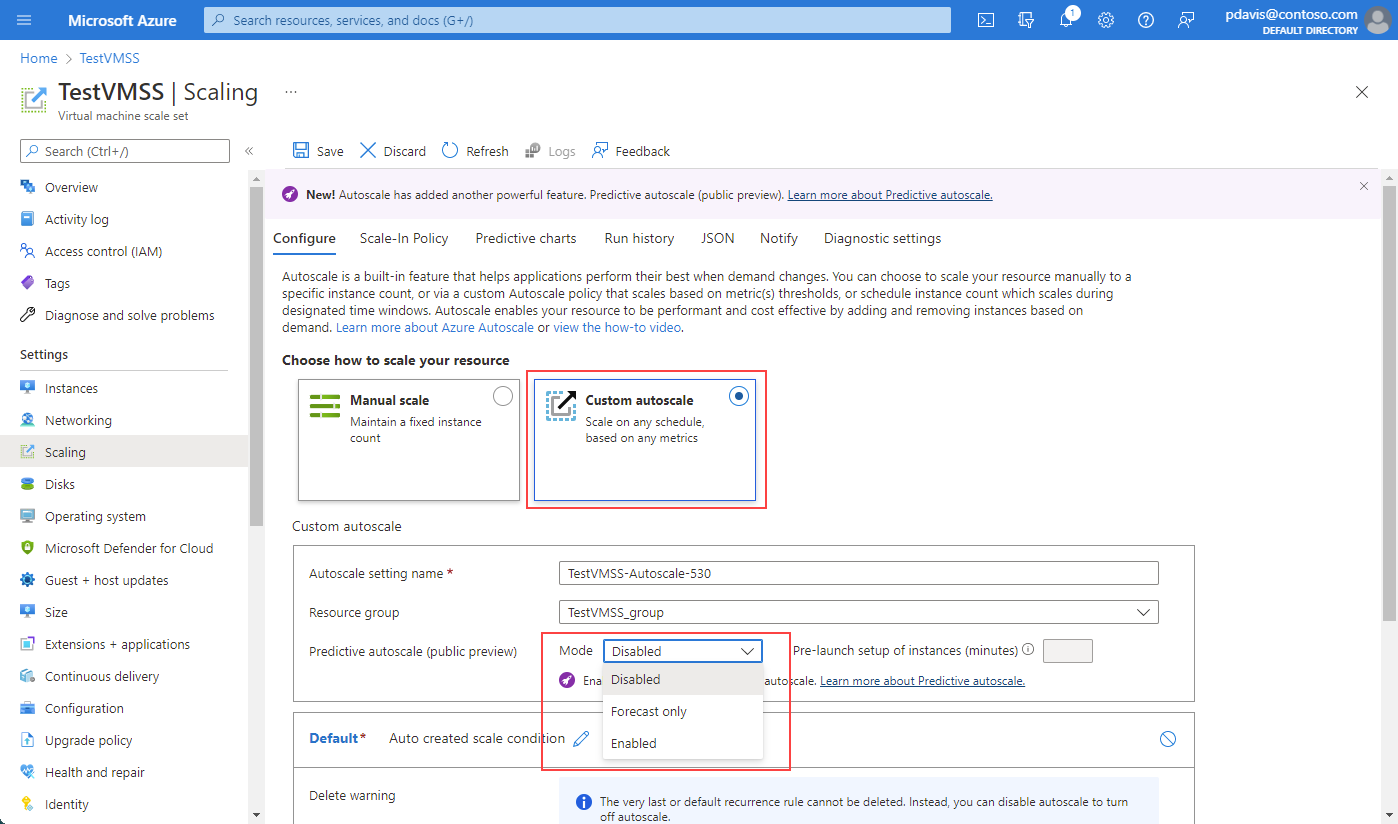
Con la selección desplegable, puede hacer lo siguiente:
- Deshabilitar la escalabilidad automática predictiva. Deshabilitar es la selección predeterminada cuando se encuentra por primera vez en la página de la escalabilidad automática predictiva.
- Habilitar el modo de solo previsión.
- Habilitar la escalabilidad automática predictiva.
Nota
Para poder habilitar la escalabilidad automática predictiva o el modo de solo previsión, debe configurar las condiciones de la escalabilidad automática reactiva estándar.
Para habilitar el modo de solo previsión, selecciónelo en la lista desplegable. Defina un desencadenador de escalabilidad horizontal basado en Porcentaje de CPU. Después, seleccione Guardar. Se aplica el mismo proceso para habilitar la escalabilidad automática predictiva. Para deshabilitar la escalabilidad automática predictiva o el modo de solo previsión, seleccione Deshabilitar en la lista desplegable.
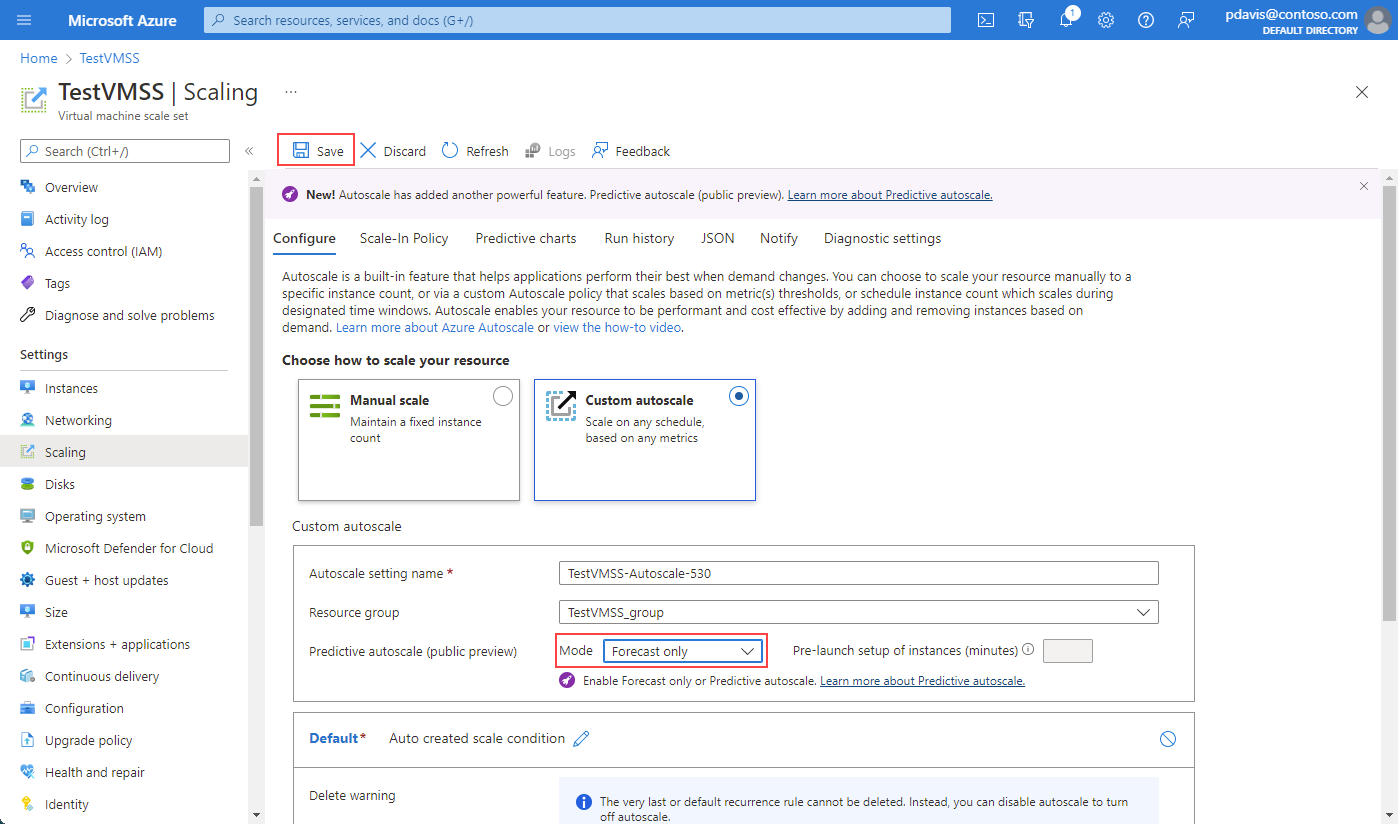
Si lo desea, especifique una hora de inicio previo para que las instancias se ejecuten completamente antes de que sean necesarias. Puede iniciar previamente las instancias entre 5 y 60 minutos antes del tiempo de predicción necesario.
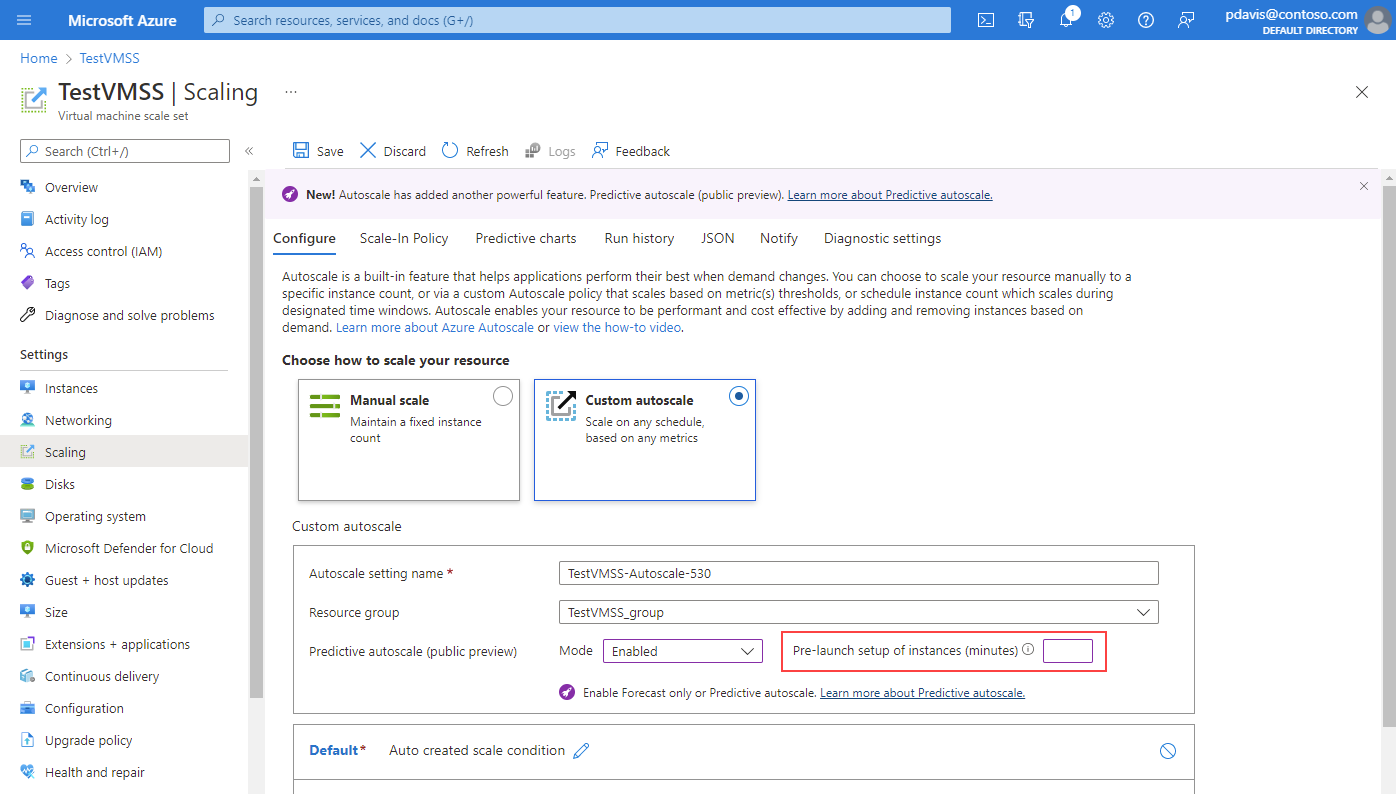
Una vez que haya habilitado la escalabilidad automática predictiva o el modo de solo previsión y lo haya guardado, seleccione Gráficos predictivos.
Verá tres gráficos:
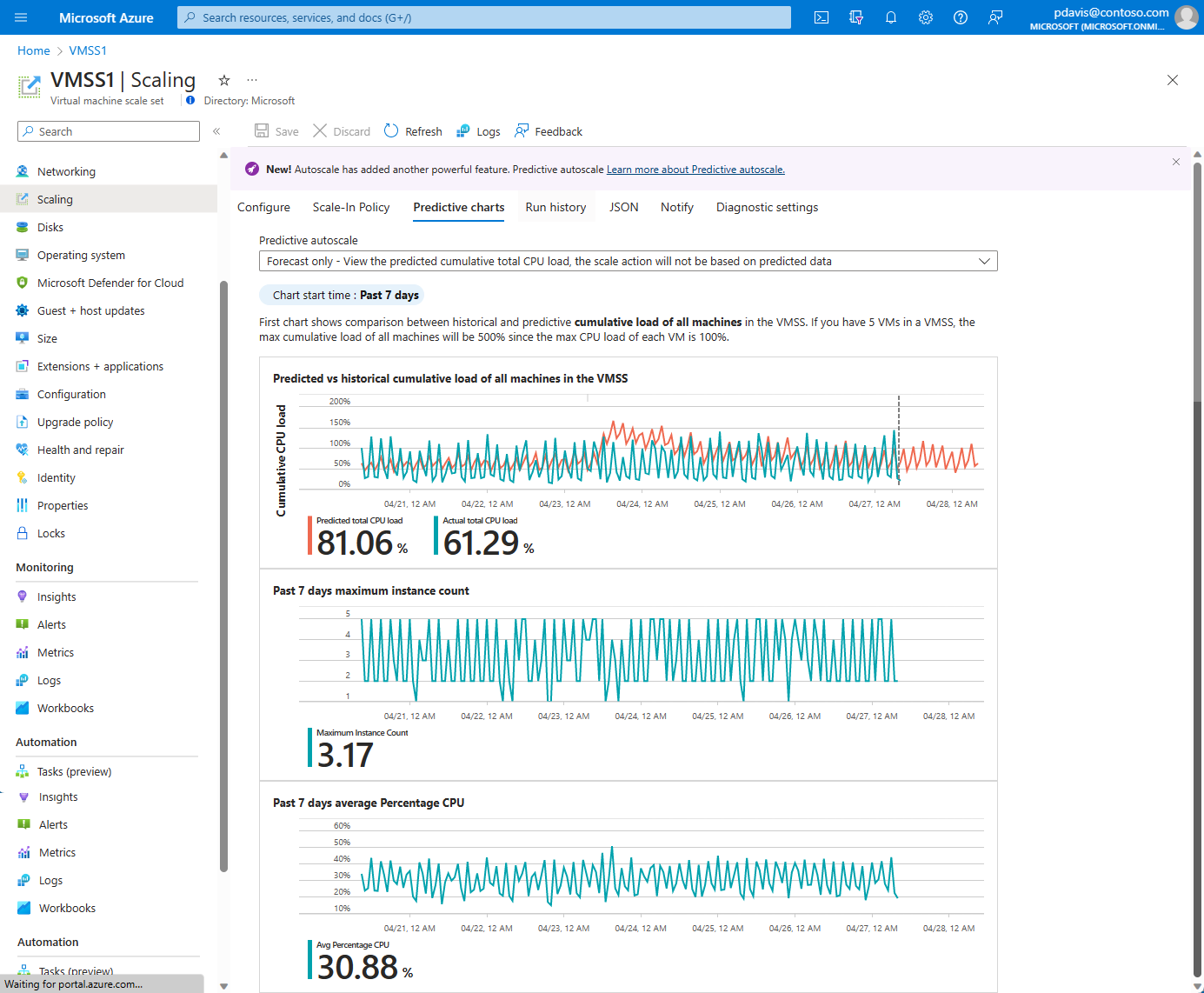
- En el gráfico superior se muestra una comparación superpuesta del porcentaje real frente al porcentaje total de CPU previsto. El intervalo de tiempo del gráfico que se muestra es de los últimos siete días a las siguientes 24 horas.
- En el gráfico central se muestra el número máximo de instancias que se ejecutan en los últimos siete días.
- En el gráfico inferior se muestra el uso medio de CPU actual en los últimos siete días.



Habilitación mediante una plantilla de Azure Resource Manager
Recupere el identificador de recurso del conjunto de escalado de máquinas virtuales y el grupo de recursos del conjunto de escalado de máquinas virtuales. Por ejemplo: /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
Actualice el archivo autoscale_only_parameters con el identificador de recurso del conjunto de escalado de máquinas virtuales y los parámetros de configuración de la escalabilidad automática.
Use un comando de PowerShell para implementar la plantilla que contiene la configuración de la escalabilidad automática. Por ejemplo:
PS G:\works\kusto_onboard\test_arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy -resourcegroupname cpatest2 -templatefile autoscale_only.json -templateparameterfile autoscale_only_parameters.json
PS C:\works\autoscale\predictive_autoscale\arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy - resourcegroupname patest2 -templatefile autoscale_only_binz.json -templateparameterfile autoscale_only_parameters_binz.json
DeploymentName : binzAutoScaleDeploy
ResourceGroupName : patest2
ProvisioningState : Succeeded
Timestamp : 3/30/2021 10:11:02 PM
Mode : Incremental
TemplateLink
Parameters :
Name Type Value
================ ============================= ====================
targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
location String East US
minimumCapacity Int 1
maximumCapacity Int 4
defaultCapacity Int 4
metricThresholdToScaleOut Int 50
metricTimeWindowForScaleOut String PT5M
metricThresholdToScaleln Int 30
metricTimeWindowForScaleln String PT5M
changeCountScaleOut Int 1
changeCountScaleln Int 1
predictiveAutoscaleMode String Enabled
Outputs :
Name Type Value
================ ============================== ====================
targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
settingLocation String East US
predictiveAutoscaleMode String Enabled
DeloymentDebugLoglevel :
PS C:\works\autoscale\predictive_autoscale\arm_template>
autoscale_only.json
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"targetVmssResourceId": {
"type": "string"
},
"location": {
"type": "string"
},
"minimumCapacity": {
"type": "Int",
"defaultValue": 2,
"metadata": {
"description": "The minimum capacity. Autoscale engine will ensure the instance count is at least this value."
}
},
"maximumCapacity": {
"type": "Int",
"defaultValue": 5,
"metadata": {
"description": "The maximum capacity. Autoscale engine will ensure the instance count is not greater than this value."
}
},
"defaultCapacity": {
"type": "Int",
"defaultValue": 3,
"metadata": {
"description": "The default capacity. Autoscale engine will preventively set the instance count to be this value if it can not find any metric data."
}
},
"metricThresholdToScaleOut": {
"type": "Int",
"defaultValue": 30,
"metadata": {
"description": "The metric upper threshold. If the metric value is above this threshold then autoscale engine will initiate scale out action."
}
},
"metricTimeWindowForScaleOut": {
"type": "string",
"defaultValue": "PT5M",
"metadata": {
"description": "The metric look up time window."
}
},
"metricThresholdToScaleIn": {
"type": "Int",
"defaultValue": 20,
"metadata": {
"description": "The metric lower threshold. If the metric value is below this threshold then autoscale engine will initiate scale in action."
}
},
"metricTimeWindowForScaleIn": {
"type": "string",
"defaultValue": "PT5M",
"metadata": {
"description": "The metric look up time window."
}
},
"changeCountScaleOut": {
"type": "Int",
"defaultValue": 1,
"metadata": {
"description": "The instance count to increase when autoscale engine is initiating scale out action."
}
},
"changeCountScaleIn": {
"type": "Int",
"defaultValue": 1,
"metadata": {
"description": "The instance count to decrease the instance count when autoscale engine is initiating scale in action."
}
},
"predictiveAutoscaleMode": {
"type": "String",
"defaultValue": "ForecastOnly",
"metadata": {
"description": "The predictive Autoscale mode."
}
}
},
"variables": {
},
"resources": [{
"type": "Microsoft.Insights/autoscalesettings",
"name": "cpuPredictiveAutoscale",
"apiVersion": "2022-10-01",
"location": "[parameters('location')]",
"properties": {
"profiles": [{
"name": "DefaultAutoscaleProfile",
"capacity": {
"minimum": "[parameters('minimumCapacity')]",
"maximum": "[parameters('maximumCapacity')]",
"default": "[parameters('defaultCapacity')]"
},
"rules": [{
"metricTrigger": {
"metricName": "Percentage CPU",
"metricNamespace": "",
"metricResourceUri": "[parameters('targetVmssResourceId')]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "[parameters('metricTimeWindowForScaleOut')]",
"timeAggregation": "Average",
"operator": "GreaterThan",
"threshold": "[parameters('metricThresholdToScaleOut')]"
},
"scaleAction": {
"direction": "Increase",
"type": "ChangeCount",
"value": "[parameters('changeCountScaleOut')]",
"cooldown": "PT5M"
}
}, {
"metricTrigger": {
"metricName": "Percentage CPU",
"metricNamespace": "",
"metricResourceUri": "[parameters('targetVmssResourceId')]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "[parameters('metricTimeWindowForScaleIn')]",
"timeAggregation": "Average",
"operator": "LessThan",
"threshold": "[parameters('metricThresholdToScaleIn')]"
},
"scaleAction": {
"direction": "Decrease",
"type": "ChangeCount",
"value": "[parameters('changeCountScaleOut')]",
"cooldown": "PT5M"
}
}
]
}
],
"enabled": true,
"targetResourceUri": "[parameters('targetVmssResourceId')]",
"predictiveAutoscalePolicy": {
"scaleMode": "[parameters('predictiveAutoscaleMode')]"
}
}
}
],
"outputs": {
"targetVmssResourceId" : {
"type" : "string",
"value" : "[parameters('targetVmssResourceId')]"
},
"settingLocation" : {
"type" : "string",
"value" : "[parameters('location')]"
},
"predictiveAutoscaleMode" : {
"type" : "string",
"value" : "[parameters('predictiveAutoscaleMode')]"
}
}
}
autoscale_only_parameters.json
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"targetVmssResourceId": {
"value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2"
},
"location": {
"value": "East US"
},
"minimumCapacity": {
"value": 1
},
"maximumCapacity": {
"value": 4
},
"defaultCapacity": {
"value": 4
},
"metricThresholdToScaleOut": {
"value": 50
},
"metricTimeWindowForScaleOut": {
"value": "PT5M"
},
"metricThresholdToScaleIn": {
"value": 30
},
"metricTimeWindowForScaleIn": {
"value": "PT5M"
},
"changeCountScaleOut": {
"value": 1
},
"changeCountScaleIn": {
"value": 1
},
"predictiveAutoscaleMode": {
"value": "Enabled"
}
}
}
Para más información sobre las plantillas de Azure Resource Manager, consulte Introducción a las plantillas de Resource Manager.
Preguntas más frecuentes
En esta sección se responden las preguntas más frecuentes.
¿Por qué el porcentaje de CPU supera el 100 % en los gráficos predictivos?
El gráfico predictivo muestra la carga acumulativa de todas las máquinas del conjunto de escalado. Si tiene 5 máquinas virtuales en un conjunto de escalado, la carga acumulativa máxima para todas las máquinas virtuales será del 500 %, es decir, cinco veces la carga máxima de CPU del 100 % de cada máquina virtual.
¿Qué ocurre con el tiempo al activar la escalabilidad automática predictiva para un conjunto de escalado de máquinas virtuales?
La escalabilidad automática predictiva usa el historial de un conjunto de escalado de máquinas virtuales en ejecución. Si el conjunto de escalado se ha estado ejecutando menos de siete días, recibirá un mensaje que indica que el modelo se está entrenando. Para más información, consulte el mensaje sin datos predictivos. Las predicciones mejoran a medida que pasa el tiempo y logran su precisión máxima 15 días después de crear el conjunto de escalado de máquinas virtuales.
Si se producen cambios en el patrón de carga de trabajo (pero estos siguen siendo periódicos), el modelo reconoce el cambio y comienza a ajustar la previsión. La previsión mejora a medida que pasa el tiempo. La precisión máxima se alcanza 15 días después de que se produzca el cambio en el patrón de tráfico. Recuerde que todavía se aplican las reglas de escalabilidad automática estándar. Si se produce un nuevo aumento imprevisto del tráfico, el conjunto de escalado de máquinas virtuales se escalará horizontalmente para satisfacer la demanda.
¿Qué ocurre si el modelo no funciona bien para mí?
El modelado funciona mejor con cargas de trabajo que presentan periodicidad. En primer lugar, se recomienda evaluar las predicciones habilitando el modo de "solo previsión", lo que superpondrá el uso de CPU previsto del conjunto de escalado con el uso real observado. Una vez que compare y evalúe los resultados, puede optar por habilitar el escalado en función de las métricas predichas si las predicciones del modelo son lo suficientemente cercanas para su escenario.
¿Por qué es necesario habilitar la escalabilidad automática estándar antes de habilitar la escalabilidad automática predictiva?
La escalabilidad automática estándar es una reserva necesaria si el modelo predictivo no funciona bien para su escenario. La escalabilidad automática estándar abarca picos de carga inesperados que no forman parte del patrón de carga de CPU típico. También proporciona una reserva si se produce un error al recuperar los datos predictivos.
¿Qué regla surte efecto si se establecen reglas de escalado automático predictivo y estándar?
Las reglas de escalado automático estándar se usan si hay un pico inesperado en la carga de la CPU o se produce un error al recuperar datos predictivos
El umbral establecido en las reglas de escalabilidad automática estándar se usa para comprender cuándo le interesa escalar horizontalmente y en cuántas instancias. Si desea que el conjunto de escalado de máquinas virtuales se escale horizontalmente cuando el uso de la CPU supere el 70 % y los datos reales o previstos muestren que el uso de CPU es o superará el 70 %, se producirá una reducción horizontal.
Errores y advertencias
En esta sección se tratan errores y advertencias comunes.
No se ha habilitado la escalabilidad automática estándar
Aparece el siguiente mensaje de error:
Para habilitar el escalado automático predictivo, cree una regla de escalabilidad horizontal basada en la métrica "Porcentaje de CPU". Haga clic aquí para ir a la pestaña "Configurar" para establecer una regla de escalabilidad automática.
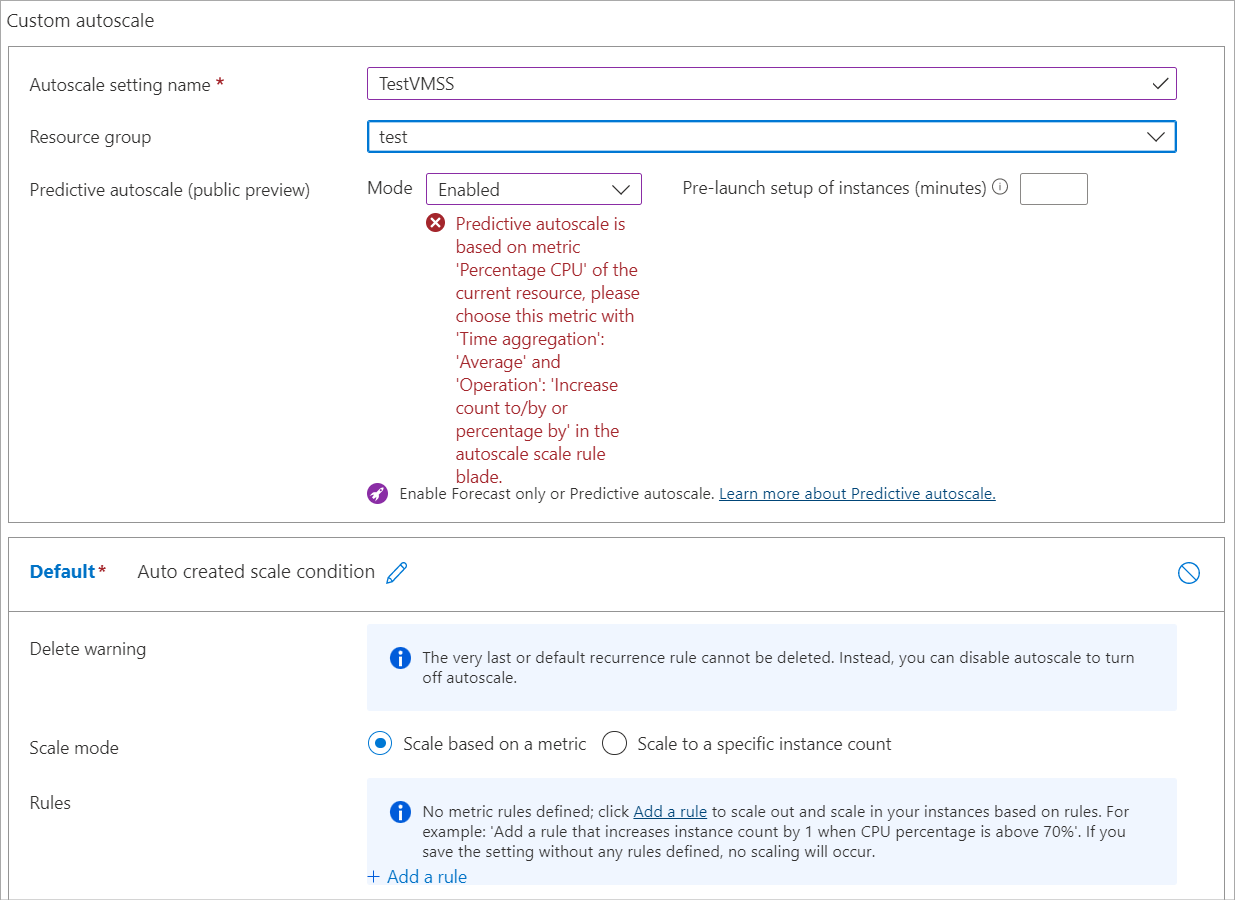
Este mensaje significa que intentó habilitar la escalabilidad automática predictiva antes de habilitar la estándar y configurarla para usar la métrica Porcentaje de CPU con el tipo de agregación Promedio.
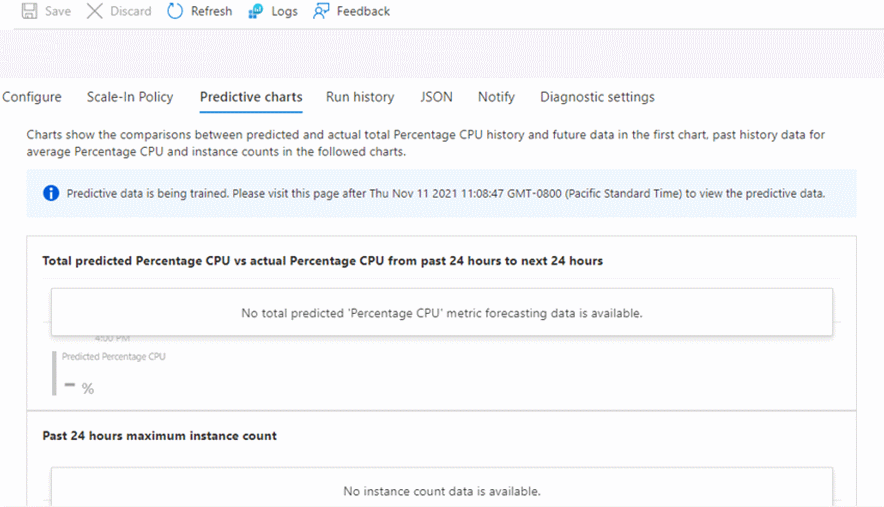
No hay datos predictivos
No verá datos en los gráficos predictivos en determinadas condiciones. Esto no es un error; es el comportamiento previsto.
Si se deshabilita la escalabilidad automática predictiva, recibirá, en su lugar, un mensaje que comienza por "No hay datos para mostrar...".Verá instrucciones sobre qué habilitar para que pueda ver un gráfico predictivo.

La primera vez que cree un conjunto de escalado de máquinas virtuales y habilite el modo de solo previsión, recibirá un mensaje que le indica "Se están entrenando los datos predictivos..." y un tiempo para volver a ver el gráfico.
Pasos siguientes
Obtenga más información sobre la escalabilidad automática en los artículos siguientes:
- Introducción a la escalabilidad automática
- Métricas comunes de escalado automático de Azure Monitor
- Procedimientos recomendados de escalado automático en Azure Monitor
- Uso de acciones de escalado automático para enviar notificaciones de alerta por correo electrónico y Webhook en Azure Insights
- API de REST de escalado automático