Conmutación por error y aplicación de revisiones para Azure Managed Redis (versión preliminar)
Para crear aplicaciones cliente resistentes y correctas, es fundamental comprender la conmutación por error en el servicio Azure Managed Redis (versión preliminar). Una conmutación por error puede formar parte de las operaciones de administración planeadas o puede ser el resultado de errores de red o hardware no planeados. Un uso habitual de la conmutación por error de la caché tiene lugar cuando el servicio de administración aplica parches a los archivos binarios de Azure Managed Redis.
En este artículo, encontrará esta información:
- ¿Qué es la conmutación por error?
- Cómo se produce una conmutación por error durante la aplicación de revisiones.
- Cómo crear una aplicación cliente resistente.
¿Qué es la conmutación por error?
Comencemos con información general de la conmutación por error para Azure Managed Redis.
Un resumen rápido de la arquitectura de la caché
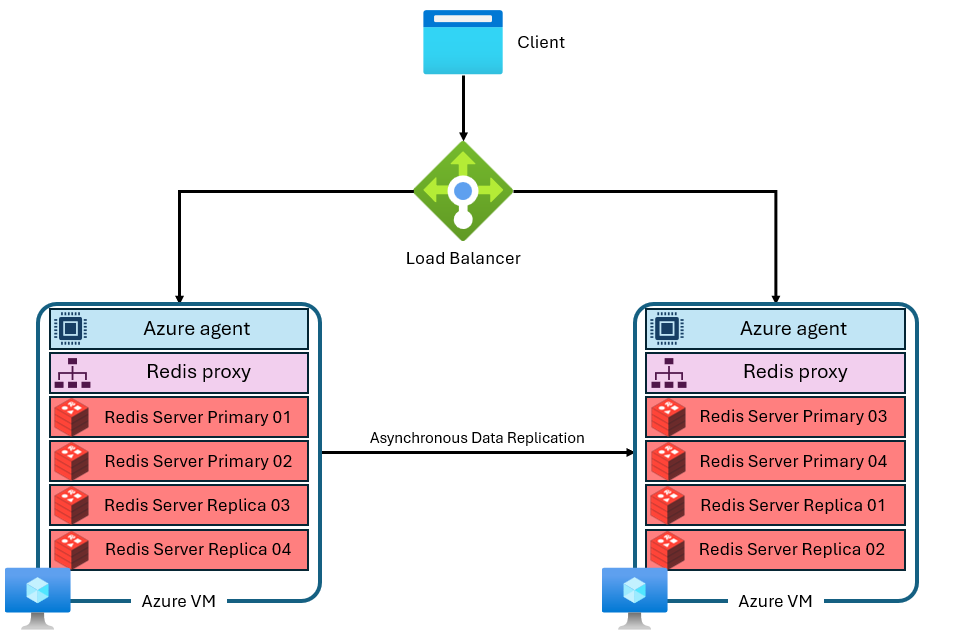
Una memoria caché se construye con varias máquinas virtuales que tienen direcciones IP privadas independientes. Cada máquina virtual (o "nodo") ejecuta varios procesos de servidor de Redis (denominados "particiones") en paralelo. Varias particiones permiten un uso más eficaz de las vCPU en cada máquina virtual y un mayor rendimiento. No todas las particiones principales de Redis están en la misma máquina virtual o nodo. En su lugar, las particiones principales y de réplica se distribuyen entre ambos nodos. Dado que las particiones principales utilizan más recursos de CPU que las particiones de réplica, este enfoque permite ejecutar más particiones principales en paralelo. Cada nodo tiene un proceso de proxy de alto rendimiento para administrar las particiones, controlar la administración de conexiones y desencadenar la recuperación automática. Puede que una partición esté inactiva mientras otras permanecen disponibles.
Puede encontrar más detalles de la arquitectura de Azure Managed Redis aquí.
Explicación de una conmutación por error
Una conmutación por error se produce cuando una o varias particiones de réplica se promueven a sí mismas para convertirse en particiones principales y las particiones principales antiguas cierran las conexiones existentes. Una conmutación por error puede ser planeada o no planeada.
Una conmutación por error planeada tiene lugar durante dos momentos diferentes:
- Actualizaciones del sistema, como aplicación de revisiones de Redis o actualizaciones del sistema operativo.
- Operaciones de administración, como el escalado y el reinicio.
Dado que los nodos reciben un aviso por adelantado de la actualización, pueden intercambiar roles de forma cooperativa y actualizar rápidamente el equilibrador de carga del cambio. Una conmutación por error planeada suele finalizar en menos de un segundo.
Una conmutación por error no planeada puede producirse debido a un error de hardware, a un error de red o a otras interrupciones inesperadas en uno o varios nodos del clúster. Las particiones de réplica en los nodos restantes se promoverán a sí mismos a principal para mantener la disponibilidad, pero el proceso tarda más tiempo. Una partición de réplica debe detectar primero que su partición principal no está disponible antes de que pueda iniciar el proceso de conmutación por error. La partición de réplica también debe comprobar si este error no planeado es transitorio o local, para evitar una conmutación por error innecesaria. Este retraso en la detección significa que una conmutación por error no planeada finaliza normalmente en 10 o 15 segundos.
¿Cómo se realiza la aplicación de la revisión?
El servicio Azure Managed Redis actualiza regularmente la memoria caché con las características y correcciones de plataforma más recientes. Para aplicar una revisión en una caché, el servicio lleva a cabo estos pasos:
- El servicio crea nuevas máquinas virtuales actualizadas para reemplazar todas las máquinas virtuales que se están revisando.
- A continuación, promueve una de las nuevas máquinas virtuales como líder del clúster.
- Uno por uno, todos los nodos que se revisan se quitan del clúster. Las particiones de estas máquinas virtuales se degradarán y migrarán a una de las nuevas máquinas virtuales.
- Por último, se eliminan todas las máquinas virtuales que se reemplazaron.
La aplicación de la revisión se realiza por separado en cada partición de una caché en clúster, y no cierra las conexiones a otra partición.
Cuando hay varias cachés en el mismo grupo de recursos o en la misma región, la aplicación de la revisión también se realiza en una partición a la vez. En las memorias caché que se encuentran en distintos grupos de recursos o en regiones diferentes, la aplicación de la revisión se puede realizar simultáneamente.
Dado que la sincronización de datos completa se produce antes de que se repita el proceso, es poco probable que se produzca la pérdida de datos para la memoria caché. Puede protegerse aún más contra la pérdida de datos mediante la exportación de datos y la habilitación de la persistencia.
Carga adicional de caché
Siempre que se produce una conmutación por error, las cachés deben replicar los datos de un nodo a otro. Esta replicación provoca un aumento de la carga en la CPU y en la memoria del servidor. Si la instancia de caché ya está muy cargada, puede que haya mayor latencia en las aplicaciones cliente. En casos extremos, las aplicaciones cliente pueden recibir excepciones de tiempo de espera.
¿Cómo afecta una conmutación por error a mi aplicación cliente?
Las aplicaciones cliente podrían recibir algunos errores de la instancia de Azure Managed Redis. El número de errores detectados por una aplicación cliente depende del número de operaciones pendientes en esa conexión en el momento de la conmutación por error. Cualquier conexión que se enrute mediante el nodo que cerró sus conexiones verá errores.
Muchas bibliotecas cliente pueden emitir distintos tipos de errores al interrumpirse las conexiones, entre ellos:
- Excepciones de tiempo de espera
- Excepciones de conexión
- Excepciones de socket
El número y el tipo de excepciones dependen de dónde se encuentre la solicitud en la ruta de acceso al código cuando la memoria caché cierra sus conexiones. Por ejemplo, una operación que envía una solicitud pero que no ha recibido una respuesta cuando se produce la conmutación por error puede obtener una excepción de tiempo de espera. Las nuevas solicitudes en el objeto de conexión cerrado reciben excepciones de conexión hasta que la reconexión se produce correctamente.
La mayoría de las bibliotecas cliente intentan volver a conectarse a la memoria caché si están configuradas para ello. Sin embargo, en ocasiones, errores imprevistos pueden dejar los objetos de biblioteca en un estado irrecuperable. Si los errores continúan durante más tiempo del preconfigurado, se debe volver a crear el objeto de conexión. En Microsoft .NET y en otros lenguajes orientados a objetos, se puede volver a crear la conexión sin necesidad de reiniciar la aplicación, mediante un patrón ForceReconnect.
¿Cuáles son las actualizaciones incluidas en mantenimiento?
El mantenimiento incluye estas actualizaciones:
- Actualizaciones del servidor de Redis: cualquier actualización o revisión de los archivos binarios del servidor de Redis.
- Actualizaciones de la máquina virtual: las actualizaciones de la máquina virtual que hospedan el servicio Redis. Las actualizaciones de máquina virtual incluyen componentes de software de aplicación de revisiones en el entorno de hospedaje para actualizar componentes de red o su retirada.
¿Aparece el mantenimiento en el estado del servicio en Azure Portal antes de una revisión?
No, el mantenimiento no aparece en el estado del servicio en el portal ni en ningún otro lugar.
Cambios en la configuración de red del cliente
Algunos cambios en la configuración de red del lado cliente pueden desencadenar errores de tipo Ninguna conexión disponible. Estos cambios podrían incluir:
- Intercambio de la dirección IP virtual de una aplicación cliente entre los espacios de ensayo y producción.
- Escalado del tamaño o número de instancias de su aplicación.
Estos cambios pueden provocar un problema de conectividad que suele durar menos de un minuto. Es probable que la aplicación cliente pierda la conexión a otros recursos de red externos, además del servicio Azure Managed Redis.
Creación de resistencia
No se pueden evitar completamente las conmutaciones por error. En su lugar, escriba las aplicaciones cliente para que sean resistentes a las interrupciones de la conexión y a las solicitudes con error. La mayoría de las bibliotecas cliente se vuelven a conectar automáticamente al punto de conexión de la memoria caché, pero pocas intentan enviar de nuevo las solicitudes con error. En función del escenario de la aplicación, es posible que la lógica de reintento con retroceso tenga sentido.
¿Cómo hago que mi aplicación sea resistente?
Consulte estos patrones de diseño para crear clientes resistentes, sobre todo los patrones de reintento e interruptores:
- Patrones de confiabilidad: patrones de diseño en la nube
- Guía de reintentos para los servicios de Azure: procedimientos recomendados para aplicaciones en la nube
- Implementar reintentos con retroceso exponencial