Permite que una aplicación trate los errores transitorios cuando intenta conectarse a un servicio o un recurso de red, mediante el reintento de forma transparente de una operación con error. Esto puede mejorar la estabilidad de la aplicación.
Contexto y problema
Una aplicación que se comunica con elementos que se ejecutan en la nube tiene que ser vulnerable a los errores transitorios que puedan producirse en este entorno. Entre los errores transitorios cabe mencionar la pérdida momentánea de conectividad de red en componentes y servicios, la falta de disponibilidad temporal de un servicio o los tiempos de espera que surgen cuando un servicio está ocupado.
Estos errores normalmente se corrigen automáticamente, y si se repite la acción que desencadena un error tras un retraso adecuado, es probable que tenga éxito. Por ejemplo, un servicio de base de datos que procesa un número elevado de solicitudes simultáneas puede implementar una estrategia de limitación que temporalmente rechace las sucesivas solicitudes hasta que su carga de trabajo haya disminuido. Una aplicación que intenta acceder a la base de datos podría no conectarse, pero si lo intenta de nuevo después de un retraso podría tener éxito.
Solución
En la nube, cabe esperar que se produzcan errores transitorios y una aplicación debería diseñarse para tratarlos con elegancia y transparencia. De esta forma, se reducen los efectos que pueden tener los errores sobre las tareas empresariales que realiza la aplicación. El patrón de diseño más común para abordar es introducir un mecanismo de reintento.
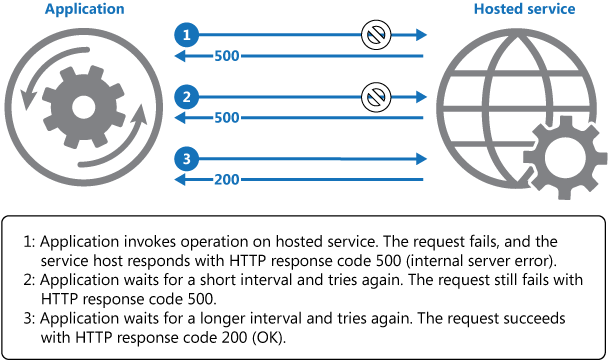
En el diagrama anterior se muestra cómo invocar una operación en un servicio hospedado mediante un mecanismo de reintento. Si la solicitud no tiene éxito después de un número predefinido de intentos, la aplicación debe tratar el error como una excepción y tratarlo como corresponda.
Nota:
Debido a la naturaleza común de los errores transitorios, los mecanismos de reintento integrados ahora están disponibles en muchas bibliotecas de cliente y servicios en la nube, con cierto grado de capacidad de configuración para el número de reintentos máximos, el retraso entre reintentos y otros parámetros. La compatibilidad integrada con reintentos para muchos servicios de Azure se puede encontrar aquí y Microsof Entity Framework proporciona servicios para reintentar operaciones de base de datos con errores.
Estrategia de reintento
Si una aplicación detecta un error al intentar enviar una solicitud a un servicio remoto, puede tratar el error mediante las estrategias siguientes:
Cancelar. Si el error indica que el error no es transitorio o que no es probable que tenga éxito si se repite, la aplicación debe cancelar la operación y notificar una excepción.
Reintentar inmediatamente. Si el error específico notificado es inusual o poco frecuente, como un paquete de red que se daña mientras se transmite, la mejor acción puede ser volver a intentar inmediatamente la solicitud.
Reintentar después de un retraso. Si el error es debido a uno de los muchos errores habituales de conectividad o disponibilidad, puede que la red o el servicio necesiten un corto período de tiempo mientras se corrigen los problemas de conectividad o se borra el trabajo pendiente, por lo que retrasar mediante programación el reintento es una buena estrategia. En muchos casos, se debe elegir el período entre reintentos para distribuir las solicitudes de varias instancias de la aplicación lo más uniformemente posible para reducir la posibilidad de que un servicio ocupado continúe sobrecargado.
Si la solicitud sigue sin funcionar, la aplicación puede esperar y realizar otro intento. Si es necesario, este proceso puede repetirse aumentando los retrasos entre reintentos, hasta que se haya intentado un número máximo de solicitudes. El retraso se puede aumentar de manera exponencial o incremental, según el tipo de error y la probabilidad de que se corrija durante este tiempo.
La aplicación debe encapsular todos los intentos de acceso a un servicio remoto en un código que implemente una directiva de reintento que coincida con una de las estrategias enumeradas anteriormente. Las solicitudes enviadas a distintos servicios pueden estar sujetas a diferentes directivas.
Una aplicación debe registrar los detalles de los errores y las operaciones con errores. Esta información es útil para los operadores. Dicho esto, con el fin de evitar el desbordamiento de operadores con alertas sobre las operaciones con reintentos correctos, es mejor registrar los primeros errores como entradas informativas y solo el error del último reintento como un error real. Este es un ejemplo del aspecto que tendría el modelo de registro.
Si un servicio está con frecuencia no disponible o ocupado, suele ser porque el servicio ha agotado sus recursos. Se puede reducir la frecuencia de estos errores mediante el escalado horizontal del servicio. Por ejemplo, si un servicio de base de datos está continuamente sobrecargado, podría ser beneficioso particionar la base de datos y repartir la carga entre varios servidores.
Problemas y consideraciones
A la hora de decidir cómo implementar este patrón, debe considerar los siguientes puntos:
Impacto en el rendimiento
La directiva de reintentos se debe optimizar para que coincida con los requisitos empresariales de la aplicación y la naturaleza del error. Si las operaciones no son críticas, es mejor provocar el fracaso y responder rápido a los errores en lugar de reintentarlas varias veces y que afecten al rendimiento de la aplicación. Por ejemplo, en una aplicación web interactiva que accede a un servicio remoto, es mejor que el error se produzca rápido tras un pequeño número de reintentos con solo un corto retraso entre ellos y mostrar un mensaje adecuado al usuario (por ejemplo, «inténtelo de nuevo más tarde»). En una aplicación por lotes, puede ser más adecuado aumentar el número de reintentos con un retraso que aumente exponencialmente entre intentos.
Una directiva de reintentos agresiva con un retraso mínimo entre intentos, y un gran número de reintentos, podría degradar aún más un servicio ocupado que se ejecuta en su capacidad o próximo a esta. Esta directiva de reintentos también podría afectar a la capacidad de respuesta de la aplicación si continuamente intenta realizar una operación con error.
Si una solicitud sigue sin funcionar después de un número considerable de reintentos, lo mejor para la aplicación es impedir que las solicitudes adicionales vayan al mismo recurso y simplemente notificar un error inmediatamente. Cuando expira el período, la aplicación puede permitir que pasen una o varias solicitudes de manera provisional para ver si se procesan correctamente. Para más información sobre esta estrategia, consulte Circuit Breaker pattern (Patrón Circuit Breaker).
Idempotencia
Considere si la operación es idempotente. Si es así, es intrínsecamente seguro volver a intentarla. En caso contrario, los reintentos podrían provocar que la operación se ejecutara más de una vez, con efectos secundarios imprevistos. Por ejemplo, un servicio podría recibir la solicitud, procesarla correctamente, pero no poder enviar una respuesta. En ese momento, la lógica de reintento podría volver a enviar la solicitud, suponiendo que no se reciba la primera solicitud.
Tipo de excepción
Una solicitud a un servicio puede dar error por diversos motivos y generar diferentes excepciones según la naturaleza del error. Algunas excepciones indican un error que puede resolverse rápidamente, mientras que otras indican que el error está durando mucho. Para la directiva de reintentos resulta útil ajustar el tiempo entre reintentos en función del tipo de la excepción.
Coherencia de las transacciones
Considere de qué modo reintentar una operación que forma parte de una transacción afectará a la coherencia de la transacción en general. Ajuste la directiva de reintentos en las operaciones transaccionales para maximizar la probabilidad de éxito y reducir la necesidad de deshacer todos los pasos de transacción.
Instrucciones generales
Asegúrese de que todo el código de reintento esté sobradamente probado en diversas condiciones de error. Compruebe que no afecte gravemente al rendimiento o la confiabilidad de la aplicación, que no provoque una carga excesiva en los servicios y recursos ni que genere condiciones de carrera o cuellos de botella.
Implemente la lógica de reintento solo donde se entienda el contexto completo de una operación con error. Por ejemplo, si una tarea que contiene una directiva de reintentos invoca otra tarea que también contiene una directiva de reintentos, este nivel adicional de reintentos puede agregar retrasos prolongados al procesamiento. Lo mejor sería configurar la tarea de nivel inferior para que fracase y responda a rápido a los errores, y notificar el motivo del error a la tarea que lo ha invocado. Esta tarea de nivel superior puede luego tratar el error según su propia directiva.
Registre todos los errores de conectividad que provocan un reintento de modo que se puedan identificar los problemas subyacentes con la aplicación, los servicios o los recursos.
Investigue los errores que es más probables que se produzcan con un servicio o un recurso a fin de detectar si es probable que sean de larga duración o terminales. Si lo son, es mejor tratar el error como una excepción. La aplicación puede notificar o registrar la excepción y, a continuación, intentar continuar bien mediante la invocando de un servicio alternativo (si está disponible) o la oferta de una funcionalidad degradada. Para más información sobre cómo detectar y tratar los errores de larga duración, consulte Circuit Breaker pattern (Patrón Circuit Breaker).
Cuándo usar este patrón
Use este patrón cuando una aplicación pueda experimentar errores transitorios mientras interactúa con un servicio remoto o accede a un recurso remoto. Cabe esperar que estos errores sean de corta duración, y repetir una solicitud que anteriormente ha dado error podría tener éxito en un intento posterior.
Este patrón podría no ser útil:
- Cuando es probable que un error sea de larga duración, ya que esto puede afectar a la capacidad de respuesta de una aplicación. La aplicación podría estar desperdiciando tiempo y recursos intentando repetir la solicitud que es probable que produzca error.
- Para tratar errores que no son debidos a errores transitorios, como excepciones internas debidas a errores de la lógica de negocios de una aplicación.
- Como alternativa para resolver problemas de escalabilidad en un sistema. Si una aplicación experimenta errores frecuentes de disponibilidad, suele ser un indicio de que el servicio o recurso al que se accede se debe escalar verticalmente.
Diseño de cargas de trabajo
Un arquitecto debe evaluar cómo se puede usar el patrón Retry en el diseño de su carga de trabajo para abordar los objetivos y principios descritos en los pilares del Marco de buena arquitectura de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | La mitigación de errores transitorios en un sistema distribuido es una técnica básica para mejorar la resistencia de la carga de trabajo. - RE:07 Conservación automática - RE:07 Errores transitorios |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
Consulte la guía Implementación de una directiva de reintentos con .NET para obtener un ejemplo detallado mediante el SDK de Azure con compatibilidad integrada con el mecanismo de reintentos integrado.
Pasos siguientes
Antes de escribir lógica de reintento personalizada, considere la posibilidad de usar un marco de trabajo general como Polly para .NET o Resilience4j para Java.
Al procesar comandos que cambien datos empresariales, tenga en cuenta que los reintentos pueden hacer que la acción se realice dos veces, lo cual sería un problema para acciones como la aplicación de un cargo a la tarjeta de crédito de un cliente. El uso del patrón Idempotence descrito en esta entrada de blog puede ayudar en estas situaciones.
Recursos relacionados
El patrón de aplicación web confiable muestra cómo aplicar el patrón de reintento a una aplicación web convergente en la nube.
Para la mayoría de los servicios de Azure, los SDK de cliente incluyen lógica de reintento integrada. Para más información, consulte la Guía de reintentos para servicios de Azure.
Patrón Circuit Breaker. Si se espera que un error sea de larga duración, puede que sea más adecuado implementar el patrón Circuit Breaker. La combinación de los patrones Retry y Circuit Breaker proporciona un enfoque integral de control de los errores.