Para comprobar que las aplicaciones y los servicios funcionan correctamente, puede usar el patrón de supervisión del punto de conexión de estado. Este patrón especifica el uso de comprobaciones funcionales en una aplicación. Las herramientas externas pueden acceder a estas comprobaciones a intervalos regulares a través de puntos de conexión expuestos.
Contexto y problema
Se recomienda supervisar aplicaciones web y servicios back-end. La supervisión contribuye a garantizar que las aplicaciones y los servicios estén disponibles y funcionen correctamente. Los requisitos de la empresa suelen incluir la supervisión.
A veces es más difícil supervisar los servicios en la nube que los servicios locales. Una de las razones es que usted no tiene control total del entorno de hospedaje. Otra es que los servicios suelen depender de otros servicios que proporcionan los proveedores de plataformas, entre otros.
Muchos factores afectan a las aplicaciones hospedadas en la nube. La latencia de red, el rendimiento y la disponibilidad de los sistemas subyacentes de proceso y almacenamiento, y el ancho de banda de red son algunos de ellos. Se puede producir un error total o parcial en un servicio a causa de cualquiera de estos factores. Para garantizar un nivel de disponibilidad necesario, debe comprobar a intervalos regulares que el servicio funciona correctamente. El contrato de nivel de servicio (SLA) puede especificar el nivel que necesita cumplir.
Solución
Implemente el seguimiento del estado mediante el envío de solicitudes a un punto de conexión de su aplicación. La aplicación debe realizar las comprobaciones necesarias y luego devolver una indicación del estado.
Una comprobación de seguimiento del estado normalmente combina dos factores:
- Las comprobaciones (en su caso) que realiza la aplicación o el servicio en respuesta a la solicitud del punto de conexión de la comprobación de estado
- El análisis de los resultados por la herramienta o el marco que realiza la comprobación de estado
El código de respuesta indica el estado de la aplicación. Existe la opción de que el código de respuesta también proporcione el estado de los componentes y servicios que usa la aplicación. La herramienta o marco de supervisión realiza la comprobación de la latencia o del tiempo de respuesta.
La siguiente ilustración proporciona información general sobre el patrón.
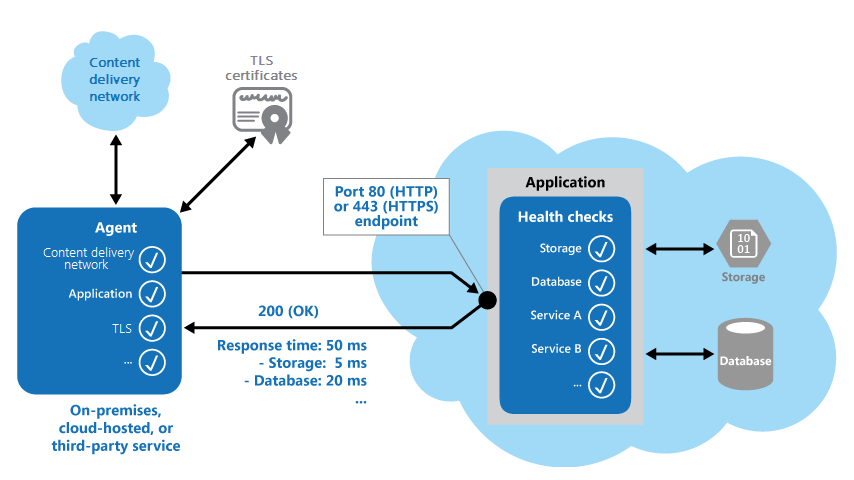
El código de seguimiento del estado de la aplicación también puede ejecutar otras comprobaciones para determinar:
- La disponibilidad y el tiempo de respuesta del almacenamiento en la nube o en una base de datos.
- El estado de otros recursos o servicios que usa la aplicación. Estos recursos y servicios pueden estar en la aplicación o fuera de la misma.
Existen servicios y herramientas disponibles que supervisan aplicaciones web mediante el envío de una solicitud a un conjunto configurable de puntos de conexión. A continuación, estos servicios y herramientas evalúan los resultados sobre la base de un conjunto de reglas configurables. Es relativamente fácil crear un punto de conexión de servicio con la finalidad única de realizar algunas pruebas funcionales en un sistema.
Entre las comprobaciones habituales que realizan las herramientas de seguimiento, se encuentran las siguientes:
- Validación del código de respuesta. Por ejemplo, una respuesta HTTP 200 (OK) indica que la aplicación respondió sin errores. El sistema de supervisión puede también comprobar otros códigos de respuesta para dar unos resultados más completos.
- Comprobación del contenido de la respuesta para detectar errores, incluso cuando el código de estado es 200 (OK). Al comprobar el contenido, le permite detectar los errores que afectan a solo una sección de la página web o la respuesta del servicio devueltas. Por ejemplo, puede comprobar el título de una página o buscar una frase específica que indique que la aplicación devolvió la página correcta.
- Medición del tiempo de respuesta. El valor incluye la latencia de red y el tiempo que la aplicación tardó en emitir la solicitud. Un valor que aumenta puede indicar un problema emergente con la aplicación o la red.
- Comprobación de recursos o servicios que se encuentran fuera de la aplicación. Por ejemplo, una red de entrega de contenido que la aplicación usa para entregar contenido de cachés globales.
- Comprobación de la expiración de los certificados TLS.
- Medición del tiempo de respuesta de una búsqueda de DNS de la dirección URL de la aplicación. Esta comprobación mide la latencia DNS y los errores de DNS.
- Validación de la dirección URL que devuelve una búsqueda de DNS. Al validar, puede asegurarse de que las entradas sean correctas. También puede contribuir a evitar el redireccionamiento de solicitudes malintencionadas que podrían producirse después de un ataque en su servidor DNS.
Siempre que sea posible, también resulta útil ejecutar estas comprobaciones desde ubicaciones diferentes locales u hospedadas y luego comparar los tiempos de respuesta. Lo ideal es que supervise las aplicaciones desde ubicaciones cercanas a los clientes. De este modo obtiene una vista exacta del rendimiento desde cada ubicación. Esta práctica proporciona un mecanismo de comprobación más sólido. Los resultados también pueden ayudarle a tomar las siguientes decisiones:
- Dónde implementar su aplicación
- Si se va a implementar en más de un centro de datos
Para asegurarse de que la aplicación funciona correctamente para todos los clientes, ejecute pruebas en todas las instancias de servicio que usen los clientes. Por ejemplo, si el almacenamiento de un cliente se distribuye en más de una cuenta de almacenamiento, el proceso de supervisión debería comprobar cada cuenta.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
Piense en cómo validar la respuesta. Por ejemplo, determine si un único código de estado 200 (OK) basta para comprobar que la aplicación funciona correctamente. Comprobar el código de estado es la implementación mínima de este patrón. Un código de estado proporciona una medida básica de disponibilidad de la aplicación. Sin embargo, un código proporciona poca información sobre las operaciones, tendencias y posibles problemas futuros en la aplicación.
Determinar el número de puntos de conexión a exponer para una aplicación. Un enfoque consiste en exponer al menos un punto de conexión para los servicios básicos que utiliza la aplicación y otro para los servicios de prioridad inferior. Con este enfoque, puede asignar distintos niveles de importancia a cada resultado de supervisión. Plantéese también la posibilidad de exponer puntos de conexión adicionales. Puede exponer uno para cada servicio principal a fin de aumentar la granularidad de la supervisión. Por ejemplo, una comprobación de estado puede comprobar la base de datos, el almacenamiento y un servicio de geocodificación externo que use una aplicación. Cada una puede requerir un nivel diferente de tiempo de actividad y tiempo de respuesta. El servicio de geocodificación o alguna otra tarea en segundo plano podría no estar disponible durante algunos minutos. Pero es posible que la aplicación siga en buen estado.
Decida si va a usar el mismo punto de conexión para la supervisión y para el acceso general. Puede usar el mismo punto de conexión para ambos, pero diseñar una ruta de acceso específica para las comprobaciones de estado. Por ejemplo, puede usar /health en el punto de conexión de acceso general. Con este enfoque, las herramientas de supervisión pueden ejecutar algunas pruebas funcionales en la aplicación. Por ejemplo, registrar un nuevo usuario, iniciar sesión y realizar un pedido de prueba. Al mismo tiempo, también puede comprobar que el punto de conexión de acceso general esté disponible.
Determine el tipo de información que se debe recopilar en el servicio en respuesta a las solicitudes de supervisión. También debe determinar cómo devolver esta información. La mayoría de las herramientas y marcos existentes mira solo el código de estado HTTP que devuelve el punto de conexión. Para devolver y validar información adicional, es posible que deba crear un servicio o una utilidad de supervisión personalizados.
Establezca cuánta información se va a recopilar. Realizar un procesamiento excesivo durante la comprobación puede sobrecargar la aplicación y afectar a otros usuarios. El tiempo de procesamiento también podría superar el tiempo de espera del sistema de supervisión. Debido a ello, el sistema podría marcar la aplicación como no disponible. La mayoría de las aplicaciones incluyen instrumentación, como controladores de errores y contadores de rendimiento. Estas herramientas pueden registrar información detallada sobre el rendimiento y los errores, lo que podría ser suficiente. Considere la posibilidad de usar estos datos en lugar de devolver información adicional de una comprobación de estado.
Considere la posibilidad de almacenar en caché el estado del punto de conexión. Ejecutar frecuentemente la comprobación de estado podría ser costoso. Por ejemplo, si el estado de mantenimiento se notifica mediante un panel, no querrá que todas las solicitudes al panel desencadenen una comprobación de estado. En vez de eso, realice comprobaciones periódicas del estado del sistema y almacene el estado en caché. Exponga un punto de conexión que devuelva el estado almacenado en caché.
Planee cómo configurar la seguridad para los puntos de conexión de supervisión. Al configurar la seguridad, puede contribuir a proteger los puntos de conexión del acceso público, y en consecuencia:
- Exponer la aplicación a ataques malintencionados.
- Arriesgar la exposición de información confidencial.
- Atraer ataques por denegación de servicio (DoS).
Lo normal es que usted configure la seguridad en la configuración de la aplicación. Después podrá actualizar la configuración fácilmente sin reiniciar la aplicación. Considere el uso de una o varias de las técnicas siguientes:
Protección del punto de conexión mediante autenticación. Si el servicio de supervisión o la herramienta admite la autenticación, puede usar una clave de seguridad de autenticación en el encabezado de la solicitud. También puede pasar credenciales con la solicitud. Al usar la autenticación, considere cómo acceder a sus puntos de conexión de comprobación de estado. Como ejemplo, Azure App Service tiene una comprobación de estado integrada que se integra con las características de autenticación y autorización de App Service.
Use un punto de conexión oscuro u oculto. Por ejemplo, exponga el punto de conexión en una dirección IP diferente a la que usa la dirección URL de la aplicación predeterminada. Configure el punto de conexión en un puerto HTTP no estándar. Además, considere la posibilidad de usar una ruta de acceso compleja a su página de prueba. Normalmente puede especificar puertos y direcciones de puntos de conexión adicionales en la configuración de la aplicación. Si es necesario, puede agregar entradas para estos puntos de conexión al servidor DNS. De este modo, evita tener que especificar directamente la dirección IP.
Exponga un método en un punto de conexión que acepte un parámetro como valor de clave o valor de modo de operación. Cuando llega una solicitud, el código puede ejecutar pruebas específicas que dependen del valor del parámetro. El código puede devolver un error 404 (no encontrado) si no reconoce el valor del parámetro. Permita definir valores de parámetro en la configuración de la aplicación.
Use un punto de conexión independiente que realiza pruebas funcionales básicas sin afectar a las operaciones de la aplicación. Con este enfoque, puede contribuir a reducir el impacto de un ataque DOS. En la medida de lo posible, evite el uso de una prueba que pueda exponer información confidencial. A veces, debe devolver información que podría ser útil para un atacante. En este caso, considere cómo proteger el punto de conexión y los datos del acceso no autorizado. Confiar en la oscuridad no es suficiente. Plantéese también usar una conexión HTTPS y el cifrado de datos confidenciales, aunque este enfoque aumenta la carga en el servidor.
Decida cómo asegurarse de que el agente de supervisión funciona correctamente. Un enfoque consiste en exponer un punto de conexión que devuelve un valor de la configuración de la aplicación o un valor aleatorio que puede utilizar para probar el agente. Asegúrese también de que el sistema de supervisión realice comprobaciones en sí mismo. Puede usar una prueba automática o integrada para evitar que el sistema de supervisión emita resultados falsos positivos.
Cuándo usar este patrón
Este patrón es útil para:
- Supervisar sitios web y aplicaciones web para comprobar la disponibilidad.
- Supervisar sitios web y aplicaciones web para comprobar para que funcionan correctamente.
- Supervisar servicios de nivel intermedio o compartidos para detectar y aislar un error que pueda afectar a otras aplicaciones.
- Complementar la instrumentación que ya existe en la aplicación como los contadores de rendimiento y los controladores de errores. La comprobación de estado no reemplaza los requisitos la aplicación de registros y auditorías. La instrumentación puede proporcionar información valiosa para un marco existente que supervisa los contadores y registros de errores para detectar errores u otros problemas. Pero la instrumentación no puede proporcionar información si una aplicación no está disponible.
Diseño de cargas de trabajo
Un arquitecto debe evaluar cómo se puede usar el patrón Health Endpoint Monitoring en el diseño de su carga de trabajo para abordar los objetivos y principios descritos en los pilares del Marco de buena arquitectura de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | Estos puntos de conexión admiten los esfuerzos de alertas de confiabilidad y paneles de una carga de trabajo. También se pueden utilizar como señal de recuperación automática. - RE:07 Recuperación automática y conservación automática - RE:10 Estrategia de supervisión y alertas |
| La excelencia operativa ayuda a ofrecer calidad de carga de trabajo a través de procesos estandarizados y cohesión de equipos. | La estandarización de los puntos de conexión de estado que se van a exponer y el nivel de detalle de los resultados en toda la carga de trabajo le ayudará a evaluar los problemas. - OE:07 Sistema de supervisión |
| La eficiencia del rendimiento ayuda a que la carga de trabajo satisfaga eficazmente las demandas mediante optimizaciones en el escalado, los datos y el código. | Los puntos de conexión de estado mejoran la lógica de equilibrio de carga mediante el enrutamiento del tráfico a solo los nodos que se comprueban como correctos. Con una configuración adicional, también puede obtener métricas de la capacidad disponible de los nodos. - PE:05 Escapado y particiones |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
Puede usar el middleware y las bibliotecas de comprobaciones de estado de ASP.NET para notificar el estado de los componentes de la infraestructura de la aplicación. Este marco proporciona una manera de notificar comprobaciones de estado de forma coherente. Implementa muchas de las prácticas que se describen en este artículo. Por ejemplo, las comprobaciones de estado de ASP.NET incluyen comprobaciones externas, como la conectividad de base de datos y conceptos específicos, como sondeos de ejecución y preparación.
Hay disponibles varias implementaciones de ejemplo que usan comprobaciones de estado de ASP.NET en GitHub.
Supervisión de puntos de conexión en aplicaciones hospedadas en Azure
Algunas opciones para la supervisión de puntos de conexión en las aplicaciones de Azure son:
- Usar las características de supervisión integradas de Azure, como Azure Monitor.
- Usar un servicio de otro fabricante o un marco como Microsoft System Center Operations Manager.
- Crear una utilidad personalizada o un servicio que se ejecuta en su propio servidor o en un servidor hospedado.
Aunque Azure proporciona opciones de supervisión completas, puede usar herramientas y servicios adicionales para proporcionar aún más información. Application Insights, una característica de Monitor, está diseñada para equipos de desarrollo. Esta característica le ayuda a comprender cómo funciona su aplicación y cómo se usa. Application Insights supervisa las tasas de solicitud, los tiempos de respuesta, las tasas de error y las tasas de dependencia. Puede ayudarle a determinar si los servicios externos le ralentizan.
Las condiciones que usted puede supervisar dependen del mecanismo de hospedaje que elija para la aplicación. Todas las opciones de esta sección admiten reglas de alertas. Una regla de alerta usa un punto de conexión web que usted especifica en la configuración del servicio. Este punto de conexión debe responder de forma puntual para que el sistema de alerta pueda detectar que la aplicación está funcionando correctamente. Para obtener más información, consulte Creación de una nueva regla de alerta.
Si hay una interrupción importante, el tráfico de cliente se debe poder redirigir a una implementación de aplicación que esté disponible en otras regiones o zonas. Esta situación es un buen caso para la conectividad entre entornos y el equilibrio de carga global. La elección depende de si la aplicación está orientada de manera interna o externa. Los servicios como Azure Front Door, Azure Traffic Manager o redes de entrega de contenido pueden enrutar el tráfico entre regiones en función de los datos que proporcionan los sondeos de estado.
Traffic Manager es un servicio de enrutamiento y equilibrio de carga. Puede usar una serie de reglas y configuraciones para distribuir solicitudes a instancias específicas de su aplicación. Además de las solicitudes de enrutamiento, Traffic Manager puede hacer ping regularmente a una dirección URL, un puerto y una ruta de acceso relativa. Especifique los destinos de ping con el objetivo de determinar qué instancias de la aplicación están activas y responden a las solicitudes. Si Traffic Manager detecta un código de estado 200 (OK), marca la aplicación como disponible. Cualquier otro código de estado hace que Traffic Manager marque la aplicación como sin conexión. La consola de Traffic Manager muestra el estado de cada aplicación. Puede configurar cada regla para redirigir solicitudes a otras instancias de la aplicación que están respondiendo.
Traffic Manager espera un lapso de tiempo concreto a recibir una respuesta desde la dirección URL de supervisión. Asegúrese de que el código de comprobación de estado se ejecuta en este tiempo. Permita la latencia de la red para el recorrido de ida y vuelta desde Traffic Manager a su aplicación y viceversa.
Pasos siguientes
Las directrices siguientes pueden ser útiles a la hora de implementar este patrón:
- Guía de supervisión del estado en aplicaciones basadas en microservicios
- Supervisión de la confiabilidad del estado de la aplicación, parte de Well-Architected Framework
- Creación de una nueva regla de alertas
Recursos relacionados
- Patrón External Configuration Store
- Circuit Breaker pattern (Patrón Circuit Breaker)
- Patrón Gateway Routing
- Patrón Gatekeeper