Controla los errores cuya recuperación puede tardar una cantidad variable de tiempo durante la conexión a un recurso o servicio remoto. Este patrón puede mejorar la estabilidad y la resistencia de una aplicación.
Contexto y problema
En un entorno distribuido, las llamadas a servicios y recursos remotos pueden producir errores debido a errores transitorios, como conexiones de red lentas, tiempos de espera o los recursos que se sobrecommiten o no están disponibles temporalmente. Estos errores suelen corregirse por sí mismos tras un breve período de tiempo y una aplicación sólida en la nube debe estar preparada para controlarlos mediante una estrategia como la del patrón Retry (reintento).
Sin embargo, también puede haber situaciones en las que los errores se deban a eventos no anticipados y cuya corrección puede tardar mucho más tiempo. La gravedad de estos errores puede abarcar desde una pérdida parcial de la conectividad hasta la total detención de un servicio. En estas situaciones, podría no tener sentido que una aplicación vuelva a intentar continuamente una operación que es poco probable que se realice correctamente y, en su lugar, la aplicación debería aceptar rápidamente que la operación ha fallado y controlar este error en consecuencia.
Además, si un servicio está muy ocupado, el error en una parte del sistema podría provocar errores en cascada. Por ejemplo, una operación que invoca un servicio podría configurarse para implementar un tiempo de espera y responder con un mensaje de error si el servicio no responde en este período. Sin embargo, esta estrategia podría hacer que muchas solicitudes simultáneas a la misma operación se bloqueen hasta que expire el período de tiempo de espera. Estas solicitudes bloqueadas pueden contener recursos críticos del sistema, tales como memoria, subprocesos o conexiones de base de datos, entre otros. Por lo tanto, estos recursos podrían agotarse, lo que provocaría errores de otras partes posiblemente no relacionadas del sistema que necesitan usar los mismos recursos. En estas situaciones, podría ser preferible para la operación dejar de funcionar de inmediato y solo intentar invocar el servicio si es probable que pueda ejecutarse correctamente. Establecer un tiempo de espera más corto podría ayudar a resolver este problema, pero el tiempo de espera no debería ser tan corto que la operación produzca un error la mayor parte del tiempo, incluso si la solicitud al servicio se realizaría correctamente.
Solución
El patrón Circuit Breaker puede impedir que una aplicación intente ejecutar repetidamente una operación que probablemente produzca un error. Ello le permite continuar sin esperar a corregir el error ni desperdiciar ciclos de CPU mientras se determina si el error continuará durante mucho tiempo. El patrón Circuit Breaker también permite a una aplicación detectar si el error se ha resuelto. Si el problema parece haberse corregido, la aplicación puede intentar invocar la operación.
El propósito del patrón Circuit Breaker difiere de la finalidad del patrón Retry. El patrón Retry permite a una aplicación volver a intentar una operación esperando que se podrá ejecutar correctamente. El patrón Circuit Breaker impide que una aplicación realice una operación que probablemente produzca errores. Una aplicación puede combinar estos dos patrones usando Retry para invocar una operación a través de un disyuntor. Sin embargo, la lógica de reintento debe tener en cuenta las excepciones devueltas por el disyuntor y dejar de reintentar la operación si este indica que un error no es transitorio.
Un disyuntor actúa como un proxy para las operaciones que podrían producir errores. El proxy debe supervisar el número de errores recientes que se han producido y usar esta información para decidir si desea permitir que la operación continúe o devolver una excepción inmediatamente.
El proxy se puede implementar como una máquina de estados con los siguientes estados que imitan la funcionalidad de un disyuntor eléctrico:
Closed (Cerrado): la solicitud de la aplicación se enruta a la operación. El proxy mantiene un recuento del número de errores recientes y, si la llamada a la operación se realiza correctamente, el proxy incrementa este recuento. Si el número de errores recientes supera un umbral especificado en un período de tiempo determinado, el proxy se coloca en el estado Open (abierto). En este momento, el proxy inicia un temporizador de tiempo de espera y, cuando este temporizador expira, el proxy se coloca en el estado de medio abierto.
El propósito del temporizador de tiempo de espera es dar tiempo al sistema para corregir el problema que provocó el error antes de permitir que la aplicación intente realizar la operación de nuevo.
Abrir: la solicitud de la aplicación produce un error inmediatamente y se devuelve una excepción a la aplicación.
Half-open (Semiabierto): se permite pasar un número limitado de solicitudes de la aplicación e invocar la operación. Si estas solicitudes se realizan correctamente, se supone que la causa del error se ha corregido y el disyuntor cambia al estado Closed (cerrado) y el número de errores se restablece. Si se produce un error en alguna solicitud, el disyuntor asume que el error sigue presente para que se revierta al estado Open y reinicia el temporizador de tiempo de espera para dar al sistema un período de tiempo adicional para recuperarse del error.
El estado Half-open (semiabierto) es útil para impedir que un servicio de recuperación se inunde de repente con solicitudes. A medida que un servicio se recupera, podría ser capaz de admitir un volumen limitado de solicitudes hasta que la recuperación se completa, pero, mientras está en curso, una saturación de trabajo puede hacer que el servicio agote el tiempo de espera o dé error de nuevo.
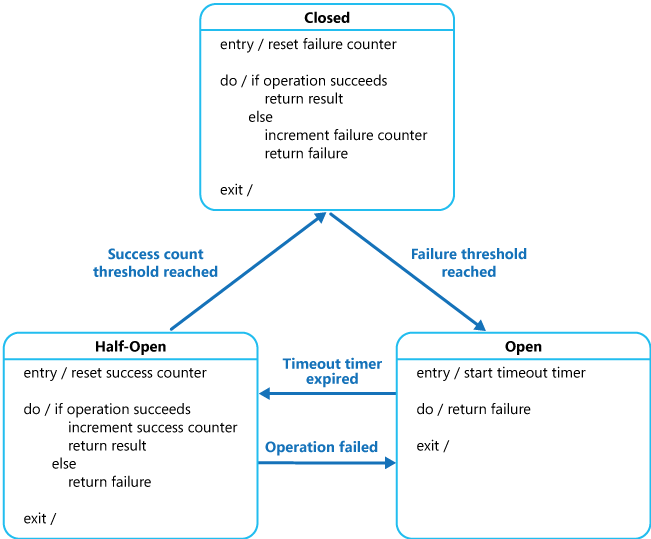
En la ilustración, el contador de errores que usa el estado Closed (cerrado) depende del tiempo. Se restablece automáticamente a intervalos periódicos. Este diseño ayuda a evitar que el disyuntor entre en el estado Abrir si experimenta errores ocasionales. El umbral de error que se encuentra con el disyuntor en el estado Open (abierto) solo se alcanza cuando se produce un número especificado de errores durante un intervalo especificado. El contador utilizado por el estado Half-Open (semiabierto) registra el número de intentos correctos para invocar la operación. El disyuntor vuelve al estado Closed (cerrado) después de un número especificado de llamadas consecutivas a la operación que hayan tenido éxito. Si se produce un error en alguna invocación, el disyuntor entra en el estado Open (abierto) inmediatamente y el contador de éxitos se restablecerá la próxima vez que entre en el estado Half-Open (semiabierto).
Externamente, es posible que las recuperaciones del sistema se traten restaurando o reiniciando un componente erróneo o reparando una conexión de red.
El patrón Circuit Breaker proporciona estabilidad mientras el sistema se recupera de un error y minimiza el impacto en el rendimiento. Puede ayudar a mantener el tiempo de respuesta del sistema al rechazar rápidamente una solicitud para una operación que es probable que dé error, en lugar de esperar a que agote el tiempo de espera o no termine nunca. Si el disyuntor genera un evento cada vez que cambia el estado, esta información puede utilizarse para supervisar el estado de la parte del sistema protegida por el disyuntor o para alertar a un administrador cuando un disyuntor se active en el estado Open (abierto).
El patrón es personalizable y puede adaptarse según el tipo de errores posibles. Por ejemplo, puede aplicar un temporizador de tiempo de espera creciente a un disyuntor. Puede colocar el disyuntor en el estado Open durante unos segundos inicialmente y, después, si el error no se ha resuelto, aumente el tiempo de espera a unos minutos, etc. En algunos casos, en lugar de que el estado Open (abierto) devuelva un error y genere una excepción, puede ser útil devolver un valor predeterminado que sea significativo para la aplicación.
Nota
Tradicionalmente, los disyuntores se basaban en umbrales preconfigurados, como el recuento de errores y la duración del tiempo de espera, lo que da lugar a un comportamiento determinista pero a veces poco óptimo. Sin embargo, las técnicas adaptables que usan IA y ML pueden ajustar dinámicamente los umbrales en función de los patrones de tráfico en tiempo real, las anomalías y las tasas de errores históricos, lo que hace que el disyuntor sea más resistente y eficaz.
Problemas y consideraciones
A la hora de decidir cómo implementar este patrón, debe considerar los siguientes puntos:
control de excepciones: una aplicación que invoca una operación a través de un disyuntor debe estar preparada para controlar las excepciones que se producen si la operación no está disponible. La forma en que se controlan las excepciones será específica de la aplicación. Por ejemplo, una aplicación podría degradar temporalmente su funcionalidad, invocar una operación alternativa para intentar realizar la misma tarea u obtener los mismos datos, o notificar la excepción al usuario y pedirle que la vuelva a intentar más tarde.
Tipos de excepciones: una solicitud podría producir un error por muchas razones, algunas de las cuales podrían indicar un tipo de error más grave que otros. Por ejemplo, una solicitud podría producir un error porque un servicio remoto se ha bloqueado y tardará varios minutos en recuperarse o debido a un tiempo de espera debido a que el servicio se sobrecarga temporalmente. Un disyuntor puede examinar los tipos de excepciones que se producen y ajustar su estrategia en función de la naturaleza de estas excepciones. Por ejemplo, podría requerir un mayor número de excepciones de tiempo de espera para que el disyuntor entre el estado Open en comparación con el número de errores debido a que el servicio no está disponible por completo.
Supervisión: un disyuntor debe proporcionar observabilidad clara en solicitudes con errores y correctas, lo que permite a los equipos de operaciones evaluar el estado del sistema. Use el seguimiento distribuido para la visibilidad de un extremo a otro en todos los servicios.
capacidad de recuperación: debe configurar el disyuntor para que coincida con el patrón de recuperación probable de la operación que protege. Por ejemplo, si el disyuntor permanece en el estado Open (abierto) durante un largo período, podría producir excepciones aunque el motivo del error se hubiese resuelto. De igual forma, podría fluctuar y reducir los tiempos de respuesta de las aplicaciones si pasa del estado Open a Half-Open demasiado rápidamente.
Las operaciones con errores de prueba: en el estado Open, en lugar de usar un temporizador para determinar cuándo cambiar al estado de medio abierto, un disyuntor puede hacer ping periódicamente al servicio remoto o al recurso para determinar si está disponible de nuevo. Este ping podría adoptar la forma de intento de invocar una operación que hubiera generado el error previamente o podría usar una operación especial proporcionada por el servicio remoto de forma específica para probar el estado del servicio, como se describe en el patrón Health Endpoint Monitoring (supervisión del punto de conexión de estado).
invalidación manual: en un sistema en el que el tiempo de recuperación de una operación con errores es extremadamente variable, es beneficioso proporcionar una opción de restablecimiento manual que permite a un administrador cerrar un interruptor (y restablecer el contador de errores). Del mismo modo, un administrador podría forzar un disyuntor al estado Abrir (y reiniciar el temporizador de tiempo de espera) si la operación protegida por el disyuntor no está disponible temporalmente.
simultaneidad: un gran número de instancias simultáneas de una aplicación podría tener acceso al mismo disyuntor. La implementación no debe bloquear las solicitudes simultáneas ni agregar una sobrecarga excesiva a cada llamada a una operación.
diferenciación de recursos: tenga cuidado al usar un único disyuntor para un tipo de recurso si puede haber varios proveedores independientes subyacentes. Por ejemplo, en un almacén de datos que contenga varias particiones, una podría ser totalmente accesible mientras otra experimenta un problema temporal. Si se combinan las respuestas de error en estos casos, una aplicación podría intentar acceder a algunas particiones incluso cuando fuese muy probable que se produjera un error, mientras que el acceso a las otras podría bloquearse, aunque hubiera mucha probabilidad de que no sufrieran problemas.
circuito acelerado: a veces, una respuesta de error puede contener suficiente información para que el disyuntor viaje inmediatamente y permanezca en un período mínimo de tiempo. Por ejemplo, la respuesta de error de un recurso compartido que está sobrecargado podría indicar que no se recomienda un reintento inmediato y que la aplicación, en cambio, debe intentarse de nuevo al cabo de unos minutos.
implementaciones de varias regiones: un disyuntor podría diseñarse para implementaciones únicas o de varias regiones. Este último se puede implementar mediante equilibradores de carga globales o estrategias de interrupción de circuitos personalizados compatibles con regiones que garantizan la conmutación por error controlada, la optimización de la latencia y el cumplimiento normativo.
interruptores de malla de servicio: los disyuntores se pueden implementar en la capa de aplicación o como una característica abstracta transversal. Por ejemplo, las mallas de servicio suelen admitir la interrupción del circuito como una sidecar o como una funcionalidad independiente sin modificar el código de la aplicación.
Nota
Un servicio puede devolver HTTP 429 (demasiadas solicitudes) si limita el cliente o HTTP 503 (servicio no disponible) si el servicio no está disponible actualmente. La respuesta puede incluir información adicional, como la duración prevista del retraso.
Reproducción de solicitudes con error: en el estado Abrir, en lugar de simplemente con errores rápidamente, un disyuntor también podría registrar los detalles de cada solicitud en un diario y organizar que estas solicitudes se reproduzcan cuando el recurso o servicio remoto esté disponible.
tiempos de espera inadecuados en servicios externos: es posible que un disyuntor no pueda proteger completamente las aplicaciones de las operaciones que producen errores en los servicios externos configurados con un largo período de tiempo de espera. Si el tiempo de espera es demasiado largo, es posible que un subproceso que ejecute un disyuntor se bloquee durante un período prolongado antes de que el disyuntor indique que se ha producido un error en la operación. En este momento, muchas otras instancias de aplicaciones también podrían intentar invocar el servicio a través del disyuntor y ocupar un número significativo de subprocesos antes de que todos den error.
adaptación a la diversificación de proceso: los disyuntores deben tener en cuenta diferentes entornos de proceso, desde cargas de trabajo sin servidor a en contenedores, donde factores como arranques en frío y control de errores de escalabilidad. Los enfoques adaptables pueden ajustar dinámicamente las estrategias en función del tipo de proceso, lo que garantiza la resistencia en arquitecturas heterogéneas.
Cuándo usar este patrón
Use este patrón:
- Para evitar errores en cascada mediante la detención de invocaciones excesivas por parte de un servicio remoto o solicitudes de acceso a un recurso compartido si es muy probable que se produzca un error en estas operaciones.
- Para mejorar la resistencia de varias regiones mediante el enrutamiento inteligente del tráfico en función de las señales de error en tiempo real.
- Para protegerse frente a dependencias lentas, lo que le ayuda a mantenerse al día con los objetivos de nivel de servicio (SLO) y para evitar la degradación del rendimiento debido a los servicios de alta latencia.
- Para controlar problemas de conectividad intermitentes y reducir los errores de solicitud en entornos distribuidos.
No se recomienda este patrón:
- Para el control del acceso a los recursos locales privados en una aplicación, como la estructura de datos en memoria. En este entorno, el uso de un disyuntor agregaría sobrecarga al sistema.
- Como sustituto para controlar las excepciones en la lógica empresarial de las aplicaciones.
- Cuando los algoritmos de reintento conocidos son suficientes y las dependencias están diseñadas para tratar con mecanismos de reintento. La implementación de un disyuntor en la aplicación en este caso podría agregar complejidad innecesaria al sistema.
- Cuando se espera a que se restablezca un interruptor, es posible que se produzcan retrasos inaceptables.
- Si tiene una arquitectura controlada por mensajes o controlada por eventos, ya que a menudo enrutan mensajes con errores a una cola de mensajes fallidos (DLQ) para el procesamiento manual o diferido. El aislamiento de errores integrado y los mecanismos de reintento que normalmente se implementan en estos diseños son suficientes.
- Si la recuperación de errores se administra en el nivel de infraestructura o plataforma, como con comprobaciones de estado en equilibradores de carga globales o mallas de servicio, es posible que los disyuntores no sean necesarios.
Diseño de cargas de trabajo
El arquitecto debe evaluar cómo se puede usar el patrón del disyuntor en el diseño de su carga de trabajo para abordar los objetivos y principios tratados en los pilares del Marco de la Well-Architected de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | Este patrón evita la sobrecarga de una dependencia con errores. También puede utilizar este patrón para desencadenar la degradación gradual de la carga de trabajo. Los disyuntores se suelen acoplar con recuperación automática para proporcionar tanto recuperación automática como conservación automática. - RE:03 Análisis del modo de error - RE:07 Errores transitorios - RE:07 Conservación automática |
| La eficiencia del rendimiento ayuda a que la carga de trabajo satisfaga eficazmente las demandas mediante optimizaciones en el escalado, los datos y el código. | Este patrón evita el enfoque de reintento por error, que puede conducir a una utilización excesiva de recursos durante la recuperación de la dependencia y también puede sobrecargar el rendimiento de una dependencia que está intentando recuperarse. - PE:07 Código e infraestructura - PE:11 Respuestas a problemas en tiempo real |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Recursos relacionados
Los patrones siguientes también pueden ser útiles a la hora de implementar este modelo:
El patrón de aplicación web confiable muestra cómo aplicar el patrón de disyuntor a una aplicación web convergente en la nube.
Patrón Retry. Describe el modo en que una aplicación puede tratar los errores temporales anticipados cuando intenta conectarse a un servicio o un recurso de red, al reintentar de forma transparente una operación que anteriormente fracasó.
Patrón Health Endpoint Monitoring. Un disyuntor puede probar el estado de un servicio enviando una solicitud a un punto de conexión expuesto por el servicio. El servicio debería devolver información que indique su estado.