Examen del estado de mantenimiento de nodos y pods
Este artículo forma parte de una serie. Comience con la información general.
Si ya comprende las comprobaciones de clústeres que realizó en el paso anterior, compruebe el estado de los nodos de trabajo de Azure Kubernetes Service (AKS). Siga los seis pasos de este artículo para comprobar el estado de los nodos, determinar el motivo de un nodo incorrecto y resolver el problema.
Paso 1: Comprobación del estado de los nodos de trabajo
Varios factores pueden contribuir a nodos incorrectos en un clúster de AKS. Una razón común es el desglose de la comunicación entre el plano de control y los nodos. Esta comunicación incorrecta suele deberse a errores de configuración en las reglas de enrutamiento y firewall.
Al configurar el clúster de AKS para enrutamiento definido por el usuario, debe configurar rutas de salida a través de una aplicación virtual de red (NVA) o un firewall, como un firewall de Azure. Para solucionar un problema de configuración incorrecta, se recomienda configurar el firewall para permitir los puertos necesarios y los nombres de dominio completos (FQDN) de acuerdo con la guía de tráfico de salida de AKS.
Otro motivo para que existan nodos incorrectos podría ser un proceso, memoria o recursos de almacenamiento inadecuados que crean presiones de kubelet. En tales casos, el escalado vertical de los recursos puede resolver eficazmente el problema.
En un clúster de AKS privado, los problemas de resolución del sistema de nombres de dominio (DNS) pueden provocar problemas de comunicación entre el plano de control y los nodos. Debe comprobar que el nombre DNS del servidor de API de Kubernetes se resuelve en la dirección IP privada del servidor de API. La configuración incorrecta de un servidor DNS personalizado es una causa común de errores de resolución DNS. Si usa servidores DNS personalizados, asegúrese de especificarlos correctamente como servidores DNS en la red virtual donde se aprovisionan los nodos. Confirme también que el servidor de API privada de AKS se puede resolverse a través del servidor DNS personalizado.
Después de solucionar estos posibles problemas relacionados con la comunicación del plano de control y la resolución de DNS, puede abordar y resolver de forma eficaz los problemas de mantenimiento del nodo dentro del clúster de AKS.
Puede evaluar el estado de los nodos mediante uno de los métodos siguientes.
Vista de estado de contenedores de Azure Monitor
Para ver el estado de los nodos, los pods de usuario y los pods del sistema en el clúster de AKS, siga estos pasos:
- En Azure Portal, vaya a Azure Monitor.
- En la sección Conclusiones del panel de navegación, seleccione Contenedores.
- Seleccione Clústeres supervisados para obtener una lista de los clústeres de AKS que se están supervisando.
- Elija un clúster de AKS en la lista para ver el estado de los nodos, los pods de usuario y los pods del sistema.

Vista de nodos de AKS
Para asegurarse de que todos los nodos del clúster de AKS estén preparados, siga estos pasos:
- En Azure Portal, vaya al clúster de AKS.
- En la sección Configuración del panel de navegación, seleccione Grupos de nodos.
- Seleccione Nodos.
- Compruebe que todos los nodos estén en estado Preparado.

Supervisión en clústeres con Prometheus y Grafana
Si ha implementado Prometheus y Grafana en el clúster de AKS, puede usar el panel de detalles del clúster K8 para obtener información. En este panel se muestran las métricas del clúster de Prometheus y se presenta información clave, como el uso de CPU, el uso de memoria, la actividad de red y el uso del sistema de archivos. También se muestran estadísticas detalladas de pods, contenedores y servicios systemd individuales.
En el panel, seleccione Condiciones del nodo para ver las métricas sobre el estado y el rendimiento del clúster. Puede realizar un seguimiento de los nodos que tengan potencialmente problemas con su programación, la red, la presión del disco, la presión de memoria, la presión de derivado integral proporcional (PID) o el espacio en disco. Supervise estas métricas para que pueda identificar y solucionar de forma proactiva los posibles problemas que afecten a la disponibilidad y el rendimiento del clúster de AKS.

Supervisión del servicio administrado para Prometheus y Azure Managed Grafana
Puede usar paneles creados previamente para visualizar y analizar las métricas de Prometheus. Para ello, debe configurar el clúster de AKS para recopilar métricas de Prometheus en Supervisión del servicio administrado para Prometheus y conectar el área de trabajo de Monitor a un área de trabajo de Azure Managed Grafana. Estos paneles proporcionan una vista completa del rendimiento y el estado del clúster de Kubernetes.
Los paneles se aprovisionan en la instancia de Azure Managed Grafana especificada en la carpeta Prometheus administrado. Algunos paneles incluyen:
- Kubernetes/Recursos de proceso/Clúster
- Kubernetes/Recursos de proceso/Espacio de nombres (pods)
- Kubernetes/Recursos de proceso/Nodo (pods)
- Kubernetes/Recursos de proceso/Pod
- Kubernetes/Recursos de proceso/Espacio de nombres (cargas de trabajo)
- Kubernetes/Recursos de proceso/Carga de trabajo
- Kubernetes/Kubelet
- Exportador de nodos/Método USE/Nodo
- Exportador de nodos/Nodos
- Kubernetes/Recursos de proceso/Clúster (ventanas)
- Kubernetes/Recursos de proceso/Espacio de nombres (ventanas)
- Kubernetes/Recursos de proceso/Pod (ventanas)
- Kubernetes/Método USE/Clúster (ventanas)
- Kubernetes/Método USE/Nodo (ventanas)
Estos paneles integrados se usan ampliamente en la comunidad de código abierto para supervisar clústeres de Kubernetes con Prometheus y Grafana. Use estos paneles para ver métricas, como el uso de recursos, el estado del pod y la actividad de red. También puede crear paneles personalizados adaptados a sus necesidades de supervisión. Los paneles le ayudan a supervisar y analizar de forma eficaz las métricas de Prometheus en el clúster de AKS, lo que le permite optimizar el rendimiento, solucionar problemas y garantizar un funcionamiento sin problemas de las cargas de trabajo de Kubernetes.
Puede usar el panel Kubernetes/ Recursos de proceso/Nodo (pods) para ver las métricas de los nodos del agente de Linux. Puede visualizar el uso de CPU, la cuota de CPU, el uso de memoria y la cuota de memoria para cada pod.

Si el clúster incluye nodos de agente de Windows, puede usar el panel de Kubernetes/Método USE/Nodo (Windows) para visualizar las métricas de Prometheus que se recopilan de estos nodos. Este panel proporciona una vista completa del consumo de recursos y el rendimiento de los nodos de Windows dentro del clúster.
Aproveche estos paneles dedicados para supervisar y analizar fácilmente métricas importantes relacionadas con la CPU, la memoria y otros recursos en los nodos del agente de Linux y Windows. Esta visibilidad le permite identificar posibles cuellos de botella, optimizar la asignación de recursos y garantizar una operación eficaz en el clúster de AKS.
Paso 2: Comprobación de la conectividad entre el plano de control y el nodo de trabajo
Si los nodos de trabajo son correctos, debe examinar la conectividad entre el plano de control de AKS administrado y los nodos de trabajo. AKS permite la comunicación entre el servidor de API de Kubernetes y el nodo individual kubelets a través de un método de comunicación de túnel seguro. Estos componentes pueden comunicarse incluso si están en diferentes redes virtuales. El túnel está protegido con cifrado mutuo de seguridad de la capa de transporte (mTLS). El túnel principal que usa AKS se denomina Konnectivity (anteriormente apiserver-network-proxy). Asegúrese de que todas las reglas de red y los FQDN cumplen las reglas de red de Azure necesarias.
Para comprobar la conectividad entre el plano de control de AKS administrado y los nodos de trabajo del clúster de un clúster de AKS, puede usar la herramienta de línea de comandos kubectl.
Para asegurarse de que los pods del agente konnectivity funcionan correctamente, ejecute el siguiente comando:
kubectl get deploy konnectivity-agent -n kube-system
Asegúrese de que los pods están en el estado Preparado.
Si hay un problema con la conectividad entre el plano de control y los nodos de trabajo, establezca la conectividad después de asegurarse de que se permiten las reglas de tráfico de salida de AKS necesarias.
Ejecute el comando siguiente para reiniciar los pods de konnectivity-agent:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Si reiniciar los pods no corrige la conexión, compruebe si hay anomalías en los registros. Ejecute el comando siguiente para ver los registros de los pods de konnectivity-agent:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
Los registros deben mostrar la siguiente salida:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Nota:
Cuando se configura un clúster de AKS con una integración de red virtual del servidor de API y una interfaz de red de contenedor de Azure (CNI) o una instancia de Azure CNI con asignación dinámica de IP de pod, no es necesario implementar agentes de Konnectivity. Los pods del servidor de API integrados pueden establecer comunicación directa con los nodos de trabajo del clúster a través de redes privadas.
Sin embargo, cuando se usa la integración de red virtual del servidor de API con la superposición de Azure CNI o Bring Your Own CNI (BYOCNI), se implementa Konnectivity para facilitar la comunicación entre los servidores de API y las direcciones IP de pod. La comunicación entre los servidores de API y los nodos de trabajo sigue siendo directa.
También puede buscar los registros de contenedor en el servicio de registro y supervisión para recuperar los registros. Para obtener un ejemplo en el que se buscan errores de conectividad de aks-link, lea Consultar registros de las conclusiones de contenedores.
Ejecute la consulta siguiente para recuperar los registros:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Ejecute la consulta siguiente para buscar registros de contenedor para cualquier pod con errores en un espacio de nombres específico:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Si no puede obtener los registros mediante consultas o la herramienta kubectl, use Autenticación de Secure Shell (SSH). En este ejemplo se busca el pod de tunnelfront después de conectarse al nodo mediante SSH.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Paso 3: Validación de la resolución de DNS al restringir la salida
La resolución DNS es un aspecto fundamental del clúster de AKS. Si la resolución DNS no funciona correctamente, puede provocar errores de plano de control o errores de extracción de imágenes de contenedor. Para asegurarse de que la resolución DNS en el servidor de API de Kubernetes funciona correctamente, siga estos pasos:
Ejecute el comando kubectl exec para abrir un shell de comandos en el contenedor que se ejecuta en el pod.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashCompruebe si las herramientas de nslookup o dig están instaladas en el contenedor.
Si ninguna herramienta está instalada en el pod, ejecute el siguiente comando para crear un pod de utilidad en el mismo espacio de nombres.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shPuede recuperar la dirección del servidor de API desde la página de información general del clúster de AKS en Azure Portal, o bien puede ejecutar el siguiente comando.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvEjecute el siguiente comando para intentar resolver el servidor de API de AKS. Para obtener más información, consulte Solución de errores de resolución de DNS desde el pod, pero no desde el nodo de trabajo.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioCompruebe el servidor DNS ascendente del pod para determinar si la resolución DNS funciona correctamente. Por ejemplo, para Azure DNS, ejecute el comando
nslookup.nslookup microsoft.com 168.63.129.16Si los pasos anteriores no proporcionan conclusiones, conéctese a uno de los nodos de trabajo e intente la resolución DNS desde el nodo. Este paso ayuda a identificar si el problema está relacionado con AKS o la configuración de red.
Si la resolución DNS se realiza correctamente desde el nodo pero no desde el pod, el problema podría estar relacionado con DNS de Kubernetes. Para conocer los pasos para depurar la resolución DNS desde el pod, consulte Solución de problemas de resolución de DNS.
Si se produce un error en la resolución DNS del nodo, revise la configuración de red para asegurarse de que las rutas de enrutamiento y los puertos adecuados están abiertos para facilitar la resolución DNS.
Paso 4: Comprobación de errores de kubelet
Compruebe la condición del proceso de kubelet que se ejecuta en cada nodo de trabajo y asegúrese de que no sufre ninguna presión. Si se da una posible presión, esta puede estar relacionada con la CPU, la memoria o el almacenamiento. Para comprobar el estado de kubelets de nodo individual, puede usar uno de los métodos siguientes.
Libro kubelet de AKS
Para asegurarse de que los kubelets del nodo del agente funcionan correctamente, siga estos pasos:
Vaya al clúster de AKS en Azure Portal.
En la sección Supervisión del panel de navegación, seleccione Libros.
Seleccione el libro Kubelet.
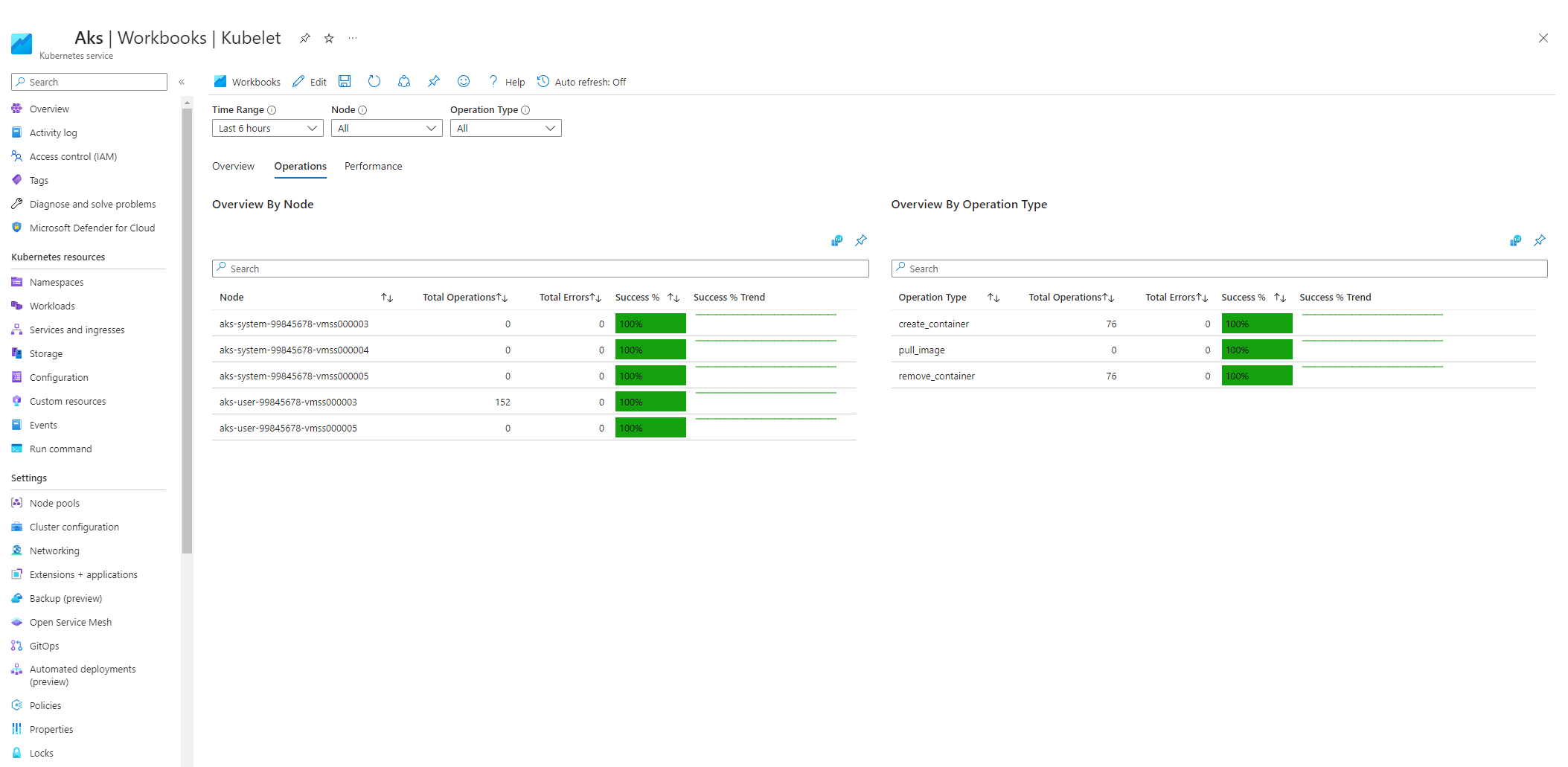
Seleccione Operaciones y asegúrese de que se completen las operaciones de todos los nodos de trabajo.


Supervisión en clústeres con Prometheus y Grafana
Si ha implementado Prometheus y Grafana en el clúster de AKS, puede usar el panel de Kubernetes/Kubelet para obtener información sobre el estado y el rendimiento de kubelets de nodos individuales.

Supervisión del servicio administrado para Prometheus y Azure Managed Grafana
Puede usar el panel precompilado Kubernetes/Kubelet para visualizar y analizar las métricas de Prometheus para el nodo de trabajo kubelets. Para ello, debe configurar el clúster de AKS para recopilar métricas de Prometheus en Supervisión del servicio administrado para Prometheus y conectar el área de trabajo de Monitor a un área de trabajo de Azure Managed Grafana.

La presión aumenta cuando un kubelet se reinicia y provoca un comportamiento esporádico e imprevisible. Asegúrese de que el recuento de errores no crezca continuamente. No pasa nada porque haya algún error ocasionalmente, pero si se da un crecimiento constante de ellos, esto indica la presencia de un problema subyacente que debe investigar y resolver.
Paso 5: Uso de la herramienta de detección de problemas de nodo (NPD) para comprobar el estado del nodo
NPD es una herramienta de Kubernetes que puede usar para identificar y notificar problemas relacionados con el nodo. Funciona como un servicio systemd en cada nodo del clúster. Recopila métricas e información del sistema, como el uso de CPU, el uso del disco y el estado de conectividad de red. Cuando se detecta un problema, la herramienta NPD genera un informe sobre los eventos y la condición del nodo. En AKS, la herramienta NPD se usa para supervisar y administrar nodos en un clúster de Kubernetes hospedado en la nube de Azure. Para obtener más información, consulte NPD en nodos de AKS.
Paso 6: Comprobación de las operaciones de E/S de disco por segundo (IOPS) para la limitación
Para asegurarse de que las IOPS no están limitadas y no afectan a los servicios y las cargas de trabajo del clúster de AKS, puede usar uno de los métodos siguientes.
Libro de E/S de disco de nodo de AKS
Para supervisar las métricas relacionadas con la E/S de disco de los nodos de trabajo del clúster de AKS, puede usar el libro de E/S de disco de nodo. Siga estos pasos para acceder al libro:
Vaya al clúster de AKS en Azure Portal.
En la sección Supervisión del panel de navegación, seleccione Libros.
Seleccione el libro E/S de disco de nodo.
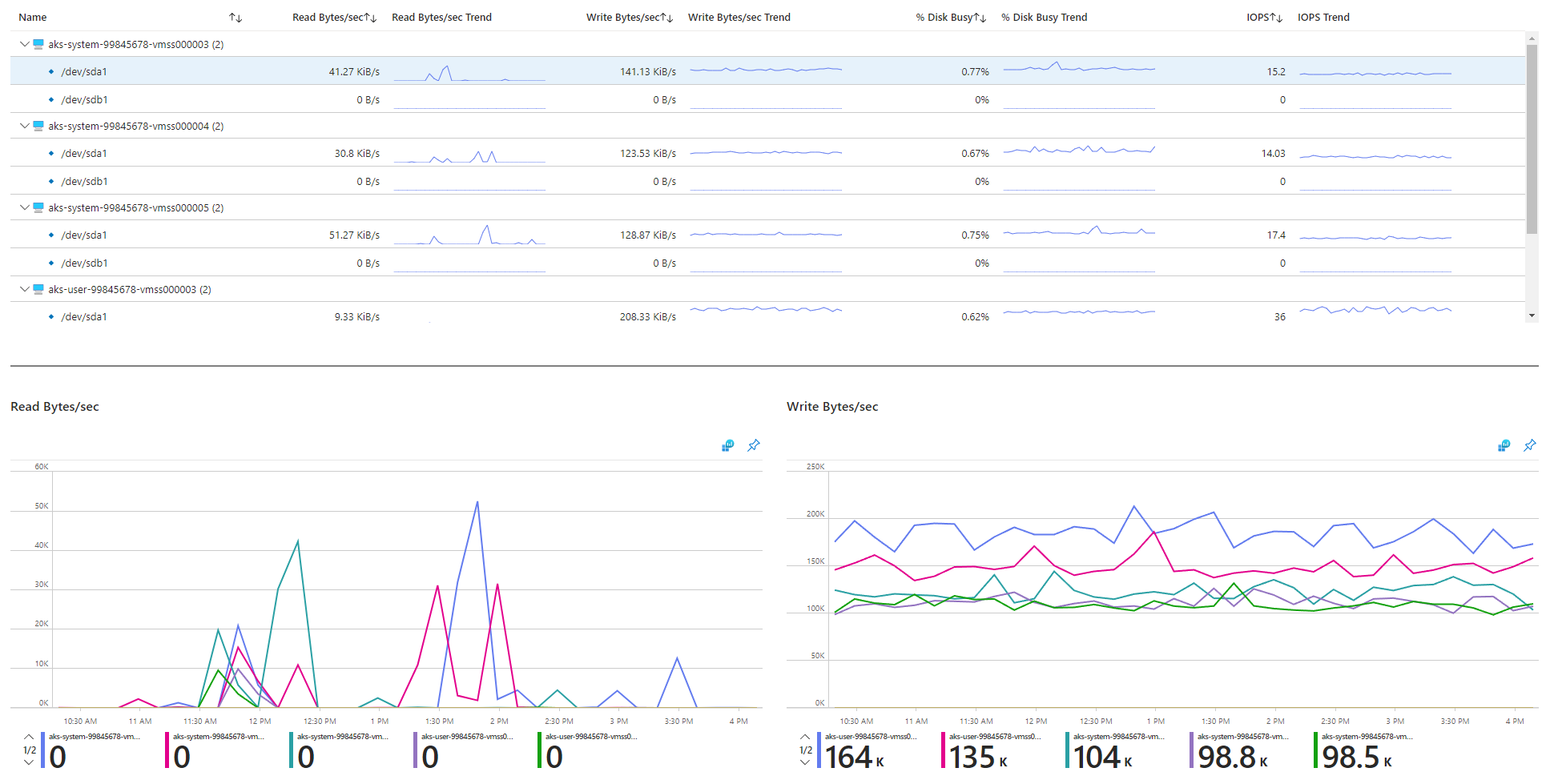
Revise las métricas de E/S.


Supervisión en clústeres con Prometheus y Grafana
Si ha implementado Prometheus y Grafana en el clúster de AKS, puede usar el panel de Método USE/Nodo para obtener información sobre la E/S de disco de los nodos de trabajo del clúster.

Supervisión del servicio administrado para Prometheus y Azure Managed Grafana
Puede usar el panel precompilado Exportador de nodos/Nodos para visualizar y analizar las métricas relacionadas con la E/S de disco de los nodos de trabajo. Para ello, debe configurar el clúster de AKS para recopilar métricas de Prometheus en Supervisión del servicio administrado para Prometheus y conectar el área de trabajo de Monitor a un área de trabajo de Azure Managed Grafana.

IOPS y discos de Azure
Los dispositivos de almacenamiento físico tienen limitaciones inherentes en términos de ancho de banda y el número máximo de operaciones de archivo que pueden controlar. Los discos de Azure se usan para almacenar el sistema operativo que se ejecuta en nodos de AKS. Los discos están sujetos a las mismas restricciones de almacenamiento físico que el sistema operativo.
Considere el concepto de rendimiento. Puede multiplicar el tamaño medio de E/S por IOPS para determinar el rendimiento en megabytes por segundo (MB/s). Los tamaños de E/S más grandes generan IOPS inferiores debido al rendimiento fijo del disco.
Cuando una carga de trabajo supera los límites máximos de servicio de IOPS asignados a los discos de Azure, es posible que el clúster deje de responder y escriba un estado de espera de E/S. En los sistemas basados en Linux, muchos componentes se tratan como archivos, como sockets de red, CNI, Docker y otros servicios que dependen de la E/S de red. Por lo tanto, si no se puede leer el disco, el error se extiende a todos estos archivos.
Varios eventos y escenarios pueden desencadenar la limitación de IOPS, entre los que se incluyen:
Un número considerable de contenedores que se ejecutan en nodos, ya que E/S de Docker comparte el disco del sistema operativo.
Herramientas personalizadas o de terceros que se emplean para la seguridad, la supervisión y el registro, y que podrían generar operaciones de E/S adicionales en el disco del sistema operativo.
Eventos de conmutación por error de nodo y trabajos periódicos que intensifican la carga de trabajo o escalan el número de pods. Este aumento de la carga aumenta la probabilidad de que se produzcan repeticiones de limitación, lo que puede provocar que todos los nodos pasen a un estado No preparado hasta que finalicen las operaciones de E/S.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Paolo Salvatori | Ingeniero principal de clientes
- Francis Simy Nazareth | Especialista técnico sénior
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.