Una arquitectura de macrodatos está diseñada para controlar la ingesta, el procesamiento y el análisis de datos demasiado grandes o complejos para los sistemas de base de datos tradicionales.

Las soluciones de macrodatos suelen implicar uno o varios de los siguientes tipos de carga de trabajo:
- Procesamiento por lotes de orígenes de macrodatos en reposo.
- Procesamiento en tiempo real de macrodatos en movimiento.
- Exploración interactiva de macrodatos.
- Análisis predictivo y aprendizaje automático.
La mayoría de las arquitecturas de macrodatos incluyen algunos o todos los componentes siguientes:
Orígenes de datos: todas las soluciones de macrodatos comienzan con uno o varios orígenes de datos. Algunos ejemplos son:
- Almacenes de datos de aplicaciones, como bases de datos relacionales.
- Archivos estáticos generados por aplicaciones, como archivos de registro del servidor web.
- Orígenes de datos en tiempo real, como dispositivos IoT.
almacenamiento de datos: los datos para las operaciones de procesamiento por lotes se almacenan normalmente en un almacén de archivos distribuido que pueden contener grandes volúmenes de archivos grandes en varios formatos. Este tipo de almacén se suele denominar lago de datos . Las opciones para implementar este almacenamiento incluyen Azure Data Lake Store o contenedores de blobs en Azure Storage.
procesamiento por lotes: dado que los conjuntos de datos son tan grandes, a menudo una solución de macrodatos debe procesar archivos de datos mediante trabajos por lotes de ejecución prolongada para filtrar, agregar y preparar los datos para su análisis. Normalmente, estos trabajos implican leer archivos de origen, procesarlos y escribir la salida en nuevos archivos. Entre las opciones se incluyen el uso de flujos de datos, canalizaciones de datos en Microsoft Fabric.
ingesta de mensajes en tiempo real: si la solución incluye orígenes en tiempo real, la arquitectura debe incluir una manera de capturar y almacenar mensajes en tiempo real para el procesamiento de flujos. Esto puede ser un almacén de datos simple, donde los mensajes entrantes se quitan en una carpeta para su procesamiento. Sin embargo, muchas soluciones necesitan un almacén de ingesta de mensajes para actuar como búfer para los mensajes y para admitir el procesamiento de escalabilidad horizontal, la entrega confiable y otras semánticas de puesta en cola de mensajes. Entre las opciones se incluyen Azure Event Hubs, Azure IoT Hubs y Kafka.
procesamiento de flujos: después de capturar mensajes en tiempo real, la solución debe procesarlos filtrando, agregando y preparando los datos para su análisis. A continuación, los datos de flujo procesados se escriben en un receptor de salida. Azure Stream Analytics proporciona un servicio de procesamiento de flujos administrado basado en la ejecución perpetua de consultas SQL que funcionan en flujos no enlazados. Otra opción es usar inteligencia en tiempo real en Microsoft Fabric, que permite ejecutar consultas KQL a medida que se ingieren los datos.
almacén de datos analíticos: muchas soluciones de macrodatos preparan datos para el análisis y, a continuación, sirven los datos procesados en un formato estructurado que se puede consultar mediante herramientas analíticas. El almacén de datos analíticos que se usa para atender estas consultas puede ser un almacenamiento de datos relacional de estilo Kimball, como se ve en la mayoría de las soluciones de inteligencia empresarial (BI) tradicionales o una casa de lago con arquitectura medallion (Bronze, Silver y Gold). Azure Synapse Analytics proporciona un servicio administrado para el almacenamiento de datos basado en la nube a gran escala. Como alternativa, Microsoft Fabric proporciona ambas opciones: almacenamiento y lakehouse, que se pueden consultar mediante SQL y Spark, respectivamente.
análisis e informes: el objetivo de la mayoría de las soluciones de macrodatos es proporcionar información sobre los datos a través del análisis y los informes. Para permitir a los usuarios analizar los datos, la arquitectura puede incluir una capa de modelado de datos, como un cubo OLAP multidimensional o un modelo de datos tabulares en Azure Analysis Services. También puede admitir bi de autoservicio, mediante las tecnologías de modelado y visualización en Microsoft Power BI o Microsoft Excel. El análisis y los informes también pueden adoptar la forma de exploración interactiva de datos por parte de científicos de datos o analistas de datos. En estos escenarios, Microsoft Fabric proporciona herramientas como cuadernos en los que el usuario puede elegir SQL o un lenguaje de programación de su elección.
orquestación: la mayoría de las soluciones de macrodatos constan de operaciones de procesamiento de datos repetidas, encapsuladas en flujos de trabajo, que transforman los datos de origen, mueven datos entre varios orígenes y receptores, cargan los datos procesados en un almacén de datos analíticos o insertan los resultados directamente en un informe o panel. Para automatizar estos flujos de trabajo, puede usar una tecnología de orquestación como Azure Data Factory o canalizaciones de Microsoft Fabric.
Azure incluye muchos servicios que se pueden usar en una arquitectura de macrodatos. Se dividen aproximadamente en dos categorías:
- Servicios administrados, incluidos Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub y Azure Data Factory.
- Tecnologías de código abierto basadas en la plataforma Apache Hadoop, como HDFS, HBase, Hive, Spark y Kafka. Estas tecnologías están disponibles en Azure en el servicio Azure HDInsight.
Estas opciones no son mutuamente excluyentes y muchas soluciones combinan tecnologías de código abierto con servicios de Azure.
Cuándo usar esta arquitectura
Tenga en cuenta este estilo de arquitectura cuando necesite:
- Almacene y procese datos en volúmenes demasiado grandes para una base de datos tradicional.
- Transformar datos no estructurados para el análisis y los informes.
- Capture, procese y analice flujos de datos sin enlazar en tiempo real o con baja latencia.
- Use Azure Machine Learning o Azure Cognitive Services.
Beneficios
- opciones de tecnología de . Puede combinar y hacer coincidir los servicios administrados de Azure y las tecnologías de Apache en clústeres de HDInsight, para aprovechar las aptitudes o inversiones tecnológicas existentes.
- rendimiento mediante paralelismo. Las soluciones de macrodatos aprovechan el paralelismo, lo que permite soluciones de alto rendimiento que se escalan a grandes volúmenes de datos.
- escalado elástico. Todos los componentes de la arquitectura de macrodatos admiten el aprovisionamiento de escalabilidad horizontal, de modo que pueda ajustar la solución a cargas de trabajo pequeñas o grandes y pagar solo por los recursos que use.
- Interoperabilidad con soluciones existentes. Los componentes de la arquitectura de macrodatos también se usan para soluciones de inteligencia empresarial y procesamiento de IoT, lo que le permite crear una solución integrada en cargas de trabajo de datos.
Desafíos
- complejidad. Las soluciones de macrodatos pueden ser extremadamente complejas, con numerosos componentes para controlar la ingesta de datos de varios orígenes de datos. Puede resultar difícil compilar, probar y solucionar problemas de procesos de macrodatos. Además, puede haber un gran número de opciones de configuración en varios sistemas que se deben usar para optimizar el rendimiento.
- conjunto de aptitudes. Muchas tecnologías de macrodatos son altamente especializadas y usan marcos y lenguajes que no son típicos de arquitecturas de aplicaciones más generales. Por otro lado, las tecnologías de macrodatos están evolucionando nuevas API que se basan en lenguajes más establecidos.
- madurez de la tecnología. Muchas de las tecnologías usadas en macrodatos evolucionan. Aunque las tecnologías básicas de Hadoop, como Hive y Spark, se han estabilizado, las tecnologías emergentes, como delta o incremental, presentan grandes cambios y mejoras. Los servicios administrados como Microsoft Fabric son relativamente jóvenes, en comparación con otros servicios de Azure, y probablemente evolucionarán con el tiempo.
- Security. Las soluciones de macrodatos suelen depender del almacenamiento de todos los datos estáticos en un lago de datos centralizado. La protección del acceso a estos datos puede ser difícil, especialmente cuando varias aplicaciones y plataformas deben ingerir y consumir los datos.
Procedimientos recomendados
Aprovechar el paralelismo. La mayoría de las tecnologías de procesamiento de macrodatos distribuyen la carga de trabajo entre varias unidades de procesamiento. Esto requiere que los archivos de datos estáticos se creen y almacenen en un formato splittable. Los sistemas de archivos distribuidos, como HDFS, pueden optimizar el rendimiento de lectura y escritura, y el procesamiento real lo realizan varios nodos de clúster en paralelo, lo que reduce los tiempos generales de trabajo. Se recomienda usar el formato de datos divididos, como Parquet.
Partición de datos. Normalmente, el procesamiento por lotes se produce en una programación periódica, por ejemplo, semanal o mensual. Particione archivos de datos y estructuras de datos como tablas, en función de períodos temporales que coincidan con la programación de procesamiento. Esto simplifica la ingesta de datos y la programación de trabajos y facilita la solución de errores. Además, las tablas de creación de particiones que se usan en consultas de Hive, Spark o SQL pueden mejorar significativamente el rendimiento de las consultas.
Aplicar semántica de esquema en lectura. El uso de un lago de datos le permite combinar el almacenamiento de archivos en varios formatos, ya sean estructurados, semiestructurados o no estructurados. Use semántica de esquema en lectura, que proyectan un esquema en los datos cuando los datos se procesan, no cuando se almacenan los datos. Esto crea flexibilidad en la solución y evita cuellos de botella durante la ingesta de datos causados por la validación de datos y la comprobación de tipos.
Procesar datos en contexto. Las soluciones de BI tradicionales suelen usar un proceso de extracción, transformación y carga (ETL) para mover datos a un almacenamiento de datos. Con datos de volúmenes mayores y una mayor variedad de formatos, las soluciones de macrodatos suelen usar variaciones de ETL, como transformar, extraer y cargar (TEL). Con este enfoque, los datos se procesan dentro del almacén de datos distribuidos, lo transforman en la estructura necesaria, antes de mover los datos transformados a un almacén de datos analíticos.
Equilibrar el uso y los costos de tiempo. Para los trabajos de procesamiento por lotes, es importante tener en cuenta dos factores: el costo por unidad de los nodos de proceso y el costo por minuto del uso de esos nodos para completar el trabajo. Por ejemplo, un trabajo por lotes puede tardar ocho horas con cuatro nodos de clúster. Sin embargo, podría resultar que el trabajo usa los cuatro nodos solo durante las dos primeras horas y, después de eso, solo se requieren dos nodos. En ese caso, la ejecución del trabajo completo en dos nodos aumentaría el tiempo total del trabajo, pero no lo duplicaría, por lo que el costo total sería menor. En algunos escenarios empresariales, un tiempo de procesamiento más largo puede ser preferible al mayor costo de usar recursos de clúster infrautilizados.
Separar recursos. Siempre que sea posible, intente separar los recursos en función de las cargas de trabajo para evitar escenarios como una carga de trabajo que use todos los recursos mientras el otro está esperando.
Orquestar la ingesta de datos. En algunos casos, las aplicaciones empresariales existentes pueden escribir archivos de datos para el procesamiento por lotes directamente en contenedores de blobs de Azure Storage, donde los servicios de nivel inferior pueden consumirlos como Microsoft Fabric. Sin embargo, a menudo tendrá que organizar la ingesta de datos de orígenes de datos locales o externos en el lago de datos. Use un flujo de trabajo o una canalización de orquestación, como los compatibles con Azure Data Factory o Microsoft Fabric, para lograr esto de forma predecible y manejable de forma centralizada.
Limpiar los datos confidenciales al principio. El flujo de trabajo de ingesta de datos debe limpiar los datos confidenciales al principio del proceso, para evitar almacenarlos en el lago de datos.
Arquitectura de IoT
Internet de las cosas (IoT) es un subconjunto especializado de soluciones de macrodatos. En el diagrama siguiente se muestra una posible arquitectura lógica para IoT. En el diagrama se resaltan los componentes de streaming de eventos de la arquitectura.
diagrama de 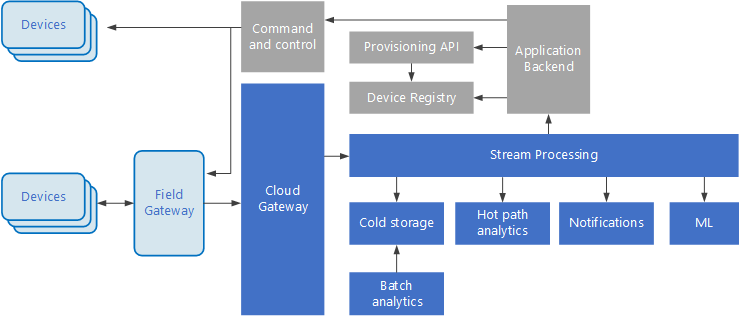
El puerta de enlace en la nube ingiere eventos de dispositivo en el límite de la nube mediante un sistema de mensajería confiable y de baja latencia.
Los dispositivos pueden enviar eventos directamente a la puerta de enlace en la nube o a través de una puerta de enlace de campo de . Una puerta de enlace de campo es un dispositivo o software especializado, normalmente colocado con los dispositivos, que recibe eventos y los reenvía a la puerta de enlace en la nube. La puerta de enlace de campo también puede preprocesar los eventos de dispositivo sin procesar, realizando funciones como el filtrado, la agregación o la transformación del protocolo.
Después de la ingesta, los eventos pasan por uno o varios procesadores de flujos que pueden enrutar los datos (por ejemplo, al almacenamiento) o realizar análisis y otro procesamiento.
A continuación se muestran algunos tipos comunes de procesamiento. (Esta lista no es ciertamente exhaustiva).
Escritura de datos de eventos en almacenamiento en frío para el archivado o el análisis por lotes.
Análisis de rutas de acceso activas, análisis de la secuencia de eventos en tiempo real (casi) para detectar anomalías, reconocer patrones en ventanas de tiempo gradual o desencadenar alertas cuando se produce una condición específica en la secuencia.
Controlar tipos especiales de mensajes que no son de telemetría desde dispositivos, como notificaciones y alarmas.
Aprendizaje automático.
Los cuadros que son grises sombreados muestran componentes de un sistema IoT que no están directamente relacionados con el streaming de eventos, pero se incluyen aquí para su integridad.
El registro de dispositivos es una base de datos de los dispositivos aprovisionados, incluidos los identificadores de dispositivo y normalmente los metadatos del dispositivo, como la ubicación.
La API de aprovisionamiento de es una interfaz externa común para aprovisionar y registrar nuevos dispositivos.
Algunas soluciones de IoT permiten mensajes de control y comandos enviarse a dispositivos.
En esta sección se ha presentado una vista muy general de IoT y hay muchas sutilezas y desafíos que se deben tener en cuenta. Para más información, consulte arquitecturas de IoT.
Pasos siguientes
- Obtenga más información sobre arquitecturas de macrodatos.
- Obtenga más información sobre arquitecturas de IoT.