Precaución
En este artículo se hace referencia a CentOS, una distribución de Linux que ha llegado a su final de ciclo vida (EOL). Tenga en cuenta su uso y planifique en consecuencia. Para más información, consulte la Guía de fin de ciclo de vida de CentOS.
En este escenario de ejemplo se muestra cómo ejecutar Apache NiFi en Azure. NiFi proporciona un sistema para procesar y distribuir datos.
Apache®, Apache NiFi® y NiFi® son marcas comerciales registradas o marcas comerciales de Apache Software Foundation en Estados Unidos u otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
Architecture

Descargue un archivo Visio de esta arquitectura.
Flujo de trabajo
La aplicación NiFi se ejecuta en VM en nodos de clúster NiFi. Las VM están en un conjunto de escalado de máquinas virtuales que la configuración implementa en las zonas de disponibilidad.
Apache ZooKeeper se ejecuta en las VM en un clúster independiente. NiFi usa el clúster de ZooKeeper para estos fines:
- Elegir un nodo de coordinación de clústeres
- Coordinar el flujo de datos
Azure Application Gateway proporciona equilibrio de carga de nivel 7 para la interfaz de usuario que se ejecuta en los nodos NiFi.
Monitor y su característica Log Analytics recopilan, analizan y actúan sobre la telemetría del sistema NiFi. La telemetría incluye registros del sistema NiFi, métricas de estado del sistema y métricas de rendimiento.
Azure Key Vault de forma segura los certificados y las claves para el clúster NiFi.
Microsoft Entra ID proporciona inicio de sesión único (SSO) y autenticación multifactor.
Componentes
- NiFi proporciona un sistema para procesar y distribuir datos.
- ZooKeeper es un servidor de código abierto que administra sistemas distribuidos.
- Las máquinas virtuales son una oferta de infraestructura como servicio (IaaS). Puede usar máquinas virtuales para implementar recursos informáticos escalables a petición. Las máquinas virtuales ofrecen la flexibilidad de la virtualización, pero eliminan las exigencias de mantenimiento del hardware físico.
- Azure Virtual Machine Scale Sets ofrece un método para administrar un grupo de VM con equilibrio de carga. El número de instancias de VM de un conjunto puede aumentar o disminuir automáticamente según la demanda, o de acuerdo a una programación definida.
- Las zonas de disponibilidad son ubicaciones físicas exclusivas dentro de una región de Azure. Estas ofertas de alta disponibilidad protegen las aplicaciones y los datos de los errores del centro de datos.
- Application Gateway es un equilibrador de carga que administra el tráfico a las aplicaciones web.
- Azure Monitor recopila y analiza los datos de entornos y recursos de Azure. Estos datos incluyen la telemetría de aplicaciones, como métricas de rendimiento y registros de actividad. Para obtener más información, vea Consideraciones de supervisión más adelante en este artículo.
- Log Analytics es una herramienta de Azure Portal que ejecuta consultas en los datos de registro de Monitor. Log Analytics también proporciona características para crear gráficos y analizar estadísticamente los resultados de las consultas.
- Azure DevOps Services proporciona servicios, herramientas y entornos para la administración de proyectos de programación e implementaciones.
- Azure Key Vault almacena y controla de forma segura el acceso a los secretos de un sistema, tales como claves de API, contraseñas, certificados y claves criptográficas.
- Microsoft Entra ID es un servicio de identidad basado en la nube que controla el acceso a Azure y a otras aplicaciones en la nube.
Alternativas
- Azure Data Factory proporciona una alternativa a esta solución.
- En lugar Key Vault, puede usar un servicio comparable para almacenar secretos del sistema.
- Apache Airflow. Para obtener más información, consulte En qué se diferencian Airflow y NiFi.
- Es posible usar una alternativa de NiFi empresarial compatible como Cloudera Apache NiFi. La oferta de Cloudera está disponible a través del Azure Marketplace.
Detalles del escenario
En este escenario, NiFi se ejecuta en una configuración en clúster en Azure Virtual Machines en un conjunto de escalado. No obstante, la mayoría de las recomendaciones de este artículo también se aplican a escenarios que ejecutan NiFi en modo de instancia única en una sola máquina virtual (VM). Los procedimientos recomendados de este artículo muestran una implementación segura y escalable de alta disponibilidad.
Posibles casos de uso
NiFi funciona bien para mover datos y administrar el flujo de datos:
- Conexión de sistemas desacoplados en la nube
- Movimiento de datos dentro y fuera de Azure Storage y otros almacenes de datos
- Integración de aplicaciones de nube híbrida y de borde a nube con Azure IoT, Azure Stack y Azure Kubernetes Service (AKS)
Como resultado, esta solución se aplica a muchas áreas:
Los almacenamientos de datos modernos (MDW) reúnen datos estructurados y no estructurados a escala. Recopilan y almacenan datos de varios orígenes, receptores y formatos. NiFi destaca en la ingesta de datos en MDW basados en Azure por los siguientes motivos:
- Hay más de 200 procesadores disponibles para leer, escribir y manipular datos.
- El sistema admite servicios de almacenamiento, como Azure Blob Storage, Azure Data Lake Storage, Azure Event Hubs, Azure Queue Storage, Azure Cosmos DB y Azure Synapse Analytics.
- Las sólidas funcionalidades de origen de datos permiten implementar soluciones compatibles. Para obtener información sobre cómo capturar orígenes de datos en la característica Log Analytics de Azure Monitor, consulte Consideraciones de informes más adelante en este artículo.
NiFi se puede ejecutar de forma independiente en dispositivos de superficie pequeña. En tales casos, NiFi permite procesar los datos perimetrales y moverlos a instancias o clústeres de NiFi más grandes en la nube. NiFi ayuda a filtrar, transformar y priorizar los datos perimetrales en movimiento, lo que garantiza flujos de datos confiables y eficaces.
Las soluciones de IoT industrial (IIoT) administran el flujo de datos desde el borde hasta el centro de datos. Ese flujo comienza con la adquisición de datos de equipos y sistemas de control industriales. A continuación, los datos se mueven a soluciones de administración de datos y MDW. NiFi ofrece funcionalidades que lo hacen adecuado para la adquisición y el movimiento de datos:
- Funcionalidad de procesamiento de datos perimetrales
- Compatibilidad con protocolos que usan las puertas de enlace y los dispositivos de IoT
- Integración con Event Hubs y servicios de almacenamiento
Las aplicaciones de IoT en las áreas de mantenimiento predictivo y administración de la cadena de suministro pueden usar esta funcionalidad.
Recomendaciones
Tenga en cuenta los siguientes puntos al utilizar esta solución:
Versiones recomendadas de NiFi
Al ejecutar esta solución en Azure, se recomienda usar la versión 1.13.2+ de NiFi. Puede ejecutar otras versiones, pero es posible que necesiten configuraciones diferentes de las de esta guía.
Para instalar NiFi en VM de Azure, es mejor descargar los archivos binarios de conveniencia desde la página de descargas de NiFi. También puede compilar los archivos binarios a partir del código fuente.
Versiones recomendadas de ZooKeeper
Para esta carga de trabajo de ejemplo, se recomienda usar las versiones 3.5.5 y posteriores o 3.6.x de ZooKeeper.
Puede instalar ZooKeeper en VM de Azure mediante archivos binarios de conveniencia oficiales o código fuente. Ambos están disponibles en la página de versiones de Apache ZooKeeper.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Para obtener información sobre cómo configurar NiFi, consulte la guía del administrador del sistema de Apache NiFi. Tenga en cuenta también estas consideraciones al implementar esta solución.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
- Use la calculadora de precios de Azure para calcular el costo de los recursos de esta arquitectura.
- Para obtener una estimación que incluya todos los servicios de esta arquitectura, excepto la solución de alertas personalizadas, consulte este perfil de costo de ejemplo.
Consideraciones sobre máquinas virtuales
En las secciones siguientes se proporciona un esquema detallado de cómo configurar las VM NiFi:
Tamaño de VM
En esta tabla se enumeran los tamaños de VM recomendados con los que empezar. Para la mayoría de los flujos de datos de uso general, Standard_D16s_v3 es la mejor opción. Pero cada flujo de datos de NiFi tiene requisitos diferentes. Pruebe el flujo y cambie el tamaño según sea necesario en función de los requisitos reales del flujo.
Considere la posibilidad de habilitar redes aceleradas en las VM para aumentar el rendimiento de la red. Para más información, consulte Redes para conjuntos de escalado de máquinas virtuales de Azure.
| Tamaño de VM | vCPU | Memoria en GB | Rendimiento máximo de disco de datos sin almacenar en caché en operaciones de E/S por segundo (IOPS) por MBps* | Número máximo de interfaces de red (NIC)/ancho de banda de red esperado (Mbps) |
|---|---|---|---|---|
| Standard_D8s_v3 | 8 | 32 | 12 800/192 | 4/4000 |
| Standard_D16s_v3** | 16 | 64 | 25 600/384 | 8/8000 |
| Standard_D32s_v3 | 32 | 128 | 51 200/768 | 8/16 000 |
| Standard_M16m | 16 | 437,5 | 10 000/250 | 8/4000 |
* Deshabilite el almacenamiento en caché de escritura del disco de datos para todos los discos de datos que use en nodos NiFi.
** Se recomienda esta SKU para la mayoría de los flujos de datos de uso general. Las SKU de VM de Azure con configuraciones de memoria y vCPU similares también deben ser adecuadas.
Sistema operativo (SO) de la VM
Se recomienda ejecutar NiFi en Azure en uno de los siguientes sistemas operativos invitados:
- Ubuntu 18.04 LTS o posterior
- CentOS 7.9
Para cumplir los requisitos específicos del flujo de datos, es importante ajustar varias opciones de configuración de nivel de sistema operativo, entre las que se incluyen:
- Máximo de procesos bifurcados.
- Máximo de identificadores de archivo.
- Hora de acceso,
atime.
Después de ajustar el sistema operativo a su caso de uso esperado, use Azure VM Image Builder para codificar la generación de esas imágenes ajustadas. Para obtener instrucciones específicas de NiFi, consulte los procedimientos recomendados de configuración en la guía del administrador del sistema de Apache NiFi.
Storage
Almacene los distintos repositorios de NiFi en discos de datos y no en el disco del sistema operativo por tres motivos principales:
- Los flujos suelen tener requisitos de alto rendimiento de disco que un solo disco no puede cumplir.
- Es mejor separar las operaciones de disco NiFi de las operaciones de disco del sistema operativo.
- Los repositorios no deben estar en almacenamiento temporal.
En las secciones siguientes se describen las directrices para configurar los discos de datos. Estas directrices son específicas de Azure. Para más información sobre la configuración de los repositorios, consulte el apartado sobre la administración de estado en la guía del administrador del sistema de Apache NiFi.
Tipo y tamaño del disco de datos
Tenga en cuenta estos factores al configurar los discos de datos para NiFi:
- Tipo de disco
- Tamaño del disco
- Número total de discos
Nota
Para obtener información actualizada sobre los tipos de disco, el tamaño y los precios, consulte Introducción a los discos administrados de Azure.
En la tabla siguiente se muestran los tipos de discos administrados que están disponibles actualmente en Azure. Puede usar NiFi con cualquiera de estos tipos de disco. No obstante, para los flujos de datos de alto rendimiento, se recomienda SSD prémium.
| Ultra Disk Storage (NVM Express (NVMe)) | SSD Premium | SSD estándar | HDD estándar | |
|---|---|---|---|---|
| Tipo de disco | SSD | SSD | SSD | HDD |
| Tamaño máximo del disco | 65 536 GB | 32 767 GB | 32 767 GB | 32 767 GB |
| Rendimiento máx. | 2000 MiB/s | 900 MiB/s | 750 MiB/s | 500 MiB/s |
| IOPS máx. | 160 000 | 20.000 | 6,000 | 2\.000 |
Use al menos tres discos de datos para aumentar el rendimiento del flujo de datos. Para obtener procedimientos recomendados para configurar los repositorios en los discos, consulte Configuración del repositorio más adelante en este artículo.
En la tabla siguiente se enumeran los números de tamaño y rendimiento pertinentes para cada tamaño y tipo de disco.
| HDD estándar S15 | HDD estándar S20 | HDD estándar S30 | SSD estándar S15 | SSD estándar S20 | SSD estándar S30 | SSD prémium P15 | SSD prémium P20 | SSD prémium P30 | |
|---|---|---|---|---|---|---|---|---|---|
| Tamaño del disco en GB | 256 | 512 | 1024 | 256 | 512 | 1024 | 256 | 512 | 1024 |
| IOPS por disco | Hasta 500 | Hasta 500 | Hasta 500 | Hasta 500 | Hasta 500 | Hasta 500 | 1 100 | 2,300 | 5\.000 |
| Rendimiento de disco. | Hasta 60 Mbps | Hasta 60 Mbps | Hasta 60 Mbps | Hasta 60 Mbps | Hasta 60 Mbps | Hasta 60 Mbps | 125 Mbps | 150 Mbps | 200 MBps |
Si el sistema alcanza los límites de la VM, es posible que agregar más discos no aumente el rendimiento:
- Los límites de IOPS y rendimiento dependen del tamaño del disco.
- El tamaño de VM que elige establece los límites de IOPS y rendimiento de la VM en todos los discos de datos.
Para ver los límites de rendimiento de disco de nivel de VM, consulte Tamaños de las máquinas virtuales Linux en Azure.
Almacenamiento en disco de VM
En las VM de Azure, la característica Almacenamiento en caché de host administra el almacenamiento en caché de escritura en disco. Para aumentar el rendimiento en los discos de datos que se usan para los repositorios, desactive el almacenamiento en caché de escritura en disco. Para ello, establezca Almacenamiento en caché de host en None.
Configuración del repositorio
Las directrices de procedimientos recomendados para NiFi son usar uno o varios discos independientes para cada uno de estos repositorios:
- Contenido
- FlowFile
- Proveniencia
Este enfoque requiere un mínimo de tres discos.
NiFi también admite el seccionamiento en el nivel de aplicación. Esta funcionalidad aumenta el tamaño o el rendimiento de los repositorios de datos.
El siguiente extracto es del archivo de configuración nifi.properties. Esta configuración particiona y secciona los repositorios en los discos administrados que están conectados a las VM:
nifi.provenance.repository.directory.stripe1=/mnt/disk1/ provenance_repository
nifi.provenance.repository.directory.stripe2=/mnt/disk2/ provenance_repository
nifi.provenance.repository.directory.stripe3=/mnt/disk3/ provenance_repository
nifi.content.repository.directory.stripe1=/mnt/disk4/ content_repository
nifi.content.repository.directory.stripe2=/mnt/disk5/ content_repository
nifi.content.repository.directory.stripe3=/mnt/disk6/ content_repository
nifi.flowfile.repository.directory=/mnt/disk7/ flowfile_repository
Para más información sobre el diseño de almacenamiento de alto rendimiento, consulte Azure Premium Storage: diseño de alto rendimiento.
Generación de informes
NiFi incluye una tarea de informes de proveniencia para la característica Log Analytics.
Puede usar esta tarea de informes para descargar eventos de proveniencia en un almacenamiento rentable y duradero a largo plazo. La característica Log Analytics proporciona una interfaz de consulta para ver y representar gráficamente eventos individuales. Para más información sobre estas consultas, vea Consultas de Log Analytics más adelante en este artículo.
También puede usar esta tarea con almacenamiento de proveniencia volátil en memoria. En muchos escenarios, puede lograr un aumento del rendimiento. No obstante, este enfoque es arriesgado si necesita conservar los datos de eventos. Asegúrese de que el almacenamiento volátil cumple los requisitos de durabilidad de los eventos de proveniencia. Para más información, consulte el apartado sobre el repositorio de proveniencia en la guía del administrador del sistema de Apache NiFi.
Antes de usar este proceso, cree un área de trabajo de análisis de registros en su suscripción de Azure. Es mejor configurar el área de trabajo en la misma región que la carga de trabajo.
Para configurar la tarea de informes de proveniencia:
- Abra la configuración del controlador en NiFi.
- Seleccione el menú de tareas de informes.
- Seleccione Create a new reporting task (Crear una nueva tarea de generación de informes).
- Seleccione Azure Log Analytics Reporting Task (Tarea de informes de Azure Log Analytics).
En la captura de pantalla siguiente se muestra el menú de propiedades de esta tarea de informes:
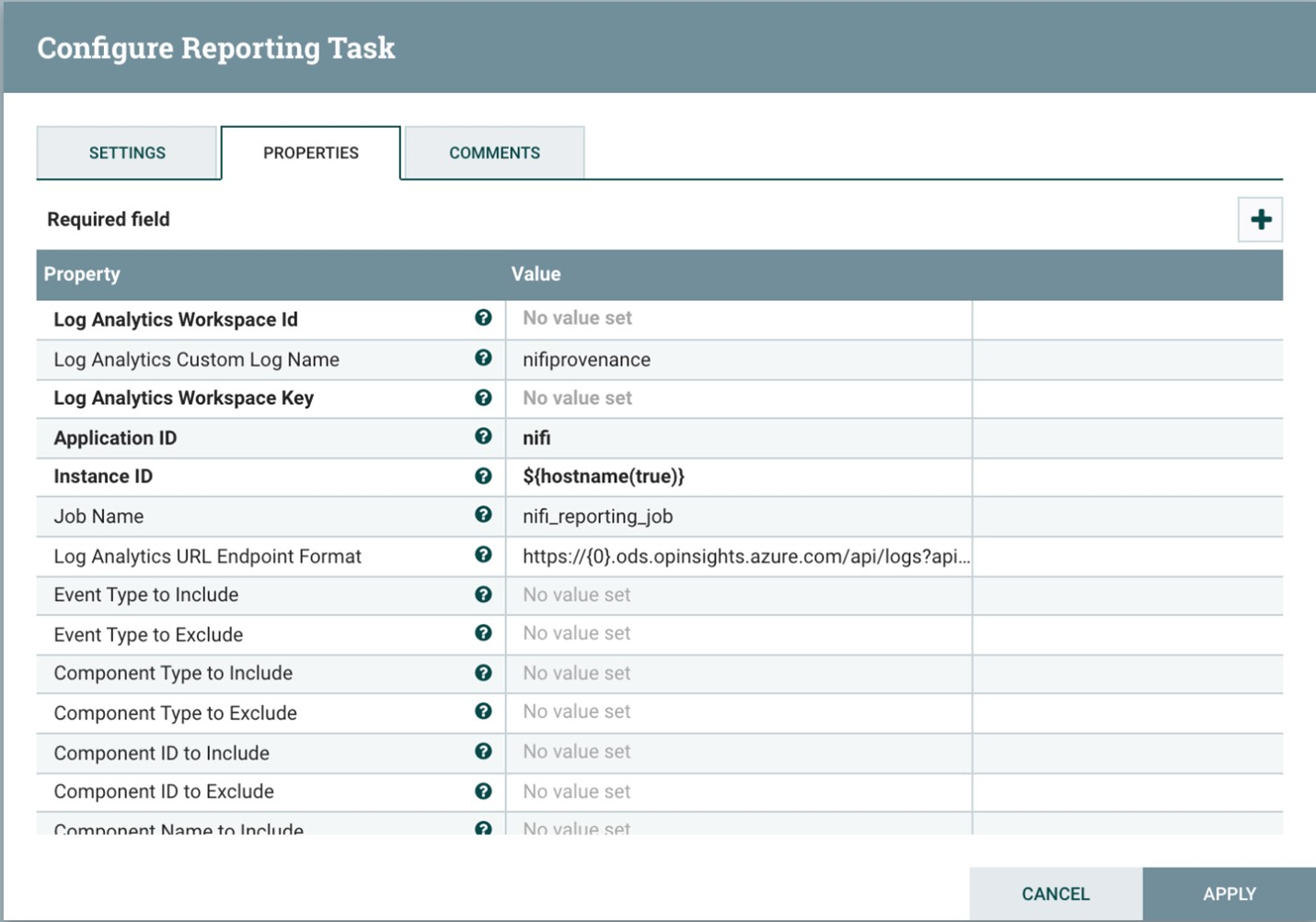
Se requieren las dos propiedades siguientes:
- Id. del área de trabajo de Log Analytics
- Clave del área de trabajo de Log Analytics
Puede encontrar estos valores en Azure Portal en el área de trabajo de Log Analytics.
También hay otras opciones disponibles para personalizar y filtrar los eventos de proveniencia que envía el sistema.
Seguridad
La seguridad proporciona garantías contra ataques deliberados y el abuso de datos y sistemas valiosos. Para más información, consulte Introducción al pilar de seguridad.
Puede proteger NiFi desde un punto de vista de autenticación y autorización. También puede proteger NiFi para todas las comunicaciones de red, que incluyen:
- Dentro del clúster.
- Entre el clúster y ZooKeeper.
Consulte la guía del administrador de Apache NiFi para obtener instrucciones sobre cómo activar las siguientes opciones:
- Kerberos
- Protocolo ligero de acceso a directorios (LDAP)
- Autenticación y autorización basadas en certificados
- Capa de sockets seguros (SSL) bidireccional para las comunicaciones de clúster
Si activa el acceso de cliente seguro de ZooKeeper, configure NiFi mediante la adición de propiedades relacionadas con el archivo de configuración bootstrap.conf. Las siguientes entradas de configuración proporcionan un ejemplo:
java.arg.18=-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty
java.arg.19=-Dzookeeper.client.secure=true
java.arg.20=-Dzookeeper.ssl.keyStore.location=/path/to/keystore.jks
java.arg.21=-Dzookeeper.ssl.keyStore.password=[KEYSTORE PASSWORD]
java.arg.22=-Dzookeeper.ssl.trustStore.location=/path/to/truststore.jks
java.arg.23=-Dzookeeper.ssl.trustStore.password=[TRUSTSTORE PASSWORD]
Para obtener recomendaciones generales, consulte la línea de base de seguridad de Linux.
Seguridad de las redes
Al implementar esta solución, tenga en cuenta los siguientes puntos sobre la seguridad de red:
Grupos de seguridad de red
En Azure, puede usar grupos de seguridad de red para restringir el tráfico de red.
Se recomienda un jumpbox para conectarse al clúster de NiFi para realizar tareas administrativas. Use esta VM con protección de seguridad con acceso Just-In-Time (JIT) o Azure Bastion. Configure grupos de seguridad de red para controlar cómo concede acceso al jumpbox o a Azure Bastion. Puede lograr el aislamiento y el control de red mediante el uso de grupos de seguridad de red de forma juiciosa en las distintas subredes de la arquitectura.
En la captura de pantalla siguiente se muestran los componentes de una red virtual típica. Contiene una subred común para el jumpbox, el conjunto de escalado de máquinas virtuales y las VM de ZooKeeper. Esta topología de red simplificada agrupa los componentes en una subred. Siga las directrices de su organización para la separación de tareas y el diseño de red.
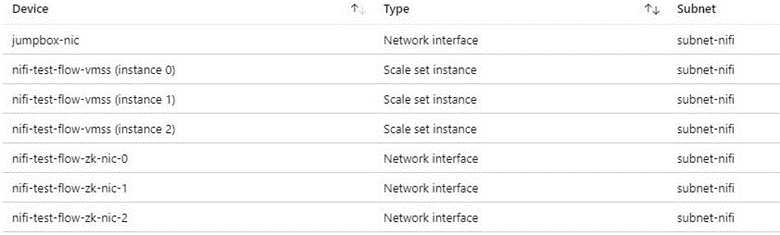
Consideración de acceso a Internet de salida
NiFi en Azure no necesita acceso a la red pública de Internet para ejecutarse. Si el flujo de datos no necesita acceso a Internet para recuperar datos, mejore la seguridad del clúster siguiendo estos pasos para deshabilitar el acceso a Internet de salida:
Cree una regla de grupo de seguridad de red adicional en la red virtual.
Use estos valores de configuración:
- Origen:
Any - Destino:
Internet - Acción:
Deny
- Origen:

Con esta regla implementada, todavía puede acceder a algunos servicios de Azure desde el flujo de datos si configura un punto de conexión privado en la red virtual. Use Azure Private Link para este propósito. Este servicio proporciona una manera de que el tráfico viaje por la red troncal de Microsoft sin necesidad de ningún otro acceso a la red externa. Actualmente, NiFi admite Private Link para los procesadores de Blob Storage y Data Lake Storage. Si un servidor de protocolo de hora de red (NTP) no está disponible en la red privada, permita el acceso a NTP de salida. Para obtener información detallada, consulte Sincronizar la hora en las máquinas virtuales de Linux en Azure.
Protección de datos
Es posible usar NiFi sin protección, cifrado de conexión, administración de identidad y acceso (IAM) ni cifrado de datos. No obstante, es mejor proteger las implementaciones de producción y de nube pública de estas maneras:
- Cifrado de la comunicación con Seguridad de la capa de transporte (TLS)
- Uso de un mecanismo de autenticación y autorización admitido
- Cifrado de datos en reposo
Azure Storage proporciona cifrado de datos transparente del lado servidor. No obstante, a partir de la versión 1.13.2, NiFi no configura el cifrado de conexión ni IAM de forma predeterminada. Este comportamiento puede cambiar en futuras versiones.
En las secciones siguientes se muestra cómo proteger las implementaciones de estas maneras:
- Habilitación del cifrado de conexión con TLS
- Configuración de la autenticación basada en certificados o Microsoft Entra ID
- Administración del almacenamiento cifrado en Azure
Cifrado de discos
Para mejorar la seguridad, use Azure Disk Encryption. Para obtener un procedimiento detallado, consulte Cifrado de discos de datos conectados y de sistema operativo en un conjunto de escalado de máquinas virtuales con la CLI de Azure. Ese documento también contiene instrucciones sobre cómo proporcionar su propia clave de cifrado. En los pasos siguientes se describe un ejemplo básico de NiFi que funciona en la mayoría de las implementaciones:
Para activar el cifrado de disco en una instancia de Key Vault existente, use el siguiente comando de la CLI de Azure:
az keyvault create --resource-group myResourceGroup --name myKeyVaultName --enabled-for-disk-encryptionActive el cifrado de los discos de datos del conjunto de escalado de máquinas virtuales con el siguiente comando:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet --disk-encryption-keyvault myKeyVaultID --volume-type DATAOpcionalmente, puede usar una clave de cifrado de claves (KEK). Use el comando de la CLI de Azure siguiente para el cifrado con una clave KEK:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet \ --disk-encryption-keyvault myKeyVaultID \ --key-encryption-keyvault myKeyVaultID \ --key-encryption-key https://<mykeyvaultname>.vault.azure.net/keys/myKey/<version> \ --volume-type DATA
Nota
Si configuró el conjunto de escalado de máquinas virtuales para el modo de actualización manual, ejecute el comando update-instances. Incluya la versión de la clave de cifrado que almacenó en Key Vault.
Cifrado en tránsito
NiFi admite TLS 1.2 para el cifrado en tránsito. Este protocolo ofrece protección para el acceso de los usuarios a la interfaz de usuario. Con los clústeres, el protocolo protege la comunicación entre los nodos NiFi. También puede proteger la comunicación con ZooKeeper. Al habilitar TLS, NiFi usa TLS mutuo (mTLS) para la autenticación mutua para:
- Autenticación de cliente basada en certificados si configuró este tipo de autenticación.
- Toda la comunicación entre clústeres.
Para habilitar TLS, siga estos pasos:
Cree un almacén de claves y un almacén de confianza para la comunicación y autenticación cliente-servidor y entre clústeres.
Configure
$NIFI_HOME/conf/nifi.properties. Establezca los valores siguientes:- Nombres de host
- Puertos
- Propiedades del almacén de claves
- Propiedades del almacén de confianza
- Propiedades de seguridad del clúster y de ZooKeeper, si procede
Configure la autenticación en
$NIFI_HOME/conf/authorizers.xml, normalmente con un usuario inicial que tenga autenticación basada en certificados u otra opción.Opcionalmente, configure mTLS y una directiva de lectura de proxy entre NiFi y cualquier servidor proxy, equilibrador de carga o punto de conexión externo.
Para obtener un tutorial completo, consulte Protección de NiFi con TLS en la documentación del proyecto de Apache.
Nota
A partir de la versión 1.13.2:
- NiFi no habilita TLS de forma predeterminada.
- No hay compatibilidad lista para usar para el acceso anónimo y de usuario único para las instancias de NiFi habilitadas para TLS.
Para habilitar TLS para el cifrado en tránsito, configure un grupo de usuarios y un proveedor de directivas para la autenticación y autorización en $NIFI_HOME/conf/authorizers.xml. Para obtener más información, consulte Control de identidades y acceso más adelante en este artículo.
Certificados, claves y almacenes de claves
Para admitir TLS, genere certificados, almacénelos en Java KeyStore y TrustStore, y distribúyalos a través de un clúster NiFi. Hay dos opciones generales para los certificados:
- Certificados autofirmados
- Certificados que firman las autoridades certificadas (CA)
Con los certificados firmados por la entidad de certificación, es mejor usar una entidad de certificación intermedia para generar certificados para los nodos del clúster.
KeyStore y TrustStore son los contenedores de claves y certificados de la plataforma Java. KeyStore almacena la clave privada y el certificado de un nodo en el clúster. TrustStore almacena uno de los siguientes tipos de certificados:
- Todos los certificados de confianza para certificados autofirmados en KeyStore
- Un certificado de una entidad de certificación para certificados firmados por la entidad de certificación en KeyStore
Tenga en cuenta la escalabilidad del clúster NiFi al elegir un contenedor. Por ejemplo, es posible que desee aumentar o disminuir el número de nodos de un clúster en el futuro. Elija certificados firmados por la entidad de certificación en KeyStore y uno o varios certificados de una CA en TrustStore en ese caso. Con esta opción, no es necesario actualizar el TrustStore existente en los nodos existentes del clúster. Un TrustStore existente confía en los certificados de estos tipos de nodos y los acepta:
- Nodos que se agregan al clúster
- Nodos que reemplazan a otros nodos del clúster
Configuración de NiFi
Para habilitar TLS para NiFi, use $NIFI_HOME/conf/nifi.properties para configurar las propiedades de esta tabla. Asegúrese de que las siguientes propiedades incluyen el nombre de host que usa para acceder a NiFi:
-
nifi.web.https.hostonifi.web.proxy.host - Nombre designado del certificado de host o nombres alternativos del firmante
De lo contrario, puede producirse un error de comprobación del nombre de host o un error de comprobación del encabezado HTTP HOST, lo que le denegará el acceso.
| Nombre de propiedad | Descripción | Valores de ejemplo |
|---|---|---|
nifi.web.https.host |
Nombre de host o dirección IP que se usará para la interfaz de usuario y la API de REST. Este valor debe poder resolverse internamente. Se recomienda no usar un nombre accesible públicamente. | nifi.internal.cloudapp.net |
nifi.web.https.port |
Puerto HTTPS que se usará para la interfaz de usuario y la API de REST. |
9443 (valor predeterminado) |
nifi.web.proxy.host |
Lista separada por comas de nombres de host alternativos que los clientes usan para acceder a la interfaz de usuario y la API de REST. Normalmente, esta lista incluye cualquier nombre de host que se especifique como nombre alternativo del firmante (SAN) en el certificado de servidor. La lista también puede incluir cualquier nombre de host y puerto que use un equilibrador de carga, un proxy o un controlador de entrada de Kubernetes. | 40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443 |
nifi.security.keystore |
Ruta de acceso a un almacén de claves JKS o PKCS12 que contiene la clave privada del certificado. | ./conf/keystore.jks |
nifi.security.keystoreType |
Tipo de almacén de claves. |
JKS o PKCS12 |
nifi.security.keystorePasswd |
Contraseña del almacén de claves. | O8SitLBYpCz7g/RpsqH+zM |
nifi.security.keyPasswd |
(Opcional) Contraseña de la clave privada. | |
nifi.security.truststore |
Ruta de acceso a un almacén de confianza JKS o PKCS12 que contiene certificados o certificados de entidad de certificación que autentican usuarios de confianza y nodos de clúster. | ./conf/truststore.jks |
nifi.security.truststoreType |
Tipo de almacén de confianza. |
JKS o PKCS12 |
nifi.security.truststorePasswd |
Contraseña del almacén de confianza. | RJlpGe6/TuN5fG+VnaEPi8 |
nifi.cluster.protocol.is.secure |
Estado de TLS para la comunicación entre clústeres. Si nifi.cluster.is.node es true, establezca este valor en true para habilitar TLS del clúster. |
true |
nifi.remote.input.secure |
Estado de TLS para la comunicación de sitio a sitio. | true |
En el ejemplo siguiente se muestra cómo aparecen estas propiedades en $NIFI_HOME/conf/nifi.properties. Tenga en cuenta que los valores nifi.web.http.host y nifi.web.http.port están en blanco.
nifi.remote.input.secure=true
nifi.web.http.host=
nifi.web.http.port=
nifi.web.https.host=nifi.internal.cloudapp.net
nifi.web.https.port=9443
nifi.web.proxy.host=40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443
nifi.security.keystore=./conf/keystore.jks
nifi.security.keystoreType=JKS
nifi.security.keystorePasswd=O8SitLBYpCz7g/RpsqH+zM
nifi.security.keyPasswd=
nifi.security.truststore=./conf/truststore.jks
nifi.security.truststoreType=JKS
nifi.security.truststorePasswd=RJlpGe6/TuN5fG+VnaEPi8
nifi.cluster.protocol.is.secure=true
Configuración de ZooKeeper
Para obtener instrucciones sobre cómo habilitar TLS en Apache ZooKeeper para las comunicaciones de cuórum y el acceso de cliente, consulte la guía del administrador de ZooKeeper. Solo las versiones 3.5.5 o posteriores admiten esta funcionalidad.
NiFi usa ZooKeeper para la agrupación en clústeres de líder cero y la coordinación de clústeres. A partir de la versión 1.13.0, NiFi admite el acceso de cliente seguro a las instancias habilitadas para TLS de ZooKeeper. ZooKeeper almacena la pertenencia al clúster y el estado del procesador con ámbito de clúster en texto sin formato. Por lo tanto, es importante usar el acceso de cliente seguro a ZooKeeper para autenticar las solicitudes de cliente de ZooKeeper. Cifre también los valores confidenciales en tránsito.
Para habilitar TLS para el acceso de cliente NiFi a ZooKeeper, establezca las siguientes propiedades en $NIFI_HOME/conf/nifi.properties. Si establece nifi.zookeeper.client.securetrue sin configurar las propiedades de nifi.zookeeper.security, NiFi recurrirá al almacén de claves y al de confianza que se especifique en nifi.securityproperties.
| Nombre de propiedad | Descripción | Valores de ejemplo |
|---|---|---|
nifi.zookeeper.client.secure |
Estado de TLS de cliente al conectarse a ZooKeeper. | true |
nifi.zookeeper.security.keystore |
Ruta de acceso a un almacén de claves JKS, PKCS12 o PEM que contiene la clave privada del certificado que se presenta a ZooKeeper para la autenticación. | ./conf/zookeeper.keystore.jks |
nifi.zookeeper.security.keystoreType |
Tipo de almacén de claves. |
JKS, PKCS12, PEM o detección automática por extensión |
nifi.zookeeper.security.keystorePasswd |
Contraseña del almacén de claves. | caB6ECKi03R/co+N+64lrz |
nifi.zookeeper.security.keyPasswd |
(Opcional) Contraseña de la clave privada. | |
nifi.zookeeper.security.truststore |
Ruta de acceso a un almacén de confianza JKS, PKCS12 o PEM que contiene certificados o certificados de entidad de certificación que se usan para la autenticación de ZooKeeper. | ./conf/zookeeper.truststore.jks |
nifi.zookeeper.security.truststoreType |
Tipo de almacén de confianza. |
JKS, PKCS12, PEM o detección automática por extensión |
nifi.zookeeper.security.truststorePasswd |
Contraseña del almacén de confianza. | qBdnLhsp+mKvV7wab/L4sv |
nifi.zookeeper.connect.string |
Cadena de conexión al host o cuórum de ZooKeeper. Esta cadena es una lista de valores host:port separados por comas. Normalmente, el valor secureClientPort no coincide con el valor clientPort. Consulte la configuración de ZooKeeper para obtener el valor correcto. |
zookeeper1.internal.cloudapp.net:2281, zookeeper2.internal.cloudapp.net:2281, zookeeper3.internal.cloudapp.net:2281 |
En el ejemplo siguiente se muestra cómo aparecen estas propiedades en $NIFI_HOME/conf/nifi.properties:
nifi.zookeeper.client.secure=true
nifi.zookeeper.security.keystore=./conf/keystore.jks
nifi.zookeeper.security.keystoreType=JKS
nifi.zookeeper.security.keystorePasswd=caB6ECKi03R/co+N+64lrz
nifi.zookeeper.security.keyPasswd=
nifi.zookeeper.security.truststore=./conf/truststore.jks
nifi.zookeeper.security.truststoreType=JKS
nifi.zookeeper.security.truststorePasswd=qBdnLhsp+mKvV7wab/L4sv
nifi.zookeeper.connect.string=zookeeper1.internal.cloudapp.net:2281,zookeeper2.internal.cloudapp.net:2281,zookeeper3.internal.cloudapp.net:2281
Para obtener más información sobre cómo proteger ZooKeeper con TLS, consulte la guía de administración de Apache NiFi.
Control de identidades y acceso
En NiFi, la identidad y el control de acceso se logran a través de la autenticación y autorización del usuario. Para la autenticación de usuario, NiFi tiene varias opciones entre las que elegir: Usuario único, LDAP, Kerberos, Lenguaje de marcado de aserción de seguridad (SAML) y OpenID Connect (OIDC). Si no configura una opción, NiFi usa certificados de cliente para autenticar a los usuarios a través de HTTPS.
Si se plantea la posibilidad de la autenticación multifactor, se recomienda la combinación de Microsoft Entra ID y OIDC. Microsoft Entra ID admite el inicio de sesión único (SSO) nativo en la nube con OIDC. Con esta combinación, los usuarios pueden aprovechar muchas características de seguridad empresarial:
- Registro y alertas sobre actividades sospechosas de cuentas de usuario
- Supervisión de los intentos de acceso a credenciales desactivadas
- Alertas sobre el comportamiento de inicio de sesión inusual de la cuenta
Para la autorización, NiFi proporciona una aplicación basada en directivas de usuario, grupo y acceso. NiFi proporciona esta aplicación a través de UserGroupProviders y AccessPolicyProviders. De forma predeterminada, los proveedores incluyen File, LDAP, Shell y UserGroupProviders basados Graph Azure. Con AzureGraphUserGroupProvider, puede obtener grupos de usuarios de Microsoft Entra ID. A continuación, puede asignar directivas a estos grupos. Para obtener instrucciones de configuración, consulte la guía de administración de Apache NiFi.
Los objetos AccessPolicyProviders que se basan en archivos y Apache Ranger están disponibles actualmente para administrar y almacenar directivas de usuario y grupo. Para obtener información detallada, consulte la documentación de Apache NiFi y la documentación de Apache Ranger.
puerta de enlace de aplicaciones
Una puerta de enlace de aplicaciones proporciona un equilibrador de carga administrado de nivel 7 para la interfaz de NiFi. Configure la puerta de enlace de aplicaciones para usar el conjunto de escalado de máquinas virtuales de los nodos NiFi como su grupo de back-end.
Para la mayoría de las instalaciones de NiFi, se recomienda la siguiente configuración de Application Gateway:
- Nivel: Estándar
- Tamaño de SKU: medio
- Recuento de instancias: dos o más
Use un sondeo de estado para supervisar el estado del servidor web en cada nodo. Quite los nodos incorrectos de la rotación del equilibrador de carga. Este enfoque facilita la visualización de la interfaz de usuario cuando el clúster general es incorrecto. El explorador solo le dirige a los nodos que están actualmente en buen estado y responden a las solicitudes.
Hay dos sondeos de estado clave que se deben tener en cuenta. Juntos proporcionan un latido regular sobre el estado general de cada nodo del clúster. Configure el primer sondeo de estado para que apunte a la ruta de acceso /NiFi. Este sondeo determina el estado de la interfaz de usuario de NiFi en cada nodo. Configure un segundo sondeo de estado para la ruta de acceso /nifi-api/controller/cluster. Este sondeo indica si cada nodo es correcto actualmente y está unido al clúster general.
Tiene dos opciones para configurar la dirección IP de front-end de la puerta de enlace de aplicaciones:
- Con una dirección IP pública
- Con una dirección IP de subred privada
Incluya solo una dirección IP pública si los usuarios necesitan acceder a la interfaz de usuario a través de la red pública de Internet. Si no se requiere acceso a la red pública de Internet para los usuarios, acceda al front-end del equilibrador de carga desde un jumpbox de la red virtual o mediante el emparejamiento a la red privada. Si configura la puerta de enlace de aplicaciones con una dirección IP pública, se recomienda habilitar la autenticación de certificados de cliente para NiFi y habilitar TLS para la interfaz de usuario de NiFi. También puede usar un grupo de seguridad de red en la subred de puerta de enlace de aplicaciones delegada para limitar las direcciones IP de origen.
Diagnósticos y supervisión de estado
En la configuración de diagnóstico de Application Gateway, hay una opción de configuración para enviar métricas y registros de acceso. Con esta opción, puede enviar esta información desde el equilibrador de carga a varios lugares:
- Una cuenta de almacenamiento
- Event Hubs
- Un área de trabajo de Log Analytics
Activar esta configuración es útil para depurar problemas de equilibrio de carga y para obtener información sobre el estado de los nodos del clúster.
La siguiente consulta de Log Analytics muestra el estado del nodo del clúster a lo largo del tiempo desde la perspectiva de Application Gateway. Puede usar una consulta similar para generar alertas o acciones de reparación automatizadas para nodos incorrectos.
AzureDiagnostics
| summarize UnHealthyNodes = max(unHealthyHostCount_d), HealthyNodes = max(healthyHostCount_d) by bin(TimeGenerated, 5m)
| render timechart
En el siguiente gráfico de los resultados de la consulta se muestra una vista de tiempo del estado del clúster:

Disponibilidad
Al implementar esta solución, tenga en cuenta los siguientes puntos sobre la disponibilidad:
Equilibrador de carga
Use un equilibrador de carga para la interfaz de usuario con el fin de aumentar la disponibilidad de la interfaz de usuario durante el tiempo de inactividad del nodo.
VM independientes
Para aumentar la disponibilidad, implemente el clúster de ZooKeeper en VM independientes de las VM del clúster de NiFi. Para más información sobre la configuración de ZooKeeper, consulte el apartado sobre la administración de estado en la guía del administrador del sistema de Apache NiFi.
Zonas de disponibilidad
Implemente el conjunto de escalado de máquinas virtuales de NiFi y el clúster de ZooKeeper en una configuración entre zonas para maximizar la disponibilidad. Cuando la comunicación entre los nodos del clúster cruza zonas de disponibilidad, introduce una pequeña cantidad de latencia. No obstante, esta latencia suele tener un efecto general mínimo en el rendimiento del clúster.
Conjuntos de escalado de máquinas virtuales
Se recomienda implementar los nodos NiFi en un único conjunto de escalado de máquinas virtuales que abarque las zonas de disponibilidad cuando estén disponibles. Para obtener información detallada sobre el uso de conjuntos de escalado de esta manera, consulte Crear un conjunto de escalado de máquinas virtuales que use zonas de disponibilidad.
Supervisión
Para supervisar el estado y el rendimiento de un clúster de NiFi, use tareas de informes.
Supervisión basada en tareas de informes
Para la supervisión, puede usar una tarea de informes que configure y ejecute en NiFi. Como se describe en Diagnósticos y supervisión de estado, Log Analytics proporciona una tarea de informes en el paquete de Azure NiFi. Puede usar esa tarea de informes para integrar la supervisión con Log Analytics y los sistemas de registro o supervisión existentes.
Consultas de Log Analytics
Las consultas de ejemplo de las secciones siguientes pueden ayudarle a empezar. Para obtener información general sobre cómo consultar datos de Log Analytics, consulte Consultas de registro de Azure Monitor.
Las consultas de registro de Monitor y Log Analytics usan una versión del lenguaje de consulta Kusto. No obstante, existen diferencias entre las consultas de registro y las consultas de Kusto. Para más información, vea la introducción a las consultas de Kusto.
Para obtener un aprendizaje más estructurado, consulte estos tutoriales:
- Introducción a las consultas de registro en Azure Monitor
- Introducción a los análisis de registros de Azure Monitor
Tarea de informes de Log Analytics
De forma predeterminada, NiFi envía datos de métricas a la tabla nifimetrics. No obstante, puede configurar un destino diferente en las propiedades de la tarea de informes. La tarea de informes captura las siguientes métricas de NiFi:
| Tipo de métrica | Nombre de métrica |
|---|---|
| Métricas NiFi | FlowFilesReceived |
| Métricas NiFi | FlowFilesSent |
| Métricas NiFi | FlowFilesQueued |
| Métricas NiFi | BytesReceived |
| Métricas NiFi | BytesWritten |
| Métricas NiFi | BytesRead |
| Métricas NiFi | BytesSent |
| Métricas NiFi | BytesQueued |
| Métricas de estado del puerto | InputCount |
| Métricas de estado del puerto | InputBytes |
| Métricas de estado de la conexión | QueuedCount |
| Métricas de estado de la conexión | QueuedBytes |
| Métricas de estado del puerto | OutputCount |
| Métricas de estado del puerto | OutputBytes |
| Métricas de la máquina virtual Java (JVM) | jvm.uptime |
| Métricas de JVM | jvm.heap_used |
| Métricas de JVM | jvm.heap_usage |
| Métricas de JVM | jvm.non_heap_usage |
| Métricas de JVM | jvm.thread_states.runnable |
| Métricas de JVM | jvm.thread_states.blocked |
| Métricas de JVM | jvm.thread_states.timed_waiting |
| Métricas de JVM | jvm.thread_states.terminated |
| Métricas de JVM | jvm.thread_count |
| Métricas de JVM | jvm.daemon_thread_count |
| Métricas de JVM | jvm.file_descriptor_usage |
| Métricas de JVM | jvm.gc.runs jvm.gc.runs.g1_old_generation jvm.gc.runs.g1_young_generation |
| Métricas de JVM | jvm.gc.time jvm.gc.time.g1_young_generation jvm.gc.time.g1_old_generation |
| Métricas de JVM | jvm.buff_pool_direct_capacity |
| Métricas de JVM | jvm.buff_pool_direct_count |
| Métricas de JVM | jvm.buff_pool_direct_mem_used |
| Métricas de JVM | jvm.buff_pool_mapped_capacity |
| Métricas de JVM | jvm.buff_pool_mapped_count |
| Métricas de JVM | jvm.buff_pool_mapped_mem_used |
| Métricas de JVM | jvm.mem_pool_code_cache |
| Métricas de JVM | jvm.mem_pool_compressed_class_space |
| Métricas de JVM | jvm.mem_pool_g1_eden_space |
| Métricas de JVM | jvm.mem_pool_g1_old_gen |
| Métricas de JVM | jvm.mem_pool_g1_survivor_space |
| Métricas de JVM | jvm.mem_pool_metaspace |
| Métricas de JVM | jvm.thread_states.new |
| Métricas de JVM | jvm.thread_states.waiting |
| Métricas de nivel de procesador | BytesRead |
| Métricas de nivel de procesador | BytesWritten |
| Métricas de nivel de procesador | FlowFilesReceived |
| Métricas de nivel de procesador | FlowFilesSent |
Esta es una consulta de ejemplo para la métrica BytesQueued de un clúster:
let table_name = nifimetrics_CL;
let metric = "BytesQueued";
table_name
| where Name_s == metric
| where Computer contains {ComputerName}
| project TimeGenerated, Computer, ProcessGroupName_s, Count_d, Name_s
| summarize sum(Count_d) by bin(TimeGenerated, 1m), Computer, Name_s
| render timechart
Esa consulta genera un gráfico como el de esta captura de pantalla:

Nota
Al ejecutar NiFi en Azure, no se limita a la tarea de informes de Log Analytics. NiFi admite tareas de informes para muchas tecnologías de supervisión de terceros. Para obtener una lista de las tareas de informes admitidas, consulte la sección sobre tareas de informes del índice de documentación de Apache NiFi.
Supervisión de la infraestructura de NiFi
Además de la tarea de informes, instale la extensión de VM de Log Analytics en los nodos de NiFi y ZooKeeper. Esta extensión recopila registros, métricas de nivel de VM adicionales y métricas de ZooKeeper.
Registros personalizados para la aplicación NiFi, el usuario, el arranque y ZooKeeper
Para capturar más registros, siga estos pasos:
En Azure Portal, vaya a Áreas de trabajo de Log Analytics y seleccione su área de trabajo.
En Configuración, seleccione Registros personalizados.
Seleccione Agregar registro personalizado.
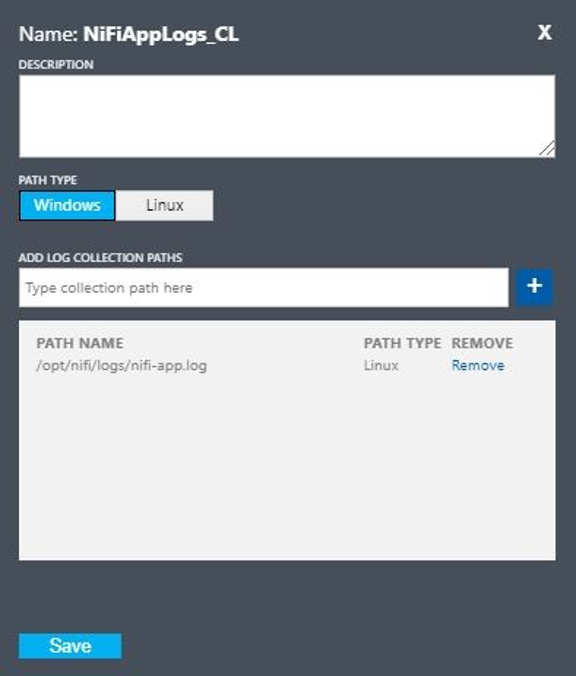
Configure un registro personalizado con estos valores:
- Nombre:
NiFiAppLogs - Tipo de ruta de acceso:
Linux - Nombre de la ruta de acceso:
/opt/nifi/logs/nifi-app.log
- Nombre:
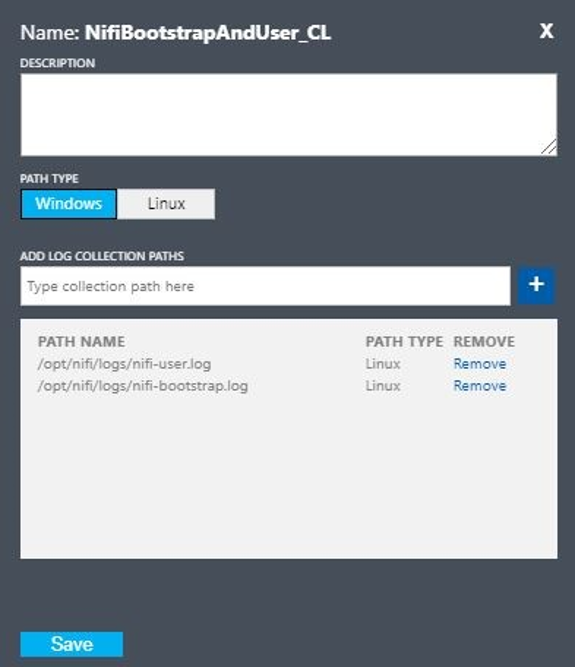
Configure un registro personalizado con estos valores:
- Nombre:
NiFiBootstrapAndUser - Tipo de la primera ruta de acceso:
Linux - Nombre de la primera ruta de acceso:
/opt/nifi/logs/nifi-user.log - Tipo de la segunda ruta de acceso:
Linux - Nombre de la segunda ruta de acceso:
/opt/nifi/logs/nifi-bootstrap.log
- Nombre:
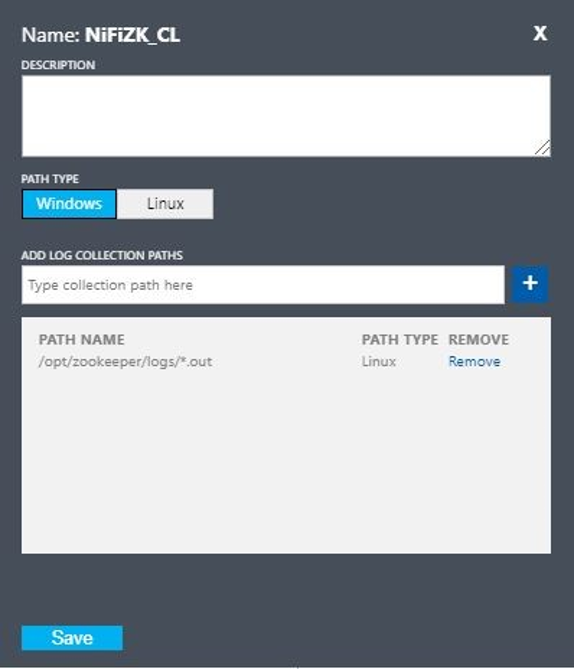
Configure un registro personalizado con estos valores:
- Nombre:
NiFiZK - Tipo de ruta de acceso:
Linux - Nombre de la ruta de acceso:
/opt/zookeeper/logs/*.out
- Nombre:
Esta es una consulta de ejemplo de la tabla personalizada NiFiAppLogs que creó el primer ejemplo:
NiFiAppLogs_CL
| where TimeGenerated > ago(24h)
| where Computer contains {ComputerName} and RawData contains "error"
| limit 10
Esa consulta genera resultados similares a los siguientes:

Configuración del registro de infraestructura
Puede usar Monitor para supervisar y administrar VM o equipos físicos. Estos recursos pueden estar en el centro de datos local u otro entorno en la nube. Para configurar esta supervisión, implemente el agente de Log Analytics. Configure el agente para que informe a un área de trabajo de Log Analytics. Para obtener más información, consulte Introducción al agente de Log Analytics.
En la captura de pantalla siguiente se muestra una configuración de agente de ejemplo para las VM NiFi. En la tabla Perf se almacenan los datos recopilados.

Esta es una consulta de ejemplo para los registros de Perf de la aplicación NiFi:
let cluster_name = {ComputerName};
// The hourly average of CPU usage across all computers.
Perf
| where Computer contains {ComputerName}
| where CounterName == "% Processor Time" and InstanceName == "_Total"
| where ObjectName == "Processor"
| summarize CPU_Time_Avg = avg(CounterValue) by bin(TimeGenerated, 30m), Computer
Esa consulta genera un informe como el de esta captura de pantalla:

Alertas
Use Monitor para crear alertas sobre el estado y el rendimiento del clúster NiFi. Las alertas de ejemplo incluyen:
- El recuento total de colas ha superado un umbral.
- El valor
BytesWrittenestá por debajo de un umbral esperado. - El valor
FlowFilesReceivedestá por debajo del umbral. - El clúster está en mal estado.
Para más información sobre la configuración de alertas en Monitor, consulte Información general sobre las alertas en Microsoft Azure.
Parámetros de configuración
En las secciones siguientes se analizan las configuraciones recomendadas y no predeterminadas para NiFi y sus dependencias, incluidos ZooKeeper y Java. Esta configuración es adecuada para los tamaños de clúster que son posibles en la nube. Establezca las propiedades en los siguientes archivos de configuración:
$NIFI_HOME/conf/nifi.properties$NIFI_HOME/conf/bootstrap.conf$ZOOKEEPER_HOME/conf/zoo.cfg$ZOOKEEPER_HOME/bin/zkEnv.sh
Para obtener información detallada sobre los archivos y las propiedades de configuración disponibles, consulte la guía del administrador del sistema de Apache NiFi y la guía del administrador de ZooKeeper.
NiFi
Para una implementación de Azure, considere la posibilidad de ajustar las propiedades en $NIFI_HOME/conf/nifi.properties. En la tabla siguiente se enumeran las propiedades más importantes. Para obtener más recomendaciones e información, consulte las listas de distribución de correo de Apache NiFi.
| Parámetro | Descripción | Default | Recomendación |
|---|---|---|---|
nifi.cluster.node.connection.timeout |
Cuánto tiempo se debe esperar al abrir una conexión a otros nodos del clúster. | 5 segundos | 60 segundos |
nifi.cluster.node.read.timeout |
Cuánto tiempo se debe esperar una respuesta al realizar una solicitud a otros nodos del clúster. | 5 segundos | 60 segundos |
nifi.cluster.protocol.heartbeat.interval |
Frecuencia con la que se deben enviar latidos al coordinador del clúster. | 5 segundos | 60 segundos |
nifi.cluster.node.max.concurrent.requests |
Qué nivel de paralelismo se debe usar al replicar llamadas HTTP como llamadas API de REST a otros nodos del clúster. | 100 | 500 |
nifi.cluster.node.protocol.threads |
Tamaño inicial del grupo de subprocesos para comunicaciones entre clústeres y replicadas. | 10 | 50 |
nifi.cluster.node.protocol.max.threads |
Número máximo de subprocesos que se usarán para las comunicaciones entre clústeres o replicadas. | 50 | 75 |
nifi.cluster.flow.election.max.candidates |
Número de nodos que se usarán al decidir cuál es el flujo actual. Este valor interrumpe el voto en el número especificado. | empty | 75 |
nifi.cluster.flow.election.max.wait.time |
Cuánto tiempo se debe esperar en los nodos antes de decidir cuál es el flujo actual. | 5 minutos | 5 minutos |
Comportamiento del clúster
Al configurar clústeres, tenga en cuenta los siguientes puntos.
Tiempo de espera
Para garantizar el estado general de un clúster y sus nodos, puede ser beneficioso aumentar los tiempos de espera. Esta práctica ayuda a garantizar que no se produzcan errores como resultado de problemas transitorios de red o cargas elevadas.
En un sistema distribuido, el rendimiento de los sistemas individuales varía. Esta variación incluye las comunicaciones de red y la latencia, lo que normalmente afecta a la comunicación entre nodos y entre clústeres. La infraestructura de red o el propio sistema pueden provocar esta variación. Como resultado, la probabilidad de variación es muy alta en grandes clústeres de sistemas. En las aplicaciones Java sometidas a carga, las pausas en la recolección de elementos no utilizados (GC) en la máquina virtual Java (JVM) también pueden afectar a los tiempos de respuesta de las solicitudes.
Use las propiedades de las secciones siguientes para configurar tiempos de espera que se adapten a las necesidades del sistema:
nifi.cluster.node.connection.timeout y nifi.cluster.node.read.timeout
La propiedad nifi.cluster.node.connection.timeout especifica cuánto tiempo se debe esperar al abrir una conexión. La propiedad nifi.cluster.node.read.timeout especifica cuánto tiempo se debe esperar al recibir datos entre solicitudes. El valor predeterminado de cada propiedad es de cinco segundos. Estas propiedades se aplican a las solicitudes de nodo a nodo. Aumentar estos valores ayuda a mitigar varios problemas relacionados:
- El coordinador del clúster realiza la desconexión debido a interrupciones de latido.
- Error al obtener el flujo del coordinador al unirse al clúster.
- Establecimiento de comunicaciones de sitio a sitio (S2S) y equilibrio de carga.
A menos que el clúster tenga un conjunto de escalado muy pequeño, como tres nodos o menos, use valores mayores que los predeterminados.
nifi.cluster.protocol.heartbeat.interval
Como parte de la estrategia de agrupación en clústeres NiFi, cada nodo emite un latido para comunicar su estado correcto. De forma predeterminada, los nodos envían latidos cada cinco segundos. Si el coordinador del clúster detecta un error en ocho latidos seguidos de un nodo, desconecta el nodo. Aumente el intervalo establecido en la propiedad nifi.cluster.protocol.heartbeat.interval para ayudar a admitir los latidos lentos e impedir que el clúster desconecte nodos innecesariamente.
Simultaneidad
Use las propiedades de las secciones siguientes para configurar la simultaneidad:
nifi.cluster.node.protocol.threads y nifi.cluster.node.protocol.max.threads
La propiedad nifi.cluster.node.protocol.max.threads especifica el número máximo de subprocesos que se usarán para las comunicaciones de todos los clústeres, como el equilibrio de carga S2S y la agregación de la interfaz de usuario. El valor predeterminado de esta propiedad es de 50 subprocesos. En el caso de clústeres grandes, aumente este valor para tener en cuenta el mayor número de solicitudes que requieren estas operaciones.
La propiedad nifi.cluster.node.protocol.threads determina el tamaño inicial del grupo de subprocesos. El valor predeterminado es de 10 subprocesos. Este valor es un mínimo. Crece según sea necesario hasta el máximo establecido en nifi.cluster.node.protocol.max.threads. Aumente el valor de nifi.cluster.node.protocol.threads para los clústeres que usan un conjunto de escalado grande en el inicio.
nifi.cluster.node.max.concurrent.requests
Muchas solicitudes HTTP, como las llamadas API de REST y las llamadas de interfaz de usuario, deben replicarse en otros nodos del clúster. A medida que aumenta el tamaño del clúster, se replica un número creciente de solicitudes. La propiedad nifi.cluster.node.max.concurrent.requests limita el número de solicitudes pendientes. Su valor debe superar el tamaño esperado del clúster. El valor predeterminado es de 100 solicitudes simultáneas. A menos que ejecute un clúster pequeño de tres o menos nodos, aumente este valor para evitar las solicitudes con errores.
Elección del flujo
Use las propiedades de las secciones siguientes para configurar las opciones de elección de flujo:
nifi.cluster.flow.election.max.candidates
NiFi usa la agrupación en clústeres de líder cero, lo que significa que no hay un nodo autoritativo específico. Como resultado, los nodos votan qué definición de flujo se considera la correcta. También votan para decidir qué nodos se unen al clúster.
De forma predeterminada, la propiedad nifi.cluster.flow.election.max.candidates es el tiempo de espera máximo que especifica la propiedad nifi.cluster.flow.election.max.wait.time. Si este valor es demasiado alto, el inicio puede ser lento. El valor predeterminado de nifi.cluster.flow.election.max.wait.time es de cinco minutos. Establezca el número máximo de candidatos en un valor no vacío igual o mayor que 1 para asegurarse de que la espera no sea superior a la necesaria. Si establece esta propiedad, asígnele un valor que corresponda al tamaño del clúster o a una fracción de la mayoría del tamaño esperado del clúster. Para clústeres pequeños y estáticos de 10 nodos o menos, establezca este valor en el número de nodos del clúster.
nifi.cluster.flow.election.max.wait.time
En un entorno de nube elástica, el tiempo para aprovisionar hosts afecta al tiempo de inicio de la aplicación. La propiedad nifi.cluster.flow.election.max.wait.time determina cuánto tiempo espera NiFi antes de decidirse por un flujo. Haga que este valor sea proporcional al tiempo de inicio general del clúster en su tamaño inicial. En las pruebas iniciales, cinco minutos son más que suficiente en todas las regiones de Azure con los tipos de instancia recomendados. No obstante, puede aumentar este valor si el tiempo para aprovisionar suele superar el valor predeterminado.
Java
Se recomienda usar una versión LTS de Java. De estas versiones, Java 11 es preferible a Java 8, porque Java 11 admite una implementación de recolección de elementos no utilizados más rápida. Sin embargo, es posible tener una implementación de NiFi de alto rendimiento con cualquiera de las versiones.
En las secciones siguientes se explican las configuraciones comunes de JVM que se usan al ejecutar NiFi. Establezca los parámetros de JVM del archivo de configuración de arranque en $NIFI_HOME/conf/bootstrap.conf.
Recolector de elementos no utilizados
Si ejecuta Java 11, se recomienda usar el recolector de elementos no utilizados G1 (G1GC) en la mayoría de las situaciones. G1GC ha mejorado el rendimiento con respecto a ParallelGC, porque G1GC reduce la duración de las pausas de GC. G1GC es el valor predeterminado en Java 11, pero puede establecer el siguiente valor en bootstrap.conf para configurarlo explícitamente:
java.arg.13=-XX:+UseG1GC
Si ejecuta Java 8, no use G1GC. Use ParallelGC en su lugar. Hay deficiencias en la implementación de Java 8 de G1GC que impiden su uso con las implementaciones de repositorio recomendadas. ParallelGC es más lento que G1GC. No obstante, con ParallelGC todavía puede tener una implementación NiFi de alto rendimiento con Java 8.
Montón
Un conjunto de propiedades del archivo bootstrap.conf determina la configuración del montón JVM de NiFi. Para un flujo estándar, configure un montón de 32 GB mediante estas opciones:
java.arg.3=-Xmx32g
java.arg.2=-Xms32g
Para elegir el tamaño óptimo del montón que se va a aplicar al proceso de JVM, tenga en cuenta dos factores:
- Características del flujo de datos
- La forma en que NiFi usa memoria en su procesamiento
Para ver documentación detallada, consulte el artículo sobre Apache NiFi en profundidad.
Haga que el montón sea tan grande como sea necesario para cumplir los requisitos de procesamiento. Este enfoque minimiza la longitud de las pausas de GC. Para ver consideraciones generales sobre la recolección de elementos no utilizados de Java, consulte la guía de optimización de la recolección de elementos no utilizados para su versión de Java.
Al ajustar la configuración de memoria de JVM, tenga en cuenta estos factores importantes:
Número de FlowFiles, o registros de datos de NiFi, que están activos en un período determinado. Este número incluye FlowFiles con presión retroactiva o en cola.
Número de atributos definidos en FlowFiles.
Cantidad de memoria que un procesador necesita para procesar un fragmento de contenido determinado.
La forma en que un procesador procesa los datos:
- Streaming de datos
- Uso de procesadores orientados a registros
- Retención de todos los datos en memoria a la vez
Estos detalles son importantes. Durante el procesamiento, NiFi retiene las referencias y los atributos de cada FlowFile en la memoria. Con un rendimiento máximo, la cantidad de memoria que usa el sistema es proporcional al número de FlowFiles activos y a todos los atributos que contienen. Este número incluye los FlowFiles en cola. NiFi puede intercambiar al disco. No obstante, evite esta opción porque perjudica al rendimiento.
Tenga en cuenta también el uso de la memoria de objetos básica. En concreto, haga que el montón sea lo suficientemente grande como para retener objetos en memoria. Tenga en cuenta estas sugerencias para configurar las opciones de memoria:
- Ejecute el flujo con datos representativos y una contrapresión mínima. Para ello, primero configure
-Xmx4Gy, a continuación, aumente la memoria de forma conservadora según sea necesario. - Ejecute el flujo con datos representativos y una contrapresión máxima. Para ello, primero configure
-Xmx4Gy, a continuación, aumente el tamaño del clúster de forma conservadora según sea necesario. - Para perfilar la aplicación mientras se ejecuta el flujo, use herramientas como VisualVM y YourKit.
- Si los aumentos conservadores del montón no mejoran significativamente el rendimiento, considere la posibilidad de rediseñar flujos, procesadores y otros aspectos del sistema.
Parámetros adicionales de JVM
En la siguiente tabla se enumeran opciones de JVM adicionales. También se proporcionan los valores que funcionaron mejor en las pruebas iniciales. En las pruebas se observaron el uso de memoria y la actividad de GC, y se usó una generación de perfiles cuidadosa.
| Parámetro | Descripción | Predeterminado de JVM | Recomendación |
|---|---|---|---|
InitiatingHeapOccupancyPercent |
Cantidad de montón que está en uso antes de que se desencadene un ciclo de marcado. | 45 | 35 |
ParallelGCThreads |
Número de subprocesos que usa GC. Este valor es limitado para restringir el efecto general en el sistema. | 5/8 del número de vCPU | 8 |
ConcGCThreads |
Número de subprocesos de GC que se ejecutarán en paralelo. Este valor aumenta para tener en cuenta los valores de ParallelGCThreads limitados. | 1/4 del valor de ParallelGCThreads |
4 |
G1ReservePercent |
Porcentaje de memoria de reserva que se debe mantener libre. Este valor aumenta para evitar el agotamiento del espacio, lo que ayuda a evitar la recolección de elementos no utilizados completa. | 10 | 20 |
UseStringDeduplication |
Si se intentan identificar y desduplicar referencias a cadenas idénticas. Activar esta característica puede ayudar a ahorrar memoria. | - | present |
Para configurar estos valores, agregue las siguientes entradas a NiFi bootstrap.conf:
java.arg.17=-XX:+UseStringDeduplication
java.arg.18=-XX:G1ReservePercent=20
java.arg.19=-XX:ParallelGCThreads=8
java.arg.20=-XX:ConcGCThreads=4
java.arg.21=-XX:InitiatingHeapOccupancyPercent=35
ZooKeeper
Para mejorar la tolerancia a errores, ejecute ZooKeeper como un clúster. Tome este enfoque aunque la mayoría de las implementaciones de NiFi coloquen una carga relativamente moderada en ZooKeeper. Active la agrupación en clústeres para ZooKeeper explícitamente. De forma predeterminada, ZooKeeper se ejecuta en modo de servidor único. Para obtener información detallada, consulte el tema sobre la configuración en clústeres (varios servidores) en la guía del administrador de ZooKeeper.
Excepto para la configuración de agrupación en clústeres, use los valores predeterminados para la configuración de ZooKeeper.
Si tiene un clúster NiFi grande, es posible que tenga que usar un mayor número de servidores de ZooKeeper. En el caso de los tamaños de clúster más pequeños, los tamaños más pequeños de VM y discos administrados SSD estándar son suficientes.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Muazma Zahid | Project Manager principal
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
El material y las recomendaciones de este documento se obtuvieron de varias fuentes:
- Experimentación
- Procedimientos recomendados de Azure
- Conocimientos, procedimientos recomendados y documentación de la comunidad de NiFi
Para obtener más información, consulte los siguientes recursos:
- Guía del administrador del sistema de Apache NiFi
- Listas de correo de Apache NiFi
- Procedimientos recomendados de Cloudera para configurar una instalación NiFi de alto rendimiento
- Azure Premium Storage: diseño de alto rendimiento
- Solución de problemas de rendimiento de máquinas virtuales de Azure en Linux o Windows