El TDSP es una metodología de ciencia de datos ágil e iterativa que puede usar para proporcionar soluciones de análisis predictivo y aplicaciones de IA de manera eficiente. El TDSP mejora la colaboración en equipo y el aprendizaje al recomendar formas óptimas de que los roles de equipo funcionen juntos. El TDSP incorpora los procedimientos recomendados y los marcos de Microsoft y otros líderes del sector para ayudar a su equipo a implementar eficazmente iniciativas de ciencia de datos. El TDSP le permite obtener las ventajas de su programa de análisis.
En este artículo se proporciona una introducción al TDSP y sus componentes principales. Se presentan instrucciones sobre cómo implementar el TDSP mediante herramientas e infraestructura de Microsoft. Puede encontrar recursos más detallados en todo el artículo.
Principales componentes del TDSP
El TDSP tiene los siguientes componentes principales:
- Una definición del ciclo de vida de ciencia de datos
- Estructura de proyecto estandarizada
- Infraestructura y recursos idóneos para proyectos de ciencia de datos
- IA responsable: y un compromiso con el avance de la IA, impulsado por principios éticos
Ciclo de vida de ciencia de datos
El TDSP proporciona un ciclo de vida que puede usar para estructurar el desarrollo de sus proyectos de ciencia de datos. En el ciclo de vida se describen todos los pasos que siguen los proyectos correctos.
Puede combinar el TDSP basado en tareas con otros ciclos de vida de la ciencia de datos, como el proceso estándar intersectorial para la minería de datos (CRISP-DM), el proceso de descubrimiento de conocimientos en bases de datos (KDD) u otro proceso personalizado. En un nivel alto, estas distintas metodologías tienen mucho en común.
Use este ciclo de vida si tiene un proyecto de ciencia de datos que forma parte de una aplicación inteligente. Las aplicaciones inteligentes implementan modelos de Machine Learning o IA para realizar un análisis predictivo. También puede usar este proceso para proyectos de ciencia de datos exploratorios y proyectos de análisis improvisados.
El ciclo de vida de TDSP se compone de cinco fases principales que el equipo ejecuta de forma iterativa. Estas fases incluyen:
- Conocimiento del negocio
- Adquisición y comprensión de los datos
- Modelado
- Implementación
- Aceptación del cliente
Esta es una representación visual del ciclo de vida de TDSP:
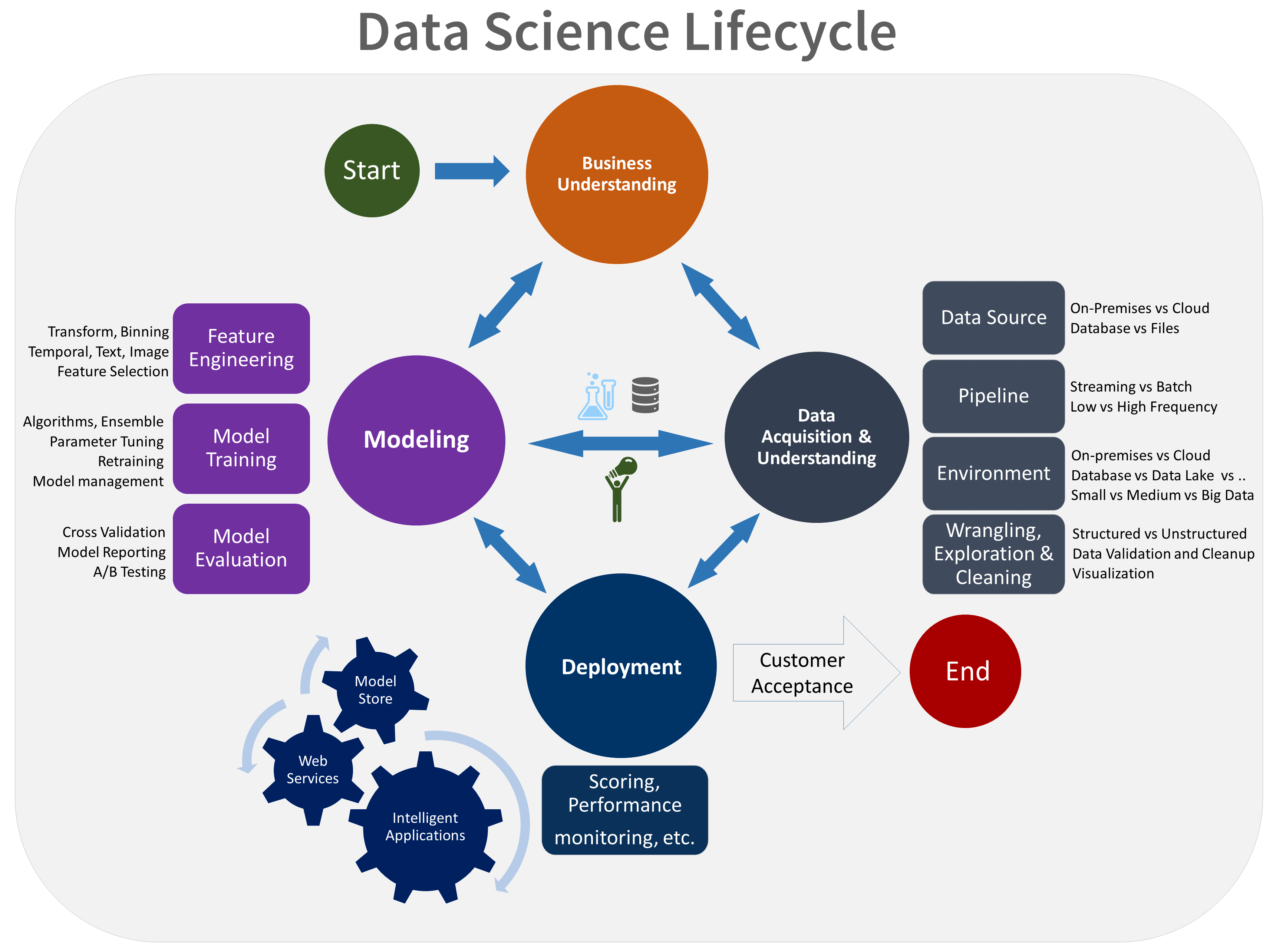
Para obtener más información sobre los objetivos, las tareas y los artefactos de documentación de cada fase, consulte El ciclo de vida del TDSP.
Estas tareas y artefactos se alinean con roles de proyecto, por ejemplo:
- Arquitecto de soluciones
- Jefe de proyecto
- Ingeniero de datos
- Científico de datos
- Desarrollador de aplicaciones
- Responsable de proyecto
En el siguiente diagrama se muestran las tareas (en azul) y los artefactos (en verde) correspondientes a cada fase del ciclo de vida que se muestra en el eje horizontal) y para los roles que se muestran en el eje vertical.

Estructura de proyecto estandarizada
El equipo puede usar la infraestructura de Azure para organizar los recursos de ciencia de datos.
Azure Machine Learning admite MLflow de código abierto. Se recomienda usar MLflow para la administración de proyectos de ciencia de datos e IA. MLflow está diseñado para administrar el ciclo de vida completo del aprendizaje automático. Entrena y sirve modelos en distintas plataformas, por lo que puede usar un conjunto coherente de herramientas independientemente de dónde se ejecuten los experimentos. Puede usar MLflow localmente en el equipo, en un destino de proceso remoto, en una máquina virtual o en una instancia de proceso de Machine Learning.
MLflow consta de varias funcionalidades clave:
Seguimiento de experimentos: puede usar MLflow para realizar un seguimiento de los experimentos, incluidos los parámetros, las versiones de código, las métricas y los archivos de salida. Esta característica le ayuda a comparar diferentes ejecuciones y a administrar el proceso de experimentación de forma eficaz.
Código de paquete: ofrece un formato estandarizado para empaquetar código de aprendizaje automático, que incluye dependencias y configuraciones. Este empaquetado facilita reproducir ejecuciones y compartir código con otros usuarios.
Administración de modelos: MLflow proporciona funcionalidades para administrar y crear versiones de modelos. Admite varios marcos de aprendizaje automático, por lo que puede almacenar, versionar y servir modelos.
Entrega e implementación de modelos: MLflow integra las funcionalidades de entrega e implementación del modelo, por lo que puede implementar fácilmente modelos en diversos entornos.
Registro de modelos: puede administrar el ciclo de vida de un modelo, incluido el control de versiones, las transiciones de fase y las anotaciones. Puede usar MLflow para mantener un almacén de modelos centralizado en un entorno de colaboración.
Uso de una API y una interfaz de usuario: dentro de Azure, MLflow se agrupa en la versión 2 de la API de Machine Learning, por lo que puede interactuar con el sistema mediante programación. Puede usar Azure Portal para interactuar con una interfaz de usuario.
MLflow simplifica y estandariza el proceso de desarrollo de aprendizaje automático, desde la experimentación hasta la implementación.
Machine Learning se integra con repositorios de Git, por lo que puede usar servicios compatibles con GitHub, como GitHub, GitLab, Bitbucket, Azure DevOps u otro servicio compatible con Git. Además de los activos que ya se han seguido en Machine Learning, el equipo puede desarrollar su propia taxonomía dentro de su servicio compatible con Git para almacenar otros datos del proyecto, como:
- Documentación
- Datos del proyecto: por ejemplo, el informe final del proyecto
- Informe de datos: por ejemplo, el diccionario de datos o los informes de calidad de datos
- Modelo: por ejemplo, informes de modelos
- Código
- Preparación de datos
- Desarrollo del modelo
- Puesta en funcionamiento, incluida la seguridad y el cumplimiento
Infraestructura y recursos
El TDSP proporciona recomendaciones sobre cómo administrar la infraestructura de almacenamiento y análisis compartidos en las siguientes categorías:
- Sistemas de archivos en la nube para almacenar conjuntos de datos
- Bases de datos en la nube
- Clústeres de macrodatos que usan SQL o Spark
- Servicios de inteligencia artificial y aprendizaje automático
Sistemas de archivos en la nube para almacenar conjuntos de datos
Los sistemas de archivos en la nube son fundamentales para el TDSP por varias razones:
Almacenamiento de datos centralizado: los sistemas de archivos en la nube proporcionan una ubicación centralizada para almacenar conjuntos de datos, lo que es esencial para la colaboración entre los miembros del equipo de ciencia de datos. La centralización garantiza que todos los miembros del equipo puedan acceder a los datos más actuales y reduce el riesgo de trabajar con conjuntos de datos obsoletos o incoherentes.
Escalabilidad: los sistemas de archivos en la nube pueden controlar grandes volúmenes de datos, lo que es común en los proyectos de ciencia de datos. Los sistemas de archivos proporcionan soluciones de almacenamiento escalables que crecen con las necesidades del proyecto. Permiten a los equipos almacenar y procesar conjuntos de datos masivos sin preocuparse por las limitaciones de hardware.
Accesibilidad: con sistemas de archivos en la nube, puede acceder a datos desde cualquier lugar con una conexión a Internet. Este acceso es importante para los equipos distribuidos o cuando los miembros del equipo necesitan trabajar de forma remota. Los sistemas de archivos en la nube facilitan la colaboración sin problemas y garantizan que los datos siempre sean accesibles.
Seguridad y cumplimiento: los proveedores de nube suelen implementar medidas de seguridad sólidas, que incluyen cifrado, controles de acceso y cumplimiento con estándares y regulaciones del sector. Las medidas de seguridad sólidas pueden proteger los datos confidenciales y ayudar a su equipo a cumplir los requisitos legales y normativos.
Control de versiones: los sistemas de archivos en la nube suelen incluir características de control de versiones, que los equipos pueden usar para realizar un seguimiento de los cambios en los conjuntos de datos a lo largo del tiempo. El control de versiones es fundamental para mantener la integridad de los datos y reproducir los resultados en los proyectos de ciencia de datos. También le ayuda a auditar y solucionar los problemas que surjan.
Integración con herramientas: los sistemas de archivos en la nube se pueden integrar perfectamente con diversas plataformas y herramientas de ciencia de datos. La integración de herramientas facilita la ingesta, el procesamiento y el análisis de datos. Por ejemplo, Azure Storage se integra bien con Machine Learning, Azure Databricks y otras herramientas de ciencia de datos.
Colaboración y uso compartido: los sistemas de archivos en la nube facilitan el uso compartido de conjuntos de datos con otros miembros del equipo o partes interesadas. Estos sistemas admiten características colaborativas, como carpetas compartidas y administración de permisos. Las características de colaboración facilitan el trabajo en equipo y garantizan que las personas adecuadas tengan acceso a los datos que necesitan.
Rentabilidad: los sistemas de archivos en la nube pueden ser más rentables que mantener soluciones de almacenamiento locales. Los proveedores de nube tienen modelos de precios flexibles que incluyen opciones de pago por uso, que pueden ayudar a administrar los costes en función de los requisitos reales de uso y almacenamiento del proyecto de ciencia de datos.
Recuperación ante desastres: los sistemas de archivos en la nube suelen incluir características para la copia de seguridad de datos y la recuperación ante desastres. Estas características ayudan a proteger los datos frente a errores de hardware, eliminaciones accidentales y otros desastres. Proporciona tranquilidad y admite la continuidad en las operaciones de ciencia de datos.
Automatización e integración de flujos de trabajo: los sistemas de almacenamiento en la nube se pueden integrar en flujos de trabajo automatizados, lo que permite la transferencia de datos sin problemas entre distintas fases del proceso de ciencia de datos. La automatización puede ayudar a mejorar la eficiencia y reducir el esfuerzo manual necesario para administrar los datos.
Recursos de Azure recomendados para sistemas de archivos en la nube
- Azure Blob Storage: documentación completa sobre Azure Blob Storage, que es un servicio de almacenamiento de objetos escalable para datos no estructurados.
- Azure Data Lake Storage: información sobre Azure Data Lake Storage Gen2, diseñado para el análisis de macrodatos y admite conjuntos de datos a gran escala.
- Azure Files: detalles sobre Azure Files, que proporciona recursos compartidos de archivos totalmente administrados en la nube.
En resumen, los sistemas de archivos en la nube son cruciales para el TDSP, ya que proporcionan soluciones de almacenamiento escalables, seguras y accesibles que admiten todo el ciclo de vida de los datos. Los sistemas de archivos en la nube permiten la integración de datos de varios orígenes sin problemas, lo que admite la adquisición y comprensión integrales de datos. Los científicos de datos pueden usar sistemas de archivos en la nube para almacenar, administrar y acceder eficazmente a grandes conjuntos de datos. Esta funcionalidad es esencial para entrenar e implementar modelos de aprendizaje automático. Estos sistemas también mejoran la colaboración al permitir que los miembros del equipo compartan y trabajen en datos simultáneamente en un entorno unificado. Los sistemas de archivos en la nube proporcionan características de seguridad sólidas que ayudan a proteger los datos y a que sean compatibles con los requisitos normativos, lo que es fundamental para mantener la integridad y la confianza de los datos.
Bases de datos en la nube
Las bases de datos en la nube desempeñan un papel fundamental en el TDSP por varias razones:
Escalabilidad: las bases de datos en la nube proporcionan soluciones escalables que pueden crecer fácilmente para satisfacer las crecientes necesidades de datos de un proyecto. La escalabilidad es fundamental para los proyectos de ciencia de datos que controlan con frecuencia conjuntos de datos grandes e intrincados. Las bases de datos en la nube pueden controlar distintas cargas de trabajo sin necesidad de realizar intervenciones manuales o actualizaciones de hardware.
Optimización del rendimiento: los desarrolladores optimizan las bases de datos en la nube para el rendimiento mediante funcionalidades como la indexación automática, la optimización de consultas y el equilibrio de carga. Estas características ayudan a garantizar que la recuperación y el procesamiento de datos sean rápidos y eficaces, lo que es fundamental para las tareas de ciencia de datos que requieren acceso a datos en tiempo real o casi en tiempo real.
Accesibilidad y colaboración: los equipos pueden acceder a los datos almacenados en bases de datos en la nube desde cualquier ubicación. Esta accesibilidad fomenta la colaboración entre los miembros del equipo que podrían estar dispersos geográficamente. La accesibilidad y la colaboración son importantes para equipos distribuidos o personas que trabajan de forma remota. Las bases de datos en la nube admiten entornos multiusuario que permiten el acceso simultáneo y la colaboración.
Integración con herramientas de ciencia de datos: las bases de datos en la nube se integran perfectamente con diversas plataformas y herramientas de ciencia de datos. Por ejemplo, las bases de datos en la nube de Azure se integran bien con Machine Learning, Power BI y otras herramientas de análisis de datos. Esta integración simplifica la canalización de datos, desde la ingesta y el almacenamiento hasta el análisis y la visualización.
Seguridad y cumplimiento: los proveedores de nube implementan medidas de seguridad sólidas, que incluyen cifrado de datos, controles de acceso y cumplimiento con estándares y regulaciones del sector. Las medidas de seguridad protegen los datos confidenciales y ayudan a su equipo a cumplir los requisitos legales y normativos. Las características de seguridad son fundamentales para mantener la integridad y la privacidad de los datos.
Rentabilidad: las bases de datos en la nube suelen funcionar en un modelo de pago por uso, lo que puede ser más rentable que mantener sistemas de bases de datos locales. Esta flexibilidad de precios permite a las organizaciones administrar sus presupuestos de forma eficaz y pagar solo por los recursos de almacenamiento y proceso que usan.
Copias de seguridad automáticas y recuperación ante desastres: las bases de datos en la nube proporcionan soluciones de copia de seguridad y recuperación ante desastres automáticas. Estas soluciones ayudan a evitar la pérdida de datos si hay errores de hardware, eliminaciones accidentales u otros desastres. La confiabilidad es fundamental para mantener la continuidad e integridad de los datos en los proyectos de ciencia de datos.
Procesamiento de datos en tiempo real: muchas bases de datos en la nube admiten el procesamiento y el análisis de datos en tiempo real, que es esencial para las tareas de ciencia de datos que requieren la información más actual. Esta funcionalidad ayuda a los científicos de datos a tomar decisiones oportunas basadas en los datos disponibles más recientes.
Integración de datos: las bases de datos en la nube se pueden integrar fácilmente con otros orígenes de datos, bases de datos, lagos de datos y fuentes de distribución de datos externas. La integración ayuda a los científicos de datos a combinar datos de varios orígenes y proporciona una vista completa y un análisis más sofisticado.
Flexibilidad y variedad: las bases de datos en la nube tienen varias formas, como bases de datos relacionales, bases de datos NoSQL y almacenes de datos. Esta variedad permite a los equipos de ciencia de datos elegir el mejor tipo de base de datos para sus necesidades específicas, independientemente de si requieren almacenamiento de datos estructurados, control de datos no estructurados o análisis de datos a gran escala.
Compatibilidad con el análisis avanzado: las bases de datos en la nube a menudo incluyen compatibilidad integrada con análisis avanzado y aprendizaje automático. Por ejemplo, Azure SQL Database proporciona servicios de aprendizaje automático integrados. Estos servicios ayudan a los científicos de datos a realizar análisis avanzados directamente en el entorno de la base de datos.
Recursos de Azure recomendados para bases de datos en la nube
- Azure SQL Database: documentación sobre Azure SQL Database, un servicio de base de datos relacional totalmente administrado.
- Azure Cosmos DB: información sobre Azure Cosmos DB, un servicio de base de datos multimodelo distribuido globalmente.
- Azure Database for PostgreSQL: guía de Azure Database for PostgreSQL, un servicio de base de datos administrado para el desarrollo e implementación de aplicaciones.
- Azure Database for MySQL: detalles sobre Azure Database for MySQL, un servicio administrado para bases de datos MySQL.
En resumen, las bases de datos en la nube son cruciales para TDSP, ya que proporcionan soluciones de administración y almacenamiento de datos escalables, confiables y eficaces que admiten proyectos controlados por datos. Facilitan la integración de datos sin problemas, lo que ayuda a los científicos de datos a ingerir, preprocesar y analizar grandes conjuntos de datos de varios orígenes. Las bases de datos en la nube permiten el procesamiento rápido de consultas y datos, que es esencial para desarrollar, probar e implementar modelos de aprendizaje automático. Además, las bases de datos en la nube mejoran la colaboración al proporcionar una plataforma centralizada para que los miembros del equipo accedan y trabajen con datos simultáneamente. Por último, las bases de datos en la nube proporcionan características de seguridad avanzadas y compatibilidad con el cumplimiento para mantener los datos protegidos y compatibles con los estándares normativos, lo que es fundamental para mantener la integridad y la confianza de los datos.
Clústeres de macrodatos que usan SQL o Spark
Los clústeres de macrodatos, como los que usan SQL o Spark, son fundamentales para el TDSP por varias razones:
Control de grandes volúmenes de datos: los clústeres de macrodatos están diseñados para controlar grandes volúmenes de datos de forma eficaz. Los proyectos de ciencia de datos suelen implicar conjuntos de datos masivos que superan la capacidad de las bases de datos tradicionales. Los clústeres de macrodatos basados en SQL y Spark pueden administrar y procesar estos datos a escala.
Computación distribuida: los clústeres de macrodatos usan la computación distribuida para distribuir datos y tareas computacionales en varios nodos. La funcionalidad de procesamiento paralelo acelera significativamente las tareas de procesamiento y análisis de datos, que es esencial para obtener información oportuna en proyectos de ciencia de datos.
Escalabilidad: los clústeres de macrodatos proporcionan alta escalabilidad, tanto horizontalmente agregando más nodos como verticalmente aumentando la potencia de los nodos existentes. La escalabilidad ayuda a garantizar que la infraestructura de datos crezca con las necesidades del proyecto mediante el control del aumento de los tamaños y la complejidad de los datos.
Integración con herramientas de ciencia de datos: los clústeres de macrodatos se integran bien con diversas plataformas y herramientas de ciencia de datos. Por ejemplo, Spark se integra perfectamente con Hadoop y los clústeres de SQL funcionan con varias herramientas de análisis de datos. La integración facilita un flujo de trabajo sin problemas desde la ingesta de datos hasta el análisis y la visualización.
Análisis avanzado: los clústeres de macrodatos admiten análisis avanzados y aprendizaje automático. Por ejemplo, Spark proporciona las siguientes bibliotecas integradas:
- Machine Learning; MLlib
- Procesamiento de gráficos, GraphX
- Procesamiento de flujos, Spark Streaming
Estas funcionalidades ayudan a los científicos de datos a realizar análisis complejos directamente dentro del clúster.
Procesamiento de datos en tiempo real: los clústeres de macrodatos, especialmente los que usan Spark, admiten el procesamiento de datos en tiempo real. Esta funcionalidad es fundamental para los proyectos que requieren análisis de datos y toma de decisiones al minuto. El procesamiento en tiempo real ayuda en escenarios como la detección de fraudes, las recomendaciones en tiempo real y los precios dinámicos.
Transformación de datos y extracción, transformación y carga (ETL): los clústeres de macrodatos son ideales para la transformación de datos y los procesos ETL. Pueden controlar de forma eficaz las transformaciones de datos complejas, la limpieza y las tareas de agregación, que a menudo son necesarias para poder analizar los datos.
Rentabilidad: los clústeres de macrodatos pueden ser rentables, especialmente cuando se usan soluciones basadas en la nube como Azure Databricks y otros servicios en la nube. Estos servicios proporcionan modelos de precios flexibles que incluyen el pago por uso, que puede ser más económico que mantener la infraestructura de macrodatos local.
Tolerancia a errores: los clústeres de macrodatos están diseñados teniendo en cuenta la tolerancia a errores. Replican datos entre nodos para asegurarse de que el sistema permanece operativo incluso si se produce un error en algunos nodos. Esta confiabilidad es fundamental para mantener la integridad de los datos y la disponibilidad en los proyectos de ciencia de datos.
Integración de Data Lake: los clústeres de macrodatos a menudo se integran perfectamente con lagos de datos, lo que permite a los científicos de datos acceder y analizar diversos orígenes de datos de forma unificada. La integración fomenta análisis más completos al admitir una combinación de datos estructurados y no estructurados.
Procesamiento basado en SQL: para los científicos de datos que están familiarizados con SQL, los clústeres de macrodatos que funcionan con consultas SQL, como Spark SQL o SQL en Hadoop, proporcionan una interfaz familiar para consultar y analizar macrodatos. Esta facilidad de uso puede acelerar el proceso de análisis y hacer que sea más accesible para una gama más amplia de usuarios.
Colaboración y uso compartido: los clústeres de macrodatos admiten entornos de colaboración en los que varios científicos de datos y analistas pueden trabajar juntos en los mismos conjuntos de datos. Proporcionan características para compartir código, cuadernos y resultados que fomentan el uso compartido de conocimientos y el trabajo en equipo.
Seguridad y cumplimiento: los clústeres de macrodatos proporcionan características de seguridad sólidas, como el cifrado de datos, los controles de acceso y el cumplimiento de los estándares del sector. Las características de seguridad protegen los datos confidenciales y ayudan a su equipo a cumplir los requisitos normativos.
Recursos de Azure recomendados para clústeres de macrodatos
- Apache Spark en Machine Learning: la integración de Machine Learning con Azure Synapse Analytics proporciona un acceso sencillo a los recursos de computación distribuidos a través del marco de Apache Spark.
- Azure Synapse Analytics: documentación completa de Azure Synapse Analytics, que integra macrodatos y almacenamiento de datos.
En resumen, los clústeres de macrodatos, ya sea SQL o Spark, son cruciales para el TDSP, ya que proporcionan la capacidad computacional y la escalabilidad necesarias para controlar de forma eficaz grandes cantidades de datos. Los clústeres de macrodatos permiten a los científicos de datos realizar consultas complejas y análisis avanzados en grandes conjuntos de datos que facilitan la información detallada y el desarrollo preciso de modelos. Cuando se usa la computación distribuida, estos clústeres permiten un rápido procesamiento y análisis de datos, lo que acelera el flujo de trabajo general de ciencia de datos. Los clústeres de macrodatos también admiten la integración sin problemas con varios orígenes de datos y herramientas, lo que mejora la capacidad de ingerir, procesar y analizar datos de varios entornos. Los clústeres de macrodatos también promueven la colaboración y la reproducibilidad proporcionando una plataforma unificada en la que los equipos pueden compartir eficazmente recursos, flujos de trabajo y resultados.
Servicios de inteligencia artificial y aprendizaje automático
Los servicios de IA y aprendizaje automático (ML) son integrales para el TDSP por varias razones:
Análisis avanzado: los servicios de IA y ML permiten el análisis avanzado. Los científicos de datos pueden usar análisis avanzados para detectar patrones complejos, realizar predicciones y generar conclusiones que no son posibles con métodos analíticos tradicionales. Estas funcionalidades avanzadas son cruciales para crear soluciones de ciencia de datos de alto impacto.
Automatización de tareas repetitivas: los servicios de IA y ML pueden automatizar tareas repetitivas, como la limpieza de datos, la ingeniería de características y el entrenamiento del modelo. La automatización ahorra tiempo y ayuda a los científicos de datos a centrarse en aspectos más estratégicos del proyecto, lo que mejora la productividad general.
Mejora de la precisión y el rendimiento: los modelos de ML pueden mejorar la precisión y el rendimiento de las predicciones y los análisis mediante el aprendizaje de los datos. Estos modelos pueden mejorar continuamente a medida que se exponen a más datos, lo que conduce a una mejor toma de decisiones y resultados más confiables.
Escalabilidad: los servicios de IA y ML proporcionados por plataformas en la nube, como Machine Learning, son altamente escalables. Pueden controlar grandes volúmenes de datos y cálculos complejos, lo que ayuda a los equipos de ciencia de datos a escalar sus soluciones para satisfacer las crecientes demandas sin preocuparse por las limitaciones subyacentes de la infraestructura.
Integración con otras herramientas: los servicios de IA y ML se integran perfectamente con otras herramientas y servicios dentro del ecosistema de Microsoft, como Azure Data Lake, Azure Databricks y Power BI. La integración admite un flujo de trabajo simplificado desde la ingesta y el procesamiento de datos hasta la implementación y visualización del modelo.
Implementación y administración de modelos: los servicios de IA y ML proporcionan herramientas sólidas para implementar y administrar modelos de aprendizaje automático en producción. Las características como el control de versiones, la supervisión y el reentrenamiento automatizado ayudan a garantizar que los modelos sigan siendo precisos y eficaces a lo largo del tiempo. Este enfoque simplifica el mantenimiento de las soluciones de ML.
Procesamiento en tiempo real: los servicios de IA y ML admiten el procesamiento de datos en tiempo real y la toma de decisiones. El procesamiento en tiempo real es esencial para las aplicaciones que requieren información y acciones inmediatas, como la detección de fraudes, los precios dinámicos y los sistemas de recomendaciones.
Personalización y flexibilidad: los servicios de IA y ML proporcionan una variedad de opciones personalizables, desde modelos y API precompilados hasta marcos para crear modelos personalizados desde cero. Esta flexibilidad ayuda a los equipos de ciencia de datos a adaptar soluciones a necesidades empresariales y casos de uso específicos.
Acceso a algoritmos de vanguardia: los servicios de IA y ML proporcionan a los científicos de datos acceso a algoritmos y tecnologías de vanguardia desarrollados por investigadores líderes. El acceso garantiza que el equipo pueda usar los últimos avances en IA y ML para sus proyectos.
Colaboración y uso compartido: las plataformas de IA y ML admiten entornos de desarrollo colaborativos, donde varios miembros del equipo pueden trabajar juntos en el mismo proyecto, compartir código y reproducir experimentos. La colaboración mejora el trabajo en equipo y ayuda a garantizar la coherencia en el desarrollo del modelo.
Rentabilidad: los servicios de IA y ML en la nube pueden ser más rentables que crear y mantener soluciones locales. Los proveedores de nube tienen modelos de precios flexibles que incluyen opciones de pago por uso, lo que puede reducir los costes y optimizar el uso de recursos.
Seguridad y cumplimiento mejorados: los servicios de IA y ML incluyen características de seguridad sólidas, como el cifrado de datos, los controles de acceso seguro y el cumplimiento de estándares y regulaciones del sector. Estas características ayudan a proteger los datos y modelos y a cumplir los requisitos legales y normativos.
Modelos y API pregenerados: muchos servicios de IA y ML proporcionan modelos y API precompilados para tareas comunes, como el procesamiento de lenguaje natural, el reconocimiento de imágenes y la detección de anomalías. Las soluciones precompiladas pueden acelerar el desarrollo y la implementación y ayudar a los equipos a integrar rápidamente las funcionalidades de inteligencia artificial en sus aplicaciones.
Experimentación y creación de prototipos: las plataformas de IA y ML proporcionan entornos para la experimentación rápida y la creación de prototipos. Los científicos de datos pueden probar rápidamente diferentes algoritmos, parámetros y conjuntos de datos para encontrar la mejor solución. La experimentación y la creación de prototipos admiten un enfoque iterativo para el desarrollo de modelos.
Recursos de Azure recomendados para los servicios de IA y ML
Machine Learning es el recurso principal que se recomienda para la aplicación de ciencia de datos y TDSP. Además, Azure proporciona servicios de IA que tienen modelos de IA listos para usar para aplicaciones específicas.
- Machine Learning: la página de documentación principal de Machine Learning que abarca la configuración, el entrenamiento de modelos, la implementación, etc.
- Servicios de Azure AI: información sobre los servicios de IA que proporcionan modelos de IA precompilados para tareas de visión, voz, lenguaje y toma de decisiones.
En resumen, los servicios de IA y ML son cruciales para el TDSP, ya que proporcionan herramientas y marcos eficaces que simplifican el desarrollo, el entrenamiento y la implementación de modelos de aprendizaje automático. Estos servicios automatizan tareas complejas, como la selección de algoritmos y el ajuste de hiperparámetros, lo que acelera considerablemente el proceso de desarrollo del modelo. Estos servicios también proporcionan una infraestructura escalable que ayuda a los científicos de datos a controlar de forma eficaz grandes conjuntos de datos y tareas de uso intensivo de cálculo. Las herramientas de IA y ML se integran perfectamente con otros servicios de Azure y mejoran la ingesta de datos, el preprocesamiento y la implementación del modelo. La integración ayuda a garantizar un flujo de trabajo de un extremo a otro sin problemas. Además, estos servicios fomentan la colaboración y reproducibilidad. Los equipos pueden compartir información y experimentar eficazmente con resultados y modelos mientras mantienen altos estándares de seguridad y cumplimiento.
IA responsable
Con las soluciones de IA o ML, Microsoft promueve herramientas de IA responsables dentro de sus soluciones de IA y ML. Estas herramientas admiten el Estándar de IA responsable de Microsoft. La carga de trabajo debe seguir abordando individualmente los daños relacionados con la inteligencia artificial.
Citas revisadas por expertos
El TDSP es una metodología bien establecida que los equipos usan en las interacciones de Microsoft. El TDSP está documentado y estudiado en documentación revisada por expertos. Las citas proporcionan una oportunidad para investigar las aplicaciones y características del TDSP. Para obtener más información y una lista de citas, consulte Ciclo de vida de TDSP.