Fase de adquisición y comprensión de los datos del ciclo de vida del proceso de ciencia de datos en equipos
En este artículo se describen los objetivos, las tareas y los resultados asociados a la fase de adquisición y comprensión de los datos del Proceso de ciencia de datos en equipo (TDSP). Este proceso proporciona un ciclo de vida recomendado que el equipo puede usar para estructurar los proyectos de ciencia de datos. El ciclo de vida describe las fases principales que realiza el equipo, a menudo iterativamente:
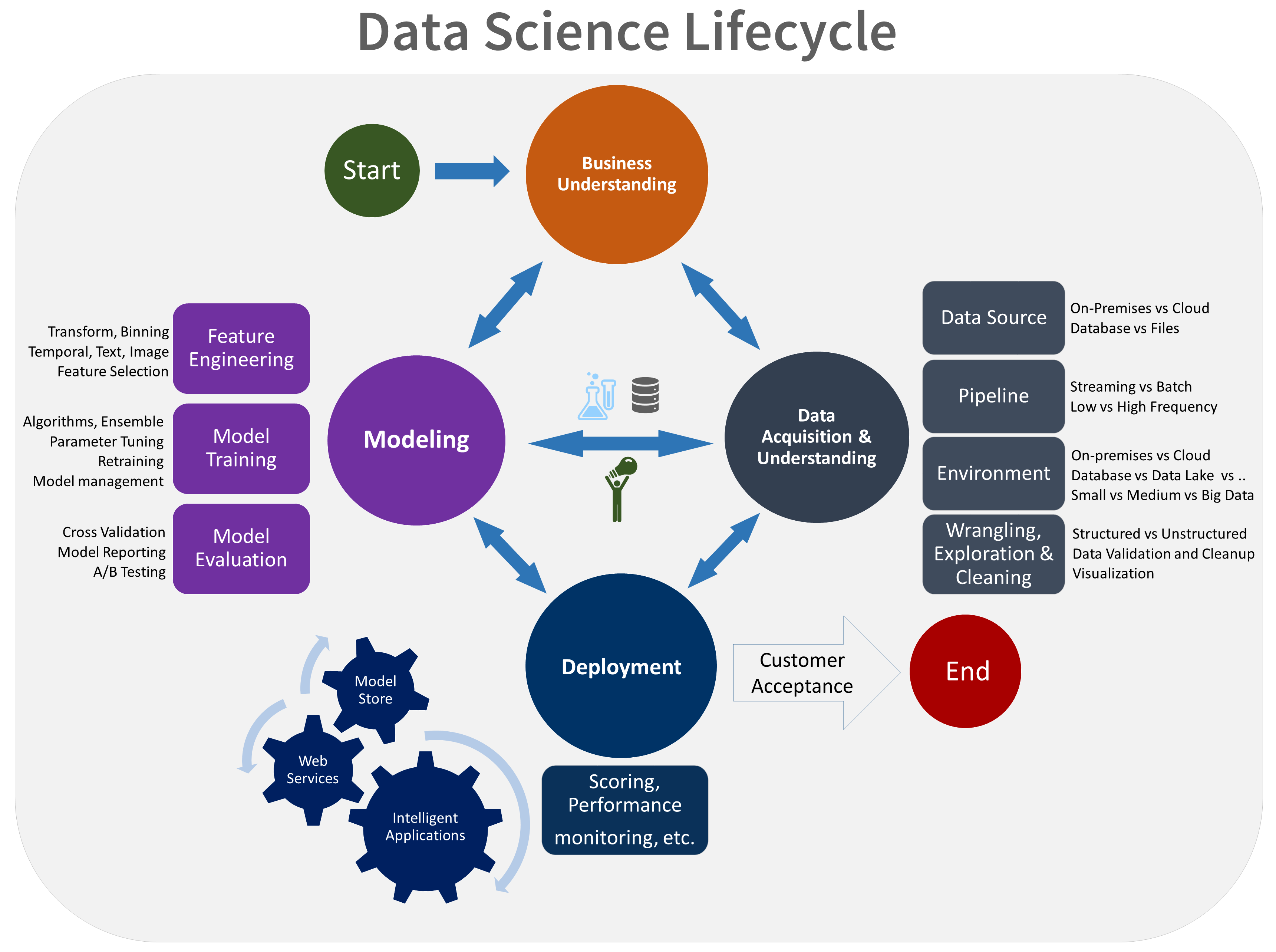
- Conocimiento del negocio
- Adquisición y comprensión de los datos
- Modelado
- Implementación
- Aceptación del cliente
Esta es una representación visual del ciclo de vida de TDSP:
Objetivos
Los objetivos de la fase de adquisición y comprensión de datos son:
Producir un conjunto de datos limpio y de alta calidad que se relacione claramente con las variables objetivo. Localizar el conjunto de datos en el entorno de análisis adecuado para que su equipo esté listo para la etapa de modelado.
Desarrolle una arquitectura de solución de la canalización de datos que actualice y puntúe los datos con regularidad.
Cómo completar las tareas
La fase de adquisición y comprensión de datos tiene tres tareas principales:
Ingesta de datos en el entorno de análisis de destino.
Exploración de datos para determinar si los datos pueden responder a la pregunta.
Configuración de una canalización de datos para puntuar los datos nuevos o que se actualizan con regularidad.
Ingerir datos
Configure un proceso para mover los datos desde las ubicaciones de origen a las ubicaciones de destino donde se ejecutan las operaciones de análisis, como el entrenamiento y las predicciones.
Exploración de datos
Antes de entrenar los modelos, debe desarrollar una comprensión sólida de los datos. A menudo, los conjuntos de datos reales contienen ruido, les faltan datos o presentan un sinfín de discrepancias de otros tipos. Puede utilizar funciones de resumen y visualización de los datos para auditar su calidad y recopilar información para procesarlos y dejarlos preparados para el modelado. Normalmente, se trata de un proceso iterativo.
Una vez que esté satisfecho con la calidad de los datos limpios, el siguiente paso es comprender mejor los patrones de los datos. Este análisis de datos ayuda a elegir y desarrollar un modelo de predicción adecuado para el destino. Determine la cantidad de datos que corresponde al destino. A continuación, decida si el equipo tiene suficientes datos para avanzar con los siguientes pasos de modelado. Como hemos indicado, normalmente, se trata de un proceso iterativo. Es posible que deba buscar otros orígenes de datos con información más precisa o pertinente con el fin de ajustar el conjunto de datos inicialmente identificado en la fase anterior.
Configuración de una canalización de datos
Además de la ingesta y limpieza de los datos, suele ser necesario configurar un proceso para puntuar los datos nuevos o actualizarlos con regularidad durante el proceso de aprendizaje continuo. Puede usar una canalización de datos o un flujo de trabajo para puntuar los datos. Se recomienda una canalización que use Azure Data Factory.
En esta fase, desarrolla una arquitectura de solución de la canalización de datos. Cree la canalización en paralelo con la siguiente fase del proyecto de ciencia de datos. En función de las necesidades empresariales y de las limitaciones de los sistemas existentes en los que se integre esta solución, la canalización puede ser:
- Basada en lotes
- Streaming o en tiempo real
- Híbrido
Integración con MLflow
Durante la fase de comprensión de datos, puede usar el seguimiento de experimentos de MLflow para realizar un seguimiento y documentar diversas estrategias de preprocesamiento de datos y análisis de datos exploratorios.
Artifacts
En esta fase, el equipo entrega lo siguiente:
Un informe de la calidad de los datos: contiene resúmenes de los datos, las relaciones entre cada atributo y objetivo, la clasificación de las variables, etc.
Una arquitectura de solución, como un diagrama o una descripción de la canalización de datos que usa el equipo para ejecutar predicciones en nuevos datos. Este diagrama contiene la canalización para volver a entrenar el modelo basándose en los nuevos datos. Al usar la plantilla de estructura de directorios del TDSP, almacene el documento en directorio del proyecto.
Una decisión de punto de control. antes de comenzar con el proceso completo de diseño de características y con la compilación del modelo, puede volver a evaluar el proyecto para determinar si el valor que está previsto que aporte es suficiente para seguir adelante con él. Por ejemplo, podría estar preparado para continuar, requerir más datos o abandonar el proyecto si no puede encontrar datos que respondan a las preguntas.
Documentación revisada por expertos
Los investigadores publican estudios sobre el TDSP en la documentación revisada por expertos. Las citas proporcionan una oportunidad para investigar otras aplicaciones o ideas similares al TDSP, incluida la fase del ciclo de vida de descripción y adquisición de los datos.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Mark Tabladillo | Arquitecto sénior de soluciones en la nube
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Recursos relacionados
En estos artículos se describen las demás fases del ciclo de vida del TDSP: