Introducción a las funcionalidades de puerta de enlace de IA generativa en Azure API Management
SE APLICA A: todos los niveles de API Management
En este artículo se presentan las funcionalidades de Azure API Management para ayudarle a administrar las API de IA generativa, como las proporcionadas por Azure OpenAI Service. Azure API Management proporciona una variedad de directivas, métricas y otras características para mejorar la seguridad, el rendimiento y la confiabilidad de las API que sirven a las aplicaciones inteligentes. En conjunto, estas características se denominan funcionalidades de puerta de enlace de IA generativa (GenAI) para las API de IA generativa.
Nota:
- Este artículo se centra en las funcionalidades para administrar las API expuestas por Azure OpenAI Service. Muchas de las funcionalidades de puerta de enlace de GenAI se aplican a otras API de modelo de lenguaje de gran tamaño (LLM), incluidas las disponibles a través de la API de inferencia de modelo de Azure AI.
- Las funcionalidades de puerta de enlace de IA generativa son características de la puerta de enlace de API existente de API Management, no una puerta de enlace de API independiente. Para más información sobre API Management, consulte Información general sobre Azure API Management.
Desafíos en la administración de las API de IA generativa
Uno de los principales recursos que tiene en los servicios de IA generativa son los tokens. Azure OpenAI Service asigna una cuota para las implementaciones del modelo expresadas en tokens por minuto (TPM), que luego se distribuye entre los consumidores del modelo, por ejemplo, diferentes aplicaciones, equipos de desarrolladores, departamentos dentro de la empresa, etc.
Azure facilita la conexión de una sola aplicación a Azure OpenAI Service: puede conectarse directamente mediante una clave de API con un límite de TPM configurado directamente en el nivel de implementación del modelo. Sin embargo, cuando su portafolio de aplicaciones empieza a crecer, se encuentra con varias aplicaciones que llaman a uno o incluso varios puntos de conexión de Azure OpenAI Service que se han implementado como de pago por uso o instancias de unidades de rendimiento aprovisionadas (PTU). Esto conlleva ciertos desafíos:
- ¿Cómo se realiza el seguimiento del uso de tokens en múltiples aplicaciones? ¿Se pueden calcular los cargos cruzados para varias aplicaciones o equipos que usan modelos de Azure OpenAI Service?
- ¿Cómo se asegura de que una sola aplicación no consuma toda la cuota de TPM, dejando otras aplicaciones sin opción para usar modelos de Azure OpenAI Service?
- ¿Cómo se distribuye la clave de API de forma segura entre varias aplicaciones?
- ¿Cómo se distribuye la carga entre varios puntos de conexión de Azure OpenAI? ¿Puede asegurarse de que se agote la capacidad confirmada en las PTU antes de revertir a las instancias de pago por uso?
En el resto de este artículo se describe cómo Azure API Management puede ayudarle a abordar estos desafíos.
Importación de un recurso de Azure OpenAI Service como una API
Importar una API desde un punto de conexión de Azure OpenAI Service a Azure API Management mediante una experiencia con un solo clic. API Management simplifica el proceso de incorporación mediante la importación automática del esquema de OpenAPI para la API de Azure OpenAI y configura la autenticación en el punto de conexión de Azure OpenAI mediante la identidad administrada, lo que elimina la necesidad de una configuración manual. Dentro de la misma experiencia fácil de usar, puede preconfigurar directivas para los límites de tokens y para emitir métricas de token.

Directiva de límite de tokens
Configure la directiva de límite de tokens de Azure OpenAI para administrar y aplicar límites por consumidor de API en función del uso de tokens de Azure OpenAI Service. Con esta directiva puede establecer límites, expresados en tokens por minuto (TPM).
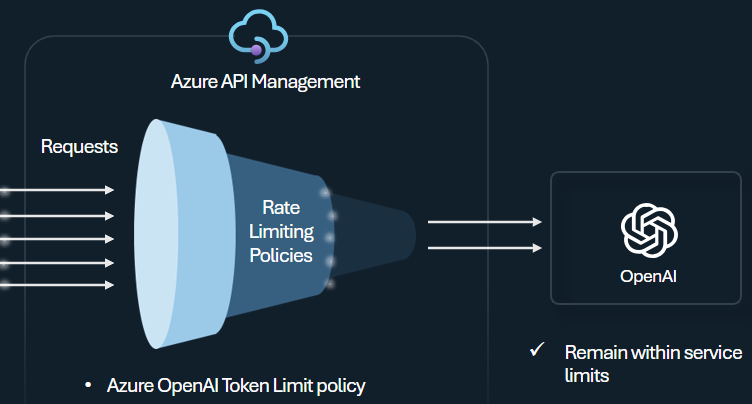
Esta directiva proporciona flexibilidad para asignar límites basados en tokens en cualquier clave de contador, como la clave de suscripción, la dirección IP de origen o una clave arbitraria definida a través de una expresión de directiva. La directiva también habilita el cálculo previo de los tokens de solicitud en el lado de Azure API Management, lo que minimiza las solicitudes innecesarias al backend de Azure OpenAI Service si la solicitud ya supera el límite.
En el siguiente ejemplo básico se muestra cómo establecer un límite de TPM de 500 por clave de suscripción:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Sugerencia
Para administrar y aplicar límites de token para las API de LLM disponibles a través de la API de inferencia de modelo de Azure AI, API Management proporciona la directiva llm-token-limit equivalente.
Directiva de emisión de métricas de token
La directiva de emisión de métricas de tokens de Azure OpenAI envía métricas a Application Insights sobre el consumo de tokens de LLM a través de las API de Azure OpenAI Service. La directiva ayuda a proporcionar información general sobre el uso de modelos de Azure OpenAI Service en varias aplicaciones o consumidores de API. Esta directiva podría ser útil para escenarios de contracargo, supervisión y planificación de capacidad.
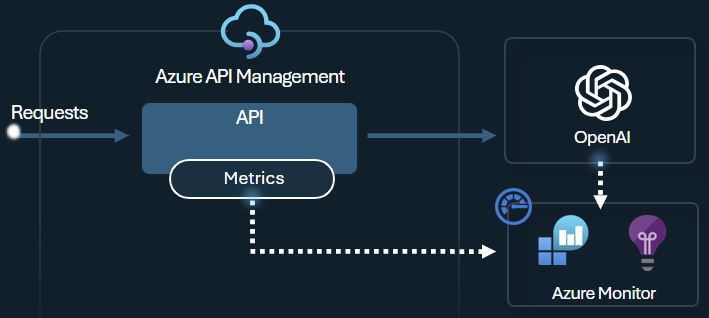
Esta directiva captura las métricas de solicitudes, finalizaciones y uso total de tokens y las envía a un espacio de nombres de Application Insights de su elección. Además, puede configurar o seleccionar entre dimensiones predefinidas para dividir las métricas de uso de tokens, de modo que pueda analizar las métricas por identificador de suscripción, dirección IP o una dimensión personalizada de su elección.
Por ejemplo, la siguiente directiva envía métricas a Application Insights divididas por dirección IP de cliente, API y usuario:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Sugerencia
Para enviar métricas para las API de LLM disponibles a través de la API de inferencia de modelo de Azure AI, API Management proporciona la directiva llm-emit-token-metric equivalente.
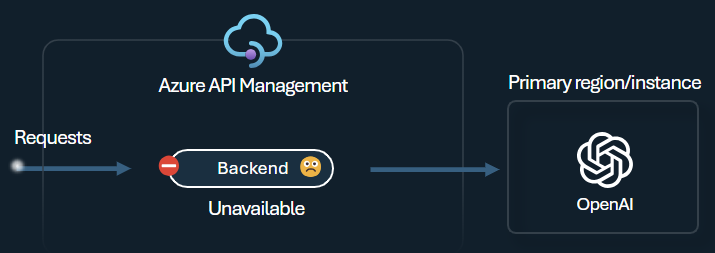
Equilibrador de carga de backend y disyuntor
Uno de los desafíos al compilar aplicaciones inteligentes es asegurarse de que las aplicaciones sean resistentes a los errores de backend y puedan controlar cargas elevadas. Al configurar los puntos de conexión de Azure OpenAI Service mediante los backend en Azure API Management, puede equilibrar la carga entre ellos. También puede definir las reglas del disyuntor para detener el reenvío de solicitudes a los backend de Azure OpenAI Service si no responden.
El equilibrador de carga del backend admite el equilibrio de carga basado en round-robin, ponderado y basado en prioridades, lo que le da flexibilidad para definir una estrategia de distribución de carga que cumpla sus requisitos específicos. Por ejemplo, defina prioridades dentro de la configuración del equilibrador de carga para garantizar un uso óptimo de puntos de conexión específicos de Azure OpenAI, especialmente aquellos adquiridos como PTU.
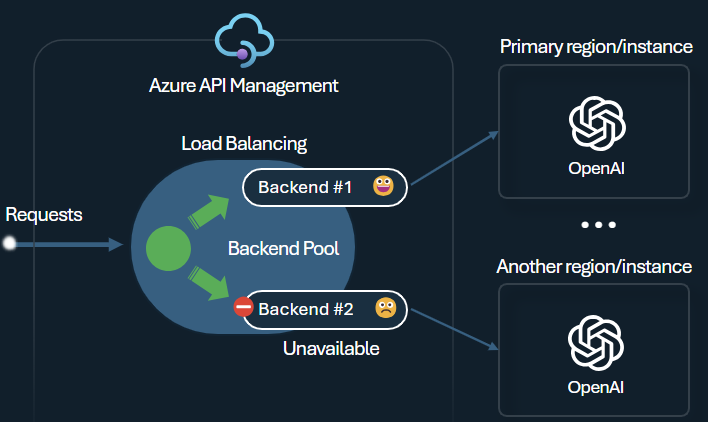
El disyuntor del backend incluye la duración del recorrido dinámica, aplicando valores del encabezado Retry-After proporcionado por el backend. Esto garantiza una recuperación precisa y oportuna de los backend, lo que maximiza el uso de sus backend prioritarios.
Directiva de almacenamiento en caché semántico
Configure las directivas de almacenamiento en caché semántico de Azure OpenAI para optimizar el uso de tokens mediante el almacenamiento de finalizaciones para solicitudes similares.
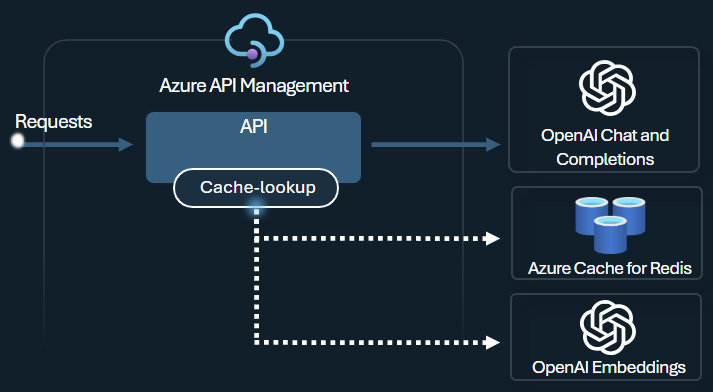
En API Management, habilite el almacenamiento en caché semántico mediante Azure Redis Enterprise u otra caché externa compatible con RediSearch e incorporada a Azure API Management. Mediante la API de inserción de Azure OpenAI Service, las directivas azure-openai-semantic-cache-store y azure-openai-semantic-cache-lookup almacenan y recuperan finalizaciones de solicitudes semánticamente similares de la memoria caché. Este enfoque garantiza la reutilización de las finalizaciones, lo que reduce el consumo de tokens y mejora el rendimiento de la respuesta.
Sugerencia
Para habilitar el almacenamiento en caché semántico para las API de LLM disponibles a través de la API de inferencia de modelo de Azure AI, API Management proporciona las directivas llm-semantic-cache-store-policy y llm-semantic-cache-lookup-policy equivalentes.
Laboratorios y ejemplos
- Laboratorios para las funcionalidades de la puerta de enlace de GenAI de Azure API Management
- Azure API Management (APIM): ejemplo de Azure OpenAI (Node.js)
- Código de ejemplo de Python para usar Azure OpenAI con API Management
Consideraciones sobre la arquitectura y el diseño
- Arquitectura de referencia de la puerta de enlace de GenAI mediante API Management
- Acelerador de zona de aterrizaje de la puerta de enlace del Centro de IA
- Diseño e implementación de una solución de puerta de enlace con recursos de Azure OpenAI
- Uso de una puerta de enlace delante de varias implementaciones o instancias de Azure OpenAI
Contenido relacionado
- Blog: Introducción a las funcionalidades de GenAI en Azure API Management
- Blog: Integración de la seguridad de contenido de Azure con API Management para puntos de conexión de Azure OpenAI
- Aprendizaje: Administración de las API de IA generativa con Azure API Management
- Equilibrio de carga inteligente para puntos de conexión de OpenAI y Azure API Management
- Autenticación y autorización del acceso a las API de Azure OpenAI mediante Azure API Management