Escalabilidad horizontal de Azure Analysis Services
Con la escalabilidad horizontal, las consultas de cliente pueden distribuirse entre varias réplicas de consulta de un grupo de consultas, reduciendo así los tiempos de respuesta durante las cargas de trabajo con un número elevado de consultas. También puede separar el procesamiento del conjunto de consultas, lo que garantiza que las consultas de los clientes no se vean afectadas negativamente por las operaciones de procesamiento. La escalabilidad horizontal puede configurarse en Azure Portal o con el uso de la API de REST de Analysis Services.
La escalabilidad horizontal está disponible para los servidores en el plan de tarifa Estándar. Cada réplica de consulta se factura a la misma tarifa que el servidor. Todas las réplicas de la consulta se crean en la misma región que el servidor. El número de réplicas de consultas que puede configurar está limitado por la región en la que se encuentra el servidor. Para más información, consulte la disponibilidad por región. La escalabilidad horizontal no aumenta la cantidad de memoria disponible para su servidor. Para aumentar la memoria, debe actualizar el plan.
Motivos para escalar horizontalmente
En una implementación típica de servidor, un servidor actúa como servidor de procesamiento y servidor de consulta. Si el número de consultas de cliente en los modelos en el servidor supera la unidades de procesamiento de consultas (QPU) del plan de su servidor o el procesamiento del modelo se produce al mismo tiempo que las cargas de trabajo con un número elevado de consultas, el rendimiento podría bajar.
Con la escalabilidad horizontal, puede crear un grupo de consultas con hasta siete recursos de réplica de consultas más (ocho en total, incluido su servidor principal). Puede escalar el número de réplicas del grupo de consultas para satisfacer las demandas de QPU en los momentos críticos y, además, puede separar un servidor de procesamiento del grupo de consultas en cualquier momento.
Independientemente del número de réplicas de consultas que tenga en un grupo de consultas, las cargas de trabajo de procesamiento no se distribuyen entre las réplicas de consultas. El servidor principal actúa como servidor de procesamiento. Las réplicas de consulta solo realizan consultas en las bases de datos de modelo sincronizadas entre el servidor principal y cada réplica del grupo de consultas.
Cuando se amplía, pueden pasar hasta cinco minutos antes de que las nuevas réplicas de consultas se agregan de forma incremental al conjunto de consultas. Cuando todas las nuevas réplicas de consulta están en funcionamiento, se equilibra la carga de las nuevas conexiones de cliente en todos los recursos del grupo de consultas. Las conexiones de clientes existentes no se cambian del recurso al que están conectados actualmente. Cuando se escalan, se cancelan todas las conexiones de cliente existentes a un recurso de grupo de consultas que se está eliminando del grupo de consultas. Los clientes pueden volver a conectarse a un recurso del grupo de consultas restante.
Funcionamiento
Cuando se configura la ampliación por primera vez, las bases de datos modelo del servidor primario se sincronizan automáticamente con las nuevas réplicas en un nuevo grupo de consultas. La sincronización automática se produce solo una vez. Durante la sincronización automática, los archivos de datos del servidor principal (cifrados en reposo en Blob Storage) se copian en una segunda ubicación, también cifrados en reposo en Blob Storage. Las réplicas del grupo de consultas se hidratan con datos del segundo conjunto de archivos.
Mientras que la sincronización automática solo se realiza cuando escala un servidor por primera vez, también puede realizar una sincronización manual. La sincronización garantiza que los datos en las réplicas del grupo de consultas coinciden con los del servidor principal. Al procesar (actualizar) modelos en el servidor principal, se debe realizar una sincronización después de la finalización de las operaciones de procesamiento. Esta sincronización copia los datos actualizados de los archivos del servidor principal de Blob Storage en el segundo conjunto de archivos. Las réplicas del grupo de consultas se hidratan con los datos actualizados del segundo conjunto de archivos de Blob Storage.
Cuando se realiza una operación de escalabilidad horizontal, por ejemplo, aumentar el número de réplicas en el conjunto de consultas de dos a cinco, las nuevas réplicas se hidratan con los datos del segundo conjunto de archivos en el almacenamiento blob. No hay sincronización. Si efectuara una sincronización después del escalado horizontal, las nuevas réplicas del grupo de consultas se hidratarían dos veces, lo que generaría una hidratación redundante. Al realizar una operación de escalado horizontal posterior, es importante tener en cuenta:
Realice una sincronización antes de la operación de escalado horizontal para evitar la hidratación redundante de las réplicas agregadas. No se permiten operaciones simultáneas de sincronización y escalabilidad horizontal.
Al automatizar las operaciones de procesamiento y escalado horizontal, es importante procesar primero los datos en el servidor principal, luego realizar una sincronización y, por último, realizar la operación de escalado horizontal. Esta secuencia garantiza un impacto mínimo en los recursos de memoria y QPU.
Durante las operaciones de escalabilidad horizontal, todos los servidores del grupo de consultas, incluido el servidor principal, están sin conexión temporalmente.
Se permite la sincronización aun cuando no haya réplicas en el grupo de consultas. Si está escalando de cero a una o más réplicas con nuevos datos de una operación de procesamiento en el servidor primario, realice la sincronización primero sin réplicas en el grupo de consultas, y luego, realice la escalabilidad horizontal. La sincronización antes del escalado horizontal evita la hidratación redundante de las réplicas recién agregadas.
Cuando se elimina una base de datos modelo del servidor primario, no se elimina automáticamente de las réplicas en el grupo de consulta. Debe realizar una operación de sincronización mediante el comando de PowerShell Sync-AzAnalysisServicesInstance que quita los archivos de esa base de datos de la ubicación de Blob Storage compartida de la réplica y luego elimina la base de datos de modelo en las réplicas del grupo de consultas. Para determinar si existe una base de datos de modelo en las réplicas del grupo de consultas, pero no en el servidor principal, asegúrese de que la opción Separar el servidor de procesamiento del grupo de consultas esté establecida en Sí. A continuación, utilice SQL Server Management Studio (SSMS) para conectarse al servidor primario utilizando el calificador
:rwpara ver si la base de datos existe. Después conéctese a las réplicas del grupo de consultas sin el calificador:rwpara ver si también existe la misma base de datos. Si la base de datos existe en las réplicas del grupo de consultas pero no en el servidor principal, ejecute una operación de sincronización.Cuando se cambia el nombre de una base de datos en el servidor primario, hay otro paso necesario para garantizar que la base de datos se sincroniza correctamente con las réplicas. Después de cambiar el nombre, realice una sincronización con el comando Sync-AzAnalysisServicesInstance especificando el parámetro
-Databasecon el nombre antiguo de la base de datos. Esta sincronización quita la base de datos y los archivos con el nombre antiguo de las réplicas. Luego realice otra sincronización especificando el parámetro-Databasecon el nuevo nombre de la base de datos. La segunda sincronización copia la base de datos con el nombre nuevo en el segundo conjunto de archivos e hidrata las réplicas. Estas sincronizaciones no pueden realizarse mediante el comando Sincronizar modelo del portal.
Modo de sincronización
De forma predeterminada, las réplicas de consultas se rehidratan en su totalidad, no de forma incremental. La rehidratación tiene lugar en fases. Las réplicas se desasocian y se asocian de dos en dos (suponiendo que haya al menos tres réplicas) para garantizar que, en un momento dado, hay al menos una réplica que se mantiene en línea para las consultas. En algunos casos, es posible que los clientes necesiten volver a conectarse a una de las réplicas en línea mientras se está llevando a cabo este proceso. Con la opción ReplicaSyncMode, ahora puede especificar que la sincronización de réplicas de consulta se realice en paralelo. La sincronización paralela brinda las siguientes ventajas:
- Una reducción significativa del tiempo de sincronización.
- Es más fácil que los datos de las diferentes réplicas mantengan la coherencia durante el proceso de sincronización.
- Dado que las bases de datos se mantienen en línea en todas las réplicas a lo largo del proceso de sincronización, los usuarios no necesitan volver a conectarse.
- La caché en memoria se actualiza de forma incremental exclusivamente con los datos modificados, lo que puede ser más rápido que rehidratar por completo el modelo.
Opción ReplicaSyncMode
Utilice SSMS para configurar ReplicaSyncMode en Propiedades avanzadas. Los valores posibles son:
-
1(valor predeterminado): rehidratación de la base de datos de réplica completa en fases (incremental). -
2: sincronización optimizada en paralelo.
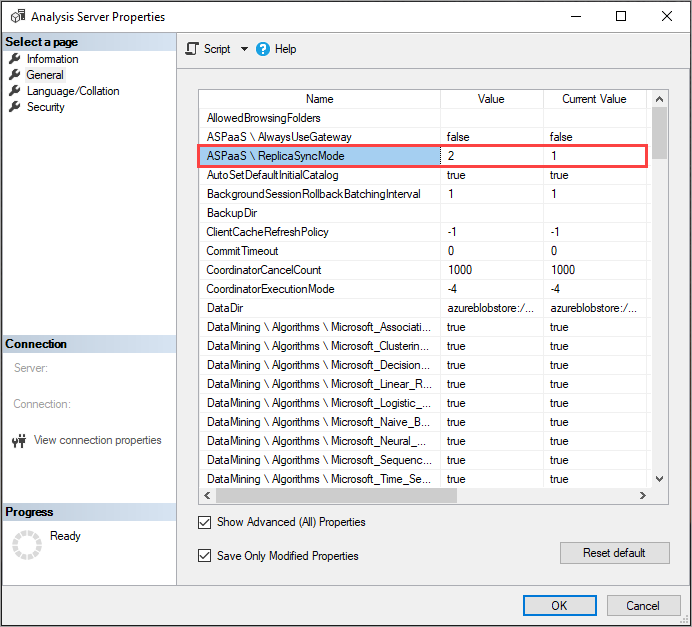
Cuando se establece ReplicaSyncMode=2, dependiendo de la cantidad de caché que deba actualizarse, las réplicas de consulta pueden consumir más memoria. Si desea mantener la base de datos en línea y disponible para las consultas, dependiendo de cuánto hayan cambiado los datos, la operación puede necesitar hasta el doble de memoria en la réplica, ya que se mantienen los dos segmentos (el nuevo y el antiguo) simultáneamente. Los nodos réplica tienen la misma asignación de memoria que el nodo primario, y normalmente hay memoria extra en el nodo primario para las operaciones de refrescamiento, por lo que es poco probable que las réplicas se queden sin memoria. Además, lo más habitual es que la base de datos se actualice incrementalmente en el nodo principal, por lo que pocas veces resulta necesario duplicar la memoria. Si la operación de sincronización se encuentra con un error de memoria agotada, vuelva a intentarlo utilizando la técnica predeterminada (conectar/desconectar de dos en dos).
Separar el procesamiento del grupo de consultas
Para obtener un rendimiento máximo para las operaciones de procesamiento y consulta, puede elegir separar el servidor de procesamiento del grupo de consultas. Cuando están separadas, las conexiones de cliente nuevas se asignan a réplicas de consulta del grupo de consultas únicamente. Si las operaciones de procesamiento solo ocupan un breve período de tiempo, puede elegir separar el servidor de procesamiento del grupo de consultas solo durante el tiempo que se tarda en realizar las operaciones de procesamiento y sincronización y, a continuación, volver a incluirlo en el grupo de consultas. Separar el servidor de procesamiento del grupo de consultas o agregarlo de nuevo al grupo de consultas puede tardar hasta cinco minutos en completarse la operación.
Supervisión del uso de QPU
Para determinar si es necesaria la escalabilidad horizontal de su servidor, supervise las métricas de su servidor en Microsoft Azure Portal. Si se supera el nivel máximo de QPU con regularidad, significa que el número de consultas en los modelos excede el límite de QPU del plan. La métrica de longitud de la cola de trabajos del grupo de consultas también aumenta si el número de consultas de la cola del grupo de subprocesos de consulta excede el número de QPU disponibles.
Otra buena métrica para inspeccionar es QPU media por ServerResourceType. Esta métrica compara el promedio de la unidad de procesamiento de consultas (QPU) del servidor principal con el grupo de consultas.
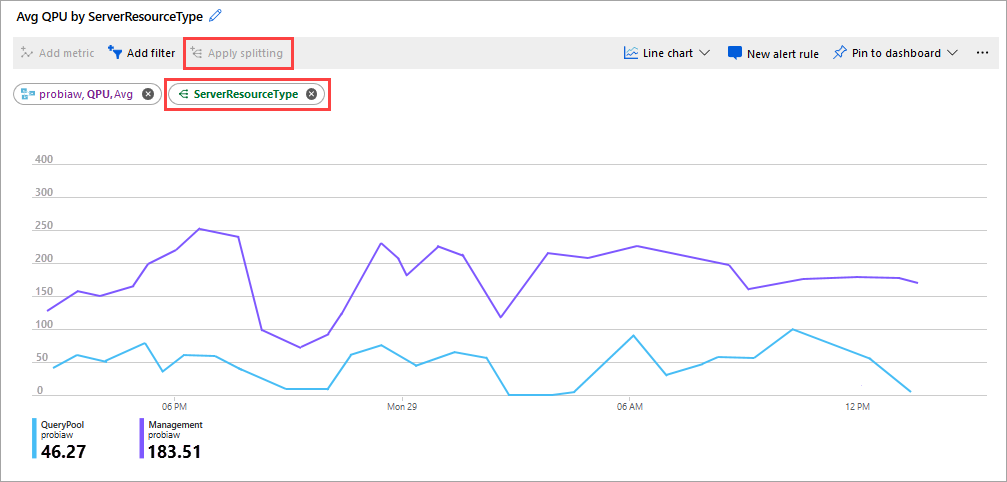
Para configurar la QPU mediante ServerResourceType
- En un gráfico de líneas Métricas, haga clic en Agregar métrica.
- En RECURSO, seleccione el servidor y, en ESPACIO DE NOMBRES DE MÉTRICA, seleccione Métricas estándar de Analysis Services; luego, en MÉTRICA, seleccione QPU y, en AGREGACIÓN, seleccione Media.
- Haga clic en Aplicar separación.
- En VALORES, seleccione ServerResourceType.
Registros de diagnóstico detallados
Utilice Azure Monitor Logs para realizar diagnósticos más detallados de los recursos del servidor con escala horizontal. Con los registros, puede usar consultas de Log Analytics para desglosar la QPU y la memoria en función de cada servidor y cada réplica. Para obtener más información, consulte Analizar registros en el área de trabajo Log Analytics. Para ver consultas de ejemplo, consulte Consultas de Kusto de ejemplo.
Configuración de la escalabilidad horizontal
En Azure Portal
En Azure Portal, haga clic en Escalabilidad horizontal. Utilice el control deslizante para seleccionar el número de servidores de réplica de consulta. El número de réplicas elegido se suma al servidor existente.
En Separar el servidor de procesamiento del grupo de consultas, seleccione Sí para excluir el servidor de procesamiento de los servidores de consulta. Las conexiones de cliente mediante la cadena de conexión predeterminada (sin
:rw) se redirigen a las réplicas del grupo de consultas.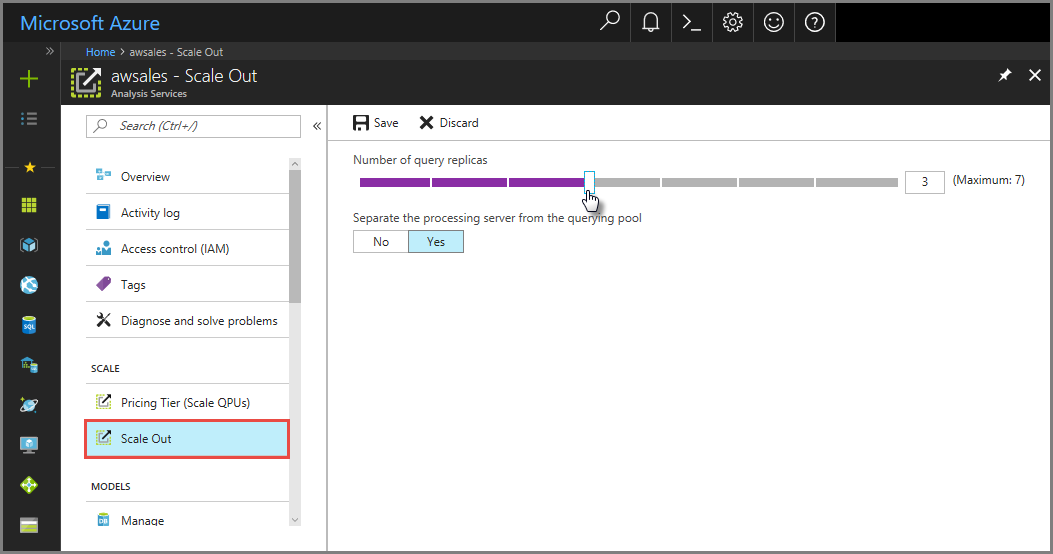
Haga clic en Guardar para aprovisionar los nuevos servidores de réplica de consulta.
Cuando se configura la escalabilidad horizontal de un servidor por primera vez, los modelos del servidor primario se sincronizan automáticamente con las réplicas del grupo de consulta. La sincronización automática solo se produce una vez, cuando se configura el escalado horizontal en una o más réplicas por primera vez. Los cambios posteriores en el número de réplicas en el mismo servidor no activan otra sincronización automática. La sincronización automática no vuelve a producirse aunque se configure el servidor a cero réplicas y luego se vuelva a escalar a cualquier número de réplicas.
Sincronizar
Las operaciones de sincronización deben realizarse manualmente o mediante la API de REST.
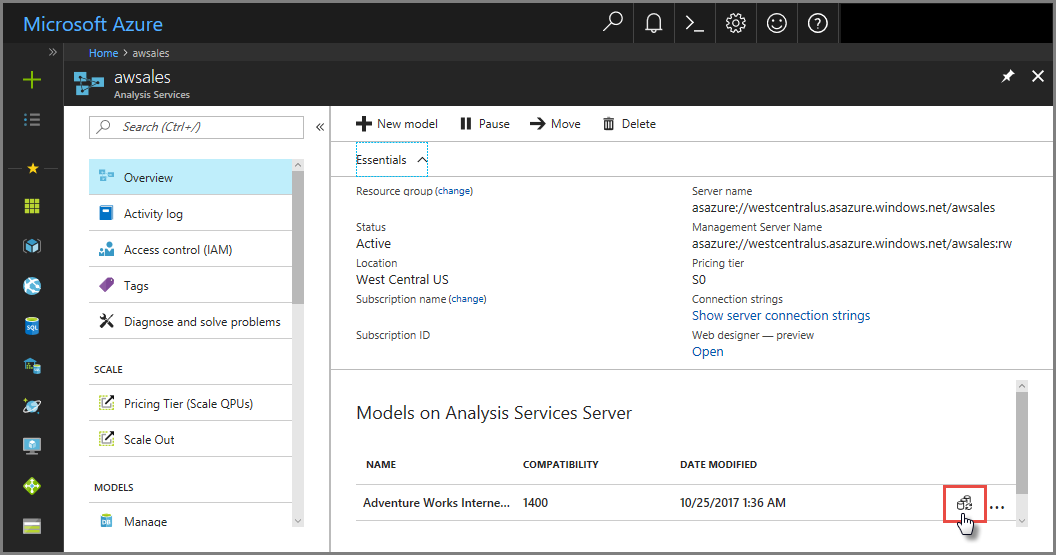
En Azure Portal
En Información general> modelo >Sincronizar el modelo.
REST API
Use la operación sync.
Sincronización de un modelo
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Obtención del estado de sincronización
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Códigos de estado devueltos:
| Código | Descripción |
|---|---|
| -1 | No válida |
| 0 | Replicando |
| 1 | Rehidratando |
| 2 | Completado |
| 3 | Con errores |
| 4 | Finalizando |
PowerShell
Nota:
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Para comenzar, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Antes de usar PowerShell, instale o actualice la última versión del módulo de Azure PowerShell.
Para ejecutar la sincronización, use Sync-AzAnalysisServicesInstance.
Para establecer el número de réplicas de consulta, use Set-AzAnalysisServicesServer. Especifique el parámetro opcional -ReadonlyReplicaCount.
Para separar el servidor de procesamiento del grupo de consultas, use Set-AzAnalysisServicesServer. Especifique el parámetro opcional -DefaultConnectionMode para usar Readonly.
Para obtener más información, vea Uso de una entidad de servicio con el módulo Az.AnalysisServices.
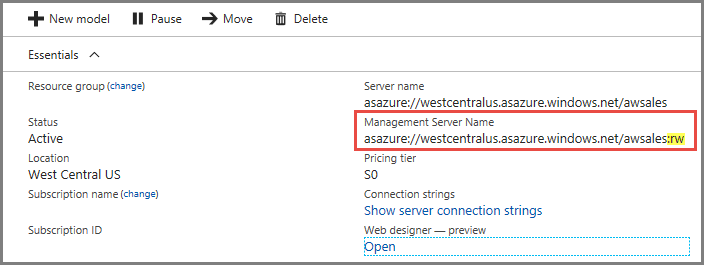
Conexiones
En la página de información general del servidor, hay dos nombres de servidor. Si aún no ha configurado la escalabilidad horizontal de un servidor, los dos nombres de servidor funcionan igual. Una vez configurada la escalabilidad horizontal de un servidor, debe especificar el nombre de servidor adecuado según el tipo de conexión.
Para las conexiones de cliente para el usuario final como Power BI Desktop, Excel y aplicaciones personalizadas, utilice Nombre del servidor.
Para SSMS, Visual Studio y cadenas de conexión en PowerShell, las aplicaciones de Azure Functions y AMO usan el nombre del servidor de administración. El nombre del servidor de administración incluye un calificador especial :rw (lectura y escritura). Todas las operaciones de procesamiento se producen en el servidor de administración (principal).
Escalado y reducción verticales frente a Escalado horizontal
Puede cambiar el plan de tarifa en un servidor con varias réplicas. El mismo plan de tarifa se aplica a todas las réplicas. Una operación de escalado primero baja todas las réplicas a la vez y luego sube todas las réplicas en el nuevo nivel de precios.
Solución de problemas
Problema: los usuarios obtienen el error no se puede encontrar el servidor "<Nombre del servidor>" instancia en el modo de conexión "ReadOnly".
Solución: al seleccionar la opción Separar el servidor de procesamiento del grupo de consultas, las conexiones del cliente que usan la cadena de conexión predeterminada (sin :rw) se redirigen a las réplicas del grupo de consultas. Si las réplicas del conjunto de consultas aún no están en línea porque la sincronización aún no se ha completado, las conexiones de cliente redirigidas pueden fallar. Para evitar errores de conexión, debe haber al menos dos servidores en el grupo de consultas al realizar una sincronización. Cada servidor se sincroniza individualmente mientras que otros siguen en línea. Si decide no incluir el servidor de procesamiento en el grupo de consultas durante el procesamiento, puede quitarlo del grupo para el procesamiento y agregarlo de nuevo una vez completado el procesamiento, pero antes de la sincronización. Use las métricas de memoria y QPU para supervisar el estado de sincronización.
Información relacionada
Supervisar Azure Analysis ServicesAdministrar Azure Analysis Services