Tutorial, Parte 3: Evaluación de una aplicación de chat personalizada con el SDK de Azure AI Foundry
En este tutorial, usará el SDK de Azure AI (y otras bibliotecas) para evaluar la aplicación de chat que creó en la Parte 2 de la serie de tutoriales. En esta parte tres, aprenderá a:
- Creación de un conjunto de datos de evaluación
- Evaluación de la aplicación de chat con evaluadores de Azure AI
- Iteración y mejora de la aplicación
Este tutorial es la tercera parte de un tutorial de tres partes.
Requisitos previos
- Complete la parte 2 de la serie de tutoriales para compilar la aplicación de chat.
- Asegúrese de que ha completado los pasos para agregar el registro de telemetría de la parte 2.
Evaluar la calidad de las respuestas de la aplicación de chat
Ahora que sabe que la aplicación de chat responde bien a las consultas, incluido el historial de chats, es el momento de evaluar cómo funciona en algunas métricas diferentes y más datos.
Use un evaluador con un conjunto de datos de evaluación y la función de destino get_chat_response() y luego evalúe los resultados de la evaluación.
Una vez que ejecute una evaluación, puede realizar mejoras en la lógica, como mejorar la solicitud del sistema y observar cómo cambian y mejoran las respuestas de la aplicación de chat.
Creación de un conjunto de datos de evaluación
Use el siguiente conjunto de datos de evaluación, que contiene preguntas de ejemplo y respuestas esperadas (verdad).
Cree un archivo denominado chat_eval_data.jsonl en la carpeta recursos.
Pegue este conjunto de datos en el archivo:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Evaluación con los evaluadores de Azure AI
Ahora defina un script de evaluación que:
- Genere un contenedor de funciones de destino alrededor de la lógica de la aplicación de chat.
- Cargue el conjunto de datos de
.jsonlde ejemplo. - Ejecute la evaluación, que toma la función de destino y combina el conjunto de datos de evaluación con las respuestas de la aplicación de chat.
- Genere un conjunto de métricas asistidas por GPT (relevancia, base y coherencia) para evaluar la calidad de las respuestas de la aplica de chat.
- Genera los resultados localmente y registra los resultados en el proyecto en la nube.
El script permite revisar los resultados localmente, mediante la salida de los resultados en la línea de comandos y en un archivo JSON.
El script también registra los resultados de evaluación en el proyecto en la nube para poder comparar las ejecuciones de evaluación en la interfaz de usuario.
Cree un archivo denominado evaluate.py en la carpeta principal.
Agregue el código siguiente para importar las bibliotecas necesarias, cree un cliente de proyecto y configure algunas opciones:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Agregue código para crear una función contenedora que implemente la interfaz de evaluación para la evaluación de consultas y respuestas:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Por último, agregue código para ejecutar la evaluación, ver los resultados localmente y obtener un vínculo a los resultados de evaluación en el portal de Azure AI Foundry:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Configuración del modelo de evaluación
Dado que el script de evaluación llama al modelo muchas veces, es posible que desee aumentar el número de tokens por minuto para el modelo de evaluación.
En la parte 1 de esta serie de tutoriales, creó un archivo .env en el que se especifica el nombre del modelo de evaluación, gpt-4o-mini. Intente aumentar el límite de tokens por minuto para este modelo, si tiene cuota disponible. Si no tiene suficiente cuota para aumentar el valor, no se preocupe. El script está diseñado para controlar los errores de límite.
- En el proyecto de Azure AI Foundry, seleccione Modelos y puntos de conexión.
- Seleccione gpt-4o-mini.
- Seleccione Editar.
- Si tiene cuota para aumentar el límite de velocidad de tokens por minuto, intente aumentarlo a 30.
- Seleccione Guardar y cerrar.
Ejecución del script de evaluación
Desde la consola, inicie sesión en su cuenta de Azure con la CLI de Azure:
az loginInstale el paquete necesario:
pip install azure-ai-evaluation[remote]Ahora ejecute el script de evaluación:
python evaluate.py
Interpretación de la salida de evaluación
En la salida de la consola, verá una respuesta para cada pregunta, seguida de una tabla con métricas resumidas. (Es posible que vea columnas diferentes en la salida).
Si no pudo aumentar el límite de tokens por minuto del modelo, es posible que vea algunos errores de tiempo de espera, que se prevén. El script de evaluación está diseñado para controlar estos errores y continuar con la ejecución.
Nota:
Es posible que vea muchos WARNING:opentelemetry.attributes:: se pueden omitir de forma segura y no afectan a los resultados de la evaluación.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Visualización de los resultados de evaluación en el portal de Azure AI Foundry
Una vez completada la ejecución de la evaluación, siga el vínculo para ver los resultados de la evaluación en la página Evaluación en el portal de Azure AI Foundry.
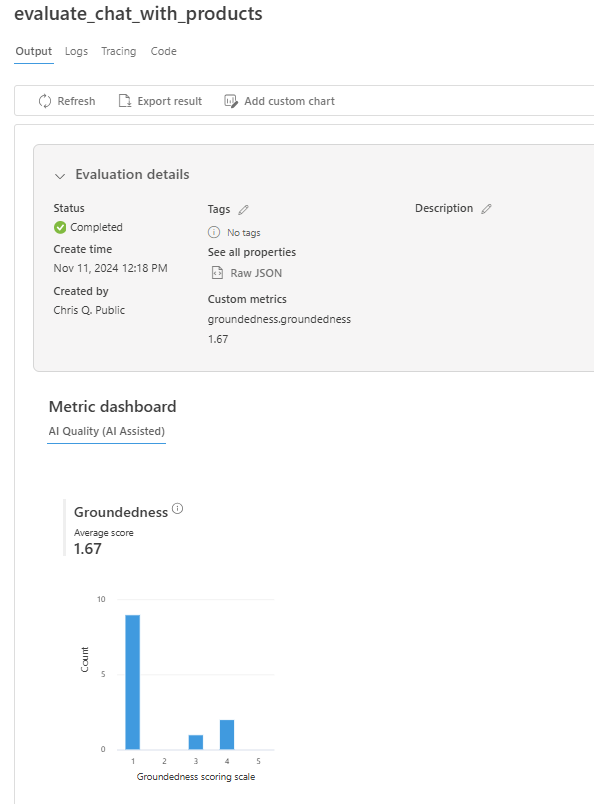
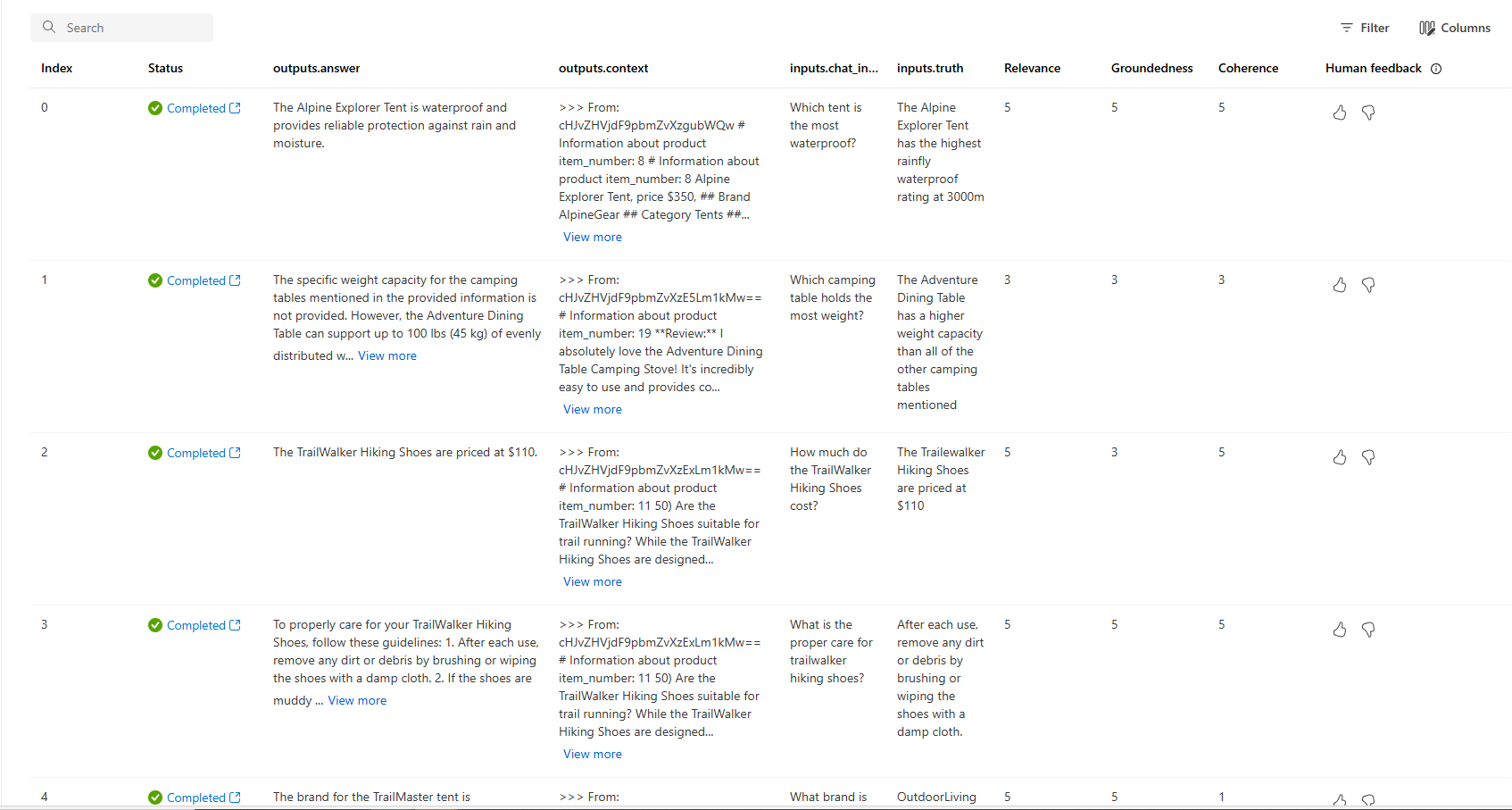
También puede ver las filas individuales, las puntuaciones de métricas por fila, el contexto o los documentos completos que se recuperaron. Estas métricas pueden ser útiles para interpretar y depurar los resultados de la evaluación.
Para obtener más información sobre los resultados de evaluación en el portal de Azure AI Foundry, consulte Visualización de los resultados de evaluación en el portal de Azure AI Foundry.
Iteración y mejora
Observe que las respuestas no están bien fundamentadas. En muchos casos, el modelo responde con preguntas en lugar de dar respuestas. Este es el resultado de las instrucciones de la plantilla de indicación.
- En el archivo assets/grounded_chat.prompty, busque la frase "En caso de que la pregunta esté relacionada con equipo y ropa para actividades al aire libre o camping, pero sea vaga, hacer preguntas aclaratorias en lugar de referenciar a documentos".
- Cambie la frase a "En caso de que la pregunta esté relacionada con equipo y ropa para actividades al aire libre o camping, pero sea vaga, responder en función de los documentos de referencia y, a continuación, hacer preguntas aclaratorias".
- Guarde el archivo y vuelva a ejecutar el script de evaluación.
Pruebe otras modificaciones en la plantilla de indicación o pruebe modelos diferentes para ver cómo afectan los cambios a los resultados de la evaluación.
Limpieza de recursos
Para evitar incurrir en costos innecesarios de Azure, debe eliminar los recursos que creó en este tutorial si ya no son necesarios. Para administrar recursos, puede usar Azure Portal.