Evaluación de aplicaciones y modelos de IA generativa con Azure AI Foundry
Para evaluar exhaustivamente el rendimiento de los modelos y aplicaciones de IA generativa cuando se aplica a un conjunto de datos sustancial, puede iniciar un proceso de evaluación. Durante esta evaluación, la aplicación o el modelo se prueban con el conjunto de datos determinado y su rendimiento se mide cuantitativamente con métricas basadas en principios matemáticos y métricas asistidas por IA. Esta ejecución de evaluación proporciona información completa sobre las funcionalidades y limitaciones de la aplicación.
Para llevar a cabo esta evaluación, puede utilizar la funcionalidad de evaluación en Azure AI Foundry, una plataforma completa que ofrece herramientas y características para evaluar el rendimiento y la seguridad del modelo de IA generativa. En el portal de Azure AI Foundry, puede registrar, ver y analizar métricas de evaluación detalladas.
En este artículo, aprenderá a crear una ejecución de evaluación contra un modelo, un conjunto de datos de prueba o un flujo utilizando métricas de evaluación integradas desde la interfaz de usuario de Azure AI Foundry. Para mayor flexibilidad, puede establecer un flujo de evaluación personalizado y emplear la característica de evaluación personalizada. Alternativamente, si el objetivo es realizar únicamente una ejecución por lotes sin ninguna evaluación, también puede usar la característica de evaluación personalizada.
Requisitos previos
Para ejecutar una evaluación con métricas asistidas por IA, debe tener lo siguiente listo:
- Un conjunto de datos de prueba en uno de estos formatos:
csvojsonl. - Una conexión de Azure OpenAI. Una implementación de uno de estos modelos: modelos GPT 3.5, modelos GPT 4 o modelos Davinci. Solo es necesario cuando se ejecuta la evaluación de calidad asistida por IA.
Creación de una evaluación con métricas de evaluación integradas
Una ejecución de evaluación permite generar salidas de métricas para cada fila de datos del conjunto de datos de prueba. Puede elegir una o varias métricas de evaluación para evaluar la salida desde diferentes aspectos. Puede crear una ejecución de evaluación desde las páginas de evaluación, catálogo de modelos o flujo de avisos en el portal de Azure AI Foundry. A continuación, aparecerá el asistente para la creación de evaluaciones para guiarlo por el proceso de configuración de una ejecución de evaluación.
Desde la página de evaluación
En el menú izquierdo contraíble, seleccione Evaluación>+ Crear una nueva evaluación.

Desde la página del catálogo de modelos
En el menú izquierdo contraíble, seleccione Catálogo de modelos> vaya al modelo específico> vaya a la pestaña de pruebas comparativas > Probar con sus propios datos. Se abre el panel de evaluación de modelos para que cree una ejecución de evaluación contra el modelo seleccionado.

Desde la página de flujo
En el menú izquierdo contraíble, seleccione Flujo de avisos>Evaluar>Evaluación automatizada.

Destino de evaluación
Al iniciar una evaluación desde la página de evaluación, primero debe decidir cuál es el destino de evaluación. Al especificar el destino de evaluación adecuado, podemos adaptar la evaluación a la naturaleza específica de la aplicación, lo que garantiza métricas precisas y pertinentes. Se admiten tres tipos de destinos de evaluación:
- Modelo e indicación: quiere evaluar la salida generada por el modelo seleccionado y la indicación definida por el usuario.
- Conjunto de datos: ya tiene los resultados generados por el modelo en un conjunto de datos de prueba.
- Flujo de avisos: ha creado un flujo y desea evaluar la salida del flujo.

Evaluación del conjunto de datos o del flujo de avisos
Al escribir entrar en el Asistente para la creación de evaluaciones, puede proporcionar un nombre opcional para la ejecución de evaluación. Actualmente se ofrece compatibilidad con el escenario de consultas y respuestas, que está diseñado para aplicaciones relacionadas con responder a consultas de usuarios y proporcionar respuestas con o sin información de contexto.
Opcionalmente, puede agregar descripciones y etiquetas a las ejecuciones de evaluación para mejorar la organización, el contexto y la facilidad de recuperación.
También puede usar el panel de ayuda para consultar las preguntas más frecuentes y guiarse a través del asistente.

Si va a evaluar un flujo de avisos, puede seleccionar el flujo que se va a evaluar. Si inicia la evaluación desde la página Flujo, seleccionaremos automáticamente el flujo para evaluarlo. Si piensa evaluar otro flujo, puede seleccionar uno diferente. Es importante tener en cuenta que, dentro de un flujo, es posible que tenga varios nodos, cada uno de los cuales podría tener su propio conjunto de variantes. En tales casos, debe especificar el nodo y las variantes que desea evaluar durante el proceso de evaluación.

Configurar los datos de prueba
Puede seleccionar entre conjuntos de datos preexistentes o cargar un nuevo conjunto de datos específicamente para su evaluación. El conjunto de datos de prueba debe tener las salidas generadas por el modelo que se van a usar para la evaluación si no hay ningún flujo seleccionado en el paso anterior.
Elija el conjunto de datos existente: puede elegir el conjunto de datos de prueba de la colección de conjuntos de datos establecida.
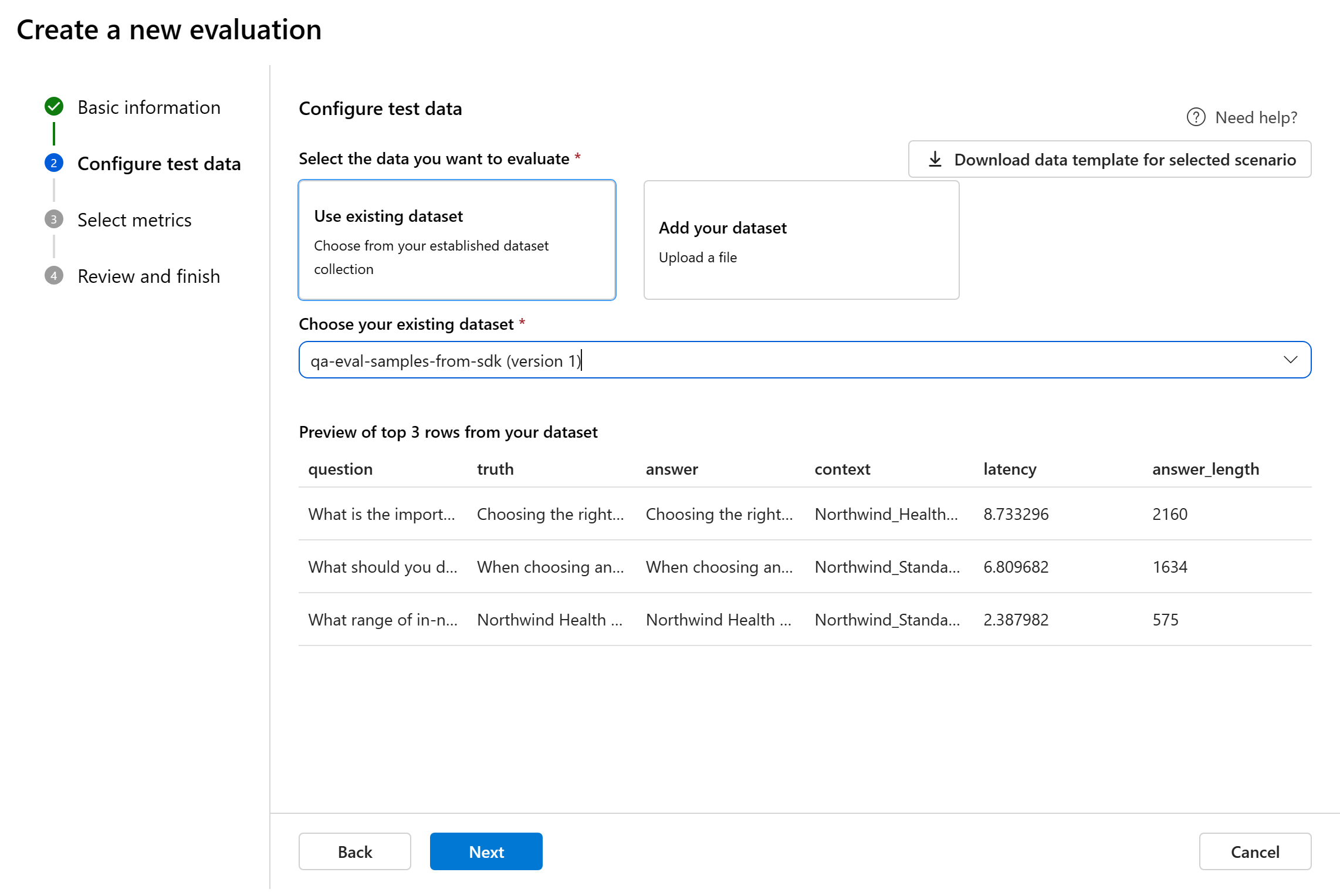
Agregar nuevo conjunto de datos: puede cargar archivos desde el almacenamiento local. Solo se admiten formatos de archivo
.csvy.jsonl.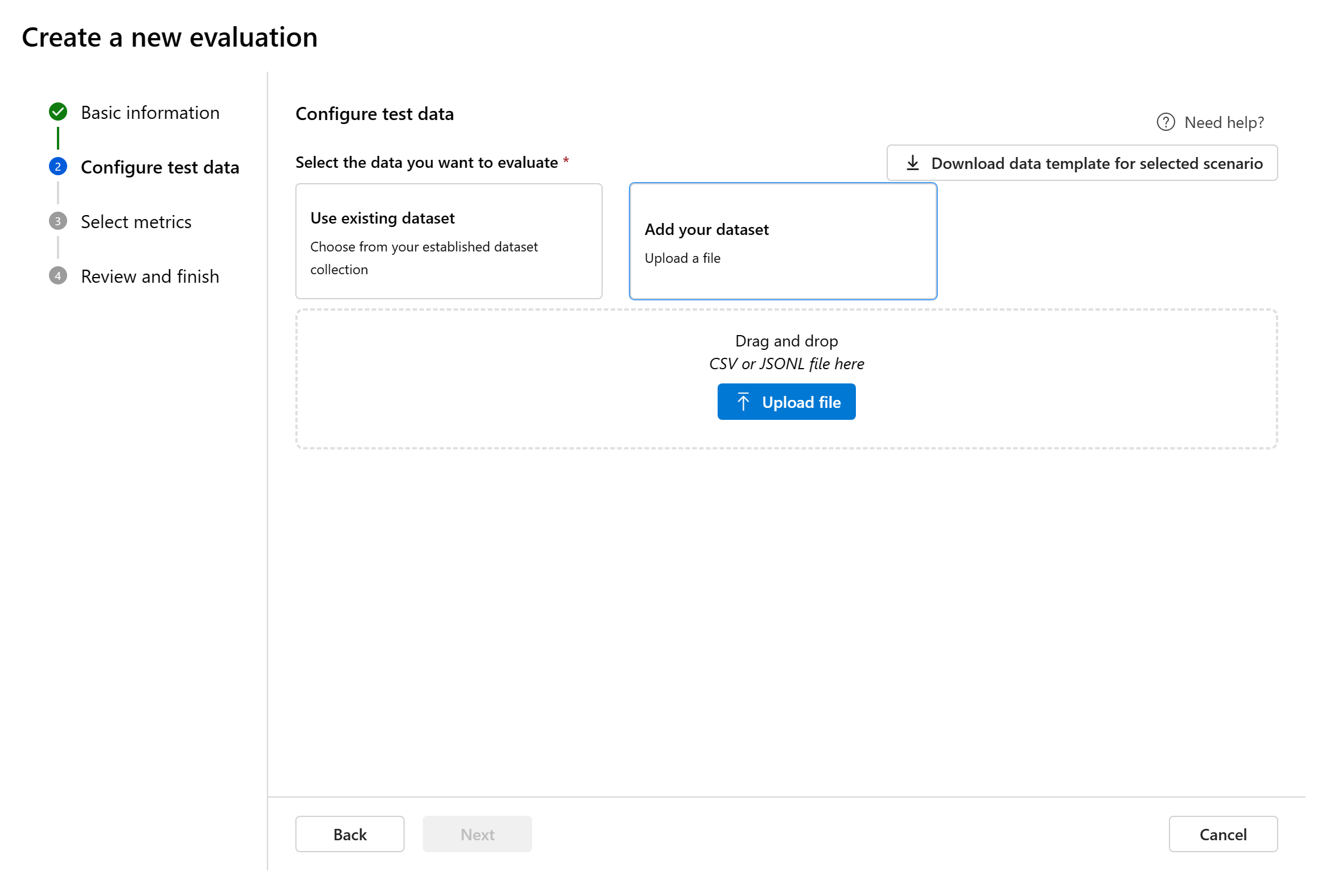
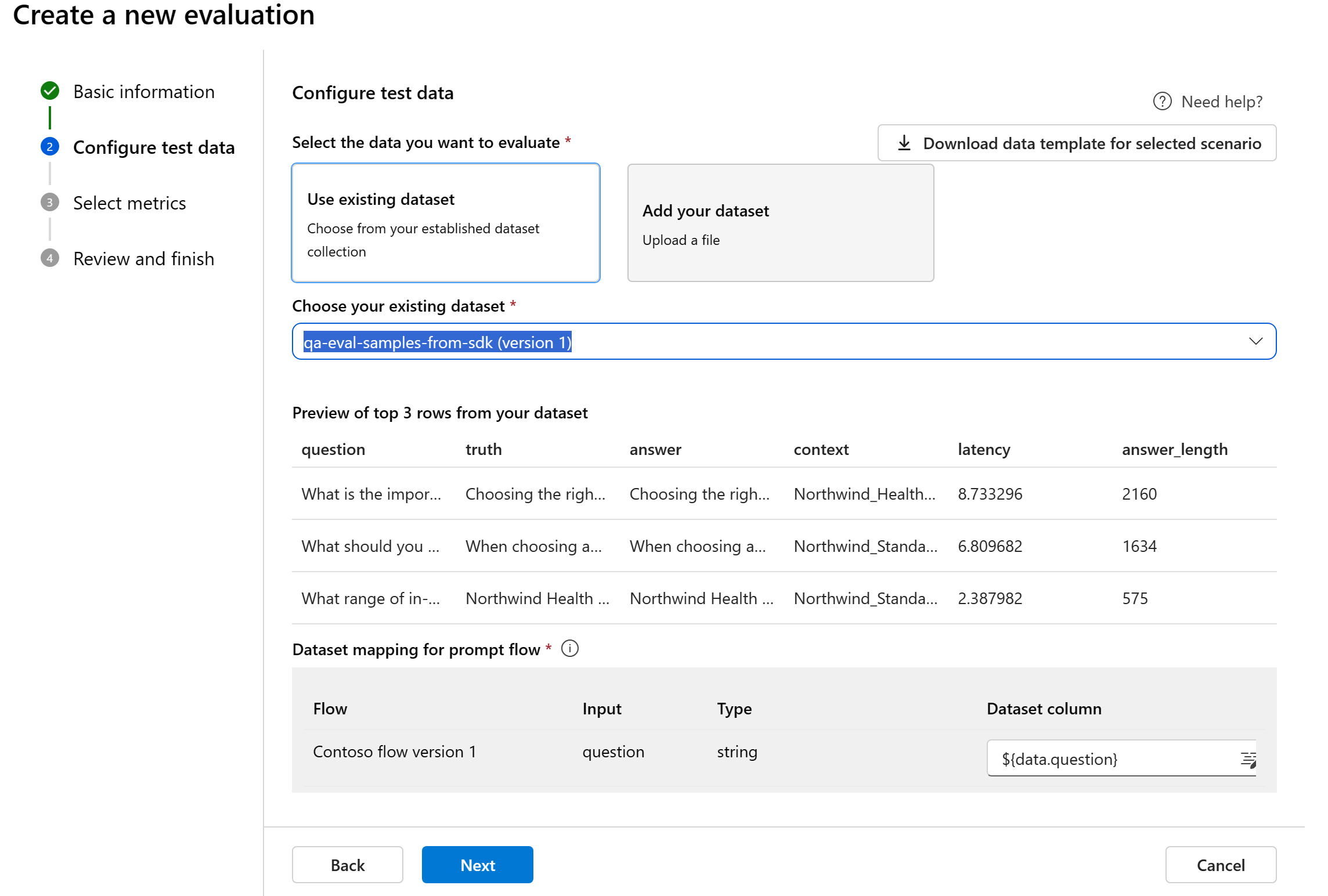
Asignación de datos para el flujo: si selecciona un flujo que se va a evaluar, asegúrese de que las columnas de datos están configuradas para alinearse con las entradas necesarias para que el flujo ejecute una ejecución por lotes, generando la salida para la evaluación. A continuación, la evaluación se llevará a cabo mediante la salida del flujo. Posteriormente, configure la asignación de datos para las entradas de evaluación en el paso siguiente.



Seleccionar métricas
Se admiten tres tipos de métricas mantenidas por Microsoft para facilitar una evaluación completa de la aplicación:
- Calidad de IA (asistida por IA): estas métricas evalúan la calidad general y la coherencia del contenido generado. Para ejecutar estas métricas, es necesaria una implementación de modelo como juez.
- Calidad de IA (NLP): estas métricas de NLP se basan en principios matemáticos y también evalúan la calidad general del contenido generado. A menudo requieren datos de verdad básica, pero no requieren la implementación de modelo como juez.
- Métricas de riesgo y seguridad: Estas métricas se centran en identificar posibles riesgos de contenido y garantizar la seguridad del contenido generado.

Puede consultar la tabla para obtener la lista completa de métricas para las que ofrecemos compatibilidad en cada escenario. Para obtener información más detallada sobre cada definición de métrica y cómo se calcula, consulte Métricas de evaluación y supervisión.
| Calidad de IA (asistida por IA) | Calidad de IA (NLP) | Métricas de riesgo y seguridad |
|---|---|---|
| Base, relevancia, coherencia, fluidez, similitud de GPT | Puntuación F1, Puntuación ROUGE, Puntuación BLEU, Puntuación GLEU, Puntuación METEOR | Contenido relacionado con autolesiones, Contenido de odio e injusto, Contenido violento, Contenido sexual, Material protegido, Ataque indirecto |
Al ejecutar evaluaciones de la calidad asistida por IA, debe especificar un modelo GPT para el proceso de cálculo. Elija una conexión de Azure OpenAI y una implementación con GPT-3.5, GPT-4 o el modelo Davinci para nuestros cálculos.

Las métricas de calidad de IA (NLP) son medidas basadas en principios matemáticos que evalúan el rendimiento de una aplicación. A menudo requieren datos de verdad básica para el cálculo. ROUGE es una familia de métricas. Puede seleccionar el tipo ROUGE para calcular las puntuaciones. Varios tipos de métricas ROUGE ofrecen distintas formas de evaluar la calidad de la generación de texto. ROUGE-N mide la superposición de n-gramas entre los textos candidato y de referencia.

En el caso de las métricas de riesgo y seguridad, no es necesario proporcionar una conexión e implementación. La evaluación de seguridad de Azure AI Foundry aprovisiona un modelo GPT-4 que puede generar puntuaciones de gravedad de riesgo de contenido y razonamiento para permitirle evaluar la aplicación por daños en el contenido.
Puede establecer el umbral para calcular la tasa de defectos de las métricas de daño de contenido (contenido relacionado con autolesiones, contenido de odio e injusto, contenido violento, contenido sexual). La tasa de defectos se calcula tomando un porcentaje de instancias con niveles de gravedad (Muy bajo, Bajo, Medio, Alto) por encima de un umbral. De forma predeterminada, establecemos el umbral como "Medio".
Para el material protegido y el ataque indirecto, la tasa de defectos se calcula tomando un porcentaje de instancias donde la salida es "true" (Tasa de defectos = (#trues / #instances) × 100).

Nota:
Las métricas de seguridad y riesgo asistidos por IA se hospedan en el servicio back-end de evaluaciones de seguridad de Azure AI Foundry y solo están disponibles en las siguientes regiones: Este de EE. UU. 2, Centro de Francia, Sur de Reino Unido, Centro de Suecia
Asignación de datos para la evaluación: debe especificar qué columnas de datos del conjunto de datos corresponden a las entradas necesarias en la evaluación. Las diferentes métricas de evaluación exigen distintos tipos de entradas de datos para cálculos precisos.

Nota:
Si va a realizar la evaluación a partir de datos, la "respuesta" debe asignarse a la columna de respuesta del conjunto de datos ${data$response}. Si va a realizar la evaluación a partir del flujo, la "respuesta" debe proceder de la salida del flujo ${run.outputs.response}.
Para obtener instrucciones sobre los requisitos de asignación de datos específicos para cada métrica, consulte la información proporcionada en la tabla:
Requisitos de métricas de consultas y respuestas
| Métrica | Consultar | Respuesta | Context | Cierto |
|---|---|---|---|---|
| Base | Obligatorio: Str | Obligatorio: Str | Obligatorio: Str | N/D |
| Coherencia | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
| Fluidez | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
| Relevancia | Obligatorio: Str | Obligatorio: Str | Obligatorio: Str | N/D |
| Similitud de GPT | Obligatorio: Str | Obligatorio: Str | N/D | Obligatorio: Str |
| Puntuación F1 | N/D | Obligatorio: Str | N/D | Obligatorio: Str |
| Puntuación BLEU | N/D | Obligatorio: Str | N/D | Obligatorio: Str |
| Puntuación de GLEU | N/D | Obligatorio: Str | N/D | Obligatorio: Str |
| Puntuación de METEOR | N/D | Obligatorio: Str | N/D | Obligatorio: Str |
| Puntuación de ROUGE | N/D | Obligatorio: Str | N/D | Obligatorio: Str |
| Contenido relacionado con autolesiones | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
| Contenido injusto y de odio | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
| Contenido violento | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
| Contenido sexual | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
| Material protegido | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
| Ataque indirecto | Obligatorio: Str | Obligatorio: Str | N/D | N/D |
- Consulta: búsqueda de información específica.
- Respuesta: el resultado de la consulta generada por el modelo.
- Contexto: el origen con respecto al cual se genera la respuesta (es decir, los documentos de base).
- Verdad de base: la respuesta a la consulta generada por el usuario/humano como respuesta verdadera.
Revisar y finalizar
Después de completar todas las configuraciones necesarias, puede revisarlas y continuar seleccionando "Enviar" para enviar la ejecución de evaluación.

Evaluación de modelos e indicaciones
Para crear una nueva evaluación para la implementación de modelo seleccionada y una indicación definida, use el panel de evaluación de modelos simplificado. Esta interfaz simplificada le permite configurar e iniciar evaluaciones dentro de un único panel consolidado.
Información básica
Para empezar, puede configurar el nombre de la ejecución de evaluación. A continuación, seleccione la implementación de modelo que desea evaluar. Se admiten modelos de Azure OpenAI y otros modelos abiertos compatibles con modelos como servicio (MaaS), como la familia de modelos Meta Llama y Phi-3. Opcionalmente, puede ajustar los parámetros del modelo, como respuesta máxima, temperatura y top P según sus necesidades.
En el cuadro de texto Mensaje del sistema, proporcione la indicación para su escenario. Para más información sobre cómo crear la indicación, consulte el catálogo de indicaciones. Puede optar por agregar un ejemplo para mostrar al chat las respuestas que desea. Habrá un intento por imitar las respuestas que agregue aquí para asegurarse de que coinciden con las reglas que ha establecido en el mensaje del sistema.

Configurar datos de prueba
Después de configurar el modelo y la indicación, configure el conjunto de datos de prueba que se usará para la evaluación. Este conjunto de datos se enviará al modelo para generar respuestas para la evaluación. Tiene tres opciones para configurar los datos de prueba:
- Generación de datos de ejemplo
- Usar el conjunto de datos existente
- Agregar un conjunto de datos
Si no tiene un conjunto de datos disponible y desea ejecutar una evaluación con una muestra pequeña, puede seleccionar la opción para usar un modelo GPT para generar preguntas de muestra basadas en el tema elegido. El tema ayuda a adaptar el contenido generado a su área de interés. Las consultas y respuestas se generarán en tiempo real y tendrá la opción de volver a generarlas según sea necesario.
Nota:
El conjunto de datos generado se guardará en el almacenamiento de blobs del proyecto una vez creada la ejecución de evaluación.

Asignación de datos
Si decide usar un conjunto de datos existente o cargar un nuevo conjunto de datos, deberá asignar las columnas del conjunto de datos a los campos necesarios para su evaluación. Durante la evaluación, la respuesta del modelo se evaluará con respecto a las entradas clave, como:
- Consulta: necesaria para todas las métricas
- Contexto: opcional.
- Verdad de base: opcional, necesaria para las métricas de calidad de IA (NLP)
Estas asignaciones garantizan una alineación precisa entre los datos y los criterios de evaluación.

Elección de las métricas de evaluación
El último paso es seleccionar lo que se quiere evaluar. En lugar de seleccionar métricas individuales y tener que familiarizarse con todas las opciones disponibles, simplificamos el proceso al permitirle seleccionar las categorías de métricas que mejor se adapten a sus necesidades. Al elegir una categoría, todas las métricas pertinentes de esa categoría se calcularán en función de las columnas de datos que proporcionó en el paso anterior. Una vez que seleccione las categorías de métricas, puede seleccionar "Crear" para enviar la ejecución de evaluación e ir a la página de evaluación para ver los resultados.
Se admiten tres categorías:
- Calidad de IA (asistida por IA): debe proporcionar una implementación de modelo de Azure OpenAI como juez para calcular las métricas asistidas por IA.
- Calidad de IA (NLP)
- Seguridad
| Calidad de IA (asistida por IA) | Calidad de IA (NLP) | Seguridad |
|---|---|---|
| Base (requerir contexto), Relevancia (requerir contexto), Coherencia, Fluidez | Puntuación F1, Puntuación ROUGE, Puntuación BLEU, Puntuación GLEU, Puntuación METEOR | Contenido relacionado con autolesiones, Contenido de odio e injusto, Contenido violento, Contenido sexual, Material protegido, Ataque indirecto |
Creación de una evaluación con un flujo de evaluación personalizado
Puede desarrollar sus propios métodos de evaluación:
En la página de flujos, en el menú izquierdo contraíble, seleccione Flujo de avisos>Evaluar>Evaluación personalizada.

Visualización y administración de los evaluadores en la biblioteca de evaluadores
La biblioteca de evaluadores es un lugar centralizado que le permite ver los detalles y el estado de los evaluadores. Puede ver y administrar evaluadores mantenidos por Microsoft.
Sugerencia
Puede usar evaluadores personalizados a través del SDK del flujo de avisos. Para obtener más información, consulteEvaluar con el SDK de flujo de mensajes.
La biblioteca de evaluadores también habilita la administración de versiones. Puede comparar diferentes versiones del trabajo, restaurar versiones anteriores si es necesario y colaborar con otros usuarios con mayor facilidad.
Para usar la biblioteca de evaluador en el portal de Azure AI Foundry, vaya a la página Evaluación del proyecto y seleccione la pestaña Biblioteca de evaluador.

Puede seleccionar el nombre del evaluador para ver más detalles. Puede ver el nombre, la descripción y los parámetros, así como comprobar los archivos asociados al evaluador. Estos son algunos ejemplos de evaluadores mantenidos por Microsoft:
- En el caso de los evaluadores de rendimiento y calidad mantenidos por Microsoft, puede ver la solicitud de anotación en la página de detalles. Puede adaptar estas indicaciones a su propio caso de uso cambiando los parámetros o criterios según sus datos y objetivos. Consulte el SDK de evaluación de Azure AI. Por ejemplo, puede seleccionar Groundedness-Evaluator y consultar el archivo Prompty que muestra cómo calculamos la métrica.
- Para los evaluadores de riesgos y seguridad mantenidos por Microsoft, puede ver la definición de las métricas. Por ejemplo, puede seleccionar Self-Harm-Related-Content-Evaluator y saber lo que significa y cómo Microsoft determina los distintos niveles de gravedad para esta métrica de seguridad.
Pasos siguientes
Obtenga más información sobre cómo evaluar las aplicaciones de IA generativa: