¿Qué es la diarización multicanal de transcripción de conversaciones? (versión preliminar)
Nota:
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin contrato de nivel de servicio y no es aconsejable usarla para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
La diarización multicanal de transcripción de conversaciones es una solución de conversión de voz en texto que proporciona transcripción asincrónica o en tiempo real de cualquier reunión. Esta característica combina el reconocimiento de voz, la identificación del hablante y la atribución de oraciones para determinar quién ha dicho qué y cuándo en una reunión.
Importante
La diarización multicanal de la transcripción de conversaciones (versión preliminar) será retirada el 28 de marzo de 2025. Para obtener más información sobre cómo migrar a otras características de conversión de voz en texto, consulte Migración de la diarización multicanal de transcripción de conversaciones.
Migración fuera de la diarización multicanal de transcripción de conversaciones
La diarización multicanal de transcripción de conversaciones (versión preliminar) se retirará el 28 de marzo de 2025.
Para seguir usando la conversión de voz en texto con diarización, use las siguientes características en su lugar:
- Conversión de voz en texto en tiempo real con diarización
- Transcripción rápida con diarización
- Transcripción por lotes con diarización
Estas características de conversión de voz en texto solo admiten la diarización para audio de un solo canal. No se admite el audio multicanal que usó con la diarización multicanal de transcripción de conversaciones.
Características principales
Es posible que encuentre útiles las siguientes características de transcripción de conversaciones:
- Marcas de tiempo: cada expresión del hablante tiene una marca de tiempo, por lo que puede encontrar fácilmente cuándo se dijo una frase.
- Transcripciones legibles: el formato y la puntuación de las transcripciones se agregan automáticamente para garantizar que el texto coincide lo más posible con lo que se ha dicho.
- Perfiles de usuario: los perfiles de usuario se generan mediante la recopilación de muestras de voz de usuarios y el envío de estas a la generación de firmas.
- Identificación del hablante: los hablantes se identifican mediante perfiles de usuario; a cada hablante se le asigna un identificador de hablante.
- Diarización de varios hablantes: determine quién dijo qué mediante la sintetización de la secuencia de audio con cada identificador de hablante.
- Transcripción en tiempo real: proporcione transcripciones en directo de quién dice qué y en qué momento mientras tiene lugar la reunión.
- Transcripción asincrónica: proporcione transcripciones con una mayor precisión mediante una secuencia de audio de varios canales.
Nota
Aunque la transcripción de conversaciones no impone un límite sobre el número de hablantes en la sala, está optimizada para entre 2 y 10 hablantes por sesión.
Casos de uso
Para que las reuniones sean inclusivas para todo el mundo, por ejemplo, para los participantes sordos y con dificultades auditivas, es importante contar con transcripción en tiempo real. La transcripción de conversaciones en tiempo real toma el audio de una reunión y determina quién dice qué, lo que permite a todos los participantes seguir la transcripción y participar en la reunión sin ningún retraso.
Los participantes en la reunión pueden centrarse en la reunión y dejar la toma de notas a la transcripción de conversaciones. De este modo, pueden participar activamente en la reunión y realizar un seguimiento rápido de los pasos que vienen a continuación valiéndose de la transcripción en lugar de tomar notas y perderse algo posiblemente durante el evento.
Funcionamiento
En el siguiente diagrama se proporciona información general sobre el funcionamiento de la característica.
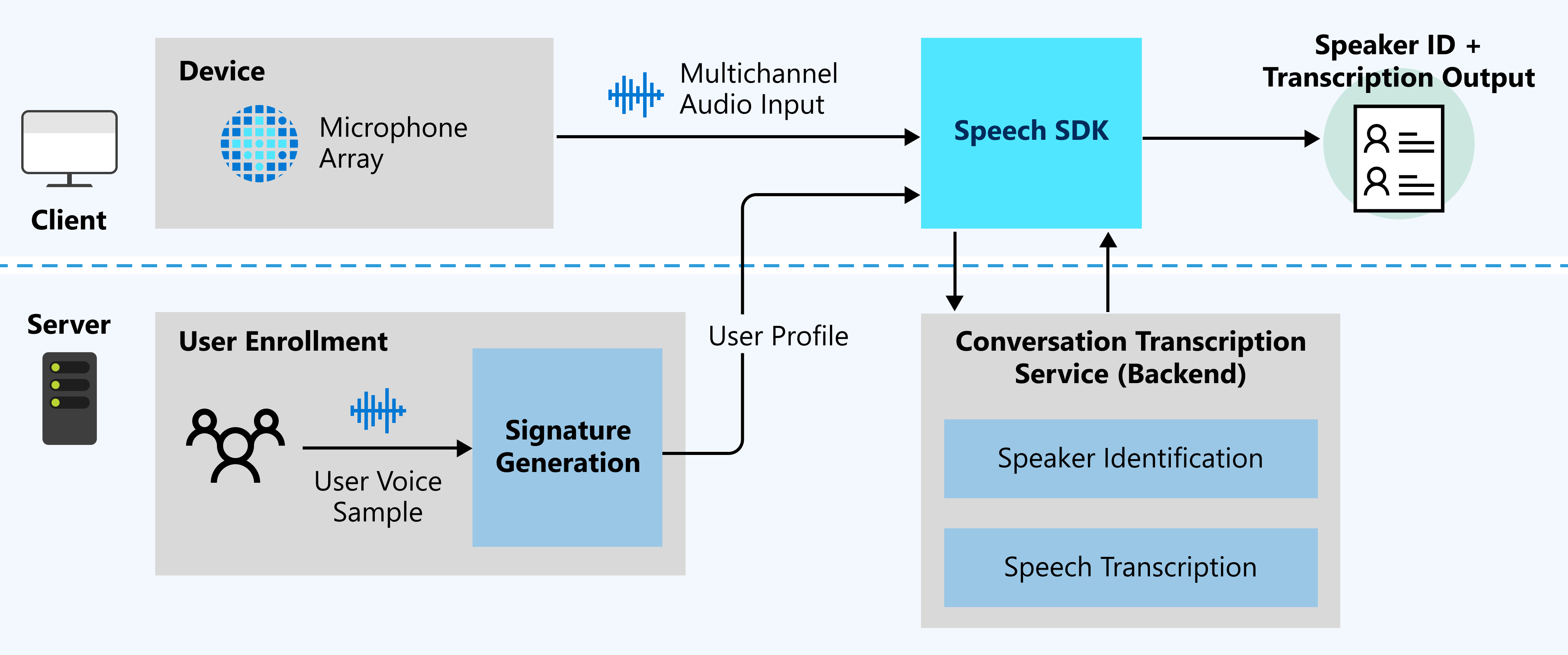
Entradas esperadas
La transcripción de conversaciones usa dos tipos de entradas:
- Secuencia de audio de varios canales: para conocer las especificaciones y los detalles de diseño, consulte Recomendación de la matriz de micrófonos.
- Muestras de voz de usuarios: la transcripción de conversaciones necesita perfiles de usuario antes de la conversación para la identificación del hablante. Recopile grabaciones de audio de cada usuario y, luego, envíelas al servicio de generación de firmas para validar el audio y generar los perfiles de usuario.
Se requieren ejemplos de voz de usuario para las firmas de voz para la identificación del hablante. Los hablantes que no tengan ejemplos de voz se marcarán como Sin identificar. Los hablantes no identificados se pueden diferenciar igualmente si la propiedad DifferentiateGuestSpeakers está habilitada (consulte el ejemplo siguiente). A continuación, la salida de la transcripción muestra a los hablantes como, por ejemplo, Guest_0 y Guest_1, en lugar de reconocerlos como nombres de hablantes específicos inscritos previamente.
config.SetProperty("DifferentiateGuestSpeakers", "true");
En tiempo real o asincrónico
En las secciones siguientes se proporcionan más detalles sobre los modos de transcripción que puede elegir.
Tiempo real
Los datos de audio se procesan en directo para devolver el identificador y la transcripción del hablante. Seleccione este modo si quiere usar la solución de transcripción para proporcionar a los participantes de la reunión una vista de la transcripción en directo de su reunión en curso. Por ejemplo, crear una aplicación para que las reuniones sean más accesibles para los participantes sordos y con dificultades auditivas es un caso de uso idóneo para la transcripción en tiempo real.
Asincrónica
Los datos de audio se procesan por lotes para devolver el identificador y la transcripción del hablante. Seleccione este modo si quiere usar la solución de transcripción para proporcionar una mayor precisión sin la vista de la transcripción en directo. Por ejemplo, si quiere crear una aplicación para permitir que los participantes de la reunión se pongan al día fácilmente con las reuniones a las que han faltado, use el modo de transcripción asincrónica para obtener resultados de transcripción de alta precisión.
Tiempo real y asincrónico
Los datos de audio se procesan en directo para devolver el identificador y la transcripción del hablante; además, se solicita una transcripción de alta precisión mediante el procesamiento asincrónico. Seleccione este modo si la aplicación necesita una transcripción en tiempo real y también requiere una transcripción de mayor precisión después de la reunión.
Compatibilidad de idioma y región
Actualmente, la transcripción de conversaciones admite todos los idiomas de conversión de voz en texto en las siguientes regiones: centralus, eastasia, eastus y westeurope.