Entrenamiento de un modelo de habla personalizada
En este artículo, aprenderá a entrenar un modelo personalizado para mejorar la precisión del reconocimiento del modelo base de Microsoft. La precisión y calidad del reconocimiento de voz de un modelo de habla personalizada seguirán siendo coherentes, incluso cuando se publique un nuevo modelo base.
Nota:
Se paga por el uso del modelo de habla personalizada y el hospedaje del punto de conexión. También se le cobrará por el entrenamiento del modelo de voz personalizado si el modelo base se creó el 1 de octubre de 2023 y versiones posteriores. No se le cobrará por el entrenamiento si el modelo base se creó antes de octubre de 2023. Para obtener más información, consulte precios de Voz de Azure AI y la sección Cargo por adaptación de la guía de migración de conversión de voz en texto 3.2.
Entrenar un modelo suele ser un proceso iterativo. En primer lugar, se selecciona un modelo base que es el punto de partida de un nuevo modelo. Puede entrenar un modelo con conjuntos de datos que pueden incluir texto y audio para, luego, probarlo. Si la calidad o la precisión del reconocimiento no cumplen sus requisitos, puede crear un nuevo modelo con datos de entrenamiento adicionales o modificados y, luego, volver a probarlo.
Puede usar un modelo personalizado durante un tiempo limitado después de entrenarlo. Debe volver a crear y adaptar periódicamente el modelo personalizado a partir del modelo base más reciente para aprovechar las ventajas de la precisión y la calidad mejoradas. Para más información, consulte Ciclo de vida del modelo y el punto de conexión.
Importante
Si va a entrenar un modelo personalizado con datos de audio, elija una región de recursos de Voz con hardware dedicado para entrenar datos de audio. Una vez entrenado un modelo, puede copiarlo en un recurso de Voz que se encuentra en otra región según sea necesario.
En las regiones con hardware dedicado al entrenamiento de Habla personalizada, el servicio Voz usará hasta 100 horas de los datos de entrenamiento de audio y puede procesar, aproximadamente, 10 horas de datos al día. Consulte las notas al pie en la tabla de regiones para obtener más información.
Crear un modelo
Después de cargar los conjuntos datos de entrenamiento, siga estas instrucciones para empezar a entrenar el modelo:
Inicie sesión en Speech Studio.
Seleccione Habla personalizada> El nombre del proyecto >Entrenar modelos personalizados.
Seleccione Entrenar un modelo nuevo.
En la página Seleccionar un modelo de línea base, seleccione un modelo base y, a continuación, elija Siguiente. Si no está seguro, seleccione el modelo más reciente en la parte superior de la lista. El nombre del modelo base corresponde a la fecha en que se publicó en formato AAAAMMDD. Las funcionalidades de personalización del modelo base se muestran entre paréntesis después del nombre del modelo en Speech Studio.
Importante
Tome nota de la fecha Expiración para la adaptación. Esta es fecha más reciente en la que puede usar el modelo base para el entrenamiento. Para más información, consulte Ciclo de vida del modelo y el punto de conexión.
En la página Elegir datos, seleccione uno o más conjuntos de datos que desee utilizar para el entrenamiento. Si no hay ningún conjunto de datos disponible, cancele la instalación y vaya al menú Speech datasets (Conjuntos de datos de voz) para cargar conjuntos de datos.
Escriba un nombre y una descripción para el modelo personalizado y seleccione Siguiente.
Opcionalmente, active la casilla Agregar prueba en el siguiente paso. Si omite este paso, puede ejecutar las mismas pruebas más adelante. Para más información, consulte Prueba de la calidad del reconocimiento y Prueba del modelo cuantitativamente.
Seleccione Guardar y cerrar para iniciar la compilación del modelo personalizado.
Vuelva a la página Entrenar modelos personalizados.
Importante
Tome nota de la fecha de expiración. Esta es la última fecha en la que puede usar el modelo personalizado para el reconocimiento de voz. Para más información, consulte Ciclo de vida del modelo y el punto de conexión.
Para crear un modelo con conjuntos de datos para el entrenamiento, use el comando spx csr model create. Construya los parámetros de solicitud según las instrucciones siguientes:
- Establezca el parámetro
projecten el identificador de un proyecto existente. Este parámetro se recomienda para que también pueda ver y administrar el modelo en Speech Studio. Puede ejecutar el comandospx csr project listpara obtener los proyectos disponibles. - Establezca el parámetro
datasetnecesario en el identificador de un conjunto de datos que quiera usar para el entrenamiento. Para especificar varios conjuntos de datos, establezca el parámetrodatasets(plural) y separe los identificadores con punto y coma. - Establezca el parámetro
languagenecesario. La configuración regional del conjunto de datos debe coincidir con la configuración regional del proyecto. Esta configuración regional no se podrá modificar más adelante. El parámetrolanguagede la CLI de Voz corresponde a la propiedadlocalede la solicitud y respuesta JSON. - Establezca el parámetro
namenecesario. Este parámetro es el nombre que se muestra en Speech Studio. El parámetronamede la CLI de Voz corresponde a la propiedaddisplayNamede la solicitud y respuesta JSON. - También tiene la opción de definir la propiedad
base. Por ejemplo:--base 5988d691-0893-472c-851e-8e36a0fe7aaf. Si no especificabase, se usa el modelo base predeterminado para la configuración regional. El parámetrobasede la CLI de Voz corresponde a la propiedadbaseModelde la solicitud y respuesta JSON.
Este es un ejemplo de comando de la CLI de Voz, que crea un modelo con conjuntos de datos para el entrenamiento:
spx csr model create --api-version v3.2 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Nota
En este ejemplo, no se establece base, por lo que se usa el modelo base predeterminado para la configuración regional. El URI del modelo base se devuelve en la respuesta.
Debe recibir un cuerpo de respuesta en el formato siguiente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Importante
Anote la fecha en la propiedad adaptationDateTime. Esta es fecha más reciente en la que puede usar el modelo base para el entrenamiento. Para más información, consulte Ciclo de vida del modelo y el punto de conexión.
Anote la fecha en la propiedad transcriptionDateTime. Esta es la última fecha en la que puede usar el modelo personalizado para el reconocimiento de voz. Para más información, consulte Ciclo de vida del modelo y el punto de conexión.
La propiedad self de nivel superior en el cuerpo de la respuesta es el URI del proyecto. Use este URI para obtener detalles sobre las fechas de proyecto, manifiesto y desuso del modelo. Use también este URI para actualizar o eliminar un modelo.
Para obtener ayuda de la CLI de Voz con modelos, ejecute el comando siguiente:
spx help csr model
A fin de crear un modelo con conjuntos de datos para el entrenamiento, use la operación Models_Create de la API REST de conversión de voz en texto. Construya el cuerpo de la solicitud según las instrucciones siguientes:
- Establezca la propiedad
projecten el URI de un proyecto existente. Esta propiedad se recomienda para que también pueda ver y administrar el modelo en Speech Studio. Puede realizar una solicitud Projects_List para obtener proyectos disponibles. - Establezca la propiedad
datasetsnecesaria en el URI de los conjuntos de datos que quiere usar para el entrenamiento. - Establezca la propiedad
localeobligatoria. La configuración regional del modelo debe coincidir con la configuración regional del proyecto y el modelo base. Esta configuración regional no se podrá modificar más adelante. - Establezca la propiedad
displayNamerequerida. Esta propiedad es el nombre que se muestra en Speech Studio. - También tiene la opción de definir la propiedad
baseModel. Por ejemplo:"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"}. Si no especificabaseModel, se usa el modelo base predeterminado para la configuración regional.
Realice una solicitud HTTP POST con el URI, como se muestra en el ejemplo siguiente. Reemplace YourSubscriptionKey por la clave de recurso de Voz, YourServiceRegion por la región del recurso de Voz, y establezca las propiedades del cuerpo de la solicitud como se ha descrito anteriormente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Nota
En este ejemplo, no se establece baseModel, por lo que se usa el modelo base predeterminado para la configuración regional. El URI del modelo base se devuelve en la respuesta.
Debe recibir un cuerpo de respuesta en el formato siguiente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Importante
Anote la fecha en la propiedad adaptationDateTime. Esta es fecha más reciente en la que puede usar el modelo base para el entrenamiento. Para más información, consulte Ciclo de vida del modelo y el punto de conexión.
Anote la fecha en la propiedad transcriptionDateTime. Esta es la última fecha en la que puede usar el modelo personalizado para el reconocimiento de voz. Para más información, consulte Ciclo de vida del modelo y el punto de conexión.
La propiedad self de nivel superior en el cuerpo de la respuesta es el URI del proyecto. Use este URI para obtener detalles sobre las fechas de proyecto, manifiesto y desuso del modelo. Use también este URI para actualizar o eliminar el modelo.
Copia de un modelo
Puede copiar un modelo en otro proyecto que use la misma configuración regional. Por ejemplo, después de entrenar un modelo con datos de audio en una región con hardware dedicado para el entrenamiento, puede copiarlo en un recurso de Voz en otra región según sea necesario.
Siga estas instrucciones para copiar un modelo en un proyecto de otra región:
- Inicie sesión en Speech Studio.
- Seleccione Habla personalizada> El nombre del proyecto >Entrenar modelos personalizados.
- Seleccione Copiar en.
- En la página Copiar modelo de voz, seleccione una región de destino donde quiera copiar el modelo.

- Seleccione un recurso de Voz en la región de destino o cree un nuevo recurso de Voz.
- Seleccione un proyecto en el que quiera copiar el modelo o cree un nuevo proyecto.
- Seleccione Copiar.

Una vez que el modelo se haya copiado correctamente, se le notificará y podrá verlo en el proyecto de destino.
No se admite la copia de un modelo directamente en un proyecto de otra región con la CLI de Voz. Puede copiar un modelo en un proyecto de otra región mediante Speech Studio o la API REST de conversión de voz en texto.
Para copiar un modelo en otro recurso de Voz, use la operación Models_Copy de la API REST de Speech to Text. Construya el cuerpo de la solicitud según las instrucciones siguientes:
- Establezca la propiedad
targetSubscriptionKeynecesaria en la clave del recurso de Voz de destino.
Realice una solicitud HTTP POST con el URI, como se muestra en el ejemplo siguiente. Use la región y el URI del modelo desde el que quiere copiar. Reemplace YourModelId por el identificador del modelo, reemplace YourSubscriptionKey por la clave de recurso de Voz, reemplace YourServiceRegion por la región del recurso de Voz, y establezca las propiedades del cuerpo de la solicitud como se ha descrito anteriormente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models/YourModelId:copy"
Nota
Solo la propiedad targetSubscriptionKey del cuerpo de la solicitud tiene información sobre el recurso de Voz de destino.
Debe recibir un cuerpo de respuesta en el formato siguiente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copy"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Conexión de un modelo
Es posible que los modelos se hayan copiado de un proyecto mediante la CLI de Voz o la API REST, sin estar conectados a otro proyecto. La conexión de un modelo es cuestión de actualizar el modelo con una referencia al proyecto.
Si se le pide en Speech Studio, puede conectarlos seleccionando el botón Conectar.
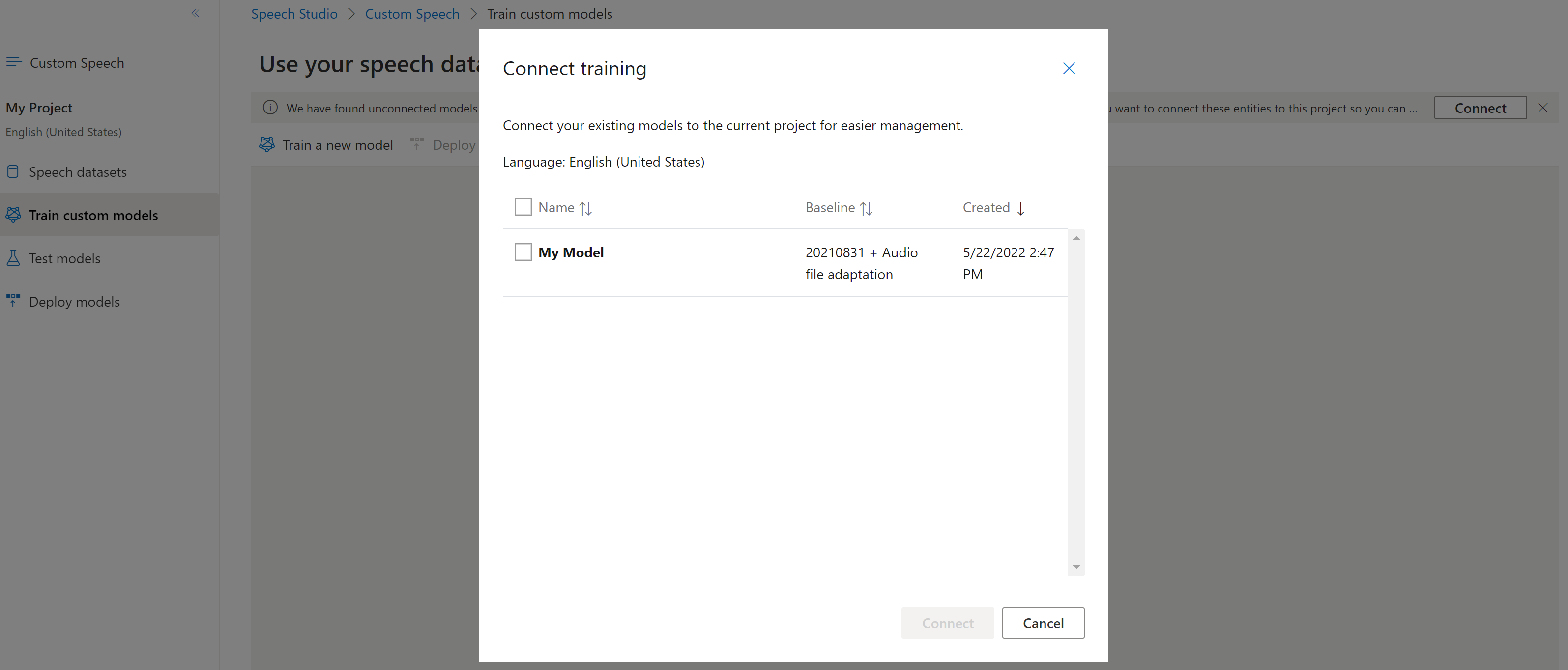
Para conectar un modelo a un proyecto, use el comando spx csr model update. Construya los parámetros de solicitud según las instrucciones siguientes:
- Establezca el parámetro
projecten el URI de un proyecto existente. Este parámetro se recomienda para que también pueda ver y administrar el modelo en Speech Studio. Puede ejecutar el comandospx csr project listpara obtener los proyectos disponibles. - Establezca el parámetro
modelIdobligatorio en el identificador del modelo que quiere conectar al proyecto.
Este es un ejemplo de comando de la CLI de Voz, que conecta un modelo a un proyecto:
spx csr model update --api-version v3.2 --model YourModelId --project YourProjectId
Debe recibir un cuerpo de respuesta en el formato siguiente:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}
Para obtener ayuda de la CLI de Voz con modelos, ejecute el comando siguiente:
spx help csr model
Para conectar un nuevo modelo a un proyecto del recurso de Voz donde se copió el modelo, use la operación Models_Update de la API REST de conversión de voz en texto. Construya el cuerpo de la solicitud según las instrucciones siguientes:
- Establezca la propiedad
projectobligatoria en el URI de un proyecto existente. Esta propiedad se recomienda para que también pueda ver y administrar el modelo en Speech Studio. Puede realizar una solicitud Projects_List para obtener proyectos disponibles.
Realice una solicitud HTTP PATCH con el URI, como se muestra en el ejemplo siguiente. Use el URI del nuevo modelo. El nuevo identificador de modelo se puede obtener de la propiedad self del cuerpo de la respuesta Models_Copy. Reemplace YourSubscriptionKey por la clave de recurso de Voz, YourServiceRegion por la región del recurso de Voz, y establezca las propiedades del cuerpo de la solicitud como se ha descrito anteriormente.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Debe recibir un cuerpo de respuesta en el formato siguiente:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}