Modelo de recibo de Documento de inteligencia
Este contenido se aplica a: ![]() v4.0 (GA) | Versiones anteriores:
v4.0 (GA) | Versiones anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Este contenido se aplica a: ![]() v3.1 (GA) | Versión más reciente:
v3.1 (GA) | Versión más reciente: ![]() v4.0 (GA) | Versiones anteriores:
v4.0 (GA) | Versiones anteriores: ![]() v3.0
v3.0 ![]() v2.1
v2.1
Este contenido se aplica a: ![]() v3.0 (GA) | Versiones más recientes:
v3.0 (GA) | Versiones más recientes: ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 | versión anterior:
v3.1 | versión anterior: ![]() v2.1
v2.1
Este contenido se aplica a: ![]() v2.1 | Versión más reciente:
v2.1 | Versión más reciente: ![]() v4.0 (GA)
v4.0 (GA)
El modelo de recibo de Documento de inteligencia combina funcionalidades de reconocimiento óptico de caracteres (OCR) eficaces con modelos de aprendizaje profundo para analizar y extraer información clave de recibos de ventas. Los recibos pueden tener varios formatos y calidad, incluidos los recibos impresos y manuscritos. La API extrae información clave, como el nombre del comerciante, el número de teléfono del comerciante, la fecha de transacción, los impuestos y el total de la transacción, y devuelve datos JSON estructurados. El modelo de recibo v4.0 (GA) también admite otros campos, incluidos ReceiptType, TaxDetails.NetAmount, TaxDetails.Description, TaxDetails.Rate y CountryRegion.
Tipos de recibo admitidos:
- Comida
- Suministros
- Hotel
- Combustible y energía
- Transporte
- Comunicación
- Suscripciones
- Entretenimiento
- Cursos
- Atención sanitaria
Extracción de datos de recibo
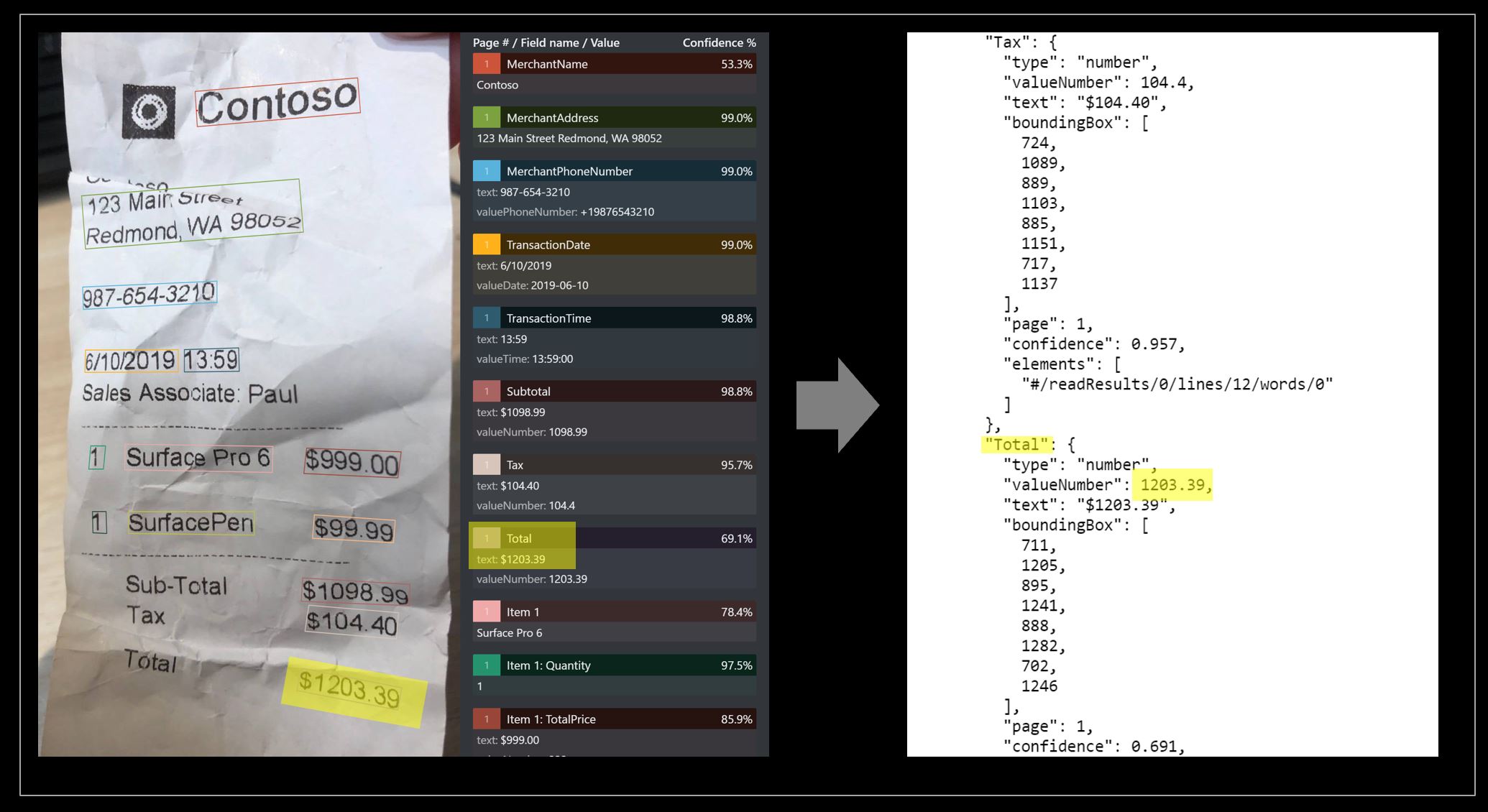
La digitalización de recibos abarca la transformación de varios tipos de recibos, incluidos los escaneados, los fotografías y las copias impresas, en un formato digital para un procesamiento descendente simplificado. Algunos ejemplos son la administración de gastos, el análisis del comportamiento del consumidor, la automatización fiscal, etc. El uso de Documento de inteligencia con tecnología OCR (reconocimiento óptico de caracteres) puede extraer e interpretar datos de estos diversos formatos de recibo. El procesamiento de Documento de inteligencia simplifica el proceso de conversión, pero también reduce significativamente el tiempo y el esfuerzo necesarios, lo que facilita la administración y recuperación eficientes de datos.
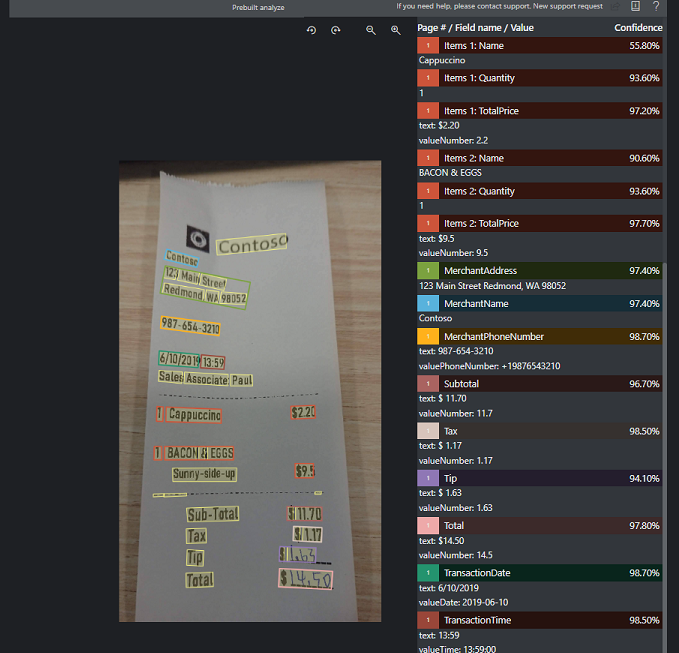
Recibo de ejemplo procesado con Documento de inteligencia Studio:

Recibo de ejemplo procesado con la Herramienta de etiquetado de ejemplo de Documento de inteligencia:
Opciones de desarrollo
Document Intelligence v4.0: 2024-11-30 (GA) admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de recibo | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
Recibo precompilado |
Documento de inteligencia v3.1 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de recibo | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
Recibo precompilado |
Documento de inteligencia v3.0 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de recibo | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
Recibo precompilado |
Documento de inteligencia v2.1 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos |
|---|---|
| Modelo de recibo | ● Herramienta de etiquetado de Documento de inteligencia ● API REST ● SDK de biblioteca cliente ● Contenedor Docker de Documento de inteligencia |
Requisitos de entrada
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento se2GB con un máximo de 10 000 páginas.
- Formatos de archivo admitidos: JPEG, PNG, PDF y TIFF.
- Se admite la asignación de páginas para PDF y TIFF: Documento de inteligencia puede procesar hasta 2000 páginas para suscriptores de nivel Estándar o solo las dos primeras páginas para suscriptores de nivel Gratis.
- Tamaño de archivo admitido: menos de 50 MB; píxeles mínimos: 50 x 50 px; píxeles máximos de 10 000 x 10 000 px.
Extracción de datos del modelo de recibo
Vea cómo Documento de inteligencia extrae de los recibos los datos, incluida la hora y la fecha de las transacciones, la información del comerciante y los importes totales. Tendrá que supervisar los recursos siguientes:
Una suscripción a Azure: puede crear una cuenta gratuita.
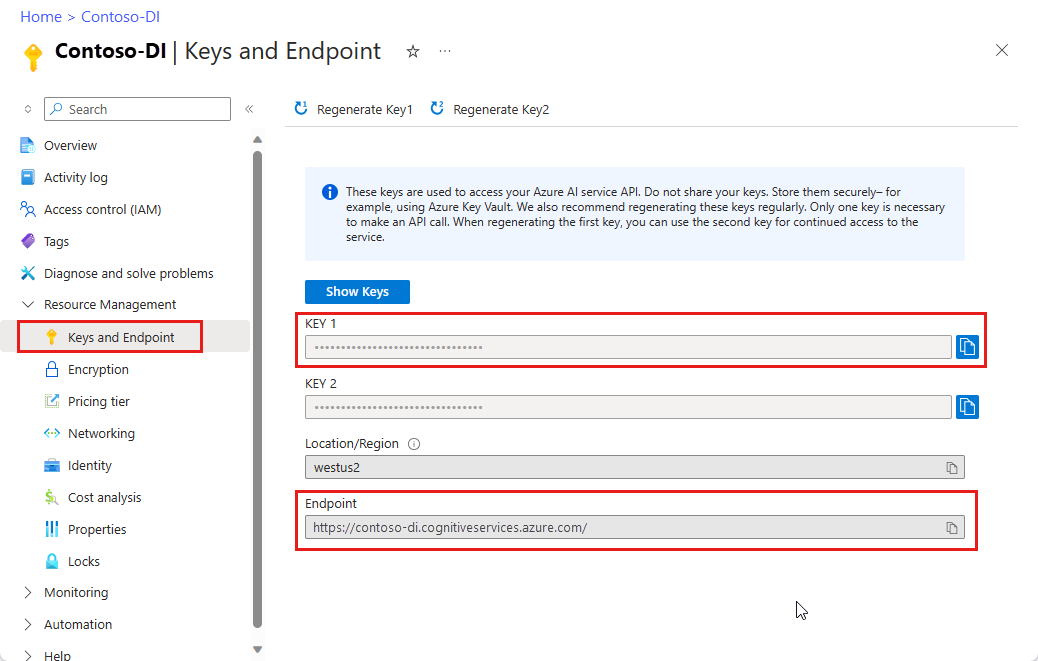
Una instancia de Document Intelligence en el Azure Portal. Puede usar el plan de tarifa gratuito (
F0) para probar el servicio. Después de implementar el recurso, seleccione Ir al recurso para obtener la clave y el punto de conexión.
Nota:
Documento de inteligencia Studio está disponible con las API v3.1 y v3.0 y versiones posteriores.
En la página principal de Studio de Documento de inteligencia, seleccione Recibos.
Puede analizar el recibo de ejemplo o cargar archivos propios.
Seleccione el botón Ejecutar análisis y, si es necesario, configure las opciones de Análisis :

Herramienta de etiquetado de ejemplo de Documento de inteligencia
En la página principal de la herramienta de ejemplo, seleccione el icono Use prebuilt model to get data (Usar un modelo precompilado para obtener datos).
Seleccione el Tipo de formulario que quiere analizar en el menú desplegable.
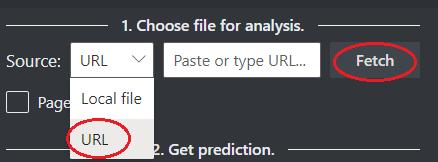
Elija una dirección URL para el archivo que quiere analizar entre las opciones siguientes:
En el campo Origen, seleccione URL en el menú desplegable, pegue la dirección URL seleccionada y seleccione el botón Capturar.
En el campo Punto de conexión de Documento de inteligencia, pegue el punto de conexión que obtuvo con la suscripción de Documento de inteligencia.
En el campo Clave, pegue la clave que obtuvo del recurso de Documento de inteligencia.

Seleccione Run analysis (Ejecutar análisis). La herramienta de etiquetado de ejemplo de Documento de inteligencia llama a la API Analyze Prebuilt y analiza el documento.
Vea los resultados: consulte los pares clave-valor extraídos, los elementos de línea, el texto resaltado extraído y las tablas detectadas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nota
La herramienta de etiquetado de ejemplo no admite el formato de archivo BMP. Se trata de una limitación de la herramienta, no del servicio de Documento de inteligencia.
Idiomas y configuraciones regionales compatibles
Para obtener una lista completa de los idiomas admitidos, consulte nuestra página compatibilidad con el lenguaje modelos precompilados.
Extracción de campos
Para los campos de extracción de documentos admitidos, consulte la página esquema del modelo de recibo en nuestro repositorio de ejemplo de GitHub
| Nombre | Escribir | Descripción | Salida estandarizada |
|---|---|---|---|
| ReceiptType | String | Tipo de recibo de venta | Detallados |
| MerchantName | String | Nombre del comerciante que emite el recibo | |
| MerchantPhoneNumber | phoneNumber | Número de teléfono mostrado del comerciante | +1 xxx xxx xxxx |
| MerchantAddress | String | Dirección mostrada del comerciante | |
| Fecha de transacción | Fecha | Fecha de emisión del recibo | aaaa-mm-dd |
| TransactionTime | Time | Hora de emisión del recibo | hh-mm-ss (24 horas) |
| Total | Número (USD) | Número total de transacciones de recibos | Float de dos decimales |
| Subtotal | Número (USD) | Subtotal del recibo, a menudo antes de aplicar impuestos | Float de dos decimales |
| Impuesto | Número (USD) | Total de impuestos en el recibo (impuesto sobre ventas o equivalente). Se ha cambiado el nombre a "TotalTax" en la versión 2022-06-30. | Float de dos decimales |
| Sugerencia | Número (USD) | Propina incluida por el comprador | Float de dos decimales |
| Elementos | Matriz de objetos | Líneas del artículo extraídas, con el nombre, la cantidad, el precio por unidad y el precio total extraídos | |
| Nombre | String | Descripción del artículo. Se ha cambiado el nombre a "Description" en la versión 2022-06-30. | |
| Cantidad | Number | Cantidad de cada artículo | Float de dos decimales |
| Precio | Número | Precio individual de cada unidad del artículo | Float de dos decimales |
| TotalPrice | Número | Precio total del artículo | Float de dos decimales |
Guía de migración y API de REST v3.1
- Siga la Guía de migración de Document Intelligence v3.1 para obtener información sobre cómo usar la versión v3.1 en las aplicaciones y flujos de trabajo.
Pasos siguientes
Pruebe a procesar sus propios formularios y documentos con Document Intelligence Studio.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.
Pruebe a procesar sus propios formularios y documentos con la Herramienta de etiquetado de muestras de Documento de inteligencia.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.