Modelo de lectura de Documento de inteligencia
Este contenido se aplica a: ![]() v4.0 (GA) | Versiones anteriores:
v4.0 (GA) | Versiones anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)
Este contenido se aplica a: ![]() v4.0 (GA) | Versiones anteriores:
v4.0 (GA) | Versiones anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)
Nota:
Para extraer texto de imágenes externas como etiquetas, señales de tráfico y carteles, utilice la característica Azure AI Image Analysis v4.0 Read optimizada para imágenes generales no documentales con una API sincrónica de rendimiento mejorado que facilita la incorporación de OCR en escenarios de experiencia de usuario en tiempo real.
El modelo de Reconocimiento óptico de caracteres (OCR) de Inteligencia de documentos se ejecuta con una resolución superior que la del modelo de lectura de Visión de Azure AI y extrae texto impreso y manuscrito de documentos PDF e imágenes escaneadas. También incluye compatibilidad para extraer texto de documentos de Microsoft Word, Excel, PowerPoint y documentos HTML. Detecta párrafos, líneas de texto, palabras, ubicaciones e idiomas. El modelo de Lectura es el motor de OCR subyacente para otros modelos precompilados de Inteligencia de documentos, como Diseño, Documento general, Factura, Recibo, Documento de identidad (ID), Tarjeta de seguro médico, W2, además de modelos personalizados.
¿Qué es el reconocimiento óptico de caracteres?
El reconocimiento óptico de caracteres (OCR) para documentos está optimizado para documentos con mucho texto en varios formatos de archivo e idiomas globales. Incluye características como el escaneo de imágenes de documentos con una mayor resolución para un mejor control del texto más pequeño y más denso; detección de párrafos; y administración de formularios rellenables. La funcionalidad OCR también incluye escenarios avanzados, como cuadros de caracteres únicos y extracción precisa de campos clave que se encuentran habitualmente en facturas, recibos y otros escenarios creados previamente.
Opciones de desarrollo (v4)
Documento de inteligencia v4.0: 2024-11-30 (GA) es compatible con las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de lectura de OCR | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-read |
Requisitos de entrada (v4)
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
Introducción al modelo de lectura (v4)
Intente extraer texto de formularios y documentos mediante Inteligencia de documentos Studio. Necesitará los recursos siguientes:
Una suscripción a Azure (se puede crear de forma gratuita).
Una instancia de Document Intelligence en el Azure Portal. Puede usar el plan de tarifa gratuito (
F0) para probar el servicio. Después de implementar el recurso, seleccione Ir al recurso para obtener la clave y el punto de conexión.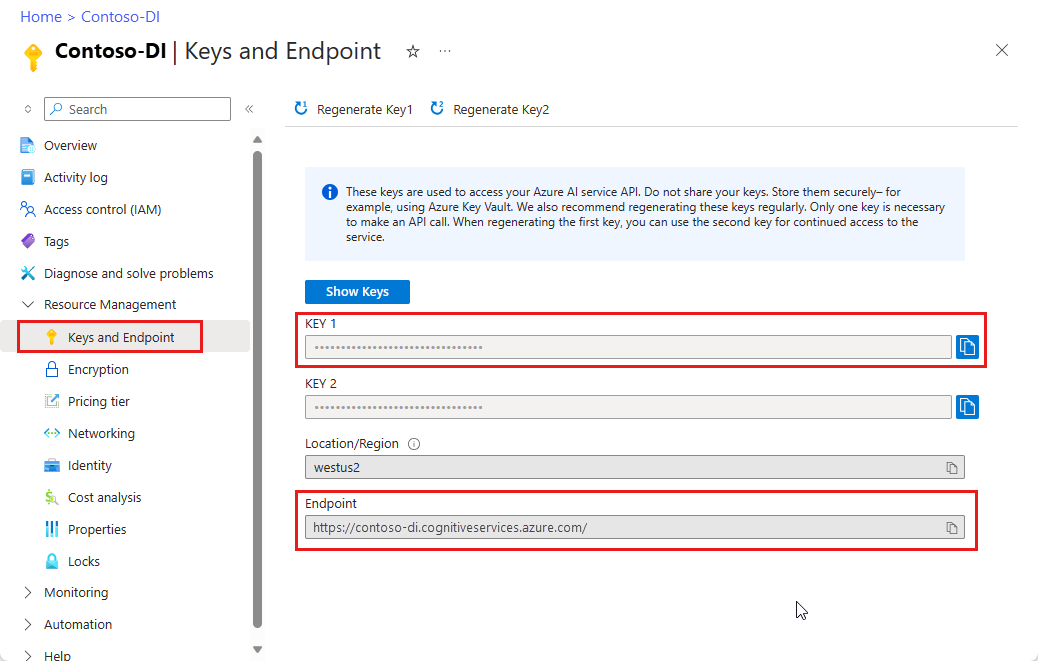
Nota:
Actualmente, Inteligencia de documentos Studio no admite formatos de archivo Microsoft Word, Excel, PowerPoint y HTML.
Documento de ejemplo procesado con Inteligencia de documentos Studio
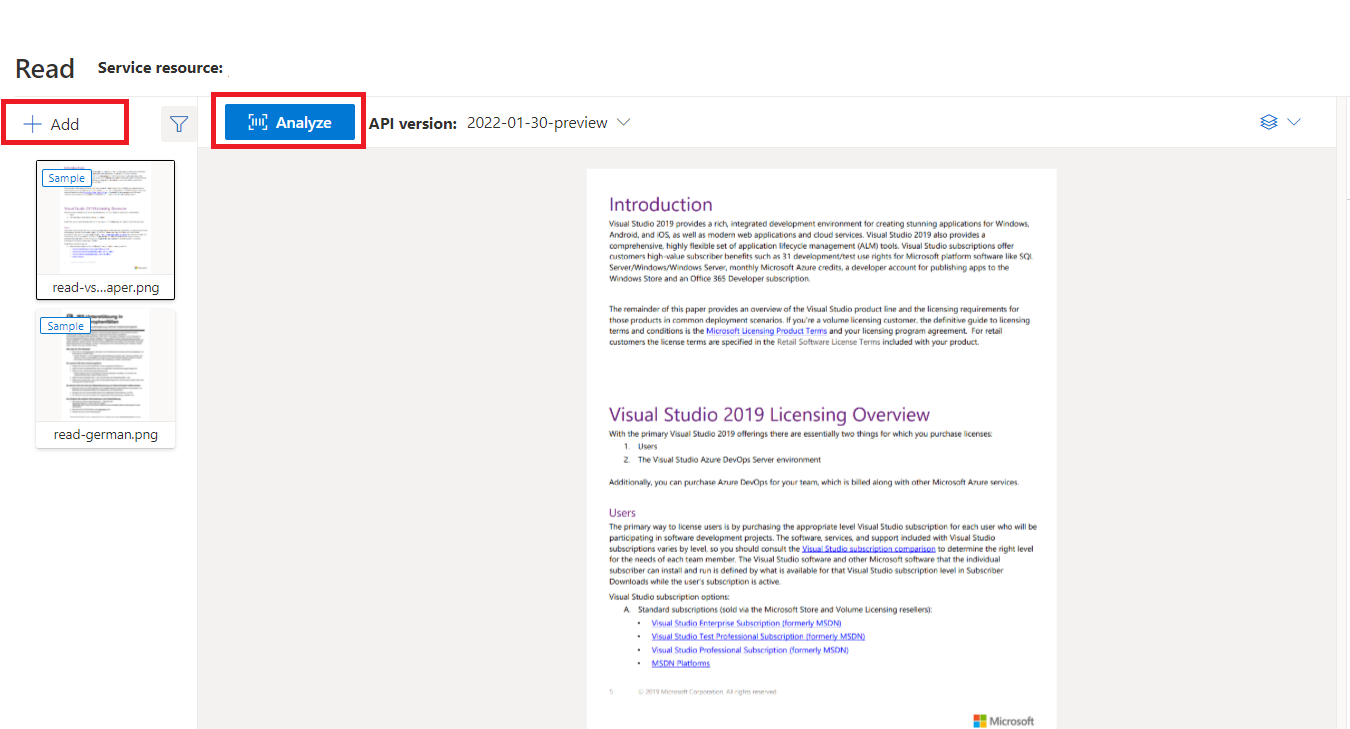
En la página principal de Estudio de Documento de inteligencia, seleccione Lectura.
Puede analizar el documento de ejemplo o cargar archivos propios.
Seleccione el botón Ejecutar análisis y, si es necesario, configure las opciones de Análisis :

Idiomas y configuraciones regionales admitidos (v4)
Para ver una lista completa de los idiomas admitidos, consulte nuestra página de Idiomas admitidos: modelos de análisis de documentos.
Extracción de datos (v4)
Nota:
Microsoft Word y el archivo HTML se admiten en v4.0. En comparación con los archivos PDF y las imágenes, no se admiten las siguientes características:
- No hay ángulo, ancho/alto ni unidad en todos los objetos de página.
- En los objetos detectados no hay polígonos delimitadores ni regiones delimitadoras.
- El intervalo de páginas (
pages) no se admite como parámetro. - No hay objetos
lines.
Archivos PDF que se pueden buscar
La funcionalidad de PDF utilizable en búsquedas le permite convertir un PDF analógico, como los archivos PDF de imágenes escaneadas, en un PDF con texto insertado. El texto insertado permite la búsqueda profunda de texto dentro del contenido extraído del PDF mediante la superposición de las entidades de texto detectadas sobre los archivos de imagen.
Importante
- Actualmente, la funcionalidad de PDF utilizable en búsquedas solo es compatible con el modelo de lectura de OCR
prebuilt-read. Al usar esta característica, especifiquemodelIdcomoprebuilt-read, ya que otros tipos de modelo devolverán un error para esta versión preliminar. - Pdf que se puede buscar se incluye con el modelo
prebuilt-readde disponibilidad general 2024-11-30 sin costo adicional para generar una salida PDF que se puede buscar.
Uso de archivos PDF que se pueden buscar
Para usar PDF utilizable en búsquedas, envíe una solicitud POST mediante la operación Analyze y especifique el formato de salida como pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Sondee la finalización de la operación de Analyze. Una vez completada la operación, emita una solicitud de GET para recuperar el formato PDF de los resultados de la operación de Analyze.
Cuando se complete correctamente, el PDF se puede recuperar y descargar como application/pdf. Esta operación permite la descarga directa del formato de texto insertado de PDF en lugar de JSON codificado en Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Parámetro Pages
La colección de páginas es una lista de páginas del documento. Cada página se representa secuencialmente dentro del documento e incluye el ángulo de orientación, que indica si la página está girada, así como su ancho y alto (dimensiones en píxeles). Las unidades de página de la salida del modelo se calculan como se muestra:
| Formato de archivo | Unidad de página calculada | Páginas totales |
|---|---|---|
| Imágenes (JPEG/JPG, PNG, BMP y HEIF) | Cada imagen = 1 unidad de página | Total de imágenes |
| Cada página del PDF = 1 unidad de página | Total de páginas en el PDF | |
| TIFF | Cada imagen del TIFF = 1 unidad de página | Total de imágenes en el TIFF |
| Word (DOCX) | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
| Excel (XLSX) | Cada hoja de cálculo = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de hojas de cálculo |
| PowerPoint (PPTX) | Cada diapositiva = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de diapositivas |
| HTML | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Uso de páginas para la extracción de texto
En el caso de documentos PDF de varias páginas de gran tamaño, use el parámetro de consulta pages para indicar números de página o intervalos de páginas específicos para la extracción de texto.
Extracción de párrafos
El modelo de lectura de OCR en Inteligencia de documentos extrae todos los bloques de texto identificados de la colección paragraphs como objeto de nivel superior en analyzeResults. Cada entrada de esta colección representa un bloque de texto e incluye el texto extraído como content y las coordenadas polygon delimitadoras. La información de span apunta al fragmento de texto dentro de la propiedad content de nivel superior que contiene el texto completo del documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Extracción de texto, líneas y palabras
El modelo de lectura de OCR extrae texto de estilo impreso y manuscrito como lines y words. El modelo genera coordenadas polygon delimitadoras y confidence para las palabras extraídas. La colección styles incluye cualquier estilo manuscrito para las líneas si se detectan, junto con los intervalos que apuntan al texto asociado. Esta característica se aplica a los idiomas manuscritos admitidos.
En el caso de Microsoft Word, Excel, PowerPoint y HTML, a partir de la versión 3.1 del modelo de lectura de Document Intelligence todo el texto insertado se extrae tal como está. Los textos se extraen en forma de palabras y párrafos. No se admiten las imágenes insertadas.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Extracción de estilo manuscrito
La respuesta incluye la clasificación de si cada línea de texto es de estilo manuscrito o no, junto con una puntuación de confianza. Para obtener más información, consulte la compatibilidad con idiomas manuscritos. En el ejemplo siguiente se muestra un ejemplo de fragmento JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Si ha habilitado la funcionalidad del complemento de estilo o fuente, también obtendrá el resultado de fuente y estilo como parte del objeto styles.
Pasos siguientes v4.0
Complete un inicio rápido de Inteligencia de documentos:
Explorar nuestra API de REST:
Encuentre más ejemplos en GitHub:
Nota:
Para extraer texto de imágenes externas, como etiquetas, señales de calle y pósteres, use la característica Lectura de Análisis de imágenes de Azure AI v4.0 optimizada para imágenes generales que no son de documento con una API sincrónica mejorada para el rendimiento que facilita la inserción de OCR en los escenarios de experiencia del usuario.
El modelo de Reconocimiento óptico de caracteres (OCR) de Inteligencia de documentos se ejecuta con una resolución superior que la del modelo de lectura de Visión de Azure AI y extrae texto impreso y manuscrito de documentos PDF e imágenes escaneadas. También incluye compatibilidad para extraer texto de documentos de Microsoft Word, Excel, PowerPoint y documentos HTML. Detecta párrafos, líneas de texto, palabras, ubicaciones e idiomas. El modelo de Lectura es el motor de OCR subyacente para otros modelos precompilados de Inteligencia de documentos, como Diseño, Documento general, Factura, Recibo, Documento de identidad (ID), Tarjeta de seguro médico, W2, además de modelos personalizados.
¿Qué es OCR para documentos?
El reconocimiento óptico de caracteres (OCR) para documentos está optimizado para documentos con mucho texto en varios formatos de archivo e idiomas globales. Incluye características como el escaneo de imágenes de documentos con una mayor resolución para un mejor control del texto más pequeño y más denso; detección de párrafos; y administración de formularios rellenables. La funcionalidad OCR también incluye escenarios avanzados, como cuadros de caracteres únicos y extracción precisa de campos clave que se encuentran habitualmente en facturas, recibos y otros escenarios creados previamente.
Opciones de desarrollo
Documento de inteligencia v3.1 es compatible con las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de lectura de OCR | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-read |
Documento de inteligencia v3.0 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de lectura de OCR | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-read |
Requisitos de entrada
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
Introducción al modelo de lectura
Intente extraer texto de formularios y documentos mediante Inteligencia de documentos Studio. Necesitará los recursos siguientes:
Una suscripción a Azure (se puede crear de forma gratuita).
Una instancia de Document Intelligence en el Azure Portal. Puede usar el plan de tarifa gratuito (
F0) para probar el servicio. Después de implementar el recurso, seleccione Ir al recurso para obtener la clave y el punto de conexión.
Nota:
Actualmente, Inteligencia de documentos Studio no admite formatos de archivo Microsoft Word, Excel, PowerPoint y HTML.
Documento de ejemplo procesado con Inteligencia de documentos Studio
En la página principal de Estudio de Documento de inteligencia, seleccione Lectura.
Puede analizar el documento de ejemplo o cargar archivos propios.
Seleccione el botón Ejecutar análisis y, si es necesario, configure las opciones de Análisis :
Idiomas y configuraciones regionales compatibles
Para ver una lista completa de los idiomas admitidos, consulte nuestra página de Idiomas admitidos: modelos de análisis de documentos.
Extracción de datos
Nota:
Los archivos de Microsoft Word y HTML se admiten a partir de la versión 3.1. En comparación con los archivos PDF y las imágenes, no se admiten las siguientes características:
- No hay ángulo, ancho/alto ni unidad en todos los objetos de página.
- En los objetos detectados no hay polígonos delimitadores ni regiones delimitadoras.
- El intervalo de páginas (
pages) no se admite como parámetro. - No hay objetos
lines.
PDF utilizable en búsquedas
La funcionalidad de PDF utilizable en búsquedas le permite convertir un PDF analógico, como los archivos PDF de imágenes escaneadas, en un PDF con texto insertado. El texto insertado permite la búsqueda profunda de texto dentro del contenido extraído del PDF mediante la superposición de las entidades de texto detectadas sobre los archivos de imagen.
Importante
- Actualmente, la funcionalidad de PDF utilizable en búsquedas solo es compatible con el modelo de lectura de OCR
prebuilt-read. Cuando utilice esta función, especifique elmodelIdcomoprebuilt-read, ya que otros tipos de modelo devolverán un error. - El modelo 2024-11-30
prebuilt-readincluye un PDF con función de búsqueda sin coste adicional para generar un PDF con función de búsqueda.- Un PDF utilizable en búsquedas actualmente solo admite archivos PDF como entrada. La compatibilidad con otros tipos de archivo, como archivos de imagen, estará disponible más adelante.
Uso de PDF utilizable en búsquedas
Para usar PDF utilizable en búsquedas, envíe una solicitud POST mediante la operación Analyze y especifique el formato de salida como pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Sondee la finalización de la operación de Analyze. Una vez completada la operación, emita una solicitud de GET para recuperar el formato PDF de los resultados de la operación de Analyze.
Cuando se complete correctamente, el PDF se puede recuperar y descargar como application/pdf. Esta operación permite la descarga directa del formato de texto insertado de PDF en lugar de JSON codificado en Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Páginas
La colección de páginas es una lista de páginas del documento. Cada página se representa secuencialmente dentro del documento e incluye el ángulo de orientación, que indica si la página está girada, así como su ancho y alto (dimensiones en píxeles). Las unidades de página de la salida del modelo se calculan como se muestra:
| Formato de archivo | Unidad de página calculada | Páginas totales |
|---|---|---|
| Imágenes (JPEG/JPG, PNG, BMP y HEIF) | Cada imagen = 1 unidad de página | Total de imágenes |
| Cada página del PDF = 1 unidad de página | Total de páginas en el PDF | |
| TIFF | Cada imagen del TIFF = 1 unidad de página | Total de imágenes en el TIFF |
| Word (DOCX) | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
| Excel (XLSX) | Cada hoja de cálculo = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de hojas de cálculo |
| PowerPoint (PPTX) | Cada diapositiva = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de diapositivas |
| HTML | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Selección de páginas para la extracción de texto
En el caso de documentos PDF de varias páginas de gran tamaño, use el parámetro de consulta pages para indicar números de página o intervalos de páginas específicos para la extracción de texto.
Párrafos
El modelo de lectura de OCR en Inteligencia de documentos extrae todos los bloques de texto identificados de la colección paragraphs como objeto de nivel superior en analyzeResults. Cada entrada de esta colección representa un bloque de texto e incluye el texto extraído como content y las coordenadas polygon delimitadoras. La información de span apunta al fragmento de texto dentro de la propiedad content de nivel superior que contiene el texto completo del documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Texto, líneas y palabras
El modelo de lectura de OCR extrae texto de estilo impreso y manuscrito como lines y words. El modelo genera coordenadas polygon delimitadoras y confidence para las palabras extraídas. La colección styles incluye cualquier estilo manuscrito para las líneas si se detectan, junto con los intervalos que apuntan al texto asociado. Esta característica se aplica a los idiomas manuscritos admitidos.
En el caso de Microsoft Word, Excel, PowerPoint y HTML, a partir de la versión 3.1 del modelo de lectura de Document Intelligence todo el texto insertado se extrae tal como está. Los textos se extraen en forma de palabras y párrafos. No se admiten las imágenes insertadas.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Estilo manuscrito para líneas de texto
La respuesta incluye la clasificación de si cada línea de texto es de estilo manuscrito o no, junto con una puntuación de confianza. Para obtener más información, consulte la compatibilidad con idiomas manuscritos. En el ejemplo siguiente se muestra un ejemplo de fragmento JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Si ha habilitado la funcionalidad del complemento de estilo o fuente, también obtendrá el resultado de fuente y estilo como parte del objeto styles.
Pasos siguientes
Complete un inicio rápido de Inteligencia de documentos:
Explorar nuestra API de REST:
Encuentre más ejemplos en GitHub: