Modelo de documento de identificación de Documento de inteligencia
Este contenido se aplica a: ![]() v4.0 (GA) | Versiones anteriores:
v4.0 (GA) | Versiones anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Este contenido se aplica a: ![]() v2.1 | Última versión:
v2.1 | Última versión: ![]() v4.0 (GA)
v4.0 (GA)
El modelo de documento de identificación (id.) de Documento de inteligencia combina el reconocimiento óptico de caracteres (OCR) con modelos de aprendizaje profundo para analizar y extraer la información clave de los documentos de identificación. La API analiza los documentos de identidad (incluidos los siguientes) y devuelve una representación de datos JSON estructurada.
| Region | Tipos de documento |
|---|---|
| Todo el mundo | Pasaporte |
| Estados Unidos | Permiso de conducir, tarjeta de identificación, permiso de residencia (tarjeta verde), tarjeta de la Seguridad Social, identificación militar |
| Europa | Licencia de conducir, tarjeta de identificación, permiso de residencia |
| India | Permiso de conducir, tarjeta PAN, tarjeta Aadhaar |
| Canada | Permiso de conducir, tarjeta de identificación, permiso de residencia (tarjeta Maple) |
| Australia | Permiso de conducir, tarjeta con fotografía, documento de identificación con clave (incluida la versión digital) |
Documento de inteligencia puede analizar y extraer información de documentos de identificación (id.) expedidos por gobiernos mediante sus modelos de id. compilados previamente. Combina nuestras eficaces funcionalidades de reconocimiento óptico de caracteres (OCR) con capacidades de reconocimiento de ID para extraer información clave de pasaportes de todo el mundo y de permisos de conducir de EE. UU. (de los 50 estados y del D.C.). La API de ID extrae información clave de estos documentos de identidad, como el nombre, el apellido, la fecha de nacimiento, el número del documento, etc. Esta API está disponible en Documento de inteligencia v2.1 como un servicio en la nube.
Procesamiento de documentos de identidad
El procesamiento de documentos de identidad implica extraer datos de documentos de identidad manualmente o mediante la tecnología basada en OCR. El procesamiento de documentos de identidad es un paso importante en cualquier operación empresarial en la que se necesite prueba de identidad. Entre los ejemplos se incluyen la verificación de clientes en bancos y otras instituciones financieras, aplicaciones hipotecas, visitas médicas, procesamiento de reclamaciones, industria de la hospitalidad, etc. Las personas proporcionan alguna prueba de su identidad a través de licencias de conducir, pasaportes y otros documentos similares para que la empresa pueda verificarlos de forma eficaz antes de proporcionar servicios y beneficios.
Licencia de conducir de EE. UU. de ejemplo procesada con Documento de inteligencia Studio
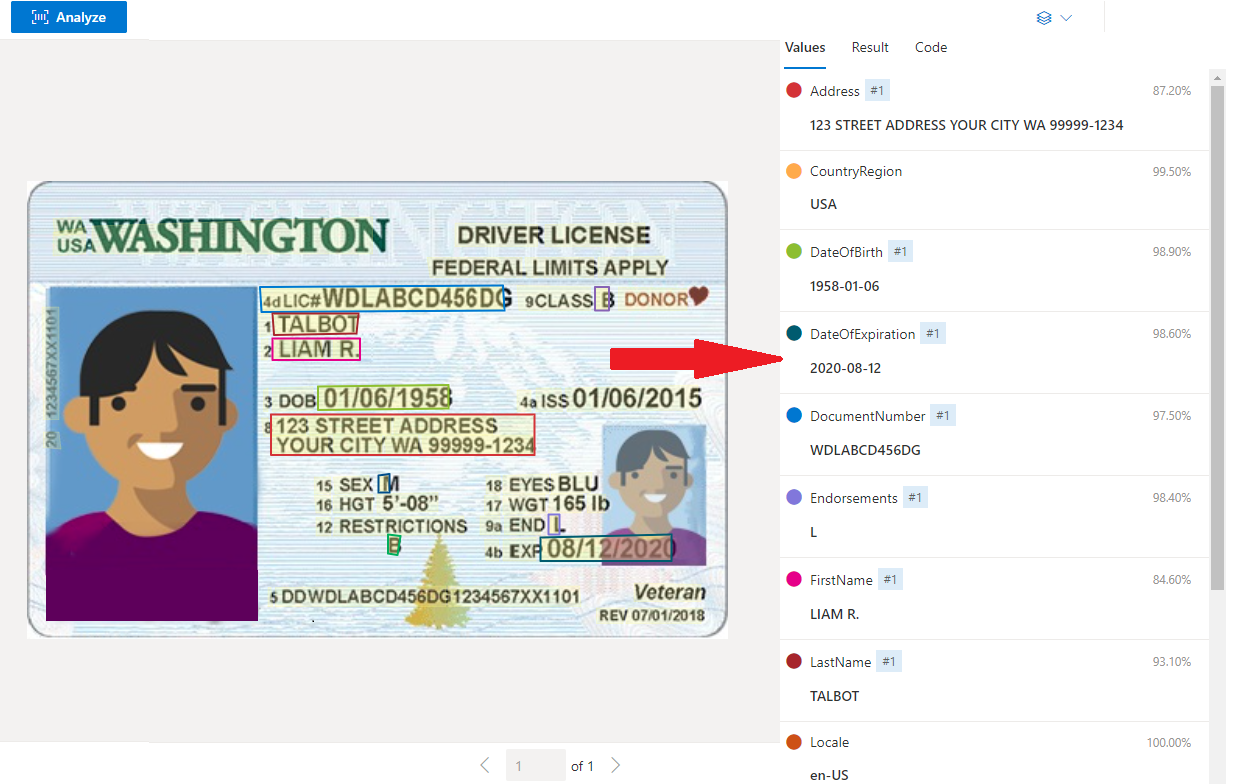
Extracción de datos
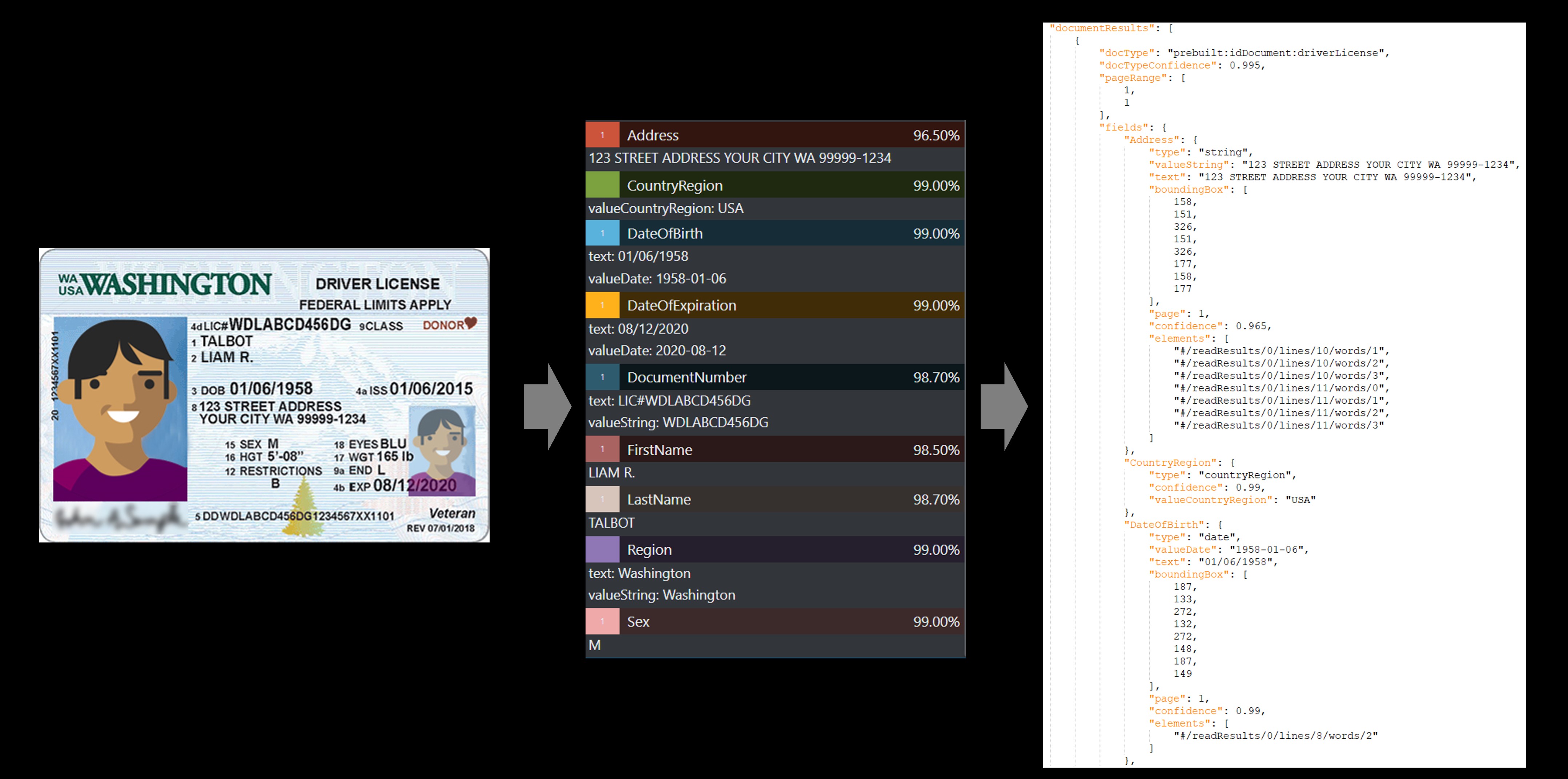
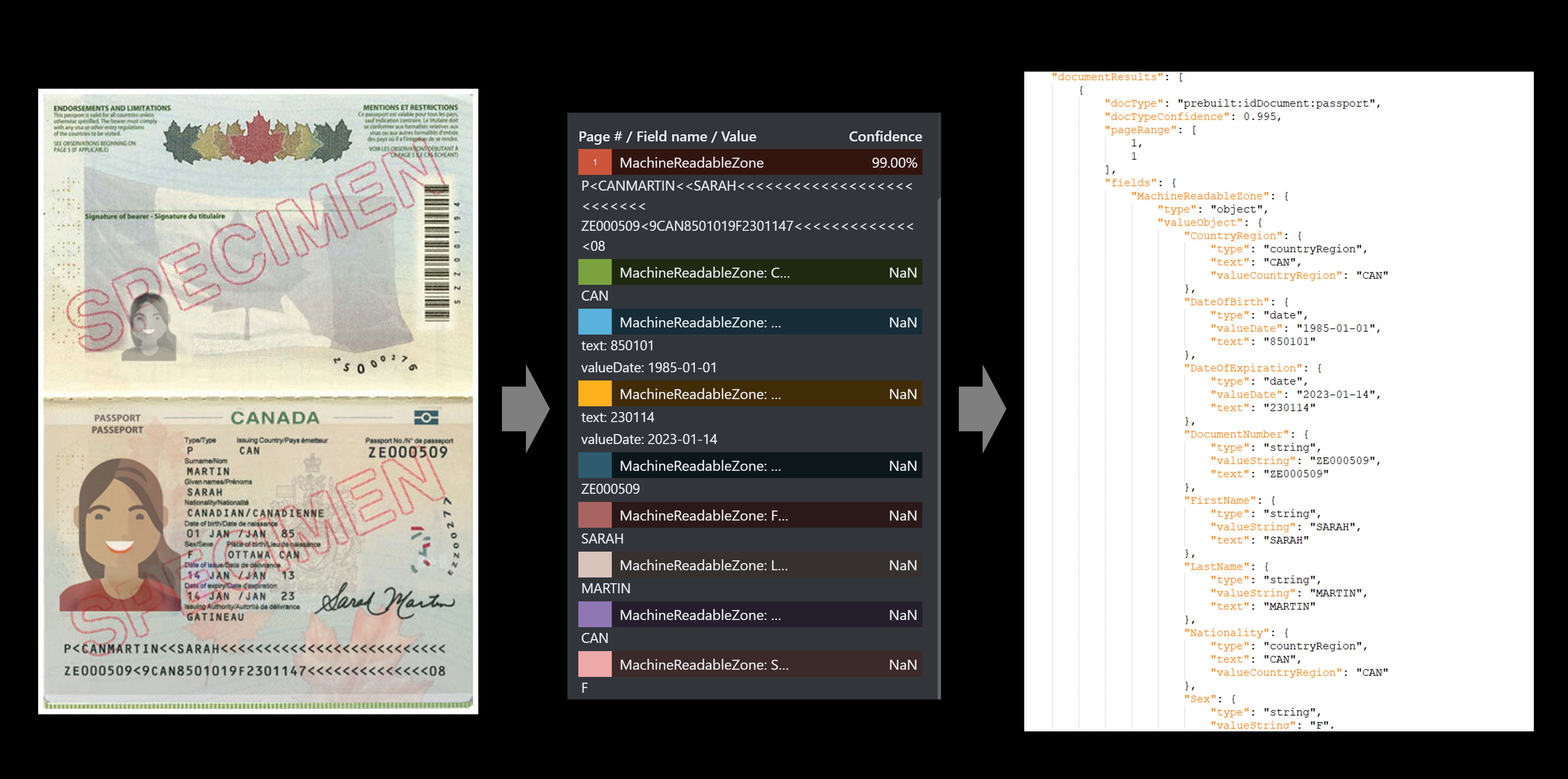
El servicio de identificaciones precompiladas extrae los principales valores de pasaportes de todo el mundo y permisos de conducir de EE. UU. y los devuelve en una respuesta JSON estructurada organizada.
Ejemplo de permiso de conducir
Ejemplo de pasaporte
Opciones de desarrollo
Documento de inteligencia v4.0: 2024-11-30 (GA) es compatible con las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de documentación de id. | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-idDocument |
Documento de inteligencia v3.1 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de documentación de id. | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-idDocument |
Documento de inteligencia v3.0 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de documentación de id. | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-idDocument |
Documento de inteligencia v2.1 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos |
|---|---|
| Modelo de documentación de id. | ● Herramienta de etiquetado de Documento de inteligencia ● API REST ● SDK de biblioteca cliente ● Contenedor Docker de Documento de inteligencia |
Requisitos de entrada
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
Formatos de archivo admitidos: JPEG, PNG, PDF y TIFF.
Número admitido de páginas para archivos PDF y TIFF hasta 2000 páginas o solo las dos primeras páginas para suscriptores de nivel gratuito.
Tamaño de archivo admitido: menos de 50 MB TOTAL; píxeles mínimos: 50 x 50 px; píxeles máximos de 10 000 x 10 000 px.
Extracción de datos del modelo de documento de identificación
Extracción de datos, incluidos el nombre, la fecha de nacimiento y la fecha de expiración, de los documentos de identificación. Tendrá que supervisar los recursos siguientes:
Una suscripción a Azure: puede crear una cuenta gratuita.
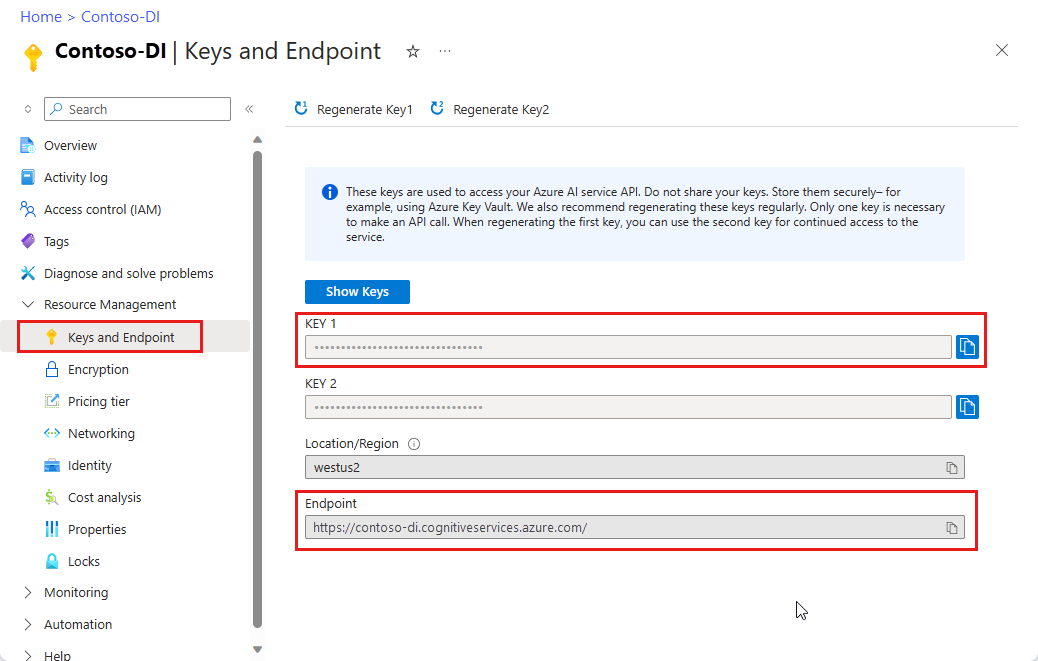
Una instancia de Document Intelligence en el Azure Portal. Puede usar el plan de tarifa gratuito (
F0) para probar el servicio. Después de implementar el recurso, seleccione Ir al recurso para obtener la clave y el punto de conexión.
Nota:
Documento de inteligencia Studio está disponible con las API v3.1 y v3.0 y versiones posteriores.
En la página principal de Estudio de Documento de inteligencia, seleccione documentos de identidad.
Puede analizar la factura de muestra o cargar sus propios archivos.
Seleccione el botón Ejecutar análisis y, si es necesario, configure las opciones de Análisis :

Herramienta de etiquetado de ejemplo de Documento de inteligencia
En la página principal de la herramienta de ejemplo, seleccione el icono Use prebuilt model to get data (Usar un modelo precompilado para obtener datos).
Seleccione el Tipo de formulario que quiere analizar en el menú desplegable.
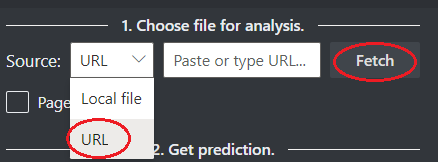
Elija una dirección URL para el archivo que quiere analizar entre las opciones siguientes:
En el campo Origen, seleccione URL en el menú desplegable, pegue la dirección URL seleccionada y seleccione el botón Capturar.
En el campo Punto de conexión de Documento de inteligencia, pegue el punto de conexión que obtuvo con la suscripción de Documento de inteligencia.
En el campo Clave, pegue la clave que obtuvo del recurso de Documento de inteligencia.

Seleccione Run analysis (Ejecutar análisis). La herramienta de etiquetado de ejemplo de Documento de inteligencia llama a la API Analyze Prebuilt y analiza el documento.
Vea los resultados: consulte los pares clave-valor extraídos, los elementos de línea, el texto resaltado extraído y las tablas detectadas.
Descargue el archivo de salida JSON para ver los resultados detallados.
- El nodo "readResults" contiene cada línea de texto con su posición de cuadro de límite correspondiente en la página.
- El nodo "selectionMarks" muestra todas las marcas de selección (casilla, botón de opción) y si su estado es seleccionado o no seleccionado.
- En la sección "pageResults" se incluyen las tablas extraídas. Para cada tabla, Documento de inteligencia extrae el texto, el índice de filas y columnas, la separación de filas y columnas, el rectángulo de selección, etc.
- El campo "documentResults" contiene información de pares clave-valor y de elementos de línea para las partes más importantes del documento.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nota
La herramienta de etiquetado de ejemplo no admite el formato de archivo BMP. Se trata de una limitación de la herramienta, no del servicio de Documento de inteligencia.
Extracciones de campos
Para ver los campos de extracción de documentos admitidos, consulte la página esquema del modelo de documento de identificador en nuestro repositorio de ejemplo de GitHub.
Tipos de documento admitidos
El modelo de documento de identificación admite actualmente licencias de conducir de EE. UU. y la página biográfica de pasaportes internacionales (excepto la extracción de visados y otros documentos de viaje).
Campos extraídos
| Nombre | Escribir | Descripción | Valor |
|---|---|---|---|
| País | country | Código de país conforme con la norma ISO 3166 estándar. | "USA" |
| DateOfBirth | date | Fecha de nacimiento en formato AAAA-MM-DD. | "1980-01-01" |
| DateOfExpiration | date | Fecha de expiración en formato AAAA-MM-DD. | "2019-05-05" |
| DocumentNumber | string | Número de pasaporte, número de permiso de conducir, etc. pertinente. | "340020013" |
| FirstName | string | Nombre extraído e inicial del segundo nombre, si procede. | "JENNIFER" |
| LastName | string | Apellido extraído | "BROOKS" |
| Nacionalidad | country | Código de país conforme con la norma ISO 3166 estándar. | "USA" |
| Sex | gender | Los valores extraídos posibles son "M", "F", "X" | "F" |
| MachineReadableZone | objeto | MRZ del pasaporte extraída, incluidas dos líneas de 44 caracteres cada una |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | string | Tipo de documento, por ejemplo, pasaporte o permiso de conducir. | "passport" |
| Dirección | string | Dirección extraída (solo permiso de conducir) | "123 STREET ADDRESS YOUR CITY WA 99999-1234" |
| Region | string | Valor extraído de región, estado, provincia, etc. (solo permiso de conducir) | "Washington" |
Guía de migración
- Siga la Guía de migración de Document Intelligence v3.1 para obtener información sobre cómo usar la versión v3.0 en las aplicaciones y flujos de trabajo.
Pasos siguientes
Pruebe a procesar sus propios formularios y documentos con Document Intelligence Studio.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.
Pruebe a procesar sus propios formularios y documentos con la Herramienta de etiquetado de muestras de Documento de inteligencia.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.