Modelo documental general de Document Intelligence
Importante
A partir de las versiones preliminares v4.0 de Document Intelligence y en adelante, el modelo de documento general (prebuilt-document) queda obsoleto. Para extraer pares clave-valor, marcas de selección, texto, tablas y estructura de documentos, use los siguientes modelos:
| Característica | version | Id. de modelo |
|---|---|---|
Modelo de Layout con el parámetro features=keyValuePairs de cadena de consulta opcional habilitado. |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| Modelo de documento general | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-document |
El modelo Documento general combina una eficaz funcionalidad de reconocimiento óptico de caracteres (OCR) con modelos de aprendizaje profundo para extraer pares clave-valor, tablas y marcas de selección de documentos. El documento general está disponible con las API v3.1 y v3.0. Para más información, consulte nuestra guía de migración.
Características del documento general
El modelo de documento general es un modelo entrenado previamente, no requiere etiquetas ni entrenamiento.
Una única API extrae pares clave-valor, marcas de selección, texto, tablas y estructura de los documentos.
El modelo de documento general admite documentos estructurados, semiestructurados y no estructurados.
Las marcas de selección se identifican como campos con un valor de
:selected:o:unselected:.
Ejemplo de documento procesado en Document Intelligence Studio
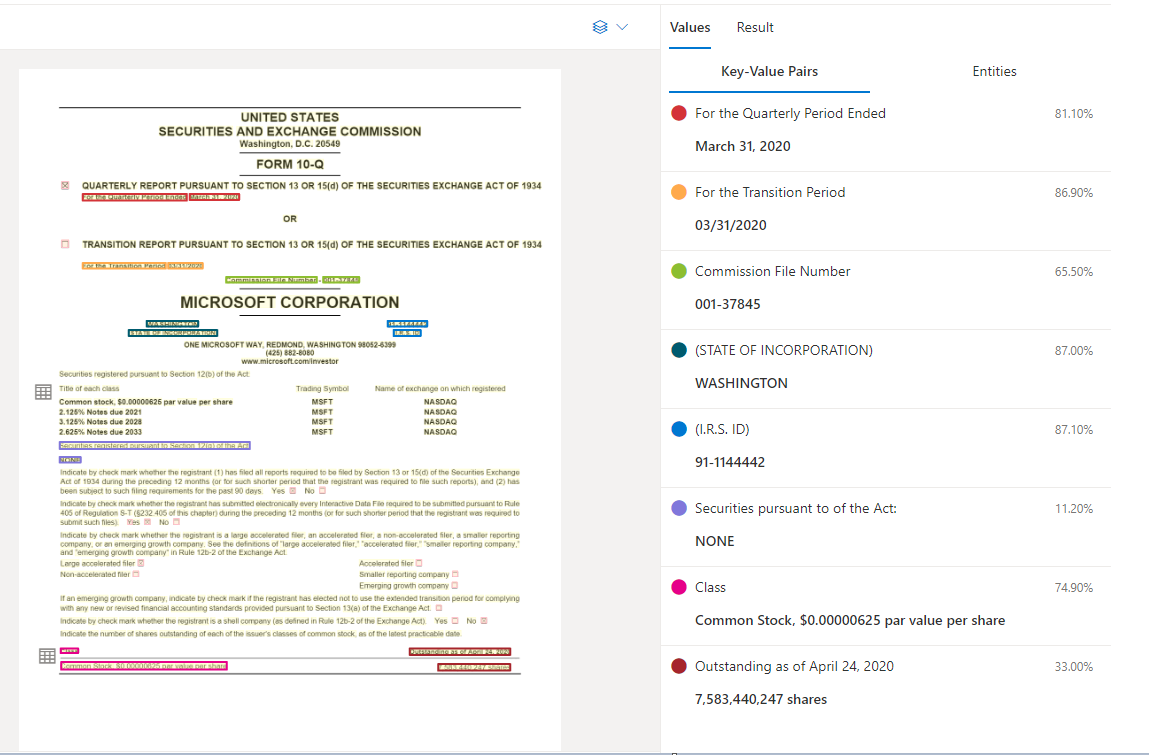
Extracción de pares clave-valor
La API de documento general admite la mayoría de los tipos de formulario y analiza los documentos y extrae las claves y los valores asociados. Es ideal para extraer pares clave-valor comunes de documentos. Puede usar el modelo de documento general como alternativa al entrenamiento de un modelo personalizado sin etiquetas.
Opciones de desarrollo
Documento de inteligencia v3.1 es compatible con las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de documento general | • Estudio de Documento de inteligencia • API de REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-document |
Documento de inteligencia v3.0 es compatible con las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de documento general | • Estudio de Documento de inteligencia • API de REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
prebuilt-document |
Requisitos de entrada
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
Extracción de datos del modelo de documento general
Pruebe a extraer datos de formularios y documentos con Document Intelligence Studio.
Tendrá que supervisar los recursos siguientes:
Una suscripción a Azure: puede crear una cuenta gratuita.
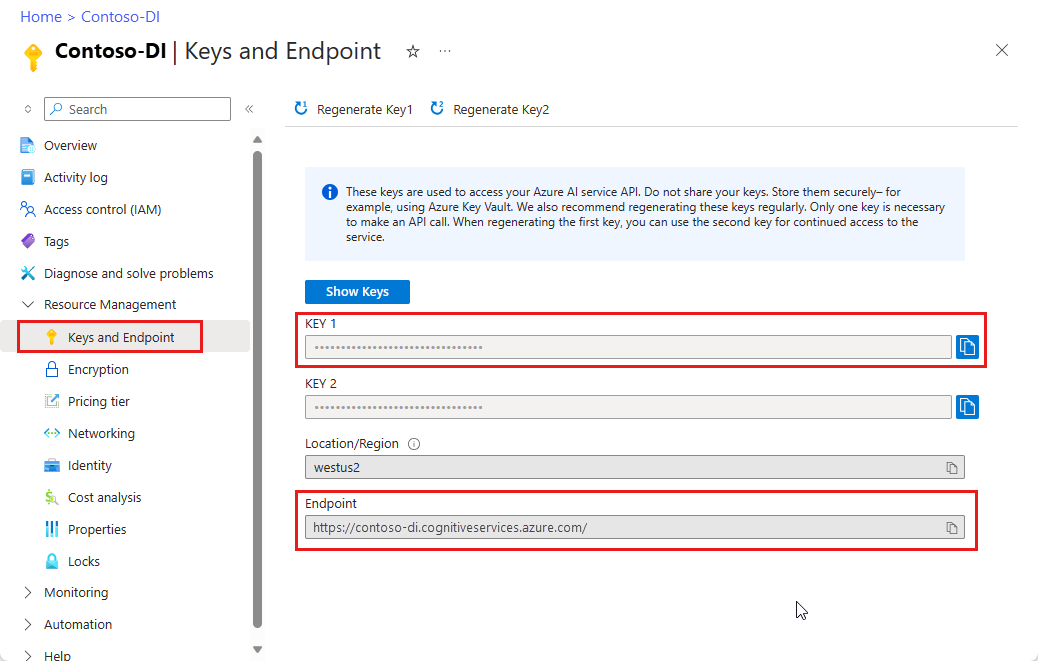
Una instancia de Document Intelligence en el Azure Portal. Puede usar el plan de tarifa gratuito (
F0) para probar el servicio. Después de implementar el recurso, seleccione Ir al recurso para obtener la clave y el punto de conexión.
Nota:
Document Intelligence Studio y el modelo general de documentos están disponibles con la API v3.0.
En la página de inicio de Document Intelligence Studio, seleccione Documentos generales.
Puede analizar el documento de ejemplo o cargar archivos propios.
Seleccione el botón Ejecutar análisis y, si es necesario, configure las opciones de Análisis :

Pares clave-valor
Los pares clave-valor son intervalos específicos dentro del documento que identifican una etiqueta o una clave y su respuesta o valor asociados. De forma estructurada, estos pares pueden ser la etiqueta y el valor que ha escrito el usuario para ese campo. En una documentación no estructurada, pueden ser la fecha en la que se ejecutó un contrato según el mensaje de texto de un párrafo. El modelo de IA está entrenado para extraer claves y valores identificables basados en una amplia variedad de tipos de documentos, formatos y estructuras.
Las claves también pueden existir de forma aislada cuando el modelo detecta que existe una clave, sin ningún valor asociado, o cuando se procesan campos opcionales. Por ejemplo, un campo de segundo nombre se puede dejar en blanco en un formulario en algunos casos. Los pares clave-valor son intervalos de texto contenidos en el documento. Para documentos donde el mismo valor se describe de diferentes maneras, por ejemplo, cliente/usuario, la clave asociada es cliente o usuario (según el contexto).
Extracción de datos
| Modelo | Extracción de texto | Pares clave-valor | Marcas de selección | Tablas | Nombres comunes |
|---|---|---|---|---|---|
| Documento general | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* - Solo disponible en la 2023-07-31 (versión 3.1 GA) y versiones posteriores de la API.
Idiomas y configuraciones regionales compatibles
Vea nuestra página de Compatibilidad de idiomas: modelos de análisis de documentos para obtener una lista completa de los idiomas admitidos.
Consideraciones
Como las claves son intervalos de texto extraídos del documento, en el caso de los documentos semiestructurados, las claves tienen que asignarse a un diccionario de claves existente.
Espere ver los pares clave-valor con una clave, pero ningún valor. Por ejemplo, si un usuario decide no proporcionar una dirección de correo electrónico en el formulario.
Pasos siguientes
Siga la Guía de migración de Document Intelligence v3.1 para obtener información sobre cómo usar la versión v3.1 en las aplicaciones y flujos de trabajo.
Explore nuestra API REST.