Mejora del modelo de Custom Vision
En esta guía aprenderá a mejorar la calidad de un modelo de Custom Vision. La calidad de su clasificador o detector de objetos depende de la cantidad, calidad y variedad de los datos con etiqueta que especifique, así como del grado de equilibrio del conjunto de datos en general. Un buen modelo tiene un conjunto de datos de aprendizaje equilibrado que es representativo de lo que se enviará al modelo. El proceso de creación de un modelo de este tipo es iterativo; es habitual requerir algunos ciclos de aprendizaje para alcanzar los resultados esperados.
Este es un patrón general que le ayudará a entrenar un modelo más preciso:
- Primera ronda de entrenamiento
- Agregar más imágenes y equilibrar datos, reentrenar
- Agregar imágenes con fondo, luz, tamaño de objeto, ángulo de cámara y estilo diversos, reentrenar
- Usar nuevas imágenes para probar la predicción
- Modificar los datos de entrenamiento existentes según los resultados de la predicción
Evitación del sobreajuste
En ocasiones, un modelo aprenderá a realizar predicciones en función de las características arbitrarias que las imágenes tienen en común. Por ejemplo, si va a crear un clasificador que distingue las manzanas de los cítricos y se proporcionan imágenes de manzanas en las manos y de cítricos en platos blancos, puede que el clasificador conceda una importancia innecesaria a la diferencia entre manos y platos blancos en vez de entre manzanas y cítricos.
Para corregir este problema, proporcione imágenes con distintos ángulos, fondos, tamaños del objeto, grupos y otras variantes. En las secciones siguientes se amplían estos conceptos.
Cantidad de datos
El número de imágenes de entrenamiento es el factor más importante para el conjunto de datos. Se recomienda usar al menos cincuenta imágenes por etiqueta como punto de partida. Con menos imágenes, hay un mayor riesgo de sobreajuste y, aunque los números de rendimiento pueden sugerir una buena calidad, el modelo podría tener dificultades con datos reales.
Equilibrio de datos
También es importante tener en cuenta las cantidades relativas de los datos de entrenamiento. Por ejemplo, el uso de 500 imágenes para una etiqueta y 50 imágenes para otra etiqueta desequilibra un conjunto de datos de entrenamiento. Esto hará que el modelo sea más preciso para predecir una etiqueta que otra. Probablemente obtendrá mejores resultados si mantiene al menos una relación 1:2 entre la etiqueta con menos imágenes y la etiqueta que tiene la mayoría de las imágenes. Por ejemplo, si la etiqueta con más imágenes tiene 500 imágenes, la etiqueta con menos imágenes necesitará tener al menos 250 imágenes para el entrenamiento.
Variedad de datos
Asegúrese de proporcionar imágenes que sean representativas de lo que se va a enviar al clasificador durante el uso normal. De lo contrario, el modelo podría obtener información sobre cómo realizar predicciones en función de las características arbitrarias que las imágenes tienen en común. Por ejemplo, si va a crear un clasificador que distingue las manzanas de los cítricos y se proporcionan imágenes de manzanas en las manos y de cítricos en platos blancos, puede que el clasificador conceda una importancia innecesaria a la diferencia entre manos y platos blancos en vez de entre manzanas y cítricos.

Para corregir este problema, incluya varias imágenes para asegurarse de que el clasificador pueda generalizar bien. A continuación se indican algunas formas de diversificar más el conjunto de entrenamiento:
Información previa: Proporcione imágenes de su objeto delante distintos fondos. Las fotos en contexto natural son mejores que las fotos delante de fondos neutros, ya que ofrecen más información para el clasificador.

Luz: Proporcione imágenes con una luz distinta (es decir, fotos realizadas con flash, con alta exposición, etc.), sobre todo si las imágenes utilizadas para predicciones presentan una iluminación distinta. También resulta útil usar imágenes con niveles diferentes de saturación, matiz y brillo.

Tamaño de objeto: Proporcione imágenes en las que los objetos varíen en tamaño y número (por ejemplo, una foto de un racimo de plátanos y un primer plano de un solo plátano). Los diferentes tamaños ayudan al clasificador a generalizar mejor.

Ángulo de cámara: proporcione imágenes realizadas con ángulos de cámara diferentes. Alternativamente, si todas las fotos se toman con cámaras fijas (como cámaras de vigilancia), asegúrese de asignar una etiqueta diferente a cada objeto que se capture periódicamente para evitar sobreajustes o la interpretación de objetos no relacionados (como las farolas) como la característica principal.

Estilo: Proporcione imágenes de diferentes estilos de la misma clase (por ejemplo, diferentes variedades de la fruta misma). Sin embargo, si tiene objetos de estilos radicalmente distintos (por ejemplo, Mickey Mouse frente a una ratón real), se recomienda etiquetarlas como clases independientes para representar mejor sus características distintivas.

Imágenes negativas (solo clasificadores)
Si va a usar un clasificador de imágenes, puede que tenga que agregar ejemplos negativos para ayudar a que el clasificador sea más preciso. Las muestras negativas son imágenes que no coinciden con ninguna de las otras etiquetas. Cuando cargue estas imágenes, aplíqueles la etiqueta especial Negative (Negativo).
Los detectores de objetos controlan los ejemplos negativos automáticamente, ya que las áreas de imágenes fuera de los rectángulos de selección dibujados se consideran negativos.
Nota
El servicio Custom Vision admite cierto control negativo automático de la imagen. Por ejemplo, si va a crear un clasificador que distingue uvas de plátanos y envía una imagen de un zapato para la predicción, el clasificador puntuaría esa imagen con un valor cercano al 0 % para uva y plátano.
Por otro lado, en los casos en que las imágenes negativas son solo una variación de las imágenes utilizadas en el entrenamiento, es probable que el modelo clasifique las imágenes negativas como una clase etiquetada debido a las grandes similitudes que existen. Por ejemplo, si tiene un clasificador que distingue naranjas de pomelos y envía una imagen de una mandarina, puede que se clasifique la mandarina como una naranja porque muchas características de las mandarinas recuerdan a las de las naranjas. Si las imágenes negativas son de esta naturaleza, se recomienda crear una o varias etiquetas adicionales (como Otros) y etiquetar las imágenes negativas con esta etiqueta durante el entrenamiento para permitir que el modelo diferencie mejor entre estas clases.
Oclusión y truncamiento (solo detectores de objetos)
Si quiere que su detector de objetos detecte objetos truncados (objetos que están parcialmente recortados en la imagen) u objetos ocluidos (objetos que están parcialmente bloqueados por otros objetos en la imagen), tendrá que incluir imágenes de entrenamiento que cubran esos casos.
Nota
El problema de los objetos que están ocluidos por otros objetos no se debe confundir con el umbral de superposición, un parámetro para el rendimiento del modelo de clasificación. El control deslizante Overlap Threshold (Umbral de superposición) del sitio web de Custom Vision permite seleccionar el grado en que un rectángulo delimitador de predicción debe superponerse al rectángulo delimitador verdadero que se considera correcto.
Uso de imágenes de predicción para entrenamiento adicional
Al usar o probar el modelo mediante el envío de imágenes al punto de conexión de predicción, el servicio Custom Vision almacena esas imágenes. A continuación, puede usarlas para mejorar el modelo.
Para ver las imágenes enviadas al modelo, abra la página web de Custom Vision, vaya al proyecto y seleccione la pestaña Predictions (Predicciones). La vista predeterminada muestra imágenes de la iteración actual. Puede usar el menú desplegable Iteración para ver las imágenes enviadas durante las iteraciones anteriores.
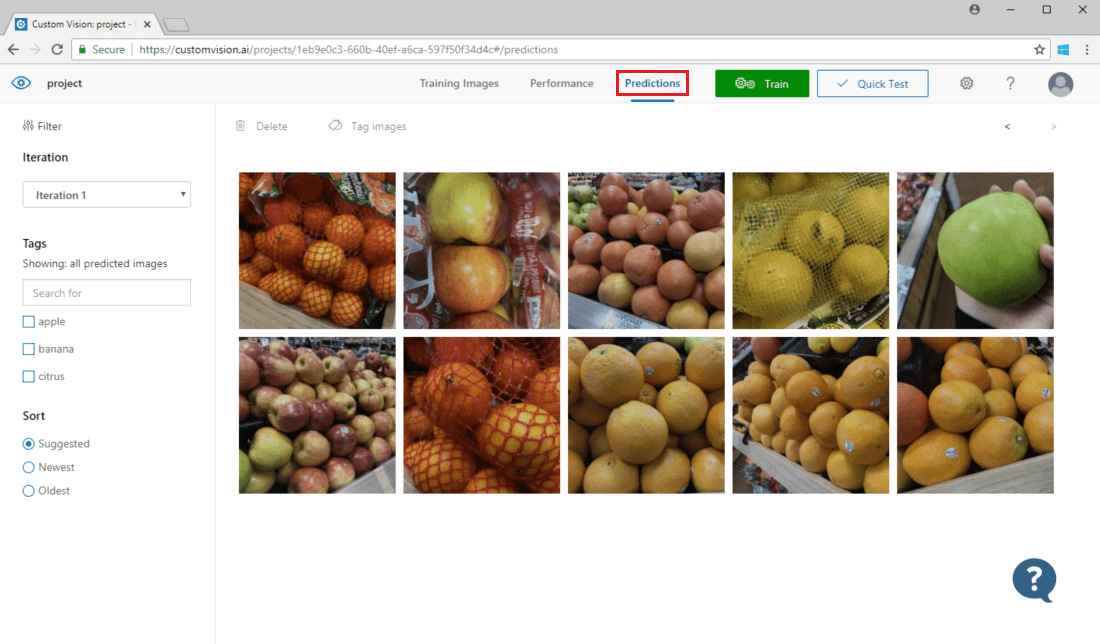
Mantenga el mouse sobre una imagen para ver las etiquetas previstas por el modelo. Las imágenes se ordenan de manera que aquellas que pueden aportar más mejoras al modelo ocupan los primeros lugares. Para usar un método de ordenación diferente, realice una selección en la sección Ordenar.
Para agregar una imagen a los datos de entrenamiento existentes, seleccione la imagen, seleccione la etiqueta correcta y después seleccione Guardar y cerrar. La imagen se quitará de las predicciones y se agrega a las imágenes de entrenamiento. Para verla, seleccione la pestaña Training Images (Imágenes de entrenamiento).
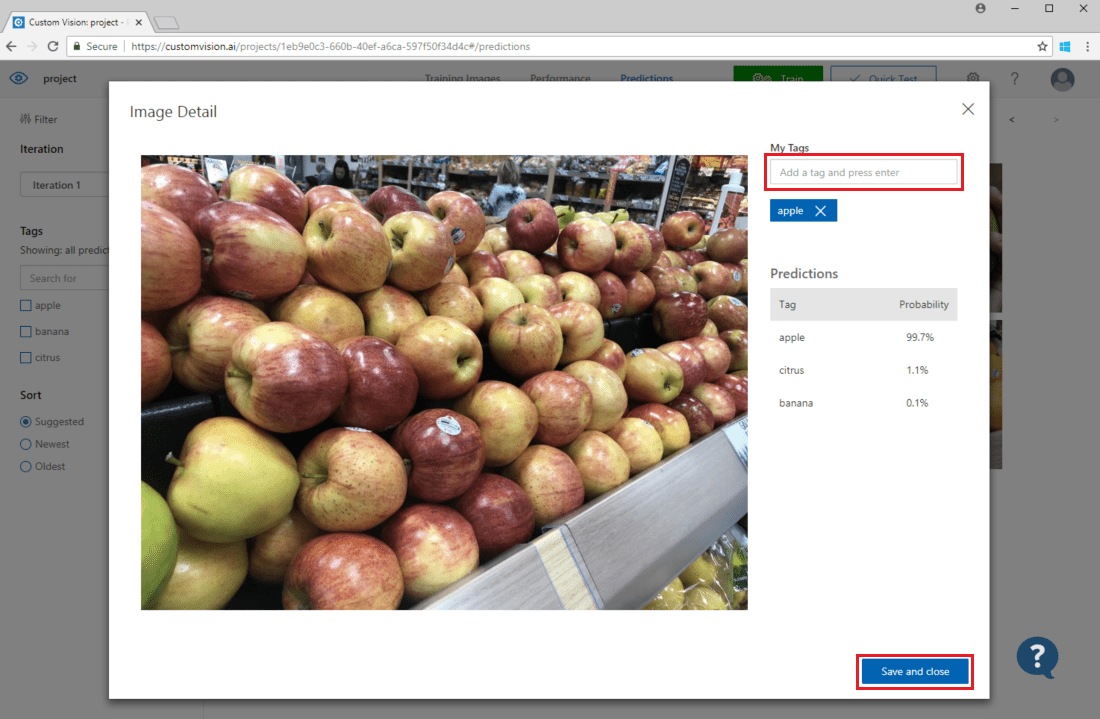
Luego, use el botón Entrenar para reentrenar el modelo.
Inspección visual de predicciones
Para inspeccionar las predicciones de la imagen, vaya a la pestaña de imágenes de entrenamiento, seleccione la iteración de entrenamiento anterior en el menú desplegable Iteración y compruebe una o varias etiquetas en la sección Etiquetas. La vista ahora debe mostrar un cuadro rojo alrededor de cada una de las imágenes para las que el modelo no pudo predecir correctamente la etiqueta determinada.
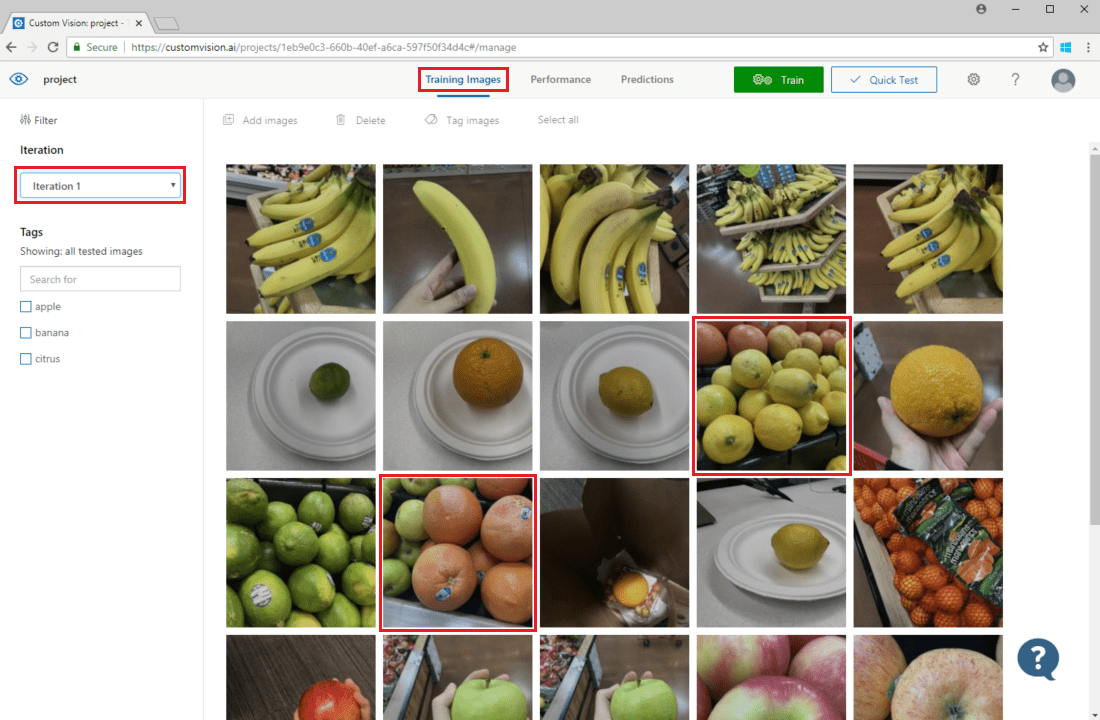
En ocasiones, la inspección visual puede identificar patrones que puede corregir agregando datos de entrenamiento adicionales o modificando los datos de entrenamiento existentes. Por ejemplo, un clasificador que distingue manzanas de limas puede etiquetar incorrectamente las manzanas verdes como limas. Puede corregir este problema agregando y proporcionando datos de entrenamiento que contengan imágenes etiquetadas de manzanas verdes.
Pasos siguientes
En esta guía, ha aprendido varias técnicas para hacer más preciso el modelo de clasificación de imágenes personalizadas o el modelo del detector de objetos. A continuación, aprenda a probar imágenes mediante programación enviándolas a Prediction API.