Preparar los datos
Nota:
Para obtener una mayor funcionalidad, PyTorch también se puede usar con DirectML en Windows.
En la fase anterior de este tutorial, instalamos PyTorch en la máquina. Ahora lo usaremos para configurar el código con los datos que utilizaremos para crear el modelo.
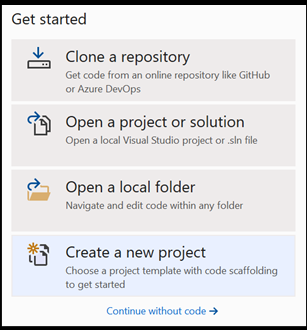
Abra un nuevo proyecto en Visual Studio.
- Abra Visual Studio y elija
create a new project.
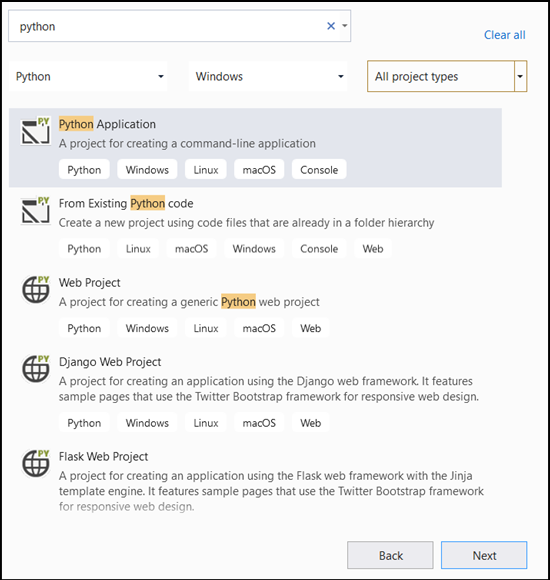
- En la barra de búsqueda, escriba
Pythony seleccionePython Applicationcomo plantilla de proyecto.
- En la ventana de configuración:
- Dé un nombre al proyecto. Aquí lo llamaremos PyTorchTraining.
- Elija la ubicación del proyecto.
- Si usa VS2019, asegúrese de que la opción
Create directory for solutionesté activada. - Si usa VS 2017, asegúrese de que la opción
Place solution and project in the same directoryesté desactivada.
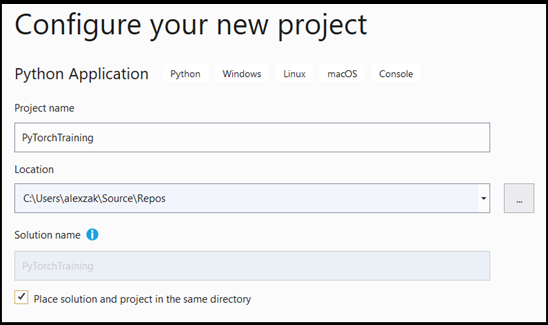
Presione create para crear el proyecto.
Creación de un intérprete de Python
En esta sección debe definir un nuevo intérprete de Python. Recuerde que debe incluir el paquete de PyTorch que instaló recientemente.
- Vaya a la selección del intérprete y seleccione
Add environment:
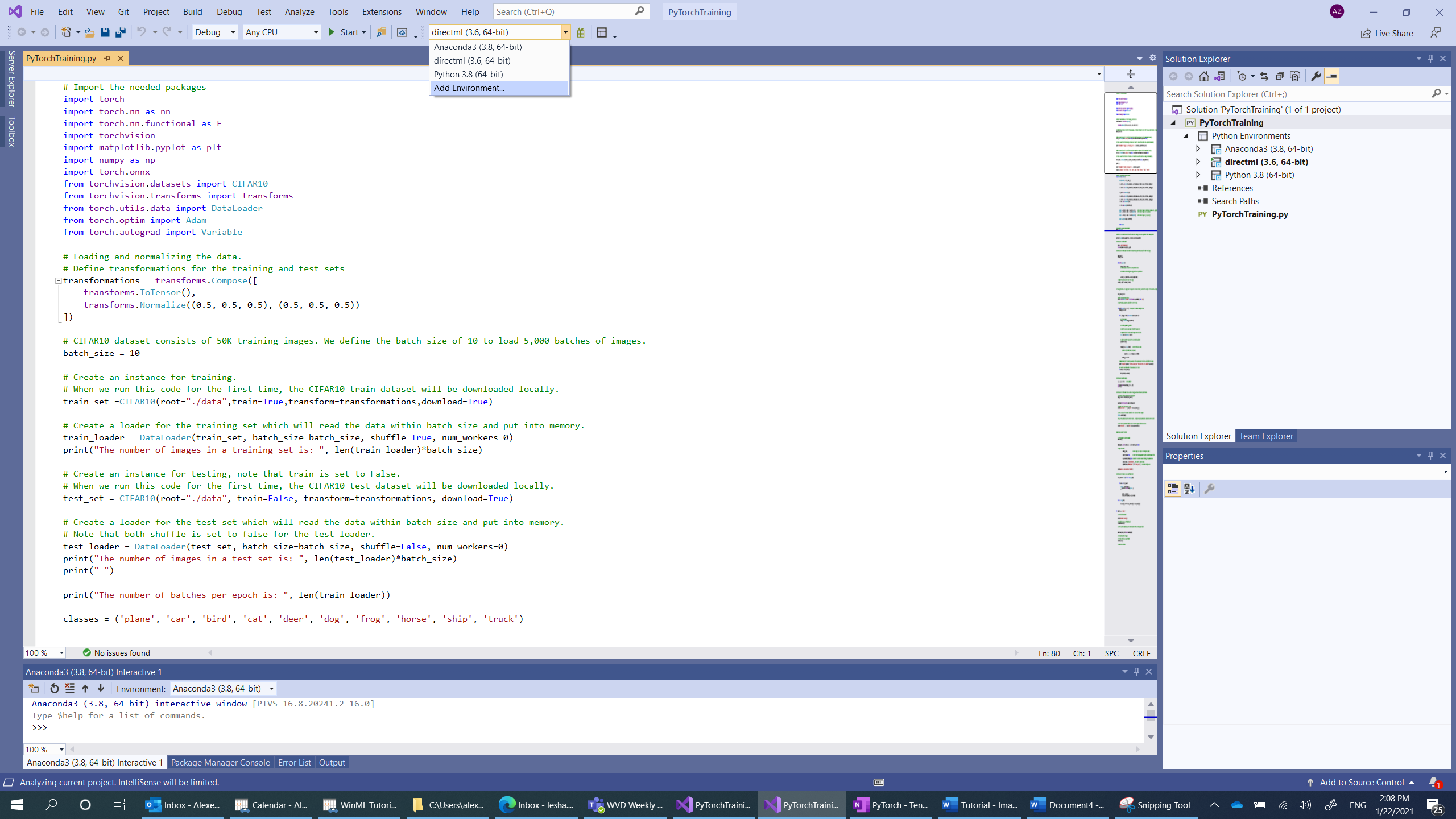
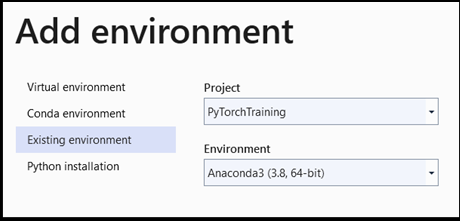
- En la ventana
Add environment, seleccioneExisting environmenty elijaAnaconda3 (3.6, 64-bit). Esta opción incluye el paquete de PyTorch.
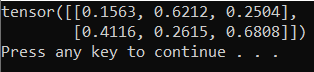
Para probar el nuevo intérprete de Python y el paquete de PyTorch, escriba el código siguiente en el archivo PyTorchTraining.py:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
El resultado debe ser un tensor aleatorio de 5 x 3 similar al siguiente.
Nota:
¿Quiere saber más sobre el tema? Visite el sitio web oficial de PyTorch.
Carga del conjunto de datos
Usará la clase torchvision de PyTorch para cargar los datos.
La biblioteca de Torchvision incluye varios conjuntos de datos conocidos, como Imagenet, CIFAR10, MNIST, etc., arquitecturas de modelos y transformaciones de imagen comunes para Computer Vision. Esto facilita bastante la carga de datos en PyTorch.
CIFAR10
Aquí usaremos el conjunto de datos CIFAR10 para compilar y entrenar el modelo de clasificación de imágenes. CIFAR10 es un conjunto de datos que se usa con frecuencia para la investigación del aprendizaje automático. Consta de 50 000 imágenes de entrenamiento y 10 000 imágenes de prueba. Todas ellas tienen un tamaño de 3 x 32 x 32, lo que significa que son imágenes de color de 3 canales de 32 x 32 píxeles de tamaño.
Las imágenes se dividen en 10 clases: "avión" (0), "automóvil" (1), "pájaro" (2), "gato" (3), "ciervo" (4), "perro" (5), "rana" (6), "'caballo" (7), "barco" (8), "camión" (9).
Tiene que seguir tres pasos para cargar y leer el conjunto de datos CIFAR10 en PyTorch:
- Defina las transformaciones que se aplicarán a la imagen: para entrenar el modelo, debe transformar las imágenes en tensores de intervalo normalizado [-1,1].
- Cree una instancia del conjunto de datos disponible y cargue el conjunto de datos: para cargar los datos, usará la clase
torch.utils.data.Dataset, que es una clase abstracta para representar un conjunto de datos. El conjunto de datos se descargará localmente solo la primera vez que ejecute el código. - Acceda a los datos mediante DataLoader. Para obtener acceso a los datos y colocarlos en la memoria, tendrá que usar la clase
torch.utils.data.DataLoader. DataLoader en PyTorch encapsula un conjunto de datos y proporciona acceso a los datos subyacentes. Este contenedor contendrá lotes de imágenes por tamaño de lote definido.
Tiene que repetir estos tres pasos para los conjuntos de entrenamiento y prueba.
- Abra
PyTorchTraining.py fileen Visual Studio y agregue el código siguiente. Esta opción controla los tres pasos anteriores de los conjuntos de datos de entrenamiento y prueba del conjunto de datos CIFAR10.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
La primera vez que ejecute este código, el conjunto de datos CIFAR10 se descargará en el dispositivo.

Pasos siguientes
Con los datos listos para usar, es el momento de entrenar nuestro modelo de PyTorch.