Creación de vistas personalizadas de objetos de C++ en el depurador mediante el marco natvis
El marco Natvis de Visual Studio personaliza la forma en la que se muestran los tipos nativos en las ventanas de variables del depurador, como las ventanas Locales e Inspección, y en Información sobre datos. Las visualizaciones de Natvis pueden ayudar a que los tipos que cree sean más visibles durante la depuración.
Natvis reemplaza el archivo autoexp.dat en versiones anteriores de Visual Studio por sintaxis XML, mejores diagnósticos, control de versiones y compatibilidad con varios archivos.
Nota
Las personalizaciones de Natvis funcionan con clases y estructuras, pero no con definiciones de tipo.
Visualizaciones de Natvis
Use el marco Natvis para crear reglas de visualización para los tipos que cree, de modo que los desarrolladores puedan verlos más fácilmente durante la depuración.
Por ejemplo, en la siguiente ilustración se muestra una variable de tipo Windows::UI::XAML::Controls::TextBox en una ventana del depurador sin ninguna visualización personalizada aplicada.
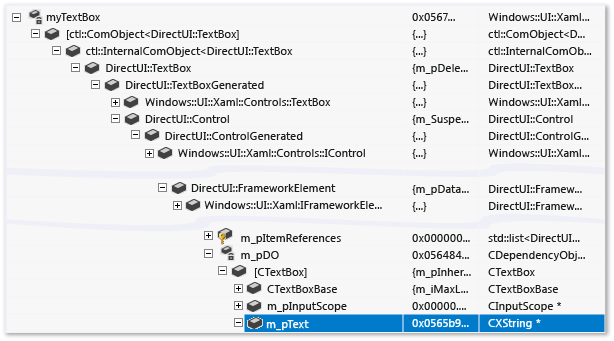
La fila resaltada muestra la propiedad Text de la clase TextBox. La jerarquía de clases compleja dificulta la búsqueda de esta propiedad. El depurador no sabe cómo interpretar el tipo de cadena personalizado, por lo que no puede ver la cadena contenida dentro del cuadro de texto.
El mismo TextBox parece mucho más sencillo en la ventana de variables cuando se aplican las reglas del visualizador personalizado de Natvis. Los miembros importantes de la clase aparecen juntos y el depurador muestra el valor de cadena subyacente del tipo de cadena personalizado.

Uso de archivos .natvis en proyectos de C++
Natvis usa archivos .natvis para especificar las reglas de visualización. Un archivo .natvis es un archivo XML con una extensión de .natvis. El esquema Natvis se define en <carpeta de instalación de VS>\Xml\Schemas\1033\natvis.xsd.
La estructura básica de un archivo de .natvis es uno o varios elementos Type que representan entradas de visualización. El nombre completo de cada elemento Type se especifica en su atributo Name.
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="MyNamespace::CFoo">
.
.
</Type>
<Type Name="...">
.
.
</Type>
</AutoVisualizer>
Visual Studio proporciona algunos archivos .natvis en la <Carpeta de instalación>\Common7\Packages\Debugger\Visualizers. Estos archivos tienen reglas de visualización para muchos tipos comunes y pueden servir como ejemplos para escribir visualizaciones para nuevos tipos.
Agregar un archivo .natvis a un proyecto de C++
Puede agregar un archivo de .natvis a cualquier proyecto de C++.
Para agregar un nuevo archivo .natvis:
Seleccione el nodo del proyecto de C++ en explorador de solucionesy seleccione Proyecto>Agregar nuevo elementoo haga clic con el botón derecho en el proyecto y seleccione Agregar>Nuevo elemento.
Si no ve todas las plantillas de elemento, elija Mostrar todas las plantillas.
En el cuadro de diálogo Agregar nuevo elemento, seleccione Visual C++>Utilidad>Archivo de visualización del depurador (.natvis).
Asigne un nombre al archivo y seleccione Agregar.
El nuevo archivo se agrega a Explorador de solucionesy se abre en el panel de documentos de Visual Studio.
El depurador de Visual Studio carga automáticamente los archivos .natvis en los proyectos de C++ y, de forma predeterminada, también los incluye en el archivo .pdb cuando el proyecto se compila. Si depura la aplicación de compilación, el depurador carga el archivo .natvis desde el archivo .pdb aunque no tenga el proyecto abierto. Si no desea que el archivo .natvis esté incluido en el archivo .pdb, puede excluirlo del archivo .pdb resultante.
Para excluir un archivo .natvis de un .pdb:
Seleccione el archivo .natvis en Explorador de soluciones, y seleccione el icono Propiedades, o haga clic con el botón derecho en el archivo y seleccione Propiedades.
Despliegue la lista de la flecha situada junto a Excluir de la compilación y seleccione Sí. Después, seleccione Aceptar.
Nota
Para los proyectos ejecutables de depuración, use los elementos de la solución para agregar los archivos .natvis que no estén en ningún archivo .pdb, ya que no hay ningún proyecto de C++ disponible.
Nota
Las reglas Natvis cargadas desde un .pdb solo se aplican a los tipos de los módulos a los que el .pdb de hace referencia. Por ejemplo, si Module1.pdb tiene una entrada Natvis para un tipo denominado Test, solo se aplica a la clase Test de Module1.dll. Si otro módulo también define una clase denominada Test, el Module1.pdb entrada Natvis no se aplica a él.
Para instalar y registrar un archivo de .natvis a través de un paquete VSIX:
Un paquete VSIX puede instalar y registrar archivos .natvis. Independientemente de dónde se instalen, todos los archivos .natvis registrados se seleccionan automáticamente durante la depuración.
Incluya el archivo .natvis en el paquete VSIX. Por ejemplo, para el siguiente archivo de proyecto:
<?xml version="1.0" encoding="utf-8"?> <Project DefaultTargets="Build" xmlns="http://schemas.microsoft.com/developer/msbuild/2003" ToolsVersion="14.0"> <ItemGroup> <VSIXSourceItem Include="Visualizer.natvis" /> </ItemGroup> </Project>Registre el archivo .natvis en el archivo source.extension.vsixmanifest:
<?xml version="1.0" encoding="utf-8"?> <PackageManifest Version="2.0.0" xmlns="http://schemas.microsoft.com/developer/vsx-schema/2011" xmlns:d="http://schemas.microsoft.com/developer/vsx-schema-design/2011"> <Assets> <Asset Type="NativeVisualizer" Path="Visualizer.natvis" /> </Assets> </PackageManifest>
Ubicaciones de archivos Natvis
Puede agregar archivos .natvis al directorio del usuario o a un directorio del sistema si quiere que se apliquen a varios proyectos.
Los archivos de .natvis se evalúan en el orden siguiente:
Los archivos .natvis insertados en un archivo .pdb que esté depurando, a menos que exista un archivo con el mismo nombre en un proyecto cargado.
Los archivos .natvis que se encuentren en un proyecto de C++ cargado o en una solución de nivel superior. Este grupo incluye todos los proyectos de C++ cargados, incluidas las bibliotecas de clases, pero no los proyectos de otros lenguajes.
Cualesquiera archivos .natvis instalados y registrados mediante un paquete VSIX.
- Directorio Natvis específico del usuario (por ejemplo, %USERPROFILE%\Documents\Visual Studio 2022\Visualizers).
- Directorio Natvis específico del usuario (por ejemplo, %USERPROFILE%\Documents\Visual Studio 2019\Visualizers).
- Directorio Natvis para todo el sistema (<carpeta de instalación de Microsoft Visual Studio>\Common7\Packages\Debugger\Visualizers). Este directorio tiene los archivos .natvis que están instalados con Visual Studio. Si tiene permisos de administrador, puede agregar archivos a este directorio.
Modificación de archivos .natvis durante la depuración
Puede modificar un archivo .natvis en el IDE mientras se depura su proyecto. Abra el archivo en la misma instancia de Visual Studio que está usando para depurar, modifíquelo y guárdelo. Cuando haya guardado el archivo, las ventanas Inspección y Locales se actualizan para reflejar el cambio.
También puede agregar o eliminar archivos .natvis en una solución que esté depurando, y Visual Studio agregará o quitará las visualizaciones pertinentes.
Durante la depuración, no puede actualizar archivos de .natvis insertados en archivos .pdb.
Si modifica el archivo .natvis fuera de Visual Studio, los cambios no surten efecto automáticamente. Para actualizar las ventanas del depurador, puede reevaluar el comando .natvisreload en la ventana Inmediato. Después, los cambios surtirán efecto sin tener que reiniciar la sesión de depuración.
Use también el comando .natvisreload para actualizar el archivo .natvis a una versión más reciente. Por ejemplo, se puede insertar el archivo .natvis en el repositorio del control de código fuente y puede recopilar los cambios recientes hechos por otra persona.
Expresiones y formato
Las visualizaciones de Natvis usan expresiones de C++ para especificar los elementos de datos que se van a mostrar. Además de las mejoras y limitaciones de las expresiones de C++ en el depurador, que se describen en operador context (C++), tenga en cuenta lo siguiente:
Las expresiones Natvis se evalúan en el contexto del objeto que se visualiza, no el marco de pila actual. Por ejemplo,
xen una expresión natvis hace referencia al campo denominado x en el objeto que se está visualizando, no a una variable local denominada x en la función actual. No se puede acceder a variables locales en expresiones natvis, aunque puede acceder a variables globales.Las expresiones Natvis no permiten la evaluación de funciones ni los efectos secundarios. Esto significa que se omiten las llamadas de función y los operadores de asignación. Puesto que las funciones intrínsecas del depurador no tienen efectos secundarios, pueden llamarse libremente desde cualquier expresión Natvis aunque no se permitan otras llamadas de función.
Para controlar cómo se muestra una expresión, puede usar cualquiera de los especificadores de formato descritos en Especificadores de formato en C++. Los especificadores de formato se omiten cuando Natvis usa internamente la entrada, como la expresión
Sizeen una expansión ArrayItems.
Nota
Como el documento Natvis tiene el formato XML, las expresiones no pueden usar directamente los operadores de desplazamiento ni los operadores Y comercial, Mayor que ni Menor que. Debe escapar estos caracteres tanto en el cuerpo del elemento como en las instrucciones de la condición. Por ejemplo:
\<Item Name="HiByte"\>(byte)(_flags \>\> 24),x\</Item\>
\<Item Name="HiByteStatus" Condition="(_flags \& 0xFF000000) == 0"\>"None"\</Item\>
\<Item Name="HiByteStatus" Condition="(_flags \& 0xFF000000) != 0"\>"Some"\</Item\>
Vistas de Natvis
Puede definir diferentes vistas de Natvis para mostrar tipos de diferentes maneras. Por ejemplo, esta es una visualización de std::vector que define una vista simplificada denominada simple. Los elementos DisplayString y ArrayItems se muestran en la vista predeterminada y en la vista simple, mientras que los elementos [size] y [capacity] no se muestran en la vista simple.
<Type Name="std::vector<*>">
<DisplayString>{{ size={_Mylast - _Myfirst} }}</DisplayString>
<Expand>
<Item Name="[size]" ExcludeView="simple">_Mylast - _Myfirst</Item>
<Item Name="[capacity]" ExcludeView="simple">_Myend - _Myfirst</Item>
<ArrayItems>
<Size>_Mylast - _Myfirst</Size>
<ValuePointer>_Myfirst</ValuePointer>
</ArrayItems>
</Expand>
</Type>
En la ventana Inspección, use el especificador de formato ,view para especificar una vista distinta. La vista simple aparece como vec,view(simple):

Errores de Natvis
Cuando el depurador encuentra errores en una entrada de visualización, los omite. Muestra el tipo en su forma sin procesar o elige otra visualización adecuada. Puede usar los diagnósticos de Natvis para comprender por qué el depurador omitió una entrada de visualización y para ver la sintaxis subyacente y analizar los errores.
Para activar el diagnóstico de Natvis:
- En Herramientas>Opciones (o Depurar>Opciones) >Depuración>Ventana de salida, establezca Mensajes de diagnóstico de natvis (solo C++) en Error, Advertencia o Detallado y después seleccione Aceptar.
Los errores se muestran en la ventana Resultados.
Referencia de sintaxis de Natvis
Los siguientes elementos y atributos se pueden usar en el archivo Natvis.
Elemento AutoVisualizer
El elemento AutoVisualizer es el nodo raíz del archivo .natvis y contiene el atributo xmlns: del espacio de nombres.
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
.
.
</AutoVisualizer>
El elemento AutoVisualizer puede tener elementos secundarios Type, HResult, UIVisualizer y CustomVisualizer.
Elemento de tipo
Un Type básico tiene el siguiente aspecto:
<Type Name="[fully qualified type name]">
<DisplayString Condition="[Boolean expression]">[Display value]</DisplayString>
<Expand>
...
</Expand>
</Type>
El elemento Type especifica:
Para qué tipo se debe usar la visualización (el atributo
Name).Cómo debería aparecer el valor de un objeto de ese tipo (el elemento
DisplayString).Qué aspecto deben tener los miembros del tipo cuando el usuario expanda el tipo en una ventana variable (el nodo
Expand).
Clases con plantilla
El atributo Name del elemento Type acepta un * de asterisco como carácter comodín que se puede usar para los nombres de clase con plantilla.
En el ejemplo siguiente, se usa la misma visualización si el objeto es un CAtlArray<int> o un CAtlArray<float>. Si hay una entrada de visualización específica para un CAtlArray<float>, tiene prioridad sobre la genérica.
<Type Name="ATL::CAtlArray<*>">
<DisplayString>{{Count = {m_nSize}}}</DisplayString>
</Type>
Puede hacer referencia a parámetros de plantilla en la entrada de visualización mediante macros $T 1, $T 2, etc. Para encontrar ejemplos de estas macros, consulte los archivos de .natvis enviados con Visual Studio.
Coincidencia de tipos del visualizador
Si no se puede validar una entrada de visualización, se usa la siguiente visualización disponible.
Atributo heredable
El atributo opcional Inheritable especifica si una visualización solo se aplica a un tipo base o a un tipo base y a todos los tipos derivados. El valor predeterminado de Inheritable es true.
En el ejemplo siguiente, la visualización solo se aplica al tipo de BaseClass:
<Type Name="Namespace::BaseClass" Inheritable="false">
<DisplayString>{{Count = {m_nSize}}}</DisplayString>
</Type>
Atributo de Prioridad
El atributo opcional Priority especifica el orden en el que usar definiciones alternativas, si una definición no se puede analizar. Los valores posibles de Priority son: Low, MediumLow,Medium, MediumHighy High. El valor predeterminado es Medium. El atributo Priority distingue solo entre las prioridades del mismo archivo .natvis.
En el ejemplo siguiente se analiza primero la entrada que coincide con el STL de 2015. Si no se puede analizar, usa la entrada alternativa para la versión 2013 de STL:
<!-- VC 2013 -->
<Type Name="std::reference_wrapper<*>" Priority="MediumLow">
<DisplayString>{_Callee}</DisplayString>
<Expand>
<ExpandedItem>_Callee</ExpandedItem>
</Expand>
</Type>
<!-- VC 2015 -->
<Type Name="std::reference_wrapper<*>">
<DisplayString>{*_Ptr}</DisplayString>
<Expand>
<Item Name="[ptr]">_Ptr</Item>
</Expand>
</Type>
Atributo opcional
Puede colocar un atributo Optional en cualquier nodo. Si una subexpresión dentro de un nodo opcional no puede analizarse, el depurador omite ese nodo, pero aplica el resto de las reglas de Type. En el siguiente tipo, [State] no es opcional, pero [Exception] es opcional. Si MyNamespace::MyClass tiene un campo denominado _M_exceptionHolder, aparecen tanto el nodo [State] como el nodo [Exception], pero si no hay ningún campo _M_exceptionHolder, solo aparece el nodo [State].
<Type Name="MyNamespace::MyClass">
<Expand>
<Item Name="[State]">_M_State</Item>
<Item Name="[Exception]" Optional="true">_M_exceptionHolder</Item>
</Expand>
</Type>
Atributo Condition
El atributo opcional Condition está disponible para muchos elementos de visualización y especifica cuándo usar una regla de visualización. Si la expresión dentro del atributo condition se resuelve en false, la regla de visualización no se aplica. Si el resultado es true, o no hay ningún atributo Condition, se aplica la visualización. Puede usar este atributo para la lógica if-else en las entradas de visualización.
Por ejemplo, la siguiente visualización tiene dos elementos DisplayString para un tipo de puntero inteligente. Cuando el miembro _Myptr está vacío, la condición del primer elemento DisplayString se resuelve en true, de modo que se muestre el formulario. Cuando el miembro _Myptr no está vacío, la condición se evalúa como falsey se muestra el segundo elemento DisplayString.
<Type Name="std::auto_ptr<*>">
<DisplayString Condition="_Myptr == 0">empty</DisplayString>
<DisplayString>auto_ptr {*_Myptr}</DisplayString>
<Expand>
<ExpandedItem>_Myptr</ExpandedItem>
</Expand>
</Type>
Atributos IncludeView y ExcludeView
Los atributos IncludeView y ExcludeView especifican elementos que se van a mostrar o no en vistas específicas. Por ejemplo, en la siguiente especificación natvis de std::vector, la vista simple no muestra los elementos [size] y [capacity].
<Type Name="std::vector<*>">
<DisplayString>{{ size={_Mylast - _Myfirst} }}</DisplayString>
<Expand>
<Item Name="[size]" ExcludeView="simple">_Mylast - _Myfirst</Item>
<Item Name="[capacity]" ExcludeView="simple">_Myend - _Myfirst</Item>
<ArrayItems>
<Size>_Mylast - _Myfirst</Size>
<ValuePointer>_Myfirst</ValuePointer>
</ArrayItems>
</Expand>
</Type>
Puede usar los atributos IncludeView y ExcludeView en tipos y en miembros individuales.
Elemento Version
El Version elemento limita una entrada de visualización a un módulo y una versión específicos. El elemento Version ayuda a evitar conflictos de nombres, reduce las discrepancias involuntarias y permite diferentes visualizaciones para distintas versiones de tipo.
Si un archivo de encabezado común que usan los distintos módulos define un tipo, la visualización con versiones solo aparece cuando el tipo está en la versión del módulo especificada.
En el ejemplo siguiente, la visualización solo es aplicable al tipo de DirectUI::Border que se encuentra en el Windows.UI.Xaml.dll de la versión 1.0 a la 1.5.
<Type Name="DirectUI::Border">
<Version Name="Windows.UI.Xaml.dll" Min="1.0" Max="1.5"/>
<DisplayString>{{Name = {*(m_pDO->m_pstrName)}}}</DisplayString>
<Expand>
<ExpandedItem>*(CBorder*)(m_pDO)</ExpandedItem>
</Expand>
</Type>
No necesita ninguno de los dos atributos Min y Max. Son atributos opcionales. No se admite el uso de caracteres comodín.
El atributo Name tiene el formato filename.ext, como hello.exe o some.dll. No se permite el uso de nombres de ruta.
Elemento DisplayString
El elemento DisplayString especifica una cadena que se va a mostrar como el valor de una variable. Acepta cadenas arbitrarias mezcladas con expresiones. Todos los datos encerrados entre llaves se interpretan como una expresión. Por ejemplo, la siguiente entrada DisplayString:
<Type Name="CPoint">
<DisplayString>{{x={x} y={y}}}</DisplayString>
</Type>
Significa que las variables de tipo CPoint se muestran como en esta ilustración:

En la expresión DisplayString, x e y, que son miembros de CPoint, se encuentran dentro de llaves, por lo que se evalúan sus valores. En el ejemplo también se muestra cómo se puede omitir una llave con llaves dobles ({{ o }}).
Nota
El elemento DisplayString es el único que acepta cadenas arbitrarias y la sintaxis de llaves. Todos los demás elementos de visualización solo aceptan expresiones que el depurador puede evaluar.
Elemento StringView
El elemento StringView define un valor que el depurador puede enviar al visualizador de texto integrado. Por ejemplo, la siguiente visualización para el tipo ATL::CStringT sería:
<Type Name="ATL::CStringT<wchar_t,*>">
<DisplayString>{m_pszData,su}</DisplayString>
</Type>
El objeto CStringT se muestra en una ventana variable como en este ejemplo:

Agregar un elemento StringView indica al depurador que puede mostrar el valor como una visualización de texto.
<Type Name="ATL::CStringT<wchar_t,*>">
<DisplayString>{m_pszData,su}</DisplayString>
<StringView>m_pszData,su</StringView>
</Type>
Durante la depuración, puede seleccionar el icono de lupa situado junto a la variable y después seleccionar Visualizador de texto para mostrar la cadena a la que dirige m_pszData.

La expresión {m_pszData,su} incluye un especificador de formato de C++ su, para mostrar el valor como una cadena Unicode. Para obtener más información, vea Especificadores de formato en C++.
Expandir elemento
El nodo opcional Expand personaliza los elementos secundarios de un tipo visualizado al expandir el tipo en una ventana de variables. El nodo Expand acepta una lista de nodos secundarios que definen los elementos secundarios.
Si no se especifica ningún nodo
Expanden una entrada de visualización, los elementos secundarios usarán las reglas predeterminadas de expansión.Si se especifica un nodo
Expandsin nodos secundarios en él, el tipo no se puede expandir en las ventanas del depurador.
Expansión de Item
El elemento Item es el elemento más básico y común de un nodo Expand. Item define un único elemento secundario. Por ejemplo, una clase CRect con campos top, left, righty bottom tiene la siguiente entrada de visualización:
<Type Name="CRect">
<DisplayString>{{top={top} bottom={bottom} left={left} right={right}}}</DisplayString>
<Expand>
<Item Name="Width">right - left</Item>
<Item Name="Height">bottom - top</Item>
</Expand>
</Type>
En la ventana del depurador, el tipo CRect es similar al de este ejemplo:

El depurador evalúa las expresiones especificadas en los elementos Width y Height, y muestra los valores de la columna Value de la ventana de variables.
El depurador crea automáticamente el nodo [Raw View] para cada expansión personalizada. En la captura de pantalla anterior se muestra el nodo [Vista sin procesar] expandido, para mostrar cómo difiere la vista sin procesar predeterminada del objeto de la visualización de Natvis. La expansión predeterminada crea un subárbol para la clase base y enumera todos los miembros de datos de la clase base como elementos secundarios.
Nota
Si la expresión del elemento del ítem apunta a un tipo complejo, el nodo Item en sí se puede expandir.
ArrayItems expansion
Use el nodo ArrayItems para que el depurador de Visual Studio interprete el tipo como una matriz y muestre sus elementos individuales. La visualización de std::vector es un buen ejemplo:
<Type Name="std::vector<*>">
<DisplayString>{{size = {_Mylast - _Myfirst}}}</DisplayString>
<Expand>
<Item Name="[size]">_Mylast - _Myfirst</Item>
<Item Name="[capacity]">(_Myend - _Myfirst)</Item>
<ArrayItems>
<Size>_Mylast - _Myfirst</Size>
<ValuePointer>_Myfirst</ValuePointer>
</ArrayItems>
</Expand>
</Type>
Un std::vector muestra sus elementos individuales cuando se expande en la ventana de variables:

El nodo ArrayItems debe tener:
- Expresión
Size(que debe evaluarse como un entero) para que el depurador comprenda la longitud de la matriz. - Expresión
ValuePointerque apunta al primer elemento (que debe ser un puntero de un tipo de elemento que no esvoid*).
El valor predeterminado del límite inferior de la matriz es 0. Para invalidar el valor, use un elemento LowerBound. Los archivos de .natvis enviados con Visual Studio tienen ejemplos.
Nota
Puede usar el operador [], por ejemplo, vector[i], con cualquier visualización de matriz unidimensional que use ArrayItems, incluso si el propio tipo (por ejemplo, CATLArray) no permite este operador.
También puede especificar matrices multidimensionales. En ese caso, el depurador necesita un poco más de información para mostrar correctamente los elementos secundarios:
<Type Name="Concurrency::array<*,*>">
<DisplayString>extent = {_M_extent}</DisplayString>
<Expand>
<Item Name="extent">_M_extent</Item>
<ArrayItems Condition="_M_buffer_descriptor._M_data_ptr != 0">
<Direction>Forward</Direction>
<Rank>$T2</Rank>
<Size>_M_extent._M_base[$i]</Size>
<ValuePointer>($T1*) _M_buffer_descriptor._M_data_ptr</ValuePointer>
<LowerBound>0</LowerBound>
</ArrayItems>
</Expand>
</Type>
Directionespecifica si la matriz está en orden de fila principal o de columna principal.Rankespecifica el rango de la matriz.- El elemento
Sizeacepta el parámetro$iimplícito, que sustituye por el índice de dimensión para encontrar la longitud de la matriz en esa dimensión.- En el ejemplo anterior, la expresión
_M_extent.M_base[0]debe proporcionar la longitud de la dimensión 0,_M_extent._M_base[1]la primera, etc.
- En el ejemplo anterior, la expresión
- El
LowerBoundespecifica el límite inferior de cada dimensión de la matriz. Para matrices multidimensionales, puede especificar una expresión que use el parámetro$iimplícito. El parámetro$ise sustituirá por el índice de dimensión para buscar el límite inferior de la matriz en esa dimensión.- En el ejemplo anterior, todas las dimensiones comenzarán en 0. Sin embargo, si tuviera
($i == 1) ? 1000 : 100como límite inferior, la dimensión 0 comenzará en 100 y la primera dimensión comenzará en 1000.- , como
[100, 1000], [100, 1001], [100, 1002], ... [101, 1000], [101, 1001],...
- , como
- En el ejemplo anterior, todas las dimensiones comenzarán en 0. Sin embargo, si tuviera
Este es el aspecto de un objeto Concurrency::array bidimensional en la ventana del depurador:
es-ES: 
Expansión de IndexListItems
Puede utilizar la expansión de ArrayItems solo si los elementos de la matriz están dispuestos de forma contigua en la memoria. El depurador obtiene el elemento siguiente simplemente al incrementar el puntero. Si necesita manipular el índice del nodo de valor, use nodos IndexListItems. Esta es una visualización con un nodo IndexListItems:
<Type Name="Concurrency::multi_link_registry<*>">
<DisplayString>{{size = {_M_vector._M_index}}}</DisplayString>
<Expand>
<Item Name="[size]">_M_vector._M_index</Item>
<IndexListItems>
<Size>_M_vector._M_index</Size>
<ValueNode>*(_M_vector._M_array[$i])</ValueNode>
</IndexListItems>
</Expand>
</Type>
La única diferencia entre ArrayItems y IndexListItems es ValueNode, que espera la expresión completa para el elemento ith con el parámetro implícito $i.
Nota
Puede usar el operador [], por ejemplo, vector[i], con cualquier visualización de matriz unidimensional que use IndexListItems, incluso si el propio tipo (por ejemplo, CATLArray) no permite este operador.
Expansión de LinkedListItems
Si el tipo visualizado representa una lista vinculada, el depurador puede mostrar sus elementos secundarios si se usa un nodo LinkedListItems. La siguiente visualización del tipo de CAtlList usa LinkedListItems:
<Type Name="ATL::CAtlList<*,*>">
<DisplayString>{{Count = {m_nElements}}}</DisplayString>
<Expand>
<Item Name="Count">m_nElements</Item>
<LinkedListItems>
<Size>m_nElements</Size>
<HeadPointer>m_pHead</HeadPointer>
<NextPointer>m_pNext</NextPointer>
<ValueNode>m_element</ValueNode>
</LinkedListItems>
</Expand>
</Type>
El elemento Size hace referencia a la longitud de la lista. HeadPointer apunta al primer elemento, NextPointer hace referencia al elemento siguiente y ValueNode hace referencia al valor del elemento.
El depurador evalúa las expresiones NextPointer y ValueNode en el contexto del elemento de nodo LinkedListItems, no el tipo de lista principal. En el ejemplo anterior, CAtlList tiene una clase CNode (que se encuentra en atlcoll.h) que es un nodo de la lista vinculada. m_pNext y m_element son campos de esa clase CNode, no de la clase CAtlList.
ValueNode puede dejarse vacío o usar this para hacer referencia al propio nodo LinkedListItems.
Expansión de CustomListItems
La expansión de CustomListItems permite escribir lógica personalizada para recorrer una estructura de datos, como una tabla hash. Utiliza CustomListItems para visualizar estructuras de datos que pueden emplear expresiones de C++ para todo lo que necesitas evaluar, pero que no encajan del todo en el molde de ArrayItems, IndexListItemso LinkedListItems.
Puede usar Exec para ejecutar código dentro de una expansión de CustomListItems, mediante las variables y los objetos definidos en la expansión. Puede usar operadores lógicos, operadores aritméticos y operadores de asignación con Exec. No se puede usar Exec para evaluar funciones, salvo funciones intrínsecas del depurador admitidas por el evaluador de expresiones de C++.
El siguiente visualizador para CAtlMap es un excelente ejemplo en el que CustomListItems es adecuado.
<Type Name="ATL::CAtlMap<*,*,*,*>">
<AlternativeType Name="ATL::CMapToInterface<*,*,*>"/>
<AlternativeType Name="ATL::CMapToAutoPtr<*,*,*>"/>
<DisplayString>{{Count = {m_nElements}}}</DisplayString>
<Expand>
<CustomListItems MaxItemsPerView="5000" ExcludeView="Test">
<Variable Name="iBucket" InitialValue="-1" />
<Variable Name="pBucket" InitialValue="m_ppBins == nullptr ? nullptr : *m_ppBins" />
<Variable Name="iBucketIncrement" InitialValue="-1" />
<Size>m_nElements</Size>
<Exec>pBucket = nullptr</Exec>
<Loop>
<If Condition="pBucket == nullptr">
<Exec>iBucket++</Exec>
<Exec>iBucketIncrement = __findnonnull(m_ppBins + iBucket, m_nBins - iBucket)</Exec>
<Break Condition="iBucketIncrement == -1" />
<Exec>iBucket += iBucketIncrement</Exec>
<Exec>pBucket = m_ppBins[iBucket]</Exec>
</If>
<Item>pBucket,na</Item>
<Exec>pBucket = pBucket->m_pNext</Exec>
</Loop>
</CustomListItems>
</Expand>
</Type>
Expansión de TreeItems
Si el tipo visualizado representa un árbol, el depurador puede recorrer el árbol y mostrar sus elementos secundarios utilizando un nodo TreeItems. Esta es la visualización del tipo std::map mediante un nodo TreeItems.
<Type Name="std::map<*>">
<DisplayString>{{size = {_Mysize}}}</DisplayString>
<Expand>
<Item Name="[size]">_Mysize</Item>
<Item Name="[comp]">comp</Item>
<TreeItems>
<Size>_Mysize</Size>
<HeadPointer>_Myhead->_Parent</HeadPointer>
<LeftPointer>_Left</LeftPointer>
<RightPointer>_Right</RightPointer>
<ValueNode Condition="!((bool)_Isnil)">_Myval</ValueNode>
</TreeItems>
</Expand>
</Type>
La sintaxis es similar al nodo LinkedListItems. LeftPointer, RightPointery ValueNode se evalúan bajo el contexto de la clase de nodo de árbol. ValueNode puede dejarse vacío o usar this para hacer referencia al propio nodo TreeItems.
Expansión de ExpandedItem
El elemento ExpandedItem genera una visualización secundaria agregada que muestra las propiedades de las clases base o los miembros de datos como si fueran elementos secundarios del tipo visualizado. El depurador evalúa la expresión especificada y agrega los nodos secundarios del resultado a la lista secundaria del tipo visualizado.
Por ejemplo, el tipo de puntero inteligente auto_ptr<vector<int>> normalmente se muestra como:

Para ver los valores del vector, debe explorar en profundidad dos niveles en la ventana de variables, pasando por el miembro _Myptr. Al agregar un elemento ExpandedItem, puede eliminar la variable _Myptr de la jerarquía y ver directamente los elementos vectoriales:
<Type Name="std::auto_ptr<*>">
<DisplayString>auto_ptr {*_Myptr}</DisplayString>
<Expand>
<ExpandedItem>_Myptr</ExpandedItem>
</Expand>
</Type>

En el ejemplo siguiente se muestra cómo agregar propiedades de la clase base en una clase derivada. Supongamos que la clase CPanel deriva de CFrameworkElement. En lugar de repetir las propiedades que proceden de la clase base CFrameworkElement, la visualización del nodo ExpandedItem anexa esas propiedades a la lista secundaria de la clase CPanel.
<Type Name="CPanel">
<DisplayString>{{Name = {*(m_pstrName)}}}</DisplayString>
<Expand>
<Item Name="IsItemsHost">(bool)m_bItemsHost</Item>
<ExpandedItem>*(CFrameworkElement*)this,nd</ExpandedItem>
</Expand>
</Type>
El especificador de formato nd, que desactiva la coincidencia de visualización para la clase derivada, es necesario aquí. De lo contrario, la expresión *(CFrameworkElement*)this haría que la visualización del CPanel se aplicara de nuevo, ya que las reglas de coincidencia de tipos de visualización predeterminadas lo consideran el más adecuado. Use el especificador de formato nd para indicar al depurador que use la visualización de la clase base o la expansión predeterminada si la clase base no tiene ninguna visualización.
Expansión de elementos sintéticos
Aunque el elemento ExpandedItem proporciona una vista más plana de los datos eliminando jerarquías, el nodo Synthetic hace lo contrario. Permite crear un elemento secundario artificial que no sea el resultado de una expresión. El elemento artificial puede tener elementos secundarios propios. En el ejemplo siguiente, la visualización del tipo Concurrency::array usa un nodo Synthetic para mostrar un mensaje de diagnóstico al usuario:
<Type Name="Concurrency::array<*,*>">
<DisplayString>extent = {_M_extent}</DisplayString>
<Expand>
<Item Name="extent" Condition="_M_buffer_descriptor._M_data_ptr == 0">_M_extent</Item>
<ArrayItems Condition="_M_buffer_descriptor._M_data_ptr != 0">
<Rank>$T2</Rank>
<Size>_M_extent._M_base[$i]</Size>
<ValuePointer>($T1*) _M_buffer_descriptor._M_data_ptr</ValuePointer>
</ArrayItems>
<Synthetic Name="Array" Condition="_M_buffer_descriptor._M_data_ptr == 0">
<DisplayString>Array members can be viewed only under the GPU debugger</DisplayString>
</Synthetic>
</Expand>
</Type>

Expansión intrínseca
Función intrínseca personalizada a la que se puede llamar desde una expresión. Un elemento <Intrinsic> debe estar acompañado de un componente de depuración que implemente la función mediante la interfaz IDkmIntrinsicFunctionEvaluator140. Para obtener más información sobre cómo implementar una función intrínseca personalizada, consulte Implementación de una función intrínseca personalizada de NatVis.
<Type Name="std::vector<*>">
<Intrinsic Name="size" Expression="(size_t)(_Mypair._Myval2._Mylast - _Mypair._Myval2._Myfirst)" />
<Intrinsic Name="capacity" Expression="(size_t)(_Mypair._Myval2._Myend - _Mypair._Myval2._Myfirst)" />
<DisplayString>{{ size={size()} }}</DisplayString>
<Expand>
<Item Name="[capacity]" ExcludeView="simple">capacity()</Item>
<Item Name="[allocator]" ExcludeView="simple">_Mypair</Item>
<ArrayItems>
<Size>size()</Size>
<ValuePointer>_Mypair._Myval2._Myfirst</ValuePointer>
</ArrayItems>
</Expand>
</Type>
Elemento HResult
El elemento HResult permite personalizar la información que se muestra para un tipo de datos HRESULT en las ventanas del depurador. El elemento HRValue debe contener el valor de 32 bits del HRESULT que se va a personalizar. El elemento HRDescription contiene la información que se va a mostrar en la ventana del depurador.
<HResult Name="MY_E_COLLECTION_NOELEMENTS">
<HRValue>0xABC0123</HRValue>
<HRDescription>No elements in the collection.</HRDescription>
</HResult>
Elemento UIVisualizer
Un elemento UIVisualizer registra un complemento de visualizador gráfico en el depurador. Un visualizador gráfico crea un cuadro de diálogo u otra interfaz que muestra una variable o un objeto de forma coherente con su tipo de datos. El complemento del visualizador se debe crear como VSPackage y tiene que exponer un servicio que el depurador pueda consumir. El archivo .natvis contiene información de registro para el complemento, como su nombre, el identificador único global (GUID) del servicio expuesto y los tipos que puede visualizar.
Este es un ejemplo de un elemento UIVisualizer:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<UIVisualizer ServiceId="{5452AFEA-3DF6-46BB-9177-C0B08F318025}"
Id="1" MenuName="Vector Visualizer"/>
<UIVisualizer ServiceId="{5452AFEA-3DF6-46BB-9177-C0B08F318025}"
Id="2" MenuName="List Visualizer"/>
.
.
</AutoVisualizer>
Un par de atributos
ServiceId-Ididentifica unUIVisualizer. ElServiceIdes el GUID del servicio que ofrece el paquete del visualizador.Ides un identificador único que diferencia a los visualizadores, si un servicio proporciona más de uno. En el ejemplo anterior, el mismo servicio visualizador proporciona dos visualizadores.El atributo
MenuNamedefine un nombre de visualizador para mostrar en la lista desplegable junto al icono de lupa del depurador. Por ejemplo:
Cada tipo definido en el archivo .natvis debe mostrar explícitamente los visualizadores de la interfaz de usuario que lo puedan mostrar. El depurador coincide con las referencias del visualizador de las entradas de tipo con los visualizadores registrados. Por ejemplo, la siguiente entrada de tipo para std::vector hace referencia al UIVisualizer en el ejemplo anterior.
<Type Name="std::vector<int,*>">
<UIVisualizer ServiceId="{5452AFEA-3DF6-46BB-9177-C0B08F318025}" Id="1" />
</Type>
Puede ver un ejemplo de UIVisualizer en la extensión Image Watch usada para ver los mapas de bits en memoria.
Elemento CustomVisualizer
CustomVisualizer es un punto de extensibilidad que especifica una extensión VSIX que se escribe para controlar las visualizaciones en Visual Studio Code. Para obtener más información sobre cómo escribir extensiones VSIX, consulte SDK de Visual Studio.
Es mucho más trabajo escribir un visualizador personalizado que una definición de Natvis XML, pero estás sin las restricciones de lo que Natvis admite o no. Los visualizadores personalizados tienen acceso a todo el conjunto de API de extensibilidad del depurador, que pueden consultar y modificar el proceso de depuración o comunicarse con otras partes de Visual Studio.
Puede usar los atributos Condition, IncludeViewy ExcludeView en elementos CustomVisualizer.
Limitaciones
Las personalizaciones de Natvis funcionan con clases y estructuras, pero no con definiciones de tipo.
Natvis no admite visualizadores para tipos primitivos (por ejemplo, int, bool) o para punteros a tipos primitivos. En este escenario, una opción es usar el especificador de formato adecuado para su caso de uso. Por ejemplo, si usa double* mydoublearray en el código, puede usar un especificador de formato de matriz en la ventana Inspección del depurador, como la expresión mydoublearray, [100], que muestra los primeros 100 elementos.