Solución de problemas de consultas de ejecución lenta en SQL Server
Versión del producto original: SQL Server
Número de KB original: 243589
Introducción
En este artículo se describe cómo solucionar un problema de rendimiento que pueden experimentar las aplicaciones de base de datos al usar SQL Server: rendimiento lento de una consulta específica o de un grupo de consultas. La siguiente metodología le ayudará a reducir la causa del problema de las consultas lentas y dirigirle hacia la resolución.
Búsqueda de consultas lentas
Para establecer que tiene problemas de rendimiento de consultas en la instancia de SQL Server, empiece por examinar las consultas por su tiempo de ejecución (tiempo transcurrido). Compruebe si el tiempo supera un umbral establecido (en milisegundos) en función de una línea base de rendimiento establecida. Por ejemplo, en un entorno de pruebas de esfuerzo, es posible que haya establecido un umbral para que la carga de trabajo no sea superior a 300 ms y puede usar este umbral. A continuación, puede identificar todas las consultas que superan ese umbral, centrándose en cada consulta individual y su duración de línea base de rendimiento preestablecida. En última instancia, los usuarios empresariales se preocupan por la duración total de las consultas de base de datos; por lo tanto, el objetivo principal es la duración de la ejecución. Otras métricas, como el tiempo de CPU y las lecturas lógicas, se recopilan para ayudar a reducir la investigación.
Para ejecutar instrucciones actualmente, compruebe las columnas total_elapsed_time y cpu_time en sys.dm_exec_requests. Ejecute la consulta siguiente para obtener los datos:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Para las ejecuciones anteriores de la consulta, compruebe las columnas last_elapsed_time y last_worker_time en sys.dm_exec_query_stats. Ejecute la consulta siguiente para obtener los datos:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNota:
Si
avg_wait_timemuestra un valor negativo, se trata de una consulta paralela.Si puede ejecutar la consulta a petición en SQL Server Management Studio (SSMS) o Azure Data Studio, ejecútelo con SET STATISTICS TIME
ONy SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFA continuación, en Mensajes, verá el tiempo de CPU, el tiempo transcurrido y las lecturas lógicas como esta:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Si puede recopilar un plan de consulta, compruebe los datos de las propiedades del plan de ejecución.
Ejecute la consulta con Incluir plan de ejecución real activado.
Seleccione el operador más a la izquierda en Plan de ejecución.
En Propiedades, expanda la propiedad QueryTimeStats .
Compruebe ElapsedTime y CpuTime.
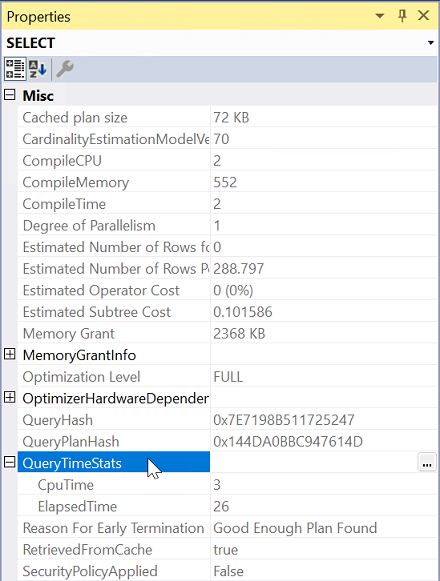
Ejecución frente a espera: ¿por qué las consultas son lentas?
Si encuentra consultas que superan el umbral predefinido, examine por qué podrían ser lentas. La causa de los problemas de rendimiento se puede agrupar en dos categorías, ejecutándose o esperando:
WAITING: las consultas pueden ser lentas porque esperan un cuello de botella durante mucho tiempo. Consulte una lista detallada de cuellos de botella en tipos de esperas.
RUNNING: las consultas pueden ser lentas porque se ejecutan (en ejecución) durante mucho tiempo. En otras palabras, estas consultas usan activamente recursos de CPU.
Una consulta puede estar ejecutándose durante algún tiempo y esperar algún tiempo en su duración. Sin embargo, el enfoque es determinar cuál es la categoría dominante que contribuye a su tiempo transcurrido largo. Por lo tanto, la primera tarea consiste en establecer en qué categoría se encuentran las consultas. Es sencillo: si una consulta no se está ejecutando, está esperando. Idealmente, una consulta pasa la mayor parte de su tiempo transcurrido en un estado en ejecución y muy poco tiempo esperando recursos. Además, en el mejor de los casos, una consulta se ejecuta dentro o por debajo de una línea base predeterminada. Compare el tiempo transcurrido y el tiempo de CPU de la consulta para determinar el tipo de problema.
Tipo 1: enlazado a CPU (ejecutor)
Si el tiempo de CPU está cerca, es igual a o superior al tiempo transcurrido, puede tratarlo como una consulta enlazada a la CPU. Por ejemplo, si el tiempo transcurrido es de 3000 milisegundos (ms) y el tiempo de CPU es de 2900 ms, significa que la mayor parte del tiempo transcurrido se dedica a la CPU. A continuación, podemos decir que es una consulta enlazada a la CPU.
Ejemplos de consultas en ejecución (enlazadas a CPU):
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1 000 | 20 |
Lecturas lógicas: leer páginas de datos o índices en la memoria caché, son los controladores más frecuentes del uso de CPU en SQL Server. Podría haber escenarios en los que el uso de CPU procede de otros orígenes: un bucle while (en T-SQL u otro código como XProcs o objetos CRL de SQL). En el segundo ejemplo de la tabla se muestra este escenario, donde la mayoría de la CPU no procede de las lecturas.
Nota:
Si el tiempo de CPU es mayor que la duración, indica que se ejecuta una consulta paralela; varios subprocesos usan la CPU al mismo tiempo. Para obtener más información, consulte Consultas paralelas: ejecutor o waiter.
Tipo 2: Esperando un cuello de botella (waiter)
Una consulta está esperando un cuello de botella si el tiempo transcurrido es significativamente mayor que el tiempo de CPU. El tiempo transcurrido incluye el tiempo que ejecuta la consulta en la CPU (tiempo de CPU) y el tiempo en espera de que se libere un recurso (tiempo de espera). Por ejemplo, si el tiempo transcurrido es de 2000 ms y el tiempo de CPU es de 300 ms, el tiempo de espera es de 1700 ms (2000 - 300 = 1700). Para obtener más información, vea Tipos de esperas.
Ejemplos de consultas en espera:
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Consultas paralelas: ejecutor o waiter
Las consultas paralelas pueden usar más tiempo de CPU que la duración total. El objetivo del paralelismo es permitir que varios subprocesos ejecuten partes de una consulta simultáneamente. En un segundo de la hora del reloj, una consulta puede usar ocho segundos de tiempo de CPU ejecutando ocho subprocesos paralelos. Por lo tanto, resulta difícil determinar un límite de CPU o una consulta en espera en función del tiempo transcurrido y la diferencia de tiempo de CPU. Sin embargo, como regla general, siga los principios enumerados en las dos secciones anteriores. El resumen es:
- Si el tiempo transcurrido es mucho mayor que el tiempo de CPU, considere que es un waiter.
- Si el tiempo de CPU es mucho mayor que el tiempo transcurrido, tenga en cuenta que es un ejecutor.
Ejemplos de consultas paralelas:
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1 500 000 |
Representación visual de alto nivel de la metodología

Diagnóstico y resolución de consultas en espera
Si ha establecido que las consultas de interés son waiters, el siguiente paso es centrarse en resolver problemas de cuello de botella. De lo contrario, vaya al paso 4: Diagnóstico y resolución de consultas en ejecución.
Para optimizar una consulta que está esperando cuellos de botella, identifique cuánto tiempo es la espera y dónde está el cuello de botella (el tipo de espera). Una vez confirmado el tipo de espera, reduzca el tiempo de espera o elimine la espera por completo.
Para calcular el tiempo de espera aproximado, resta el tiempo de CPU (tiempo de trabajo) del tiempo transcurrido de una consulta. Normalmente, el tiempo de CPU es el tiempo de ejecución real y la parte restante de la duración de la consulta está esperando.
Ejemplos de cómo calcular la duración aproximada de la espera:
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Tiempo de espera (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1 000 | 6080 |
Identificación del cuello de botella o espera
Para identificar consultas históricas de larga espera (por ejemplo, >el 20 % del tiempo de espera total transcurrido es el tiempo de espera), ejecute la consulta siguiente. Esta consulta usa estadísticas de rendimiento para los planes de consulta almacenados en caché desde el inicio de SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPara identificar las consultas que se ejecutan actualmente con esperas de más de 500 ms, ejecute la consulta siguiente:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Si puede recopilar un plan de consulta, compruebe WaitStats de las propiedades del plan de ejecución en SSMS:
- Ejecute la consulta con Incluir plan de ejecución real activado.
- Haga clic con el botón derecho en el operador de la izquierda en la pestaña Plan de ejecución.
- Seleccione Propiedades y, a continuación, propiedad WaitStats .
- Compruebe waitTimeMs y WaitType.
Si está familiarizado con los escenarios PSSDiag/SQLdiag o SQL LogScout LightPerf/GeneralPerf, considere la posibilidad de usar cualquiera de ellos para recopilar estadísticas de rendimiento e identificar consultas en espera en la instancia de SQL Server. Puede importar los archivos de datos recopilados y analizar los datos de rendimiento con SQL Nexus.
Referencias para ayudar a eliminar o reducir las esperas
Las causas y resoluciones de cada tipo de espera varían. No hay ningún método general para resolver todos los tipos de espera. Estos son los artículos para solucionar y resolver problemas comunes de tipo de espera:
- Comprender y resolver problemas de bloqueo (LCK_M_*)
- Descripción y resolución de problemas de bloqueo en Azure SQL Database
- Solución de problemas lentos de rendimiento de SQL Server causados por problemas de E/S (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Resolución de la contención de inserción de la última página de PAGELATCH_EX en SQL Server
- Memoria concede explicaciones y soluciones (RESOURCE_SEMAPHORE)
- Solución de problemas de consultas lentas resultantes de ASYNC_NETWORK_IO tipo de espera
- Solución de problemas de tipo de espera de alta HADR_SYNC_COMMIT con grupos de disponibilidad AlwaysOn
- Cómo funciona: CMEMTHREAD y depurarlos
- Hacer que el paralelismo sea accionable (CXPACKET y CXCONSUMER)
- Espera de THREADPOOL
Para obtener descripciones de muchos tipos de espera y lo que indican, consulte la tabla en Tipos de esperas.
Diagnóstico y resolución de consultas en ejecución
Si el tiempo de CPU (trabajo) está muy cerca de la duración total transcurrido, la consulta pasa la mayor parte de su duración en ejecución. Normalmente, cuando el motor de SQL Server impulsa un uso elevado de cpu, el uso elevado de CPU procede de consultas que impulsan un gran número de lecturas lógicas (la razón más común).
Para identificar las consultas responsables de la actividad alta de CPU actual, ejecute la siguiente instrucción:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Si las consultas no impulsan la CPU en este momento, puede ejecutar la siguiente instrucción para buscar consultas históricas enlazadas a la CPU:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Métodos comunes para resolver las consultas de larga duración, enlazadas a la CPU
- Examen del plan de consulta de la consulta
- Actualizar estadísticas
- Identifique y aplique los índices que faltan. Para obtener más pasos sobre cómo identificar los índices que faltan, consulte Optimización de índices no clúster con sugerencias de índice que faltan.
- Rediseñar o reescribir las consultas
- Identifique y resuelva los planes con distinción de parámetros
- Identificación y resolución de problemas de capacidad de SARG
- Identifique y resuelva los problemas de objetivo de fila en los que los bucles anidados de ejecución prolongada pueden deberse a TOP, EXISTS, IN, FAST, SET ROWCOUNT, OPTION (FAST N). Para obtener más información, consulte Las mejoras de los objetivos de fila no autorizados y del plan de presentación: Estimación de objetivos de filaRowsWithoutRowGoal
- Evaluar y resolver problemas de estimación de cardinalidad. Para obtener más información, consulte Disminución del rendimiento de las consultas después de la actualización de SQL Server 2012 o anterior a 2014 o posterior.
- Identificar y resolver los coráns que parecen no completarse nunca, consulte Solución de problemas de consultas que parecen no terminar nunca en SQL Server
- Identificación y resolución de consultas lentas afectadas por el tiempo de espera del optimizador
- Identificar problemas de alto rendimiento de CPU. Para obtener más información, consulte Solución de problemas de uso elevado de CPU en SQL Server.
- Solución de problemas de una consulta que muestra una diferencia de rendimiento significativa entre dos servidores
- Aumento los recursos informáticos en el sistema (CPU)
- Solución de problemas de rendimiento de UPDATE con planes estrechos y anchos
Recursos recomendados
- Tipos de cuellos de botella de rendimiento de consultas que pueden detectarse en SQL Server y Azure SQL Managed Instance
- Herramientas de optimización y supervisión del rendimiento
- Ajuste automático
- Directrices generales para diseñar índices
- Solución de problemas de tiempo de espera de consulta
- Solución de problemas de uso elevado de la CPU en SQL Server
- Se ha reducido el rendimiento de las consultas después de la actualización de SQL Server 2012 (o versiones anteriores) a la versión 2014 o posteriores.