Solución de problemas de colas de recuperación en un grupo de disponibilidad AlwaysOn
En este artículo se proporcionan soluciones a problemas relacionados con la cola de recuperación.
¿Qué es la cola de recuperación?
Los cambios que se realizan en la réplica primaria de la base de datos de un grupo de disponibilidad se envían a todas las réplicas secundarias definidas en el mismo grupo de disponibilidad. Una vez que esos cambios llegan a las réplicas secundarias, primero se escriben en el archivo de registro de transacciones de la base de datos del grupo de disponibilidad. Después, Microsoft SQL Server usa la operación de recuperación o puesta al día para actualizar los archivos de base de datos.
Si los cambios en un grupo de disponibilidad llegan y protegen el archivo de registro de transacciones de la base de datos más rápido de lo que se pueden recuperar, se forma una cola de recuperación. Esta cola se compone de transacciones del registro de transacciones endurecidas que no se recuperaron ni restauraron en la base de datos.
Síntomas y efecto de la puesta en cola de recuperación (rehacer)
La consulta de réplicas principales y secundarias devuelve resultados diferentes
Las cargas de trabajo de solo lectura que consultan réplicas secundarias podrían consultar datos obsoletos. Si se produce la cola de recuperación, es posible que los cambios realizados en los datos de la base de datos de réplica principal no se reflejen en la base de datos secundaria al consultar los mismos datos.
Aunque los cambios llegan a la base de datos secundaria y se escriben en el archivo de registro de la base de datos, los cambios no se consultarán hasta que se recuperen y restauren en los archivos de base de datos. La operación de recuperación es lo que hace que esos cambios sean legibles.
Para obtener más información, consulte la sección Latencia de datos en la réplica secundaria de "Diferencias entre los modos de disponibilidad de un grupo de disponibilidad AlwaysOn".
El tiempo de conmutación por error es mayor o se supera el RTO.
El objetivo de tiempo de recuperación (RTO) es el tiempo de inactividad máximo de la base de datos que una organización puede controlar. RTO también describe la rapidez con la que la organización puede recuperar el acceso a la base de datos después de una interrupción. Si hay una cola de recuperación sustancial en una réplica secundaria cuando se produce una conmutación por error, la recuperación puede tardar más tiempo. Después de la recuperación, la base de datos pasará al rol principal y representará el estado de la base de datos que existía antes de la conmutación por error. Un tiempo de recuperación más largo puede retrasar la rapidez con la que se reanuda la producción después de una conmutación por error.
Varias características de diagnóstico notifican colas de recuperación de grupos de disponibilidad
En el caso de la cola de recuperación, el panel AlwaysOn de SQL Server Management Studio (SSMS) podría notificar un grupo de disponibilidad incorrecto.
Comprobación de la cola de recuperación (rehacer)
La cola de recuperación es una medida por base de datos que se puede comprobar mediante el panel AlwaysOn de la réplica principal o mediante la vista de administración dinámica (DMV) de sys.dm_hadr_database_replica_states en la réplica principal o secundaria. Monitor de rendimiento contadores comprueban la tasa de recuperación y la cola de recuperación. Estos contadores deben comprobarse en la réplica secundaria.
En las secciones siguientes se proporcionan métodos para supervisar activamente la cola de recuperación de la base de datos del grupo de disponibilidad.
Consulta sys.dm_hadr_database_replica_states
La sys.dm_hadr_database_replica_states DMV informa de una fila para cada base de datos de grupo de disponibilidad. Una columna del informe es redo_queue_size. Este valor es el tamaño de la cola de recuperación medido en kilobytes. Puede configurar una consulta similar a la siguiente para supervisar cualquier tendencia en el tamaño de la cola de recuperación cada 30 segundos. La consulta se ejecuta en la réplica principal. Usa el is_local=0 predicado para notificar los datos de la réplica secundaria, donde redo_queue_size y redo_rate son pertinentes.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Este es el aspecto de la salida.

Revisión de la cola de recuperación en el panel AlwaysOn
Para revisar la cola de recuperación, siga estos pasos:
Abra el panel AlwaysOn en SSMS haciendo clic con el botón derecho en un grupo de disponibilidad en SSMS Explorador de objetos.
Seleccione Mostrar panel.
Las bases de datos del grupo de disponibilidad se enumeran por última vez y hay algunos datos notificados en las bases de datos. Aunque el tamaño de cola de rehacer (KB) y la velocidad de puesta al día (KB/s) no aparecen de forma predeterminada, puede agregarlos a esta vista, como se muestra en la captura de pantalla del paso siguiente.
Para agregar estos contadores, haga clic con el botón derecho en el encabezado situado encima de los informes de base de datos y seleccione en la lista de columnas disponibles.
Para agregar el tamaño de cola de rehacer (KB) y la velocidad de puesta al día (KB/s), haga clic con el botón derecho en el encabezado que se muestra como resaltado en rojo en la captura de pantalla siguiente.
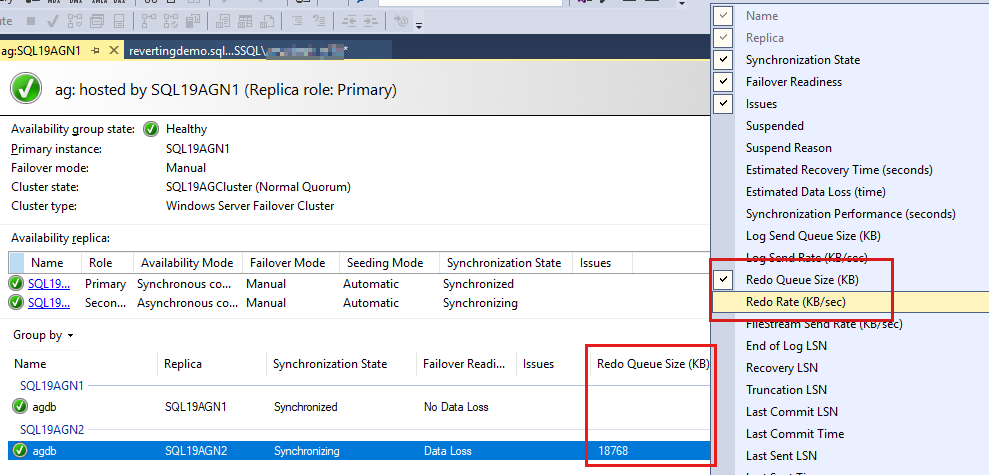
De forma predeterminada, el panel AlwaysOn actualiza automáticamente el tamaño de cola de puesta al día (KB) y la tasa de rehacer (KB/s) cada 60 segundos.
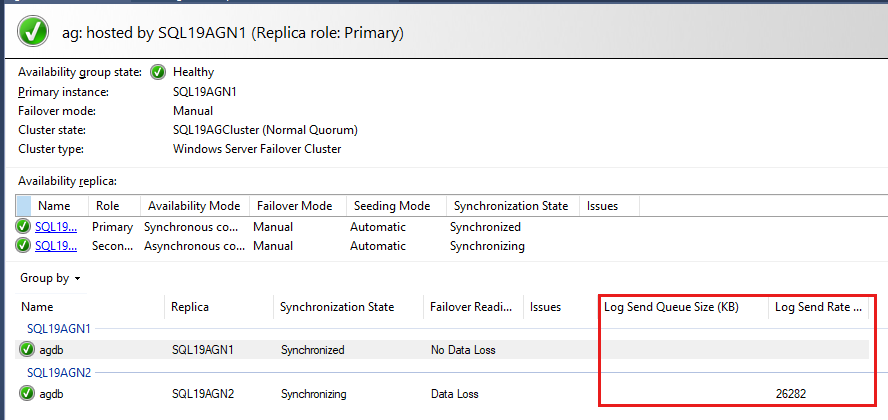


Revisión de la cola de recuperación en Monitor de rendimiento
El tamaño de la cola de recuperación es único para cada réplica secundaria y base de datos. Por lo tanto, para revisar la cola de recuperación de una base de datos de grupo de disponibilidad, siga estos pasos:
Abra Monitor de rendimiento en la réplica secundaria.
Seleccione el botón Agregar (contador).
En Contadores disponibles, seleccione SQLServer:Réplica de base de datos y, a continuación, seleccione Cola de recuperación y Rehacer bytes por segundo contadores.
En el cuadro de lista Instancia , seleccione la base de datos del grupo de disponibilidad que desea supervisar para la puesta en cola de recuperación.
Seleccione Agregar>Aceptar.
Este es el aspecto que podría tener el aumento de la cola de recuperación.
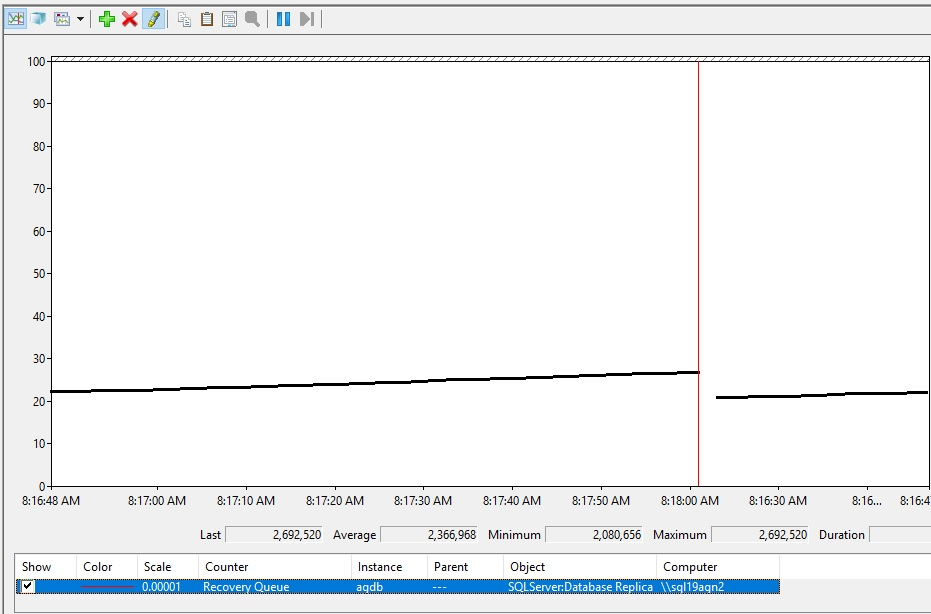

Interpretación de los valores de cola de recuperación
En esta sección se explica cómo se pueden interpretar los valores relacionados con la cola de recuperación que ha determinado en la sección anterior.
¿Cuándo se pone en cola de recuperación un problema? ¿Qué cantidad de colas de recuperación debe tolerar?
Puede suponer que si la cola de recuperación informa de un valor de 0, esto significa que no se está produciendo ninguna puesta en cola de recuperación en el momento de ese informe. Sin embargo, cuando el entorno de producción esté ocupado, debería esperar observar que la cola de recuperación notifica con frecuencia un valor distinto de cero incluso en un entorno AlwaysOn correcto. Durante la producción típica, debe esperar observar que este valor fluctúa entre 0 y un valor distinto de cero.
Si observa un aumento de la cola de recuperación a lo largo del tiempo, se garantiza una investigación adicional. Esta actividad adicional indica que ha cambiado algo. Si observa un crecimiento repentino en la cola de recuperación, las siguientes medidas son útiles para solucionar problemas:
- Tasa de rehacer de registros (KB/s) (panel AlwaysOn)
- Redo_rate en el sys.dm_hadr_database_replica_states de DMV
Obtención de las tasas de línea base para la tasa de puesta al día
Durante el rendimiento correcto de AlwaysOn, supervise la tasa de rehacer en las bases de datos de grupo de disponibilidad ocupadas. ¿Qué aspecto tienen durante las horas laborables normalmente ocupadas? ¿Cuáles son estas tasas durante períodos de mantenimiento, cuando las transacciones grandes (recompilaciones de índices, procesos ETL) impulsan un mayor rendimiento de transacción en el sistema? Puede comparar estos valores al observar el crecimiento de la cola de recuperación para ayudar a determinar lo que ha cambiado. La carga de trabajo puede ser mayor de lo habitual. Si la tasa de rehacer es menor, es posible que se requiera una investigación adicional para determinar por qué.
Los volúmenes de cargas de trabajo son importantes
Cuando tiene cargas de trabajo grandes (como una instrucción UPDATE en un millón de filas, una recompilación de índices en una tabla de 1 terabyte o incluso un lote ETL que inserta millones de filas), debería esperar ver un crecimiento de cola de recuperación, ya sea inmediatamente o con el tiempo. Esto se espera cuando se realiza un gran número de cambios repentinamente en la base de datos del grupo de disponibilidad.
Cómo diagnosticar colas de recuperación (rehacer)
Después de identificar la cola de recuperación para una base de datos de grupo de disponibilidad de réplica secundaria específica, conéctese a la réplica secundaria y, a continuación, consulte sys.dm_exec_requests para determinar los wait_type subprocesos de recuperación y wait_time para los subprocesos de recuperación. Esta es una consulta que se puede ejecutar en un bucle. Busca una frecuencia alta de uno o más tipos de espera e incluso tiempos de espera para esos tipos de espera. Esta es una consulta de ejemplo que se ejecuta cada segundo e informa de los tipos de espera y los tiempos de espera para el grupo de disponibilidad, "agdb":
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Importante
Para obtener una salida significativa del tipo de espera, se debe observar que la cola de recuperación aumenta cuando se usa uno de los métodos descritos anteriormente para supervisar esta condición.
En este ejemplo, se notifican algunos tipos de espera relacionados con E/S (PAGEIOLATCH_UP, PAGEIOATCH_EX). Supervise para comprobar si estos tipos de espera siguen teniendo los valores más grandes wait_times , como se indica en la columna siguiente.

Tipos de espera de rehacer de SQL Server
Cuando se identifica un tipo de espera, revise el siguiente artículo SQL Server 2016/2017: Modelo y rendimiento de réplica secundaria del grupo de disponibilidad: Microsoft Tech Community como referencia cruzada para tipos de espera comunes que provocan colas de recuperación y para ayudar a resolver el problema.
Subprocesos de rehacer bloqueados en servidores de informes secundarios
Si la solución dirige los informes (consultas) a las bases de datos del grupo de disponibilidad en la réplica secundaria, estas consultas de solo lectura adquieren bloqueos de estabilidad de esquema (Sch-S). Estos bloqueos sch-S pueden impedir que los subprocesos de rehacer adquieran bloqueos de modificación de esquema (Sch-M) (también conocidos como "bloqueos de modificación de esquema" o LCK_M_SCH_M) para realizar cambios en cualquier lenguaje de definición de datos (DDL), como ALTER TABLE o ALTER INDEX. Un subproceso de rehacer bloqueado no puede aplicar registros de registro hasta que se desbloquee. Esto puede provocar la puesta en cola de recuperación.
Para comprobar si hay evidencia histórica de una fase de puesta al día bloqueada, abra los archivos de seguimiento de Xevent de AlwaysOn_health en la réplica secundaria mediante SSMS. lock_redo_blocked Busque eventos.

Use Monitor de rendimiento para supervisar activamente el impacto de rehacer bloqueado en la cola de recuperación. Agregue los contadores Réplica de SQL Server::D atabase::Redo bloqueado/s y SQL Server::D atabase Replica::Recovery Queue . En la captura de pantalla siguiente se muestra un ALTER TABLE ALTER COLUMN comando que se ejecuta en la réplica principal mientras se ejecuta una consulta de ejecución prolongada en la misma tabla de la réplica secundaria. El contador Rehacer bloqueado/s indica que se ejecuta el ALTER TABLE ALTER COLUMN comando. Aunque la consulta de ejecución prolongada se ejecuta en la misma tabla de la réplica secundaria, los cambios posteriores en la réplica principal provocarán un aumento en la cola de recuperación.

Supervise el tipo de espera de bloqueo de modificación del esquema que intenta adquirir el subproceso de rehacer. Para ello, use la consulta que se describió anteriormente para comprobar los tipos de espera que se notifican para las operaciones de puesta al día en sys.dm_exec_requests. Puede observar el tiempo de espera creciente para el LCK_M_SCH_M en el bloqueo de rehacer en curso.

Rehacer de un solo subproceso
SQL Server introdujo la recuperación en paralelo para las bases de datos de réplica secundarias en Microsoft SQL Server 2016. Si experimenta colas de recuperación al ejecutar SQL Microsoft Server 2012 o Microsoft SQL Server 2014, puede actualizar a una versión posterior del programa para mejorar el rendimiento de la fase de puesta al día en el entorno de producción.
Una fase de puesta al día de un solo subproceso puede producirse en versiones de SQL Server aún más avanzadas en las que se usa la arquitectura de recuperación en paralelo. En estas versiones, una instancia de SQL Server puede usar hasta 100 subprocesos para una fase de puesta al día paralela. Según el número de procesadores y bases de datos de grupo de disponibilidad, los subprocesos de puesta al día paralelos se asignan hasta un máximo de 100 subprocesos totales. Si se alcanza el límite de rehacer de 100 subprocesos, a algunas bases de datos del grupo de disponibilidad se les asigna un único subproceso de puesta al día.
Para determinar si la base de datos del grupo de disponibilidad usa la recuperación en paralelo, conéctese a la réplica secundaria y use la consulta siguiente para determinar el número de filas (subprocesos) que aplican la recuperación para la base de datos del grupo de disponibilidad. En el ejemplo siguiente, si la base de datos "agdb" es un único subproceso y su comando es DB STARTUP, la carga de trabajo de recuperación podría beneficiarse de la recuperación en paralelo.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

Si comprueba que la base de datos usa una puesta al día de un solo subproceso, revise el algoritmo descrito anteriormente para determinar si SQL Server supera el número de 100 subprocesos de trabajo dedicados a la recuperación en paralelo. Esta condición puede ser la razón por la que la base de datos "agdb" usa solo un único subproceso para la recuperación.
SQL Server 2022 ahora usa un nuevo algoritmo de recuperación en paralelo para que los subprocesos de trabajo se asignen para la recuperación en paralelo en función de la carga de trabajo. Esto elimina la posibilidad de que una base de datos ocupada permanezca en una recuperación de un solo subproceso. Para obtener más información, consulte la sección Uso de subprocesos por grupos de disponibilidad de "Requisitos previos, restricciones y recomendaciones para grupos de disponibilidad AlwaysOn".