Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este artículo le ayuda a diagnosticar tiempos de espera de conexión intermitentes que se notifican entre las réplicas del grupo de disponibilidad.
Síntomas y efectos de los tiempos de espera de conexión intermitentes de la réplica del grupo de disponibilidad
La consulta de réplicas principales y secundarias devuelve resultados diferentes
Las cargas de trabajo de solo lectura que consultan réplicas secundarias podrían consultar datos obsoletos. Si se producen tiempos de espera intermitentes de conexión de réplica, los cambios en los datos de la base de datos de réplica principal aún no se reflejan en la base de datos secundaria cuando se consultan los mismos datos. Para obtener más información, consulte la sección Latencia de datos en la réplica secundaria.
Grupo de disponibilidad de informes de diagnóstico no sincronizado
El panel AlwaysOn de SQL Server Management Studio puede notificar un grupo de disponibilidad incorrecto que tenga réplicas que estén en un estado De no sincronización . También puede observar que las réplicas del informe del panel AlwaysOn están en el estado Sin sincronizar .

Al revisar los registros de errores de SQL Server de esas réplicas, es posible que observe mensajes como los siguientes que indican que se agotó el tiempo de espera de conexión entre las réplicas del grupo de disponibilidad:
Registro de errores de la réplica principal
2023-02-15 07:10:55.500 spid43s Always On availability groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Registro de errores de la réplica secundaria
2023-02-15 07:11:03.100 spid31s A connection time-out has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Los problemas de conexión intermitentes pueden afectar a la preparación de la conmutación por error de una réplica secundaria
Si configura el grupo de disponibilidad para la conmutación automática por error y el asociado de conmutación por error de confirmación sincrónica se desconecta intermitentemente de la principal, es posible que la conmutación automática por error no se realice correctamente.
Puede consultar sys.dm_hadr_database_replia_cluster_states para determinar si la base de datos del grupo de disponibilidad está lista para la conmutación por error en ese momento. Este es un ejemplo de los resultados si el punto de conexión de creación de reflejo se detuvo en la réplica secundaria:
SELECT drcs.database_name, drcs.is_failover_ready, ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ar.replica_id=drcs.replica_id
WHERE ars.role_desc='SECONDARY'

Es posible que la conmutación automática por error no ponga en línea el grupo de disponibilidad en el rol principal en el equipo asociado de conmutación por error si la conmutación por error coincide con un tiempo de espera de conexión de réplica.
¿Qué indican los errores de tiempo de espera de conexión?
El valor predeterminado es 10 segundos para la configuración de réplica del grupo de disponibilidad, SESSION_TIMEOUT. Esta configuración se configura para cada réplica. Determina cuánto tiempo espera la réplica para recibir una respuesta de su réplica de asociado antes de que notifique un tiempo de espera de conexión. Si una réplica no recibe respuesta de la réplica del asociado, notifica un tiempo de espera de conexión en el registro de errores de Microsoft SQL Server y el registro de aplicaciones de Windows. La réplica que informa del tiempo de espera inmediatamente intenta volver a conectarse y seguirá intentando cada cinco segundos.
Normalmente, solo una réplica detecta y notifica el tiempo de espera de conexión. Sin embargo, el tiempo de espera de conexión puede ser notificado por ambas réplicas al mismo tiempo. Hay diferentes versiones de este mensaje, en función de si se agota el tiempo de espera de la conexión mediante una conexión establecida anteriormente o una nueva conexión:
Message 35206 A connection timeout has occurred on a previously established connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
Message 35201 A connection timeout has occurred while attempting to establish a connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Es posible que la réplica del asociado no detecte un tiempo de espera. Si es así, podría notificar el mensaje 35201 o 35206. Si no es así, notifica una pérdida de conexión a cada una de las bases de datos del grupo de disponibilidad:
Message 35267 Always On Availability Groups connection with primary/secondary database terminated for primary/secondary database '<databasename>' on the availability replica '<replicaname>' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Este es un ejemplo de lo que SQL Server notifica al registro de errores: si detiene el punto de conexión de creación de reflejo en la réplica principal, la réplica secundaria detecta un tiempo de espera de conexión y los mensajes 35206 y 35267 se notifican en el registro de errores de la réplica secundaria:
2023-02-15 07:11:03.100 spid31s A connection timeout has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID:[<replicaid>]. This is an informational message only. No user action is required.
En este ejemplo, la réplica principal no detectó ningún tiempo de espera de conexión porque todavía podía comunicarse con la base de datos secundaria y notificó el mensaje 35267 para cada base de datos de grupo de disponibilidad (en este ejemplo, solo hay una base de datos, "agdb"):
2023-02-15 07:10:55.500 spid43s Always On Availability Groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Causas del tiempo de espera de conexión de réplica
Problema de la aplicación
SQL Server puede estar ocupado por cualquiera de los varios motivos y no ofrece servicio a la conexión del punto de conexión de creación de reflejo dentro del período del grupo SESSION_TIMEOUT de disponibilidad. Esto hace que se agote el tiempo de espera de la conexión. Algunas de estas razones son:
SQL Server experimenta un uso de CPU del 100 %. Esto significa que SQL Server o alguna otra aplicación impulsan la CPU durante segundos a la vez.
SQL Server experimenta eventos de programador que no producen rendimiento. Los subprocesos de SQL Server son responsables de producir el programador (CPU) a otros subprocesos para completar su trabajo si un subproceso no se produce de forma oportuna.
SQL Server experimenta agotamiento de subprocesos de trabajo, problemas de memoria insuficiente o problemas de aplicación que afectan a su capacidad de atender la conexión del punto de conexión de creación de reflejo.
Problema de red
Esto requiere que recopile registros de seguimiento de red en las réplicas principal y secundaria cuando se desencadene el error. Para ello, puede examinar la latencia de red y los paquetes descartados.
Diagnóstico de tiempos de espera de conexión de réplica
Para el problema de los problemas de la aplicación que impiden que SQL Server realice el mantenimiento de la conexión con la réplica del asociado, en esta sección se explica cómo analizar los registros de SQL Server. Estas sugerencias pueden ayudarle a identificar la causa principal del tiempo de espera de la conexión de réplica. Esta sección termina con instrucciones más avanzadas sobre cómo recopilar seguimientos de red cuando se producen los tiempos de espera de conexión para que pueda comprobar el estado de la red.
Evaluación del tiempo de espera y la ubicación de los tiempos de espera de conexión de réplica
Revise el historial, la frecuencia y las tendencias de los tiempos de espera de conexión. El uso de los mensajes que encuentra en el registro de errores de SQL Server es una excelente manera de hacerlo. ¿Dónde se notifican los tiempos de espera de conexión? ¿Se notifican de forma coherente en la réplica principal o secundaria? ¿Cuándo se produjeron los errores? ¿Se produjeron en una semana determinada del mes, el día de la semana o la hora del día? ¿Se corresponden otros procesos por lotes o mantenimiento programado a las horas en las que se observan los tiempos de espera de conexión? Esta evaluación puede ayudarle a definir el ámbito y correlacionar los tiempos de espera de conexión para identificar la causa principal.
Revisión de la sesión de eventos extendidos de AlwaysOn_health
La AlwaysOn_health sesión de eventos extendidos se ha mejorado para incluir el ucs_connection_setup evento, que se desencadena cuando una réplica establece una conexión con su réplica de asociado. Esto puede resultar útil al solucionar problemas de tiempo de espera de conexión.
Nota:
El ucs_connection_setup evento extendido se agregó a las últimas actualizaciones acumulativas de SQL Server. Debe ejecutar las actualizaciones acumulativas más recientes para observar este evento extendido.
Consultar vistas de administración distribuida alwayson (DMV)
Puede consultar DMV AlwaysOn para obtener más información sobre el estado conectado de la réplica. Esta consulta notifica solo el estado conectado y los errores asociados al tiempo de espera de conexión en el momento en que se producen los problemas. Si los problemas de conexión son intermitentes, es posible que la consulta no capture fácilmente el estado desconectado.
SELECT ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
En el ejemplo siguiente se muestra un estado desconectado sostenido porque se detuvo el punto de conexión de creación de reflejo en la réplica principal. Al consultar la réplica principal, la DMV AlwaysOn puede informar sobre la réplica principal y todas las réplicas secundarias (el punto de conexión está deshabilitado en la réplica principal).

Al consultar la réplica secundaria, las DMV AlwaysOn solo notifican en la réplica secundaria.

Revisión de la sesión de eventos extendidos de AlwaysOn
Conéctese a cada réplica mediante sql Server Management Studio (SSMS) Explorador de objetos y abra los
AlwaysOn_healtharchivos de eventos extendidos.En SSMS, vaya a Abrir archivo> y seleccione Combinar archivos de eventos extendidos.
Seleccione el botón Agregar.
En el cuadro de diálogo Abrir archivo, vaya a los archivos del directorio \LOG de SQL Server.
Presione Control y, a continuación, seleccione los archivos cuyo nombre comienza por "AlwaysOn_healthxxx.xel".
Seleccione Abrir y, después, Aceptar.
Debería ver una nueva ventana con pestañas en SSMS que muestra los eventos AlwaysOn.
En la captura de pantalla siguiente se muestran los
AlwaysOn_healthdatos de la réplica secundaria. El primer cuadro descrito muestra la pérdida de conexión después de que se detenga el punto de conexión de la réplica principal. El segundo cuadro descrito muestra el error de conexión que se produce la próxima vez que la réplica secundaria intenta conectarse a la réplica principal.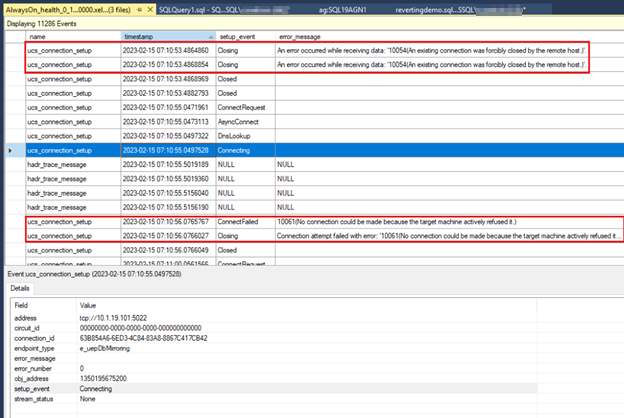

Compruebe si los eventos que no producen ningún rendimiento provocan tiempos de espera de conexión.
Una de las razones más comunes por las que una réplica de disponibilidad no puede atender la conexión de réplica de asociado es un programador que no produce rendimiento. Para obtener más información sobre los programadores que no producen rendimiento, consulte Solución de problemas de programación y rendimiento de SQL Server.
SQL Server realiza un seguimiento de los eventos del programador sin rendimiento que son tan cortos como 5 a 10 segundos. Informa de estos eventos en el TrackingNonYieldingScheduler punto de datos de la salida del sp_server_diagnostics query_processing componente.
Para comprobar si hay eventos sin rendimiento que podrían provocar tiempos de espera de conexión de réplica, siga estos pasos:
Cree un trabajo del Agente SQL que registre
sp_server_diagnosticscada cinco segundos.Programe este trabajo en el servidor que no notifica el tiempo de espera de conexión. Es decir, si el servidor A notifica el tiempo de espera de conexión de réplica en su registro de errores, configure el trabajo del Agente SQL en la réplica del asociado, Server B. Como alternativa, si ve tiempos de espera de conexión en ambas réplicas, cree el trabajo en ambas réplicas.
Ejecute el siguiente archivo por lotes para crear un trabajo que se ejecute
sp_server_diagnosticscada cinco segundos, anexe la salida a un archivo de texto y, a continuación, inicie el trabajo. El comando del ejemplo siguiente sesp_server_diagnostics 5ejecuta cada cinco segundos. Por lo tanto, no es necesario programar que este trabajo se ejecute cada cinco segundos, simplemente inicie el trabajo y se ejecutará hasta que se detenga, cada cinco segundos:USE [msdb] GO DECLARE @ReturnCode INT SELECT @ReturnCode = 0 DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Run sp_server_diagnostics', @owner_login_name=N'sa', @job_id = @jobId OUTPUT /****** Object: Step [Run SP_SERVER_DIAGNOSTICS] Script Date: 2/15/2023 4:20:41 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Run SP_SERVER_DIAGNOSTICS', @subsystem=N'TSQL', @command=N'sp_server_diagnostics 5', @database_name=N'master', @output_file_name=N'D:\cases\2423\sp_server_diagnostics_output.out', @flags=2 EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' EXEC sp_start_job 'Run sp_server_diagnostics'Nota:
En estos comandos, cambie
@output_file_namea una ruta de acceso válida y proporcione un nombre de archivo.
Análisis de los resultados
Cuando se notifica un tiempo de espera de conexión, anote la marca de tiempo del evento de tiempo de espera que se muestra en el registro de errores de SQL Server. En el caso de las réplicas del ejemplo siguiente, SQL19AGN1 se informaba del tiempo de espera de conexión de réplica. Por lo tanto, se creó un trabajo del Agente SQL en SQL19AGN2, la réplica del asociado. A continuación, se notificó un tiempo de espera de conexión en el registro de errores a las SQL19AGN1 07:24:31.

A continuación, la salida del trabajo del Agente SQL que ejecuta sp_server_diagnostics se comprueba en torno al momento notificado, en concreto revisando el TrackingNonYieldingScheduler punto de datos en la salida del query_processing componente. La salida informa de que se realizó un seguimiento de un programador que no produce (como un valor hexadecimal distinto de cero) en el servidor SQL19AGN2 (a las 07:24:33) en torno al momento en que se notificó el tiempo de espera de la conexión de réplica en SQL19AGN1 (a las 07:24:31).
Nota:
La salida siguiente sp_server_diagnostics se concatena para mostrar los create_time resultados (marca de tiempo) y query_processing TrackingNonYieldingScheduler .

Investigación de un evento de programador que no produce
Si ha comprobado los pasos de diagnóstico anteriores que provocaba un evento que no produceba el tiempo de espera de la conexión de réplica:
Identifique las cargas de trabajo que se ejecutan en SQL Server en el momento en que se ejecutan los eventos que no producen.
De forma similar a los tiempos de espera de conexión de réplica, busque tendencias en estos eventos durante el mes, el día o la semana que se producen.
Recopile el seguimiento del monitor de rendimiento en el sistema en el que se detectó el evento de no rendimiento.
Recopile contadores de rendimiento clave para los recursos del sistema, incluido Procesador::% tiempo de procesador, Memoria::MBytes disponibles, Disco lógico::Longitud media de cola de disco y Disco lógico::Promedio de disco s/Transferencia.
Si es necesario, abra un incidente de soporte técnico de SQL Server para obtener más ayuda para encontrar la causa principal de estos eventos que no producen. Comparta los registros que ha recopilado para su posterior análisis.
Recopilación avanzada de datos: recopilación de seguimiento de red durante el tiempo de espera de conexión
Si el diagnóstico anterior de la aplicación de SQL Server no produjo una causa principal, debe comprobar la red. El análisis correcto de la red requiere que recopile un seguimiento de red que abarque el tiempo de espera de la conexión.
El siguiente procedimiento inicia un seguimiento de red de Windows netsh en las réplicas en las que se notifican los tiempos de espera de conexión en los registros de errores de SQL Server. Se desencadena una tarea de eventos programados de Windows cuando se registra uno de los errores de conexión de SQL Server en el registro de aplicaciones. La tarea programada ejecuta un comando para detener el netsh seguimiento de red para que los datos de seguimiento de red clave no se sobrescriban. Estos pasos también asumen una ruta de acceso de *F:* para los registros de seguimiento y lotes. Ajuste esta ruta de acceso al entorno.
Inicie un seguimiento de red, como se muestra en el siguiente fragmento de código, en las dos réplicas en las que se producen los tiempos de espera de conexión:
netsh trace start capture=yes persistent=yes overwrite=yes maxsize=500 tracefile=f:\trace.etlCree tareas programadas de Windows que detengan el
netshseguimiento en los eventos 35206 o 35267. Puede crear estas tareas en una línea de comandos administrativa:schtasks /Create /tn Event35206Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35206] /f /RL HIGHEST schtasks /Create /tn Event35267Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35267] /f /RL HIGHESTUna vez que se produzca el evento y se detengan y capturen los seguimientos de red, puede eliminar las
ONEVENTtareas:PS C:\Users\sqladmin> Schtasks /Delete /tn Event35206Task /F PS C:\Users\sqladmin> Schtasks /Delete /tn Event35267Task /F
El análisis del seguimiento de red está fuera del ámbito de este solucionador de problemas. Si no puede interpretar el seguimiento de red, póngase en contacto con el equipo de soporte técnico de Microsoft SQL Server y proporcione el seguimiento junto con otros archivos de registro solicitados para el análisis de la causa principal.
¿Qué más puedo hacer para mitigar los tiempos de espera de conexión?
El grupo de disponibilidad predeterminado, SESSION_TIMEOUT, está configurado durante 10 segundos. Es posible que pueda mitigar los tiempos de espera de conexión ajustando la propiedad de réplica SESSION_TIMEOUT del grupo de disponibilidad. Esta configuración es por réplica. Ajustarlo para la réplica principal y cada réplica secundaria afectada. Este es un ejemplo de la sintaxis. El valor predeterminado SESSION_TIMEOUT es 10. Por lo tanto, podría usar 15 como el siguiente valor.
ALTER AVAILABILITY GROUP ag
MODIFY REPLICA ON 'SQL19AGN1' WITH (SESSION_TIMEOUT = 15);