Solucionar problemas de rendimiento de máquinas virtuales Azure en Linux o Windows
Se aplica a: ✔️ Máquinas virtuales Linux ✔️ Máquinas virtuales Windows
En este artículo se describe la solución de problemas genéricos de rendimiento de máquinas virtuales (VM) mediante la supervisión y observación de cuellos de botella, y se ofrecen posibles soluciones para los problemas que puedan surgir. Además de la monitorización, también puede utilizar Perfinsights, que puede proporcionar un informe con recomendaciones de mejores prácticas y cuellos de botella clave en torno a IO/CPU/Memory. Perfinsights está disponible para máquinas virtuales Windows y Linux en Azure.
Este artículo mostrará cómo utilizar la monitorización para diagnosticar cuellos de botella en el rendimiento.
Habilitación de diagnósticos de máquinas virtuales a través de Azure Portal
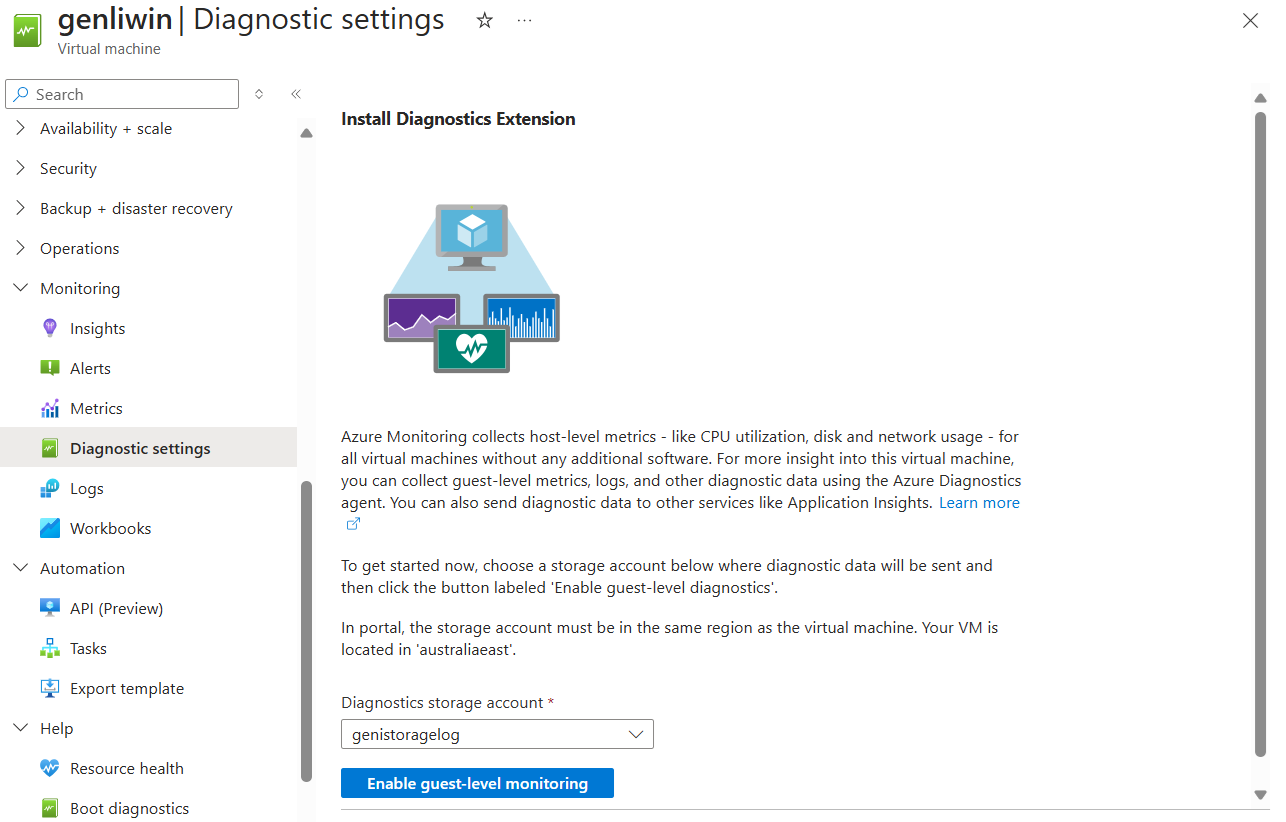
Para activar el diagnóstico de la máquina virtual:
Ve a la VM.
En la sección Supervisión , seleccione Configuración de diagnóstico.
Seleccione una cuenta de almacenamiento y, a continuación, seleccione Habilitar supervisión de nivel de invitado.

Visualización de las métricas de la cuenta de almacenamiento a través de Azure Portal (para discos no administrados)
Para las máquinas virtuales que usan discos no administrados, el almacenamiento es un nivel muy importante cuando se pretende analizar el rendimiento de E/S. Para las métricas relacionadas con el almacenamiento, es necesario habilitar el diagnóstico como paso adicional:
Identifique qué cuenta de almacenamiento (o cuentas) usa la máquina virtual seleccionando la máquina virtual:
- En Azure Portal, seleccione la máquina virtual.
- En Configuración, seleccione Disco y busque la cuenta de almacenamiento donde se guarda el disco.
- Vaya a la cuenta de almacenamiento y seleccione Métricas.
Identificación de cuellos de botella de rendimiento
Una vez que hayamos completado el proceso de configuración inicial de las métricas necesarias y hayamos habilitado los diagnósticos para la máquina virtual y la cuenta de almacenamiento relacionada, podemos pasar a la fase de análisis.
Acceso a la supervisión
En Azure Portal, seleccione la máquina virtual de Azure que desea investigar, seleccione Métricas en la sección Supervisión y, a continuación, seleccione una métrica.

Plazos de observación
Para identificar si tiene algún cuello de botella de recursos, revise sus datos. Si descubre que su máquina ha estado funcionando bien, pero se ha informado de que el rendimiento se ha degradado recientemente, revise un intervalo de tiempo de datos que abarque los datos de las métricas de rendimiento antes del cambio notificado, durante y después del problema.
Compruebe si hay un cuello de botella en la CPU
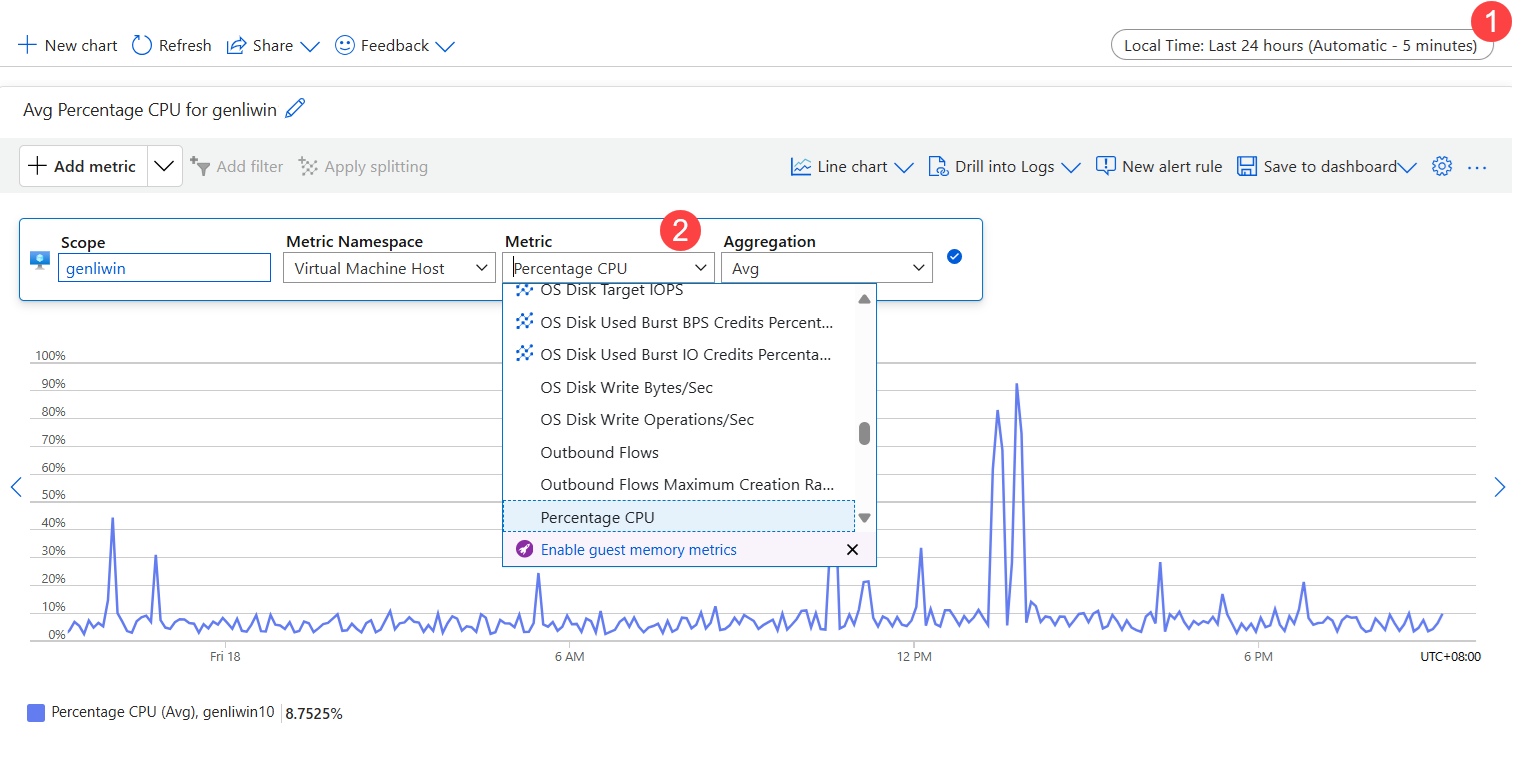
- Establece el intervalo de tiempo.
- En Métrica, seleccione Porcentaje de CPU.
Supervisión de las tendencias de rendimiento de CPU
Cuando examine los problemas de rendimiento, sea consciente de las tendencias y comprenda si le afectan. En las próximas secciones, utilizaremos los gráficos de seguimiento del portal para mostrar las tendencias. También pueden ser útiles para establecer referencias cruzadas entre diferentes comportamientos de los recursos en el mismo periodo de tiempo. Para personalizar los gráficos, haga clic en Plataforma de datos de Azure Monitor.
Picos - Los picos podrían estar relacionados con una tarea programada/evento conocido. Si puede identificar la tarea, determine si se ejecuta al nivel de rendimiento requerido. Si el rendimiento es aceptable, puede que no sea necesario aumentar los recursos.
Pico arriba y Constante - A menudo indica una nueva carga de trabajo. Si no se trata de una carga de trabajo reconocida, active la monitorización en la máquina virtual para averiguar qué proceso (o procesos) provoca el comportamiento. Una vez reconocido el proceso, determine si el aumento del consumo se debe a un código ineficiente o al consumo normal. Si el consumo es normal, decidir si el proceso funciona al nivel de rendimiento requerido.
Constante - Determine si su VM siempre se ha ejecutado en este nivel, o si sólo se ha estado ejecutando en ese nivel desde que se han habilitado los diagnósticos. Si es así, identifique el proceso (o procesos) que causa el problema y considere la posibilidad de añadir más de ese recurso.
Aumento constante: un aumento constante del consumo suele deberse a un código ineficiente o a que el proceso está asumiendo más carga de trabajo del usuario.
Corrección de la utilización elevada de la CPU
Si la aplicación o el proceso no se ejecutan de forma óptima y el uso de cpu permanece por encima del 95 %, puede realizar cualquiera de las siguientes tareas:
- Para un alivio inmediato - Aumentar el tamaño de la VM a un tamaño con más núcleos.
- Comprender el problema - localizar la aplicación/proceso y solucionar los problemas en consecuencia.
Si ha aumentado la VM y la CPU sigue funcionando al 95%, determine si esta opción de configuración ofrece un mejor rendimiento o un mayor rendimiento de la aplicación hasta alcanzar un nivel aceptable. Si no es así, solucione el problema de esa aplicación concreta.
Puede utilizar Perfinsights para Windows o Linux para analizar qué proceso está impulsando el consumo de CPU.
Compruebe si hay un cuello de botella en la memoria
Para ver las métricas:
- Añadir una sección.
- Añade un azulejo.
- Abre la Galería.
- Seleccione el Uso de memoria y arrástrelo. Cuando el mosaico esté acoplado, haga clic con el botón derecho y seleccione 6x4.
Supervisión de las tendencias de rendimiento de memoria
El uso de memoria muestra cuánta memoria está consumiendo la máquina virtual. Comprenda la tendencia y si se corresponde con el momento en el que observa problemas. Siempre deberías tener más de 100 MB de memoria disponible.
Consumo de picos y constante/constante continuo: es posible que un uso elevado de la memoria no sea la causa de un mal rendimiento, ya que algunas aplicaciones, como los motores de bases de datos relacionales, asignan una gran cantidad de memoria y este uso puede no ser significativo. Sin embargo, si hay varias aplicaciones que consumen mucha memoria, es posible que el rendimiento sea deficiente debido a la contención de memoria que provoca el recorte y la paginación/intercambio al disco. Este rendimiento deficiente suele ser una causa notable del impacto en el rendimiento de las aplicaciones.
Consumo en aumento constante - Un posible "calentamiento" de la aplicación, este consumo es común entre los motores de bases de datos que están arrancando. Sin embargo, también podría ser un signo de una fuga de memoria en una aplicación. Identifique la aplicación y comprenda si el comportamiento es el esperado.
Uso de archivos de paginación o de intercambio - Compruebe si el archivo de paginación de Windows (ubicado en D:) o el archivo de intercambio de Linux (ubicado en /dev/sdb) están siendo muy utilizados. Si no tiene nada en estos volúmenes excepto estos archivos, compruebe si hay altas lecturas/escrituras en esos discos. Este problema es indicativo de condiciones de poca memoria.
Corrección de la alta utilización de memoria
Para resolver la alta utilización de memoria, realice cualquiera de las siguientes tareas:
- Para un alivio inmediato o uso de archivo de página o intercambio: aumente el tamaño de la VM a una con más memoria y luego supervise.
- Comprender el problema: localizar las aplicaciones/procesos y solucionar los problemas para identificar las aplicaciones que consumen mucha memoria.
- Si conoces la aplicación, comprueba si se puede limitar la asignación de memoria.
Si después de actualizar a una VM más grande, descubre que sigue teniendo un aumento constante hasta el 100 %, identifique la aplicación/proceso y solucione el problema.
Puede utilizar Perfinsights para Windows o Linux para analizar qué proceso está impulsando el consumo de Memoria.
Comprobación del cuello de botella del disco (para el disco no administrado)
Para comprobar el subsistema de almacenamiento de la máquina virtual, compruebe los diagnósticos a nivel de la máquina virtual de Azure mediante los contadores de los diagnósticos de la máquina virtual y también los diagnósticos de la cuenta de almacenamiento.
Para la solución de problemas específicos dentro de VM, puede utilizar Perfinsights para Windows o Linux, lo que podría ayudar a analizar qué proceso está impulsando las IO.
Tenga en cuenta que no disponemos de contadores para las Cuentas de Almacenamiento Redundante de Zona y Premium. Para cuestiones relacionadas con estos contadores, plantee un caso de soporte.
Visualización de diagnósticos de cuentas de almacenamiento en la supervisión
Para trabajar en los siguientes elementos, vaya a la cuenta de almacenamiento de la máquina virtual en el portal:
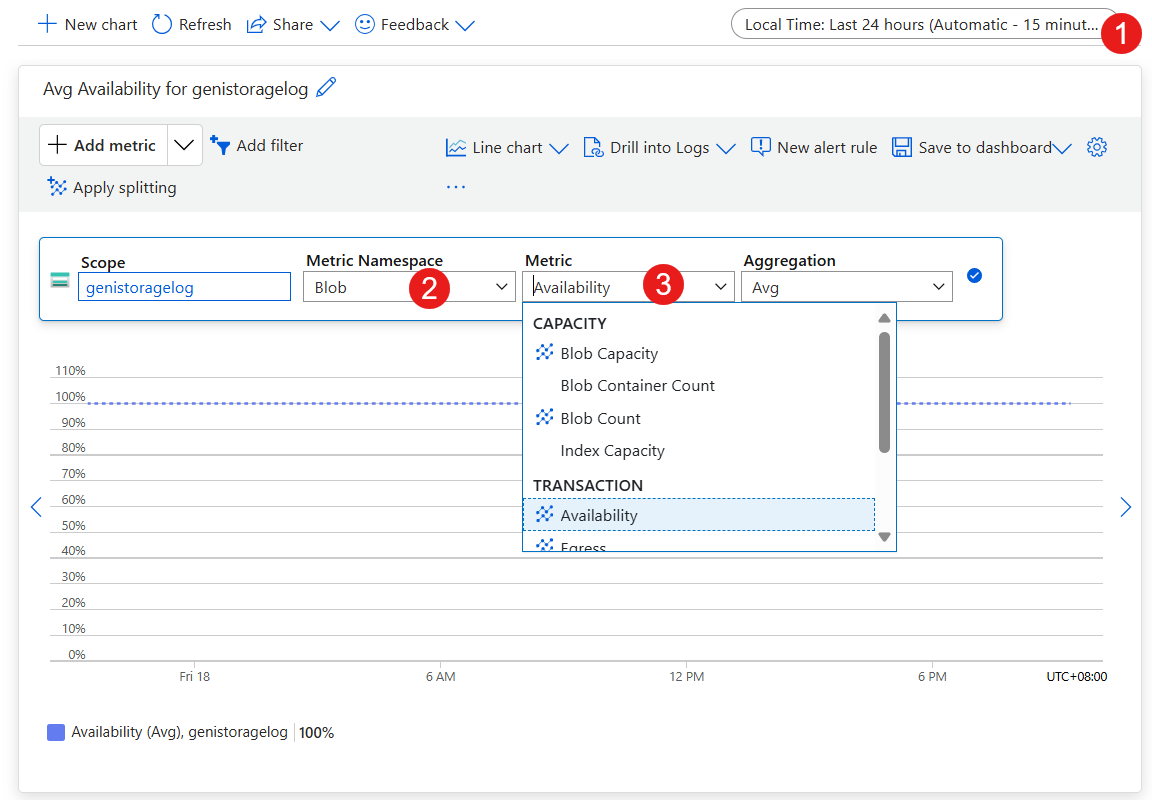
- Establece el intervalo de tiempo.
- Establezca Espacio de nombres de métrica en Blob.
- Establezca Métrica en Disponibilidad.
Supervisar las tendencias de rendimiento del disco (solo almacenamiento estándar)
Para identificar problemas con el almacenamiento, observe las métricas de rendimiento del Diagnóstico de la cuenta de almacenamiento y del Diagnóstico de la máquina virtual.
Para cada una de las comprobaciones siguientes, busque tendencias clave cuando los problemas se produzcan dentro del intervalo de tiempo del problema.
Comprobar la disponibilidad del almacenamiento Azure - Añadir la métrica de la cuenta de almacenamiento: disponibilidad
Si ves una caída en la disponibilidad, podría haber un problema con la plataforma, comprueba el Estado de Azure. Si no aparece ningún problema, envíe una nueva solicitud de asistencia.
Comprobar el tiempo de espera del almacenamiento Azure - Añadir las métricas de la cuenta de almacenamiento
- ClientTimeOutError
- ServerTimeOutError
- AverageE2ELatency
- AverageServerLatency
- TotalSolicitudes
Los valores de la métrica *TimeOutError indican que una operación IO ha tardado demasiado y se ha agotado. Los siguientes pasos le ayudarán a identificar las posibles causas.
AverageServerLatency aumenta al mismo tiempo en el TimeOutErrors podría ser un problema de la plataforma. Plantee una nueva solicitud de asistencia en esta situación.
AverageE2ELatency representa la latencia del cliente. Compruebe cómo la aplicación realiza la IOPS. Busque un aumento o una métrica TotalRequests constantemente alta. Esta métrica representa IOPS. Si estás empezando a llegar a los límites de la cuenta de almacenamiento o de un solo VHD, la latencia podría estar relacionada con el estrangulamiento.
Comprobación del estrangulamiento del almacenamiento de Azure: añada las métricas de la cuenta de almacenamiento: ThrottlingError
Los valores de limitación indican que se está limitando en el nivel de cuenta de almacenamiento, lo que significa que alcanza el límite de IOPS de la cuenta. Puede determinar si está alcanzando el umbral de IOPs comprobando la métrica TotalRequests.
Ten en cuenta que cada VHD tiene un límite de 500 IOPS o 60 MBits, pero está limitado por el límite acumulativo de 20000 IOPS por cuenta de almacenamiento.
Con esta métrica, no se puede saber qué blob está causando la ralentización y cuáles se ven afectados por ella. Sin embargo, estás superando los límites de IOPS o de entrada/salida de la cuenta de almacenamiento.
Para identificar si está alcanzando el límite de IOPS, vaya a los diagnósticos de la cuenta de almacenamiento y compruebe el TotalRequests, buscando si se está acercando a los 20 mil TotalRequests. Identifique un cambio en el patrón, si ve el límite por primera vez o si este límite se produce en un momento determinado.
Con las nuevas ofertas de discos en el almacenamiento estándar, los límites de IOPS y rendimiento pueden variar, pero el límite acumulativo de la cuenta de almacenamiento estándar es de 20000 IOPS (el almacenamiento Premium tiene diferentes límites a nivel de cuenta o de disco). Más información sobre las distintas ofertas de discos de almacenamiento estándar y los límites por disco:
Referencias
El ancho de banda de la cuenta de almacenamiento se mide mediante las métricas de la cuenta de almacenamiento: TotalIngress y TotalEgress. Tiene umbrales diferentes para el ancho de banda en función del tipo de redundancia y regiones:
- Destinos de escalabilidad y rendimiento para cuentas de almacenamiento estándar
- Objetivos de escalabilidad y rendimiento de las cuentas de almacenamiento de blob en páginas Premium
Compare los objetos TotalIngress y TotalEgress con los límites de entrada y salida para el tipo de redundancia de la cuenta de almacenamiento y la región.
Compruebe los límites de rendimiento de los VHD conectados a la máquina virtual. Añada las métricas VM Lectura y Escritura de Disco.
Las nuevas ofertas de discos en almacenamiento estándar tienen diferentes límites de IOPS y rendimiento (las IOPS no se exponen por VHD). Examine los datos para ver si está alcanzando los límites de rendimiento combinado de MB de los VHD a nivel de máquina virtual mediante lectura y escritura en disco y, a continuación, optimice la configuración de almacenamiento de la máquina virtual para superar los límites de un solo VHD. Más información sobre las distintas ofertas de discos de almacenamiento estándar y los límites por disco:
Corrección de la alta utilización del disco y la latencia
Reducción de la latencia del cliente y optimización de la E/S de las máquinas virtuales para superar los límites de los archivos VHD
Reducir la limitación
Si se alcanzan los límites superiores de las cuentas de almacenamiento, reequilibre los VHD entre las cuentas de almacenamiento. Consulte Objetivos de escalabilidad y rendimiento de Azure Storage.
Aumentar el rendimiento y reducir la latencia
Si tiene una aplicación sensible a la latencia y requiere un alto rendimiento, migre sus VHD al almacenamiento Azure Premium utilizando las VM de las series DS y GS.
En estos artículos se analizan las situaciones concretas:
Ponte en contacto con nosotros para obtener ayuda
Si tiene preguntas o necesita ayuda, cree una solicitud de soporte o busque consejo en la comunidad de Azure. También puede enviar comentarios sobre el producto con los comentarios de la comunidad de Azure.