Exploración de la arquitectura de la solución
Vamos a revisar la arquitectura que ha decidido para el flujo de trabajo de las operaciones de aprendizaje automático (MLOps) para comprender dónde y cuándo se debe comprobar el código.
Nota
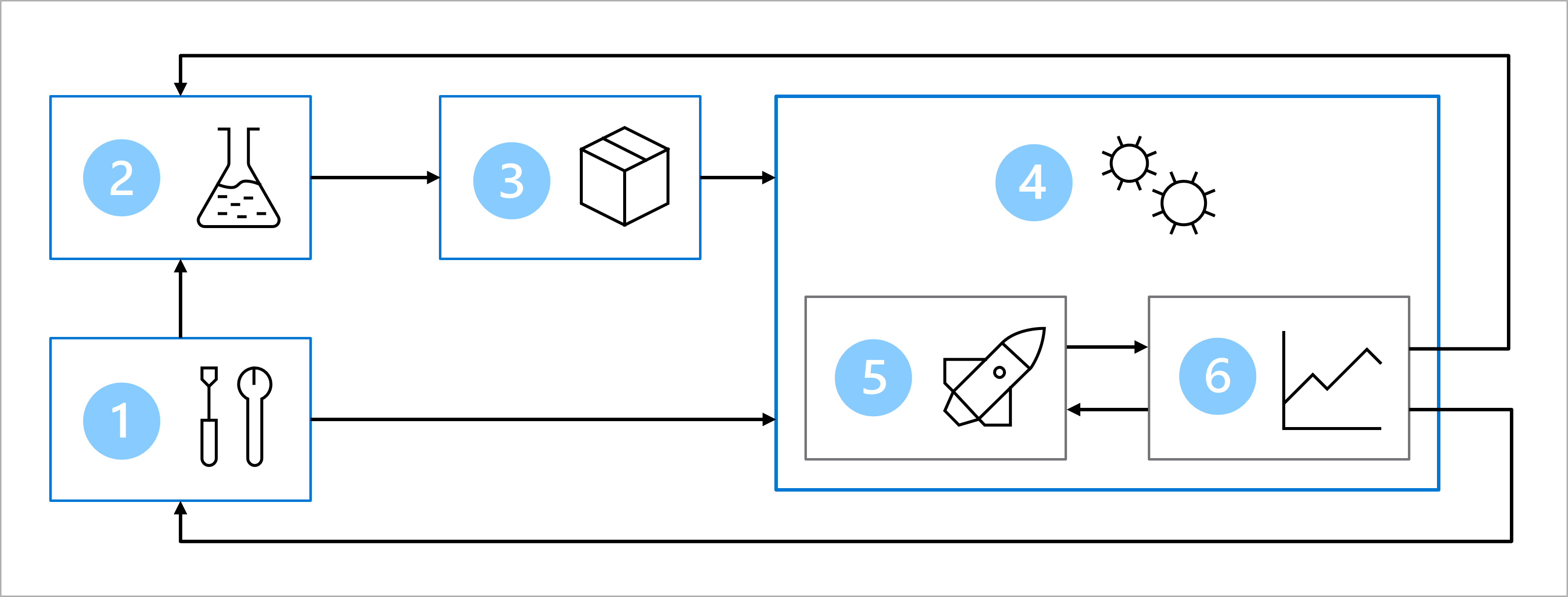
El diagrama es una representación simplificada de una arquitectura de MLOps. Para ver una arquitectura más detallada, explore los distintos casos de uso del acelerador de soluciones MLOps (v2).
El objetivo principal de la arquitectura de MLOps es crear una solución sólida y reproducible. Para lograrlo, la arquitectura incluye:
- Configuración: creación de todos los recursos de Azure necesarios para la solución.
- Desarrollo de modelos (bucle interno): análisis y procesamiento de los datos para entrenar y evaluar el modelo.
- Integración continua: empaquetado y registro del modelo.
- Implementación de modelos (bucle externo): implementación del modelo.
- Implementación continua: prueba del modelo y promoción al entorno de producción.
- Supervisión: supervisión del rendimiento del modelo y del punto de conexión.
Para mover un modelo del desarrollo a la implementación, necesitará la integración continua. Durante la integración continua, empaquetará y registrará el modelo. Sin embargo, antes de empaquetar un modelo, deberá comprobar el código usado para entrenar el modelo.
Junto con el equipo de ciencia de datos, ha aceptado usar desarrollo basado en troncos. Las ramas no solo protegerán el código de producción, sino que también le permitirán comprobar automáticamente los cambios propuestos antes de combinarlos con el código de producción.
Vamos a explorar el flujo de trabajo de un científico de datos:
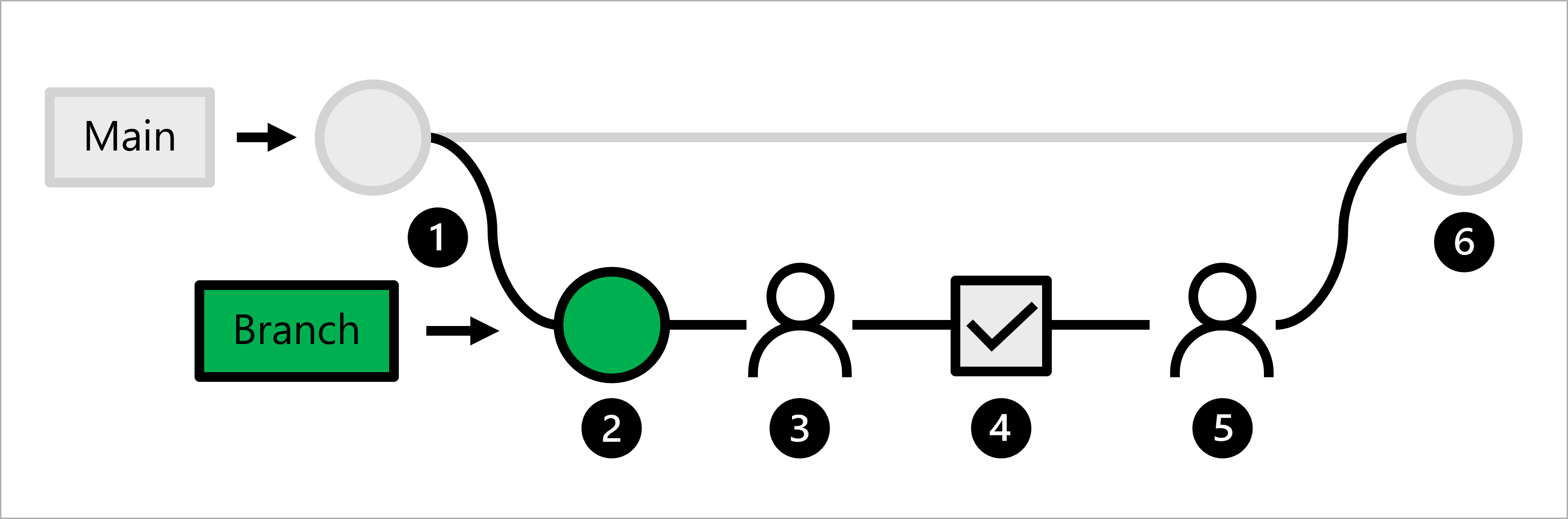
- El código de producción se hospeda en la rama principal.
- Un científico de datos crea una rama de características para el desarrollo de modelos.
- El científico de datos crea una solicitud de incorporación de cambios para proponer la inserción de cambios en la rama principal.
- Cuando se crea una solicitud de incorporación de cambios, se desencadena un flujo de trabajo de Acciones de GitHub para comprobar el código.
- Cuando el código supera ellinting y las pruebas unitarias, el científico de datos principal debe aprobar los cambios propuestos.
- Una vez que el científico de datos principal aprueba los cambios, la solicitud de incorporación de cambios se combina y la rama principal se actualiza en consecuencia.
Como ingeniero de aprendizaje automático, deberá crear un flujo de trabajo de Acciones de GitHub que compruebe el código mediante la ejecución de un linter y pruebas unitarias cada vez que se cree una solicitud de incorporación de cambios.
Sugerencia
Obtenga más información sobre cómo trabajar con el control de código fuente para proyectos de aprendizaje automático, incluido el desarrollo basado en troncos y la comprobación del código localmente.