Optimizar tablas delta
Spark es un marco de procesamiento paralelo, con datos almacenados en uno o más nodos de trabajo. Además, los archivos Parquet son inmutables, con archivos nuevos escritos para cada actualización o eliminación. Este proceso puede dar lugar a que Spark almacene datos en un gran número de archivos pequeños, conocidos como el problema de los archivos pequeños. Esto significa que las consultas en grandes cantidades de datos se pueden ejecutar lentamente o incluso no se pueden completar.
Función OptimizeWrite
OptimizeWrite es una característica de Delta Lake que reduce el número de archivos que se escriben. En lugar de escribir muchos archivos pequeños, escribe menos archivos más grandes. Esto ayuda a evitar el problema de los archivos pequeños y a garantizar que el rendimiento no está degradado.
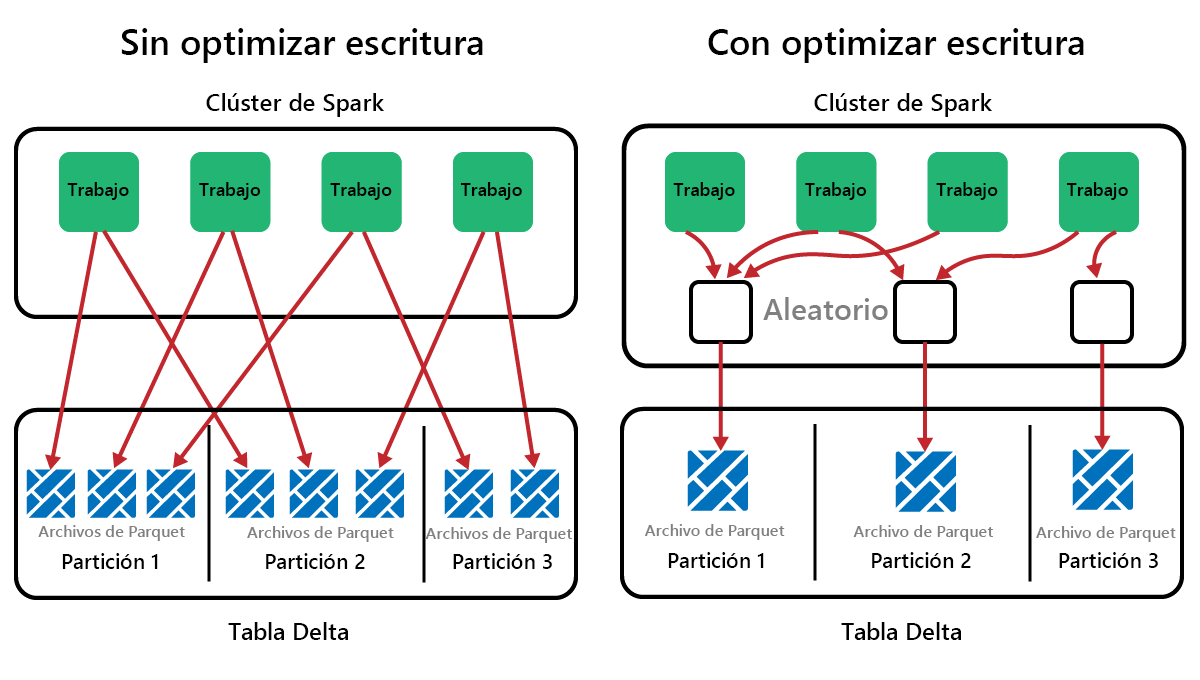
En Microsoft Fabric, OptimizeWrite está habilitado de forma predeterminada. Puede habilitarlo o deshabilitarlo en el nivel de sesión de Spark:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Nota:
OptimizeWrite también se puede establecer en Propiedades de tabla y para comandos de escritura individuales.
Optimize (Optimizar)
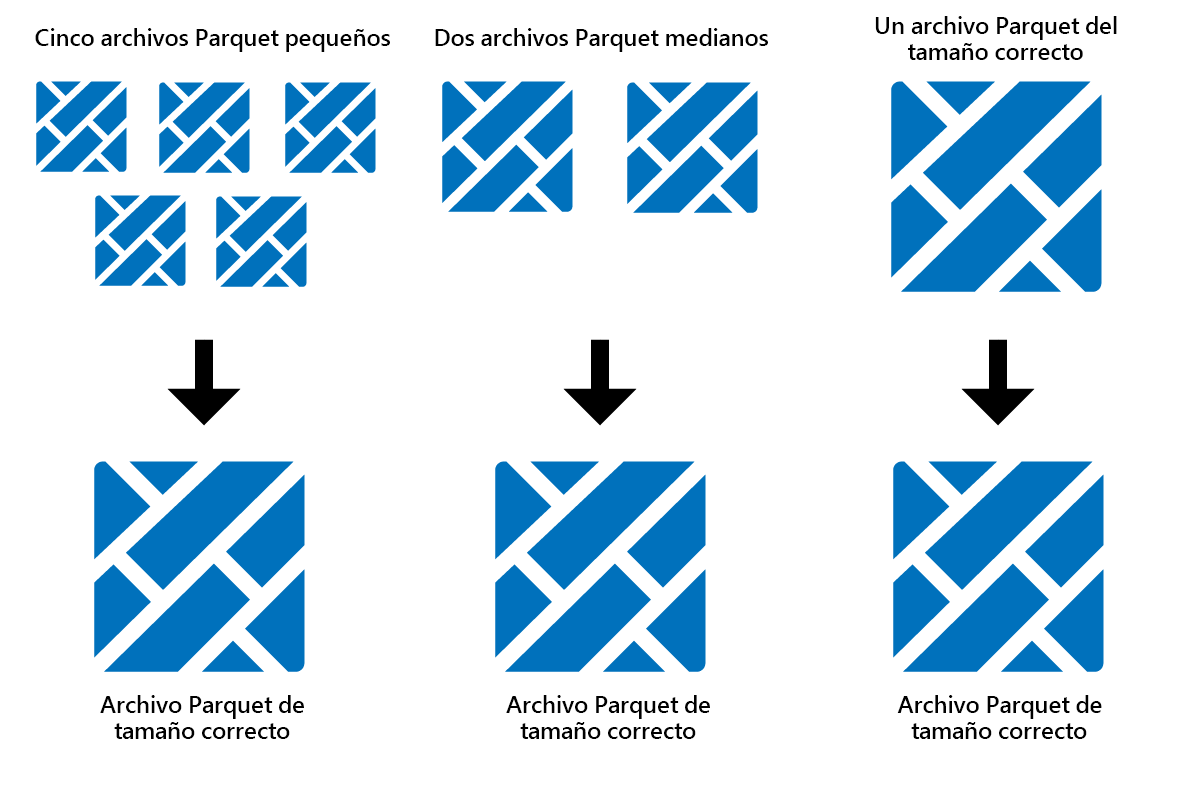
Optimizar es una característica de mantenimiento de tablas que consolida archivos pequeños de Parquet en menos archivos grandes. Puede ejecutar Optimizar después de cargar tablas grandes, lo que da como resultado:
- menos archivos más grandes
- mejor compresión
- distribución de datos eficaz entre nodos
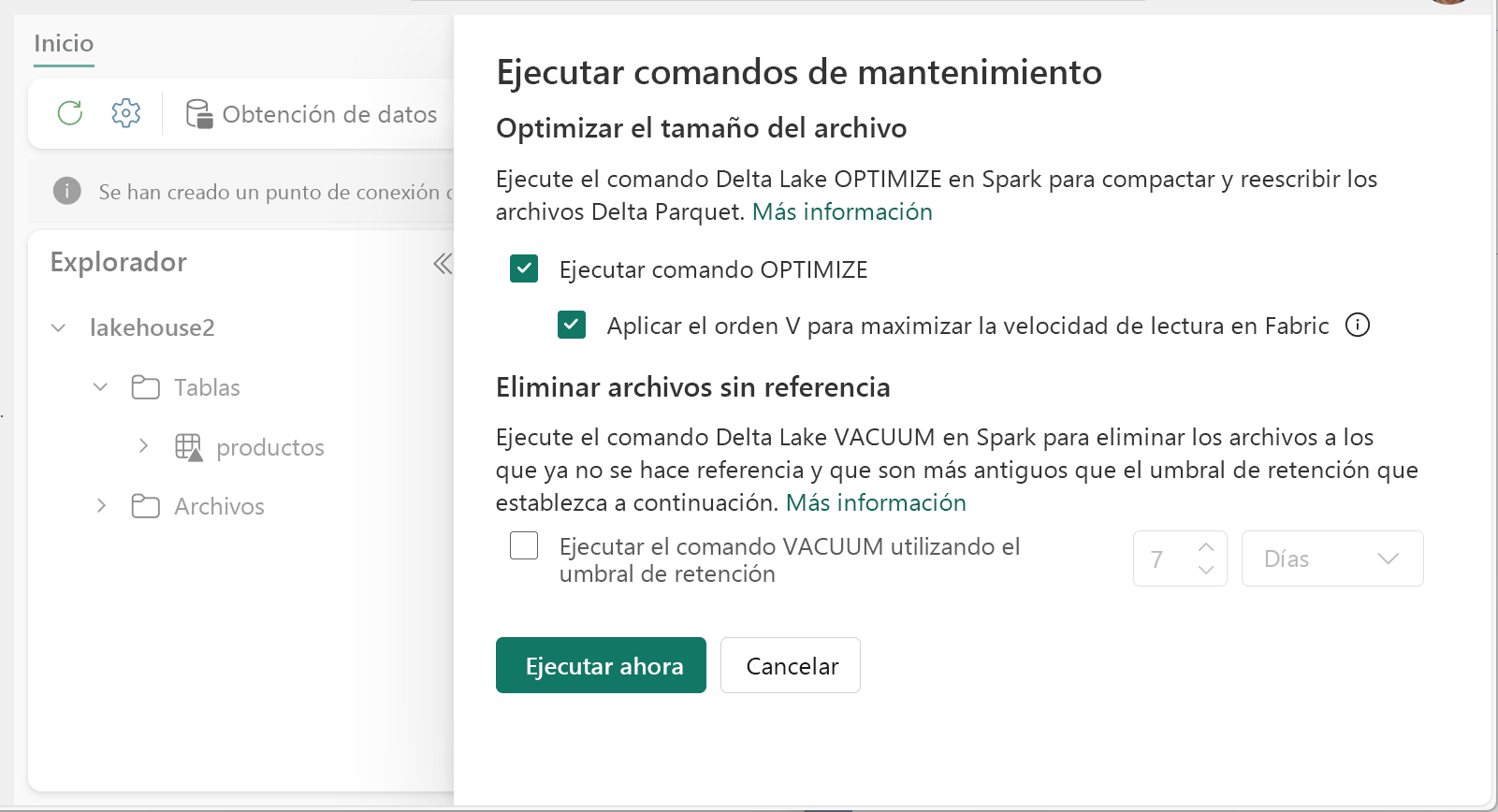
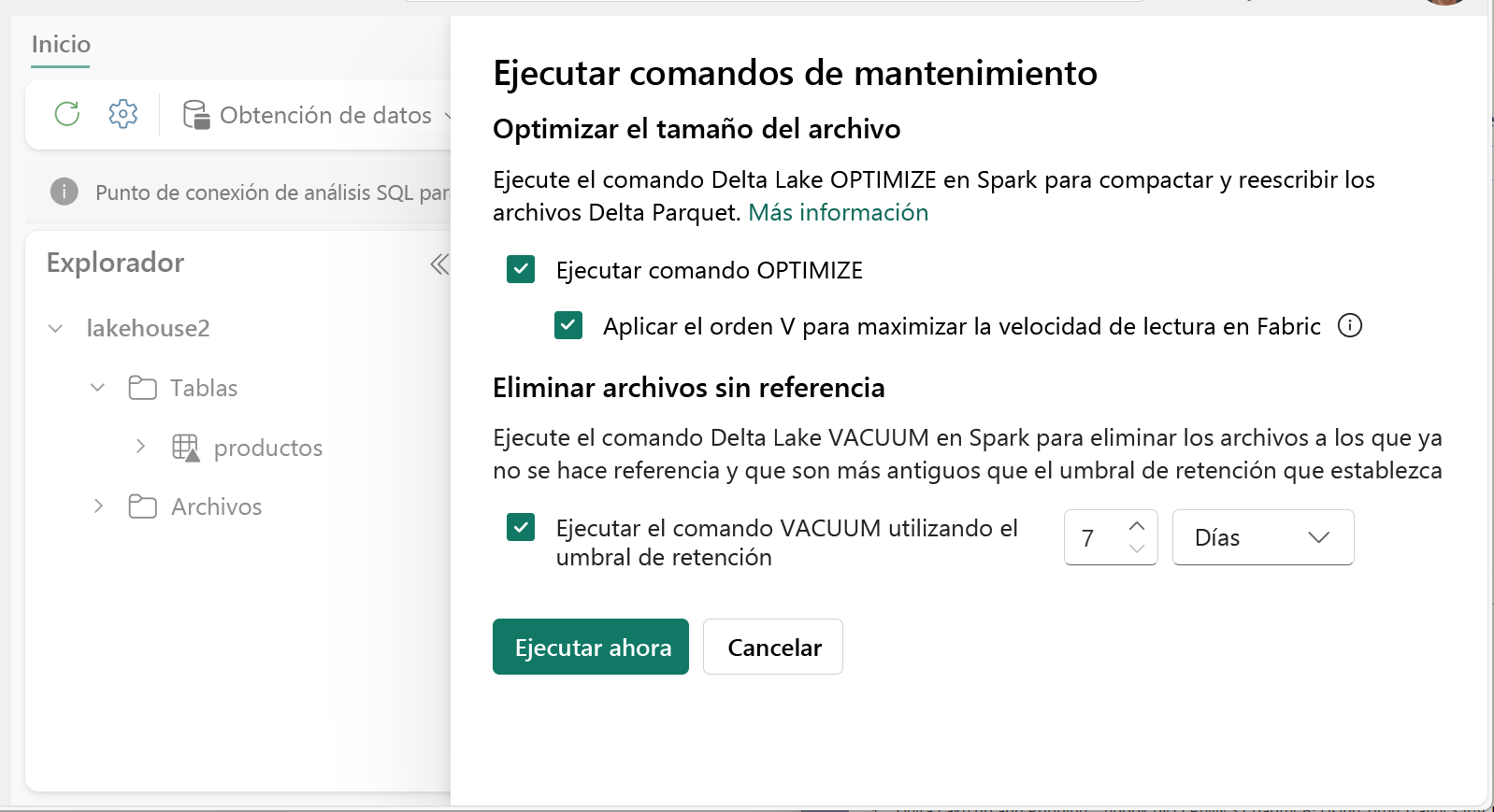
Para ejecutar Optimizar:
- En Explorador del almacén de lago de datos, seleccione ... menú junto a un nombre de tabla y seleccione Mantenimiento.
- Seleccione comando Ejecutar OPTIMIZAR.
- Si lo desea, seleccione Aplicar V-Order para maximizar la velocidad de lectura en Fabric.
- Selecciona Ejecutar ahora.
Función V-Order
Al ejecutar Optimizar, puede ejecutar opcionalmente V-Order, que está diseñado para el formato de archivo Parquet en Fabric. V-Order permite lecturas ultrarrápidas, con tiempos de acceso a los datos similares a los de la memoria. También mejora la rentabilidad, ya que reduce los recursos de red, disco y CPU durante las lecturas.
V-Order está habilitado de forma predeterminada en Microsoft Fabric y se aplica a medida que se escriben los datos. Incurre en una pequeña sobrecarga de aproximadamente el 15 % haciendo que las escrituras sean un poco más lentas. Sin embargo, V-Order permite lecturas más rápidas de los motores de proceso de Microsoft Fabric, como Power BI, SQL, Spark y otros.
En Microsoft Fabric, los motores de Power BI y SQL usan la tecnología Microsoft Verti-Scan, que aprovecha al máximo la optimización de V-Order para acelerar las lecturas. Spark y otros motores no usan la tecnología VertiScan, pero aún así se benefician de la optimización V-Order con lecturas un 10 % más rápidas, a veces hasta un 50 %.
V-Order funciona aplicando una ordenación especial, distribución de grupos de filas, codificación de diccionario y compresión en archivos Parquet. Es 100 % compatible con el formato Parquet de código abierto y todos los motores Parquet pueden leerlo.
Es posible que V-Order no sea beneficioso para escenarios de escritura intensiva, como almacenes de datos de almacenamiento provisional, donde los datos solo se leen una o dos veces. En estas situaciones, deshabilitar V-Order podría reducir el tiempo de procesamiento general de la ingesta de datos.
Aplique V-Order a tablas individuales mediante la característica Mantenimiento de tablas mediante la ejecución del comando OPTIMIZE.
Vacío
El comando VACUUM permite quitar archivos de datos antiguos.
Cada vez que se realiza una actualización o eliminación, se crea un nuevo archivo Parquet y se realiza una entrada en el registro de transacciones. Los archivos antiguos de Parquet se conservan para permitir el viaje en el tiempo, lo que significa que los archivos Parquet se acumulan a lo largo del tiempo.
El comando VACUUM elimina los archivos de datos de Parquet antiguos, pero no los registros de transacciones. Cuando ejecutas VACUUM, no puedes retroceder en el tiempo más allá del periodo de retención.
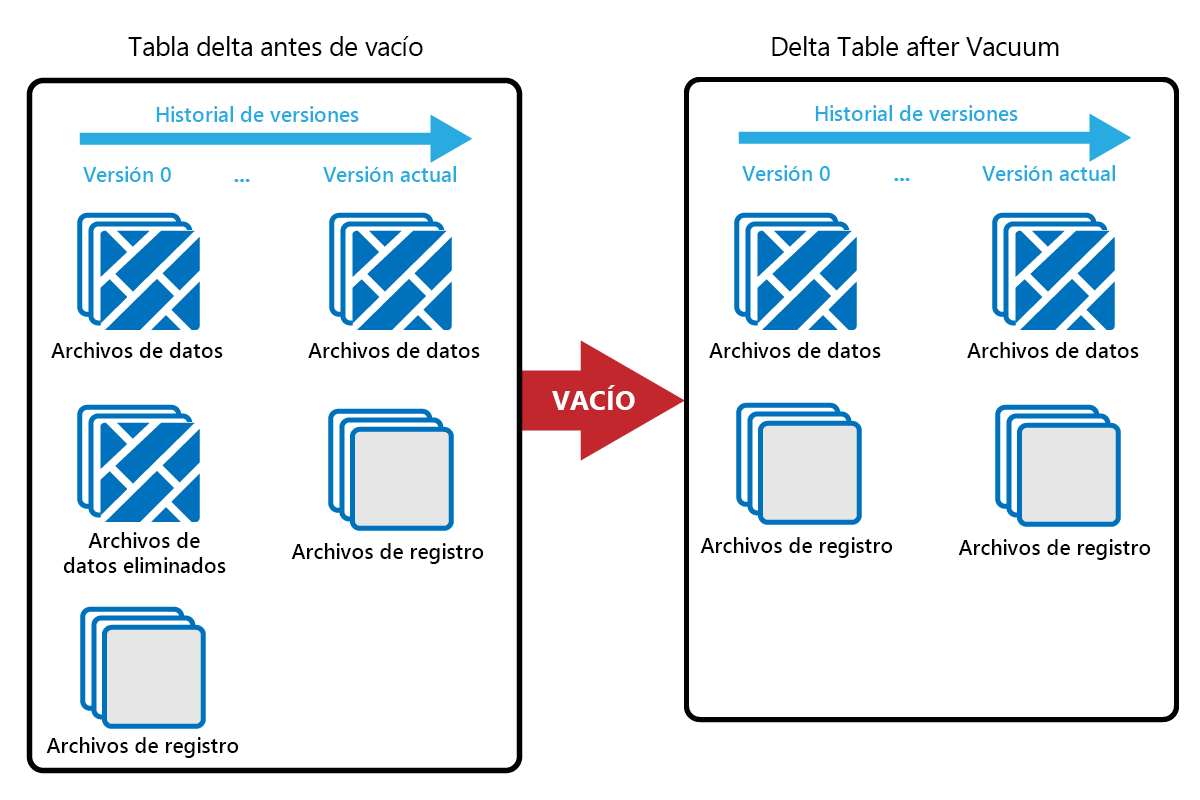
Los archivos de datos a los que no se hace referencia actualmente en un registro de transacciones y que son más antiguos que el período de retención especificado se eliminan permanentemente ejecutando VACUUM. Elija el período de retención en función de factores como:
- Requisitos de retención de datos
- Costos de almacenamiento y tamaño de datos
- Frecuencia de cambio de datos
- Requisitos reglamentarios
El período de retención predeterminado es de 7 días (168 horas) y el sistema le impide usar un período de retención más corto.
Puede ejecutar VACUUM de forma puntual o programada usando cuadernos de Fabric.
Ejecute VACUUM en tablas individuales mediante la característica Mantenimiento de tablas:
- En Explorador del almacén de lago de datos, seleccione ... menú junto a un nombre de tabla y seleccione Mantenimiento.
- Seleccione comando Ejecutar VACUUM con el umbral de retención y establezca el umbral de retención.
- Selecciona Ejecutar ahora.
También puede ejecutar VACUUM como comando SQL en un cuaderno:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM se confirma en el registro de transacciones Delta, por lo que puede ver las ejecuciones anteriores en DESCRIBE HISTORY.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Creación de particiones de tablas Delta
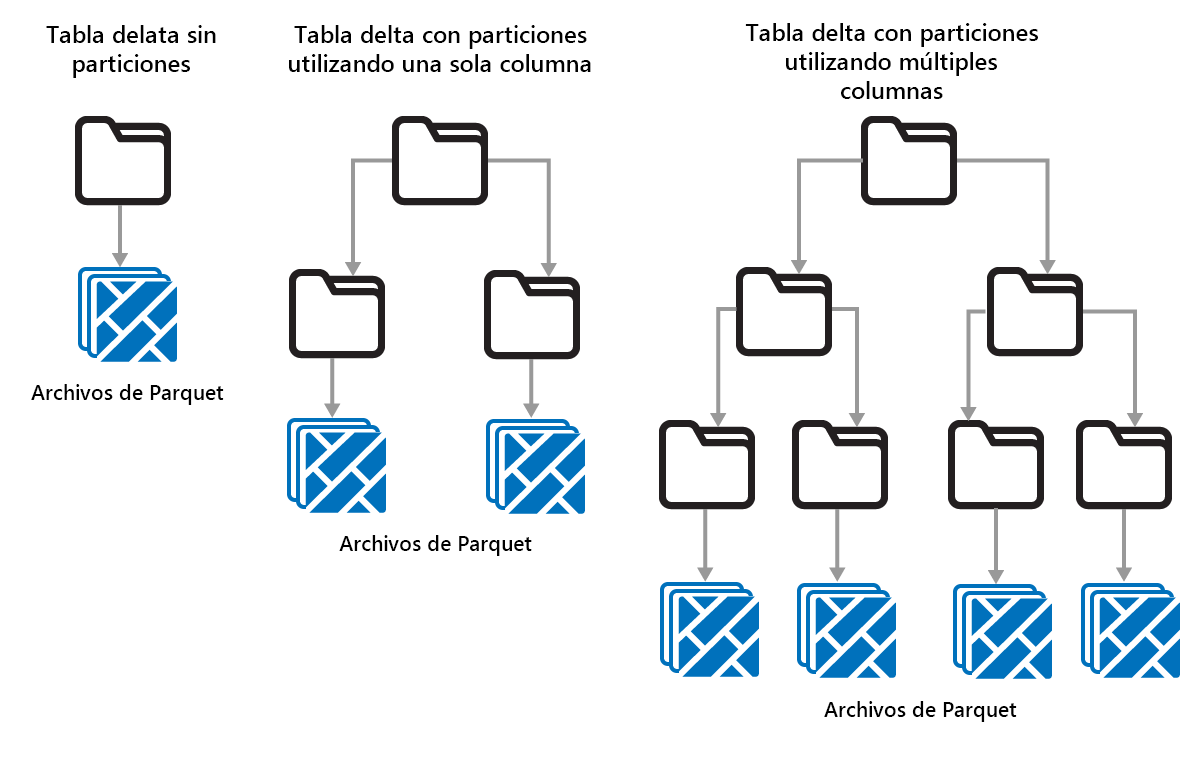
Delta Lake permite organizar los datos en particiones. Esto puede mejorar el rendimiento habilitando omisión de datos, lo que aumenta el rendimiento omitiendo objetos de datos irrelevantes en función de los metadatos de un objeto.
Considere una situación en la que se almacenan grandes cantidades de datos de ventas. Puede crear particiones de los datos de ventas por año. Las particiones se almacenan en subcarpetas denominadas "year=2021", "year=2022", etc. Si solo desea informar sobre los datos de ventas de 2024, se pueden omitir las particiones durante otros años, mejorando el rendimiento de lectura.
Sin embargo, la partición de pequeñas cantidades de datos puede degradar el rendimiento, ya que aumenta el número de archivos y puede agravar el "problema de archivos pequeños".
Use la creación de particiones si:
- Tiene grandes cantidades de datos.
- Las tablas se pueden dividir en algunas particiones grandes.
No use la creación de particiones si:
- Los volúmenes de datos son pequeños.
- Una columna de creación de particiones tiene una cardinalidad alta, ya que esto crea un gran número de particiones.
- Una columna de creación de particiones daría lugar a varios niveles.
Las particiones son un diseño de datos fijo y no se adaptan a diferentes patrones de consulta. Al considerar cómo usar la creación de particiones, piense en cómo se usan los datos y su granularidad.
En este ejemplo, un DataFrame que contiene los datos del producto se particiona por Categoría:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
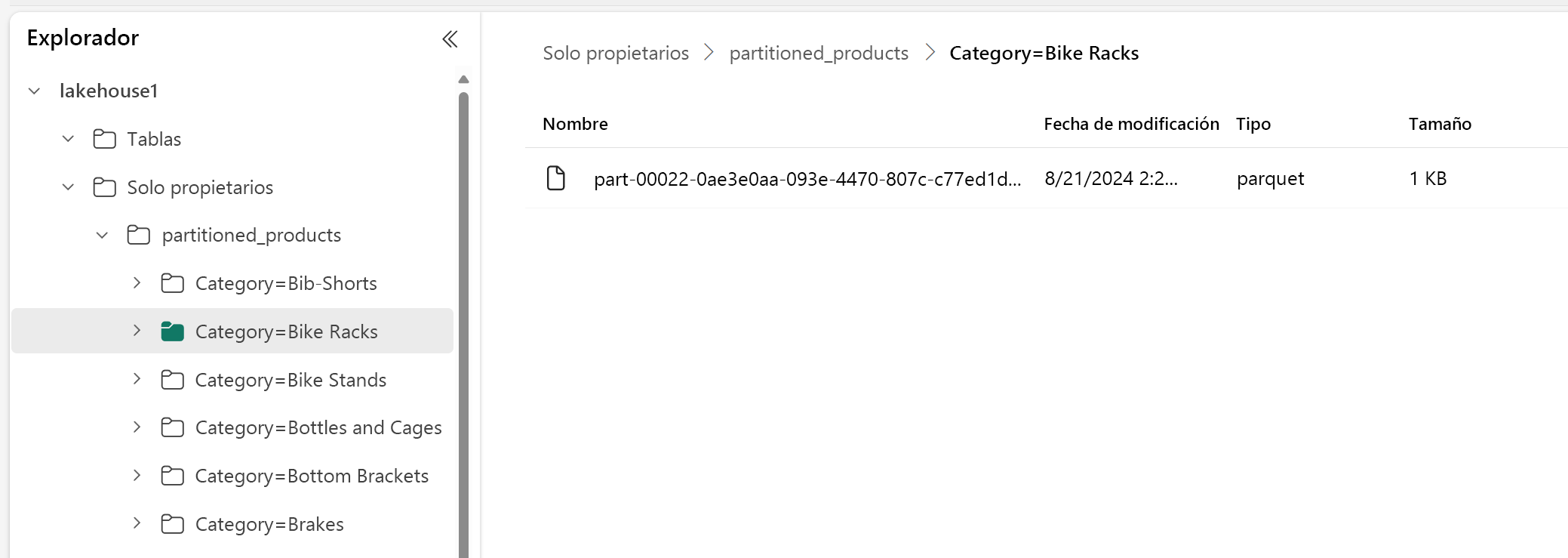
En el Explorador del almacén de lago de datos, puede ver que los datos son una tabla con particiones.
- Hay una carpeta para la tabla, denominada "partitioned_products".
- Hay subcarpetas para cada categoría, por ejemplo "Category=Bike Racks", etc.
Podemos crear una tabla con particiones similar mediante SQL:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);