Elección del destino de proceso adecuado
En Azure Machine Learning, los destinos de proceso son equipos físicos o virtuales en los que se ejecutan trabajos.
Descripción de los tipos de proceso disponibles
Azure Machine Learning admite varios tipos de proceso para la experimentación, el entrenamiento y la implementación. Al tener varios tipos de proceso, puedes seleccionar el tipo de destino de proceso más adecuado para tus necesidades concretas.
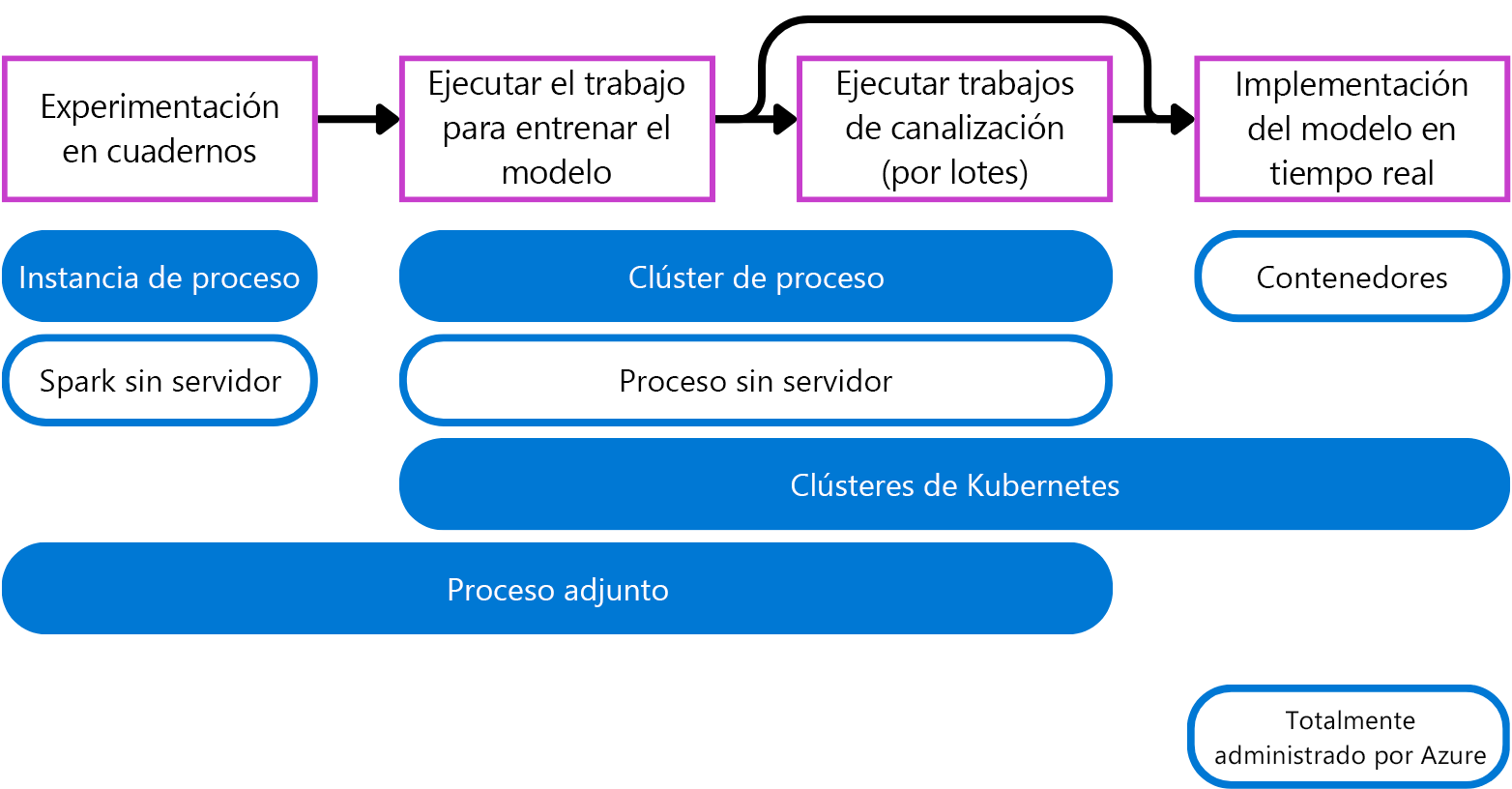
- Instancia de proceso: se comporta de forma similar a una máquina virtual y se usa principalmente para ejecutar cuadernos. Es idóneo para la experimentación.
- Clústeres de proceso: clústeres de varios nodos de máquinas virtuales que se escalan o reducen verticalmente de forma automática para satisfacer la demanda. Una manera rentable de ejecutar scripts que necesitan procesar grandes volúmenes de datos. Los clústeres también permiten usar el procesamiento paralelo para distribuir la carga de trabajo y reducir el tiempo necesario para ejecutar un script.
- Clústeres de Kubernetes: clúster basado en la tecnología Kubernetes, que proporciona más control sobre cómo se configura y administra el proceso. Puede asociar el clúster de Azure Kubernetes (AKS) autoadministrado para el proceso en la nube, o bien un clúster Arc de Kubernetes para cargas de trabajo locales.
- Proceso adjunto: Permite asociar un proceso existente como máquinas virtuales de Azure o clústeres de Azure Databricks al área de trabajo.
- Proceso sin servidor: Un proceso totalmente administrado a petición que puede usar para los trabajos de entrenamiento.
Nota:
Azure Machine Learning le ofrece la opción de crear y administrar un proceso propio, o bien usar el proceso totalmente administrado por Azure Machine Learning.
¿Cuándo usar cada tipo de proceso?
En general, hay algunos procedimientos recomendados que puede seguir al trabajar con destinos de proceso. Para comprender cómo elegir el tipo de proceso adecuado, se proporcionan varios ejemplos. Recuerde que el tipo de proceso que use siempre depende de cada situación específica.
Elección de un destino de proceso para la experimentación
Imagínate que eres un científico de datos y que te han pedido que desarrolles un nuevo modelo de Machine Learning. Es probable que dispongas de un pequeño subconjunto de los datos de entrenamiento con los que puedes experimentar.
Durante la experimentación y el desarrollo, es posible que prefieras trabajar en un cuaderno Jupyter Notebook. Una experiencia de cuaderno se beneficia principalmente de un proceso que se ejecuta de forma continuada.
Muchos científicos de datos están familiarizados con la ejecución de cuadernos en su dispositivo local. Una alternativa en la nube administrada por Azure Machine Learning es una instancia de proceso. Como alternativa, también puedes optar por el proceso sin servidor de Spark para ejecutar código Spark en cuadernos, si quieres hacer uso de la potencia de proceso distribuida de Spark.
Elección de un destino de proceso para producción
Después de la experimentación, puedes entrenar los modelos mediante la ejecución de scripts de Python como preparación para la producción. Los scripts serán más fáciles de automatizar y programar para cuando quiera volver a entrenar el modelo continuamente en el tiempo. Puedes ejecutar scripts como trabajos (de canalización).
Al pasar a producción, quiere que el destino de proceso esté listo para controlar grandes volúmenes de datos. Cuantos más datos use, mejor será el modelo de Machine Learning.
Al entrenar modelos con scripts, quieres un destino de proceso a petición. Un clúster de proceso se escalará verticalmente de forma automática cuando sea necesario ejecutar los scripts y se reducirá verticalmente cuando el script haya terminado de ejecutarse. Si quieres una alternativa que no tengas que crear y administrar, puedes usar el proceso sin servidor de Azure Machine Learning.
Elección de un destino de proceso para la implementación
El tipo de proceso que necesitas al usar el modelo para generar predicciones depende de si quieres realizar predicciones por lotes o en tiempo real.
Para las predicciones por lotes, puedes ejecutar un trabajo de canalización en Azure Machine Learning. Los destinos de proceso, como los clústeres de proceso y el proceso sin servidor de Azure Machine Learning, son ideales para los trabajos de canalización, ya que son a petición y escalables.
Cuando quieras predicciones en tiempo real, necesitarás un tipo de proceso que se ejecute continuamente. Por lo tanto, las implementaciones en tiempo real se benefician de un proceso más ligero (y, por consiguiente, son más rentables). Los contenedores son ideales para implementaciones en tiempo real. Al implementar el modelo en un punto de conexión en línea administrado, Azure Machine Learning crea y administra contenedores para que ejecutes tu modelo. Como alternativa, puedes asociar clústeres de Kubernetes para administrar el proceso necesario y generar predicciones en tiempo real.