Exploración de flujos de datos Gen2 en Microsoft Fabric
En Microsoft Fabric, puede crear un flujo de datos Gen2 en la carga de trabajo de Data Factory, en el área de trabajo de Power BI o directamente en el almacén de lago. Dado que nuestro escenario se centra en la ingesta de datos, echemos un vistazo a la experiencia de carga de trabajo de Data Factory. Los flujos de datos Gen2 usan Power Query Online para visualizar las transformaciones. Vea una introducción a la interfaz:
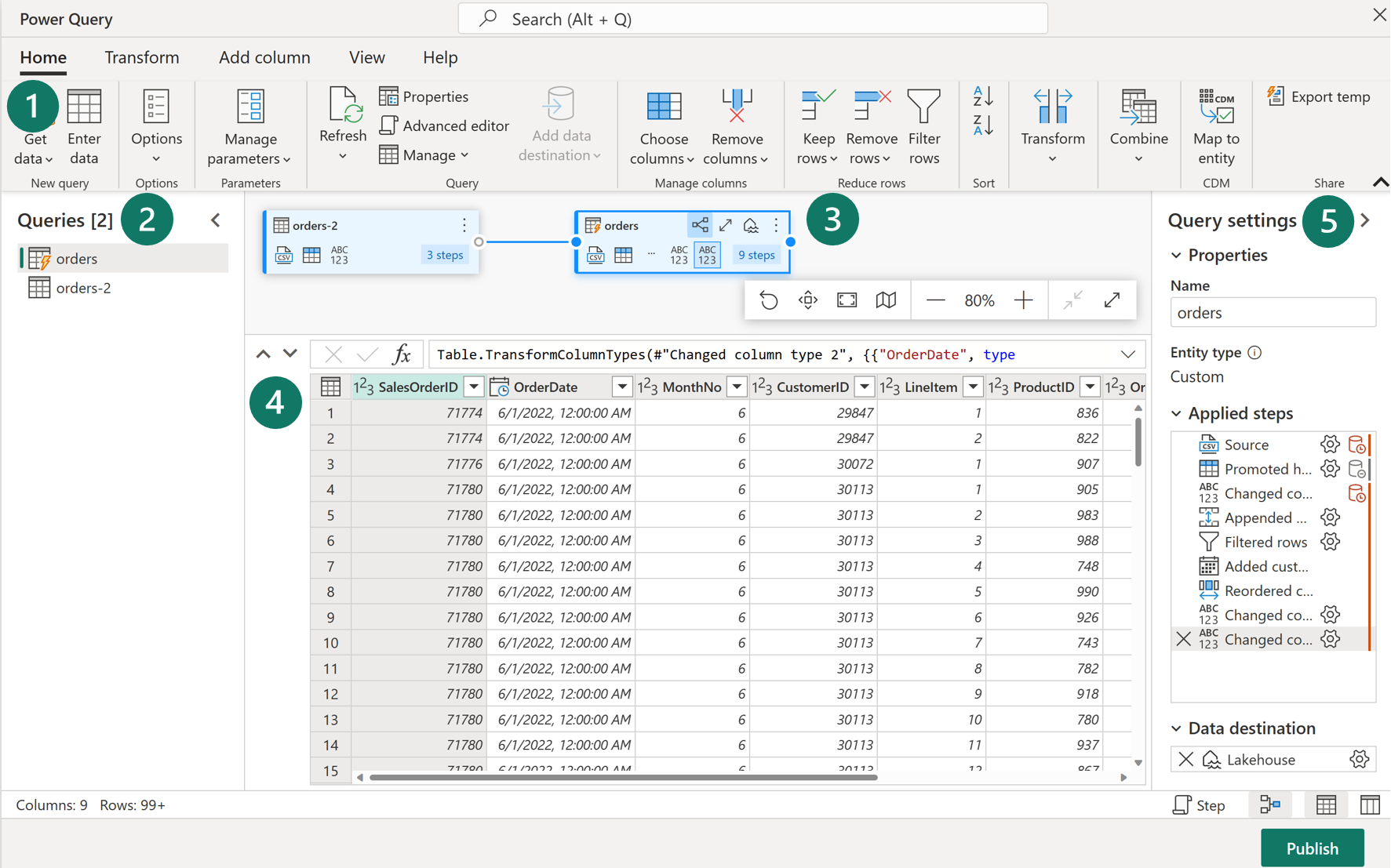
1. Cinta de opciones de Power Query
Los flujos de datos Gen2 admiten una amplia variedad de conectores de origen de datos. Los orígenes más comunes son bases de datos relacionales locales y en la nube, archivos de Excel o planos, SharePoint, SalesForce, Spark y Lakehouse de Fabric. Las transformaciones de datos posibles son muy numerosas, por ejemplo:
- Filtrar y ordenar filas.
- Dinamizar y anular la dinamización.
- Combinar y anexar consultas.
- Dividir y dividir condicionalmente.
- Reemplazar valores y quitar duplicados.
- Agregar, cambiar de nombre, reordenar o eliminar columnas.
- Calculadora de porcentaje y clasificación.
- Escoger N primeros y N últimos
También puedes crear y administrar conexiones de origen de datos, administrar parámetros y configurar el destino de datos predeterminado en esta cinta de opciones.
2. Panel Consultas
En el panel Consultas se muestran los distintos orígenes de datos, ahora denominados consultas. Estas consultas se denominan tablas cuando se cargan en el almacén de datos. Puedes duplicar o hacer referencia a una consulta si necesitas varias copias de los mismos datos, como la creación de un esquema de estrella y la división de datos en tablas independientes y más pequeñas. También puedes deshabilitar la carga de una consulta, en caso de que solo necesites la importación única.
3. Vista de diagrama
La vista de diagrama permite ver visualmente cómo están conectados los orígenes de datos y las distintas transformaciones aplicadas. Por ejemplo, el flujo de datos se conecta a un origen de datos, duplica la consulta, quita las columnas de la consulta de origen y después anula la dinamización de la consulta duplicada. Cada consulta se representa como una forma con todas las transformaciones aplicadas y conectadas mediante una línea para la consulta duplicada. Puedes activar o desactivar esta vista.
4. Panel Vista previa de los datos
El panel Vista previa de los datos solo muestra un subconjunto de datos para que pueda ver qué transformaciones debe realizar y cómo afectan a los datos. También puede interactuar con el panel de vista previa arrastrando y colocando columnas para cambiar el orden o haciendo clic con el botón derecho en las columnas para aplicar filtros o realizar cambios. La vista previa de datos muestra todas las transformaciones de la consulta seleccionada.
5. Panel Configuración de la consulta
El panel Configuración de la consulta incluye los Pasos aplicados. Cada transformación se representa como un paso, algunos de los cuales se aplican automáticamente al conectar el origen de datos. En función de la complejidad de las transformaciones, es posible que haya varios pasos aplicados a cada consulta. La mayoría de los pasos tienen un icono de engranaje que permite modificar el paso; de lo contrario, debes eliminarlo y repetir la transformación.
Cada paso también tiene un menú contextual al hacer clic con el botón derecho para poder cambiar el nombre de los pasos, reordenarlos o eliminarlos. También puede ver la consulta del origen de datos al conectarse a un origen de datos que admita el plegado de consultas.
Aunque esta interfaz visual es útil, también puede ver el código M en el Editor avanzado.
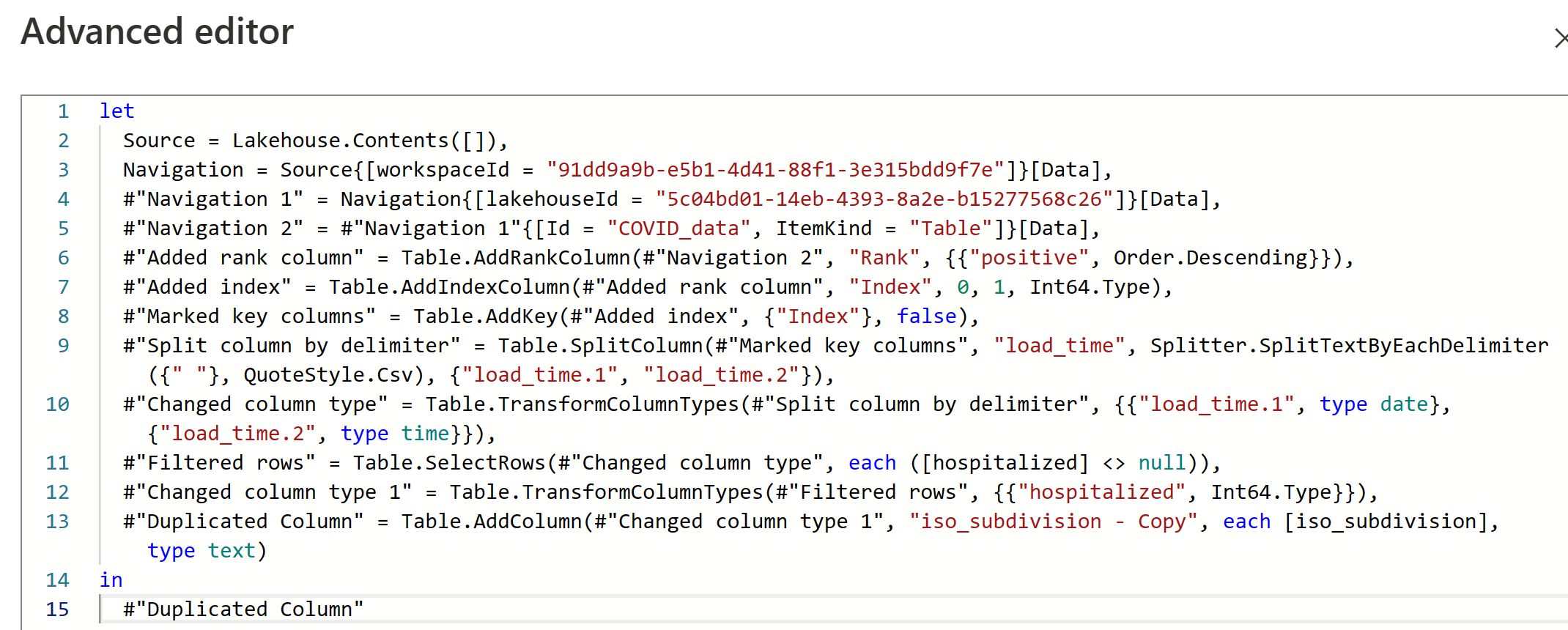
En el panel Configuración de consulta, puede ver una opción Destino de datos para colocar los datos en una de las siguientes ubicaciones del entorno de Fabric:
- Lakehouse
- Almacén
- Base de datos SQL
También puedes cargar el flujo de datos en Azure SQL Database, Azure Data Explorer o Azure Synapse Analytics.
Los flujos de datos Gen2 proporcionan una solución de código bajo a sin código para ingerir, transformar y cargar datos en tus almacenes de datos de Fabric. Los desarrolladores de Power BI están familiarizados y pueden empezar a realizar rápidamente transformaciones ascendentes para mejorar el rendimiento de sus informes.
Nota:
Para obtener más información, consulte la documentación de Power Query para optimizar los flujos de datos.