Visualización de datos
Una de las formas más intuitivas de analizar los resultados de las consultas de datos consiste en visualizarlos como gráficos. Los cuadernos de Azure Databricks ofrecen algunas funcionalidades básicas de gráficos en la interfaz de usuario y, cuando esa funcionalidad no proporciona lo que necesita, puede usar una de las muchas bibliotecas de gráficos de Python para crear y mostrar visualizaciones de datos en el cuaderno.
Uso de gráficos de cuadernos integrados
Al mostrar un elemento dataframe o ejecutar una consulta de SQL en un cuaderno de Spark en Azure Databricks, los resultados se muestran en la celda de código. De forma predeterminada, los resultados se representan como una tabla, pero también puede revisar los resultados como una visualización y personalizar cómo el gráfico visualiza los datos, tal como se muestra aquí:
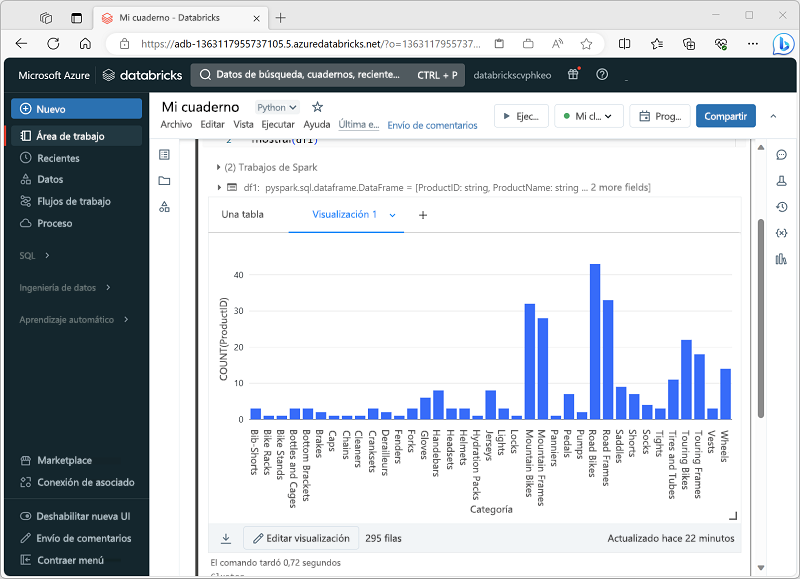
La funcionalidad de visualización integrada en cuadernos es útil cuando quiere resumir rápidamente los datos de forma visual. Si quiere tener más control sobre cómo se da formato a los datos o para mostrar los valores que ya ha agregado en una consulta, debe considerar el uso de un paquete de gráficos para crear visualizaciones propias.
Uso de paquetes gráficos en el código
Puede usar muchos paquetes gráficos para crear visualizaciones de datos en el código. En concreto, Python admite una gran selección de paquetes; la mayoría de ellos se basan en la biblioteca base Matplotlib. La salida de una biblioteca de gráficos se puede representar en un cuaderno, lo que facilita la combinación de código para ingerir y manipular datos con visualizaciones de datos insertadas y celdas de markdown para proporcionar comentarios.
Por ejemplo, puede usar el siguiente código de PySpark para agregar datos de los productos hipotéticos que se han explorado antes en este módulo y usar Matplotlib para crear un gráfico a partir de los datos agregados.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
La biblioteca Matplotlib necesita que los datos estén en un elemento dataframe de Pandas en lugar de uno de Spark, por lo que se usa el método toPandas para convertirlos. Después, el código crea una figura con un tamaño especificado y traza un gráfico de barras con alguna configuración de propiedades personalizada antes de mostrar el trazado resultante.
El gráfico generado por el código tendría un aspecto similar al de la imagen siguiente:
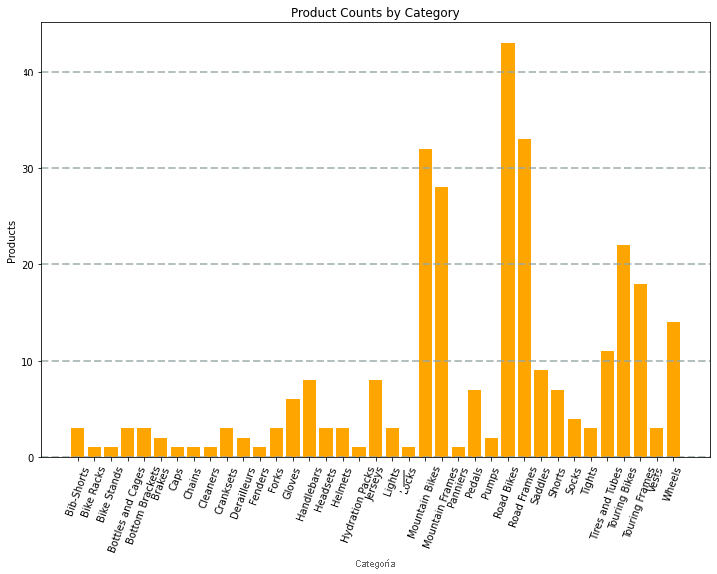
Puede usar la biblioteca Matplotlib para crear muchos tipos de gráficos; o si lo prefiere, puede usar otras bibliotecas como Seaborn para crear gráficos altamente personalizados.
Nota
Es posible que las bibliotecas de Matplotlib y Seaborn ya estén instaladas en clústeres de Databricks, en función del entorno de ejecución de Databricks para el clúster. Si no es así, o si quiere usar otra biblioteca que aún no está instalada, puede agregarla al clúster. Consulte Bibliotecas de clústeres en la documentación de Azure Databricks para obtener más información.