Descubra Spark
Para comprender mejor cómo procesar y analizar datos con Apache Spark en Azure Databricks, es importante comprender la arquitectura subyacente.
Información general de alto nivel
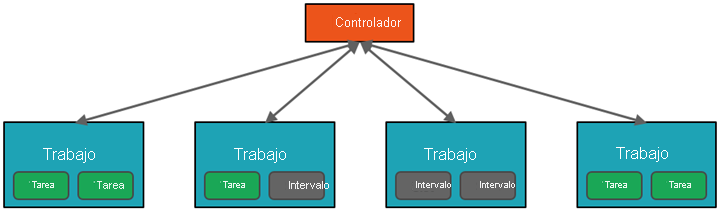
El servicio Azure Databricks inicia y administra los clústeres de Apache Spark en su suscripción de Azure desde un alto nivel. Los clústeres de Apache Spark son grupos de equipos que se tratan como un solo equipo y que controlan la ejecución de los comandos emitidos desde los cuadernos. Los clústeres le permiten procesar los datos en paralelo entre varios equipos para mejorar la escala y el rendimiento. Se componen de un controlador de Spark y de los nodos de trabajo. El nodo de controlador envía trabajo a los nodos de trabajo y les indica que extraigan los datos de un origen de datos concreto.
En Databricks, la interfaz del cuaderno es el programa del controlador normalmente. Dicho programa del controlador contiene el bucle principal del programa y crea conjuntos de datos distribuidos en el clúster; a continuación, aplica operaciones a esos conjuntos de datos. Los programas de controlador acceden a Apache Spark a través de un objeto SparkSession, independientemente de la ubicación de la implementación.
Microsoft Azure administra el clúster y le aplica la escalabilidad automática según sea necesario, en función del uso y de la configuración utilizada al configurar el clúster. También puede habilitarse la terminación automática, que permite a Azure finalizar el clúster después de un número de minutos de inactividad especificado.
Trabajos de Spark en detalle
El trabajo enviado al clúster se divide en tantos trabajos independientes como sea necesario. Este es el modo en que el trabajo se distribuye entre los nodos del clúster. Los trabajos se subdividen a su vez en tareas. La entrada a un trabajo se divide en una o más particiones. Estas particiones son la unidad de trabajo de cada espacio. Entre las distintas tareas, puede que sea necesario reorganizar las particiones y compartirlas a través de la red.
El secreto del alto rendimiento de Spark es el paralelismo. El escalado vertical (agregando recursos a un solo equipo) se limita a una cantidad finita de RAM, subprocesos y velocidades de CPU, pero los clústeres se escalan horizontalmente y agregan nuevos nodos al clúster según sea necesario.
Spark paraleliza los trabajos en dos niveles:
- El primer nivel de paralelización es el ejecutor: una máquina virtual de Java (JVM) que se ejecuta en un nodo de trabajo; normalmente hay una instancia por nodo.
- El segundo nivel de paralelización es el espacio: el número correspondiente viene determinado por el número de núcleos y CPU de cada nodo.
- Cada ejecutor tiene una serie de espacios a los que se puede asignar tareas en paralelo.
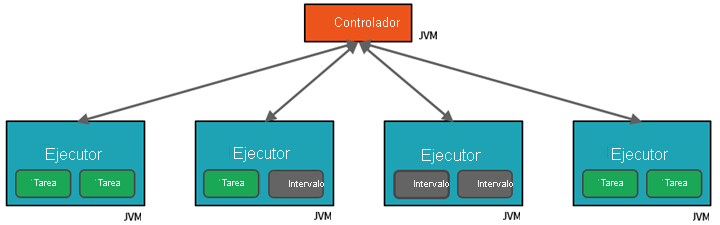
La JVM es naturalmente de tipo multiproceso, pero una sola JVM, como la que coordina el trabajo en el controlador, tiene un límite superior finito. Al dividir el trabajo en tareas, el controlador puede asignar unidades de trabajo a los *espacios de los ejecutores en nodos de trabajo para la ejecución en paralelo. Además, el controlador debe decidir cómo crear particiones de los datos a fin de que puedan distribuirse para el procesamiento en paralelo. Por lo tanto, el controlador asigna una partición de datos a cada tarea para que cada una sepa qué parte de datos va a procesar. Una vez iniciada, cada tarea capturará la partición de datos que tiene asignada.
Trabajos y fases
Dependiendo del trabajo que se realiza, es posible que se necesiten varios trabajos en paralelo. Cada trabajo se divide en fases. Una analogía útil es imaginar que el trabajo es construir una casa:
- La primera fase consistiría en sentar los cimientos.
- La segunda fase sería levantar las paredes.
- La tercera fase sería agregar el tejado.
Intentar realizar cualquiera de estos pasos fuera de orden simplemente no tiene sentido y, de hecho, puede ser imposible. De forma similar, Spark divide cada trabajo en fases para asegurarse de que todo se realiza en el orden correcto.
Modularidad
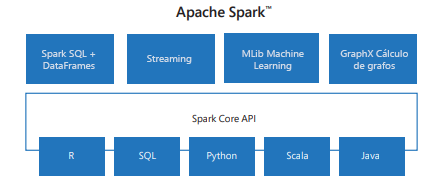
Spark incluye bibliotecas para tareas que van desde SQL hasta el streaming y el aprendizaje automático, lo que lo convierte en una herramienta para tareas de procesamiento de datos. Algunas de las bibliotecas de Spark incluyen:
- Spark SQL: Para trabajar con datos estructurados.
- SparkML: Para el aprendizaje automático.
- GraphX: Para el procesamiento de grafos.
- Spark Streaming: Para el procesamiento de datos en tiempo real.
Compatibilidad
Spark puede ejecutarse en una variedad de sistemas distribuidos, como YARN de Hadoop, Apache Mesos, Kubernetes o el propio administrador de clústeres de Spark. También lee y escribe en diversos orígenes de datos, como HDFS, Cassandra, HBase y Amazon S3.