Evaluación de un modelo de clasificación
Gran parte del aprendizaje automático trata la evaluación del funcionamiento de los modelos. Esta valoración tiene lugar durante el entrenamiento, para ayudar a dar forma al modelo y, después del entrenamiento, para ayudarnos a determinar si el modelo es adecuado para usarse en el mundo real. Los modelos de clasificación necesitan evaluación, al igual que los modelos de regresión, aunque la forma en que se lleva a cabo esta evaluación a veces puede ser un poco más compleja.
Recordatorio sobre el costo
Recuerde que durante el entrenamiento, calculamos el bajo rendimiento de un modelo y lo denominamos costo o pérdida. Por ejemplo, en regresión lineal a menudo usamos una métrica denominada error cuadrático medio (MSE). Para calcular el MSE, se comparan la predicción y la etiqueta real, se iguala la diferencia y se toma el promedio del resultado. Podemos usar MSE para ajustar el modelo e informar sobre cómo funciona.
Funciones de costo para la clasificación
Los modelos de clasificación se juzgarán en función de sus probabilidades de salida, como el 40 % de probabilidad de alud o las etiquetas finales: no avalanche o avalanche. El uso de las probabilidades de salida puede ser ventajoso durante el entrenamiento. Los pequeños cambios en el modelo se reflejan en cambios en las probabilidades, aunque no sean suficientes para cambiar la decisión final. El uso de las etiquetas finales para una función de costo es más útil si queremos estimar el rendimiento real del modelo. Por ejemplo, en el conjunto de pruebas. Dado que, para el uso real, usamos las etiquetas finales, no las probabilidades.
Pérdida logarítmica
La pérdida logarítmica es una de las funciones de costo más populares para la clasificación simple. La pérdida logarítmica se suele aplicar a las probabilidades de salida. De forma similar a MSE, pequeñas cantidades de errores tienen como resultado un costo reducido, mientras que las cantidades moderadas de errores tienen como resultado costos elevados. Hemos trazado la pérdida logarítmica en el grafo siguiente para una etiqueta en la que la respuesta correcta era 0 (false).
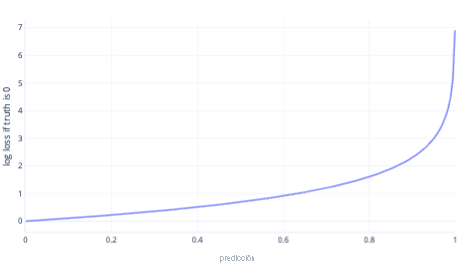
En el eje X hay posibles salidas del modelo (probabilidades de 0 a 1) y el eje Y indica el costo. Si un modelo tiene una confianza alta de que la respuesta correcta es 0 (por ejemplo, la predicción de 0,1), el costo es bajo porque en este caso la respuesta correcta es 0. Si el modelo predice con confianza un resultado erróneo (por ejemplo, 0,9), el costo será elevado. De hecho, en X=1, el costo es tan alto que aquí hemos recortado el eje X a 0,999 para mantener el grafo legible.
¿Por qué no MSE?
MSE y la pérdida logarítmica son métricas similares. Hay algunas razones complejas por las que la pérdida logarítmica se prefiere para la regresión logística, pero también algunas razones más sencillas. Por ejemplo, la pérdida logarítmica castiga las respuestas incorrectas de manera mucho más contundente que MSE. Por ejemplo, en el grafo siguiente, donde la respuesta correcta es 0, las predicciones por encima de 0,8 tienen un costo mucho mayor para la pérdida logarítmica que el MSE.
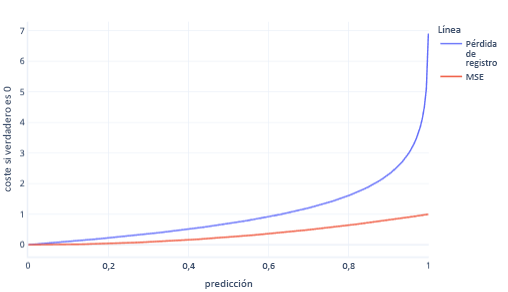
De este modo, un costo más elevado ayuda al modelo a aprender más rápido debido al mayor gradiente de la línea. Del mismo modo, la pérdida logarítmica ayuda a los modelos a confiar más en dar la respuesta correcta. Observe que en el trazado anterior, el costo de MSE para los valores menores que 0,2 es pequeño y el gradiente es casi plano. Esta relación hace que el entrenamiento sea lento para los modelos que son casi correctos. La pérdida logarítmica tiene un gradiente más inclinado para estos valores, lo que ayuda al modelo a aprender más rápido.
Limitaciones de las funciones de costo
El uso de una función de costo única para la evaluación humana del modelo siempre está limitado porque no indica qué tipo de errores está cometiendo el modelo. Por ejemplo, considere nuestro escenario de predicción de aludes. Un valor de pérdida logarítmica alto podría significar que el modelo predice repetidamente aludes cuando no se produce ninguno. O podría significar que no es capaz de predecir una y otra vez los aludes que se producen.
Para comprender mejor nuestros modelos, puede ser más fácil usar más de un número para evaluar si funcionan bien. Este tema más amplio lo tratamos en otro material didáctico, aunque lo tocaremos en los siguientes ejercicios.